

Data har blitt stadig viktigere for å bygge maskinlæringsmodeller, teste applikasjoner og tegne forretningsinnsikt.
For overholdelse av de mange dataforskriftene er den imidlertid ofte hvelvet og strengt beskyttet. Å få tilgang til slike data kan ta måneder å få de nødvendige sign-offs. Alternativt kan bedrifter bruke syntetiske data.
Innholdsfortegnelse
Hva er syntetiske data?
Bildekreditt: Twinify
Syntetiske data er kunstig genererte data som statistisk ligner det gamle datasettet. Den kan brukes med ekte data for å støtte og forbedre AI-modeller eller kan brukes som en erstatning helt.
Fordi den ikke tilhører noen registrerte og ikke inneholder personlig identifiserende informasjon eller sensitive data som personnummer, kan den brukes som et personvernbeskyttende alternativ til ekte produksjonsdata.
Forskjeller mellom ekte og syntetiske data
- Den mest avgjørende forskjellen er hvordan de to typene data genereres. Ekte data kommer fra virkelige personer hvis data ble samlet inn under undersøkelser eller da de brukte søknaden din. På den annen side genereres syntetiske data kunstig, men ligner fortsatt det originale datasettet.
- Den andre forskjellen er i databeskyttelsesforskriften som påvirker ekte og syntetiske data. Med ekte data skal forsøkspersonene kunne vite hvilke data om dem som samles inn og hvorfor de samles inn, og det er grenser for hvordan de kan brukes. Disse reglene gjelder imidlertid ikke lenger for syntetiske data fordi dataene ikke kan tilskrives et subjekt og ikke inneholder personopplysninger.
- Den tredje forskjellen er tilgjengelige datamengder. Med ekte data kan du bare ha så mye som brukerne gir deg. På den annen side kan du generere så mye syntetisk data du vil.
Hvorfor du bør vurdere å bruke syntetiske data
- Det er relativt billigere å produsere fordi du kan generere mye større datasett som ligner det mindre datasettet du allerede har. Dette betyr at maskinlæringsmodellene dine vil ha mer data å trene med.
- De genererte dataene blir automatisk merket og renset for deg. Dette betyr at du ikke trenger å bruke tid på å gjøre det tidkrevende arbeidet med å forberede dataene for maskinlæring eller analyser.
- Det er ingen personvernproblemer da dataene ikke er personlig identifiserende og ikke tilhører en registrert person. Dette betyr at du kan bruke den og dele den fritt.
- Du kan overvinne AI-bias ved å sikre at minoritetsklasser er godt representert. Dette hjelper deg med å bygge rettferdig og ansvarlig AI.
Hvordan generere syntetiske data
Mens generasjonsprosessen varierer avhengig av hvilket verktøy du bruker, begynner prosessen vanligvis med å koble en generator til et eksisterende datasett. Deretter identifiserer du de personlig identifiserende feltene i datasettet ditt og merker dem for ekskludering eller tilsløring.
Generatoren begynner deretter å identifisere datatypene for de gjenværende kolonnene og de statistiske mønstrene i disse kolonnene. Fra da kan du generere så mye syntetisk data du trenger.
Vanligvis kan du sammenligne de genererte dataene med det originale datasettet for å se hvor godt de syntetiske dataene ligner de virkelige dataene.
Nå skal vi utforske verktøyene for syntetisk datagenerering for å trene maskinlæringsmodeller.
Mest AI

For det meste har AI en AI-drevet syntetisk datagenerator som lærer av det originale datasettets statistiske mønstre. AI genererer deretter fiktive karakterer som samsvarer med de lærte mønstrene.
Med Mostly AI kan du generere hele databaser med referanseintegritet. Du kan syntetisere alle slags data for å hjelpe deg med å bygge bedre AI-modeller.
Synthesized.io

Synthesized.io brukes av ledende selskaper for deres AI-initiativer. For å bruke synthesize.io spesifiserer du datakravene i en YAML-konfigurasjonsfil.
Deretter oppretter du en jobb og kjører den som en del av en datapipeline. Den har også et veldig generøst gratis nivå som lar deg eksperimentere og se om det passer databehovene dine.
YData

Med YData kan du generere tabell-, tidsserie-, transaksjons-, multi-tabell- og relasjonsdata. Dette lar deg unngå problemene knyttet til datainnsamling, deling og kvalitet.
Den kommer med en AI og SDK som kan brukes til å samhandle med plattformen deres. I tillegg har de en sjenerøs gratis tier som du kan bruke til å demonstrere produktet.
Gretel AI

Gretel AI tilbyr APIer for å generere ubegrensede mengder syntetiske data. Gretel har en åpen kildekode-datagenerator som du kan installere og bruke.
Alternativt kan du bruke deres REST API eller CLI, som koster penger. Prisene deres er imidlertid rimelige og skalerer med størrelsen på virksomheten.
Kopulas
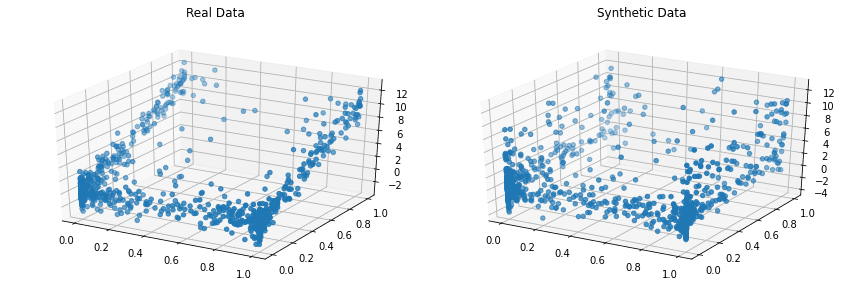
Copulas er et åpen kildekode Python-bibliotek for modellering av multivariate distribusjoner ved å bruke copula-funksjoner og generere syntetiske data som følger de samme statistiske egenskapene.
Prosjektet startet i 2018 ved MIT som en del av Synthetic Data Vault Project.
CTGAN
CTGAN består av generatorer som er i stand til å lære fra enkelttabells virkelige data og generere syntetiske data fra de identifiserte mønstrene.
Det er implementert som et åpen kildekode Python-bibliotek. CTGAN, sammen med Copulas, er en del av Synthetic Data Vault Project.
DoppelGANger
DoppelGANger er en åpen kildekode-implementering av Generative Adversarial Networks for å generere syntetiske data.
DoppelGANger er nyttig for å generere tidsseriedata og brukes av selskaper som Gretel AI. Python-biblioteket er tilgjengelig gratis og er åpen kildekode.
Synth

Synth er en åpen kildekode-datagenerator som hjelper deg med å lage realistiske data til dine spesifikasjoner, skjule personlig identifiserbar informasjon og utvikle testdata for applikasjonene dine.
Du kan bruke Synth til å generere sanntidsserier og relasjonsdata for dine maskinlæringsbehov. Synth er også databaseagnostisk, slik at du kan bruke den med SQL- og NoSQL-databasene dine.
SDV.dev
SDV står for Synthetic Data Vault. SDV.dev er et programvareprosjekt som startet ved MIT i 2016 og har laget forskjellige verktøy for å generere syntetiske data.
Disse verktøyene inkluderer Copulas, CTGAN, DeepEcho og RDT. Disse verktøyene er implementert som åpen kildekode Python-biblioteker som du enkelt kan bruke.
Tofu
Tofu er et åpen kildekode Python-bibliotek for å generere syntetiske data basert på britiske biobankdata. I motsetning til verktøyene nevnt før som vil hjelpe deg med å generere alle typer data basert på ditt eksisterende datasett, genererer Tofu data som kun ligner biobanken.
UK Biobank er en studie på de fenotypiske og genotypiske egenskapene til 500 000 middelaldrende voksne fra Storbritannia.
Twinify
Twinify er en programvarepakke som brukes som et bibliotek eller kommandolinjeverktøy for å doble sensitive data ved å produsere syntetiske data med identiske statistiske distribusjoner.

For å bruke Twinify gir du de virkelige dataene som en CSV-fil, og den lærer av dataene for å produsere en modell som kan brukes til å generere syntetiske data. Det er helt gratis å bruke.
Datanamic
Datanamic hjelper deg med å lage testdata for datadrevne og maskinlæringsapplikasjoner. Den genererer data basert på kolonneegenskaper som e-post, navn og telefonnummer.
Datanamic datageneratorer kan tilpasses og støtter de fleste databaser som Oracle, MySQL, MySQL Server, MS Access og Postgres. Den støtter og sikrer referanseintegritet i de genererte dataene.
Benerator
Benerator er programvare for dataobfuskering, generering og migrering for test- og opplæringsformål. Ved å bruke Benerator beskriver du data ved hjelp av XML (Extensible Markup Language) og genererer ved hjelp av kommandolinjeverktøyet.
Den er laget for å kunne brukes av ikke-utviklere, og med den kan du generere milliarder av rader med data. Benerator er gratis og åpen kildekode.
Siste ord
Det anslås av Gartner at innen 2030 vil det være mer syntetiske data brukt til maskinlæring enn det vil være reelle data.
Det er ikke vanskelig å se hvorfor gitt kostnadene og personvernbekymringene ved å bruke ekte data. Det er derfor nødvendig at bedrifter lærer om syntetiske data og de forskjellige verktøyene for å hjelpe dem med å generere dem.
Deretter kan du sjekke ut syntetiske overvåkingsverktøy for nettvirksomheten din.