
Hvis du er ny på big data-analyse, kan en rekke apache-verktøy være på radaren din; Imidlertid kan de forskjellige verktøyene bli forvirrende og til tider overveldende.
Dette innlegget vil løse denne forvirringen og forklare hva Apache Hive og Impala er og hva som gjør dem forskjellige fra hverandre!
Innholdsfortegnelse
Apache Hive
Apache Hive er et SQL-datatilgangsgrensesnitt for Apache Hadoop-plattformen. Hive lar deg spørre, samle og analysere data ved hjelp av SQL-syntaks.
Et lesetilgangsskjema brukes for data i HDFS-filsystemet, slik at du kan behandle data som med en vanlig tabell eller relasjons-DBMS. HiveQL-spørringer oversettes til Java-kode for MapReduce-jobber.
Hive-spørringer er skrevet i HiveQL-spørringsspråket, som er basert på SQL-språket, men som ikke har full støtte for SQL-92-standarden.
Imidlertid lar dette språket programmerere bruke sine spørringer når det er upraktisk eller ineffektivt å bruke HiveQL-funksjoner. HiveQL kan utvides med brukerdefinerte skalarfunksjoner (UDF), aggregering (UDAF-koder) og tabellfunksjoner (UDTF).
Hvordan fungerer Apache Hive
Apache Hive oversetter programmer skrevet på HiveQL-språket (nær SQL) til en eller flere MapReduce-, Apache Tez- eller Apache Spark-oppgaver. Dette er tre utførelsesmotorer som kan lanseres på Hadoop. Deretter organiserer Apache Hive dataene i en matrise for Hadoop Distributed File System (HDFS)-filen for å kjøre jobbene på en klynge for å produsere et svar.
Apache Hive-tabeller ligner på relasjonsdatabaser, og dataenheter er organisert fra den viktigste enheten til den mest detaljerte. Databaser er arrays sammensatt av partisjoner, som igjen kan brytes ned i «bøtter».
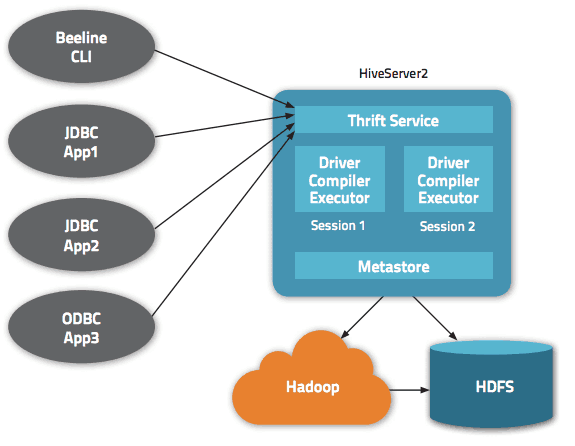
Dataene er tilgjengelige via HiveQL. Innenfor hver database er dataene nummerert, og hver tabell tilsvarer en HDFS-katalog.
Flere grensesnitt er tilgjengelige innenfor Apache Hive-arkitekturen, for eksempel webgrensesnitt, CLI eller eksterne klienter.
Faktisk lar «Apache Hive Thrift»-serveren eksterne klienter sende inn kommandoer og forespørsler til Apache Hive ved å bruke forskjellige programmeringsspråk. Apache Hives sentrale katalog er en «metastore» som inneholder all informasjon.
Motoren som får Hive til å fungere kalles «sjåføren». Den kombinerer en kompilator og en optimizer for å bestemme den optimale utførelsesplanen.
Til slutt, sikkerhet er levert av Hadoop. Den er derfor avhengig av Kerberos for gjensidig autentisering mellom klienten og serveren. Tillatelsen for nyopprettede filer i Apache Hive er diktert av HDFS, og tillater bruker-, gruppe- eller annen autorisasjon.
Funksjoner av Hive
- Støtter datamotoren til både Hadoop og Spark
- Bruker HDFS og fungerer som datavarehus.
- Bruker MapReduce og støtter ETL
- På grunn av HDFS har den feiltoleranse som ligner på Hadoop
Apache Hive: Fordeler
Apache Hive er en ideell løsning for spørringer og dataanalyse. Det gjør det mulig å oppnå kvalitativ innsikt, gir et konkurransefortrinn og gjør det mulig å reagere på markedets etterspørsel.
Blant hovedfordelene med Apache Hive kan vi nevne brukervennligheten knyttet til dets «SQL-vennlige» språk. I tillegg fremskynder det den første innsettingen av data siden dataene ikke trenger å leses eller nummereres fra en disk i det interne databaseformatet.
Når du vet at dataene er lagret i HDFS, er det mulig å lagre store datasett på opptil hundrevis av petabyte med data på Apache Hive. Denne løsningen er mye mer skalerbar enn en tradisjonell database. Å vite at det er en skytjeneste, lar Apache Hive brukere raskt starte virtuelle servere basert på svingninger i arbeidsbelastninger (dvs. oppgaver).
Sikkerhet er også et aspekt der Hive yter bedre, med sin evne til å replikere gjenopprettingskritiske arbeidsbelastninger i tilfelle et problem. Endelig er arbeidskapasiteten uten sidestykke siden den kan utføre opptil 100 000 forespørsler i timen.
Apache Impala
Apache Impala er en massivt parallell SQL-spørringsmotor for interaktiv utførelse av SQL-spørringer på data lagret i Apache Hadoop, skrevet i C++ og distribuert under Apache 2.0-lisensen.
Impala kalles også en MPP (Massively Parallel Processing)-motor, en distribuert DBMS og til og med en SQL-on-Hadoop stackdatabase.

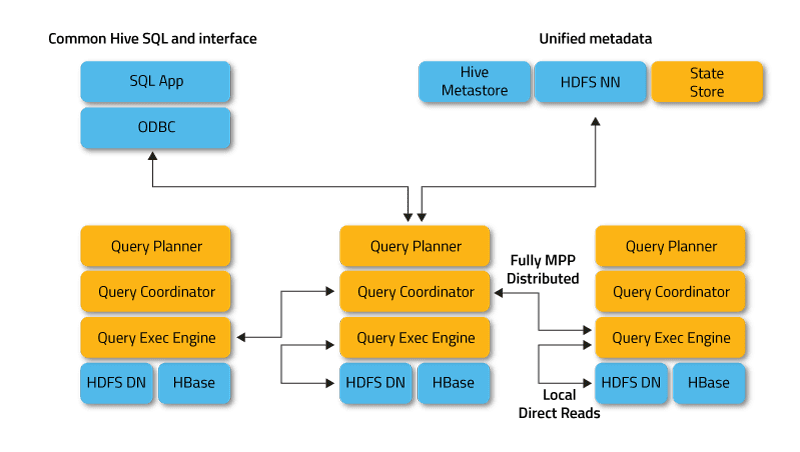
Impala opererer i distribuert modus, der prosessinstanser kjører på forskjellige klyngenoder, mottar, planlegger og koordinerer klientforespørsler. I dette tilfellet er parallell kjøring av fragmenter av SQL-spørringen mulig.
Klienter er brukere og applikasjoner som sender SQL-spørringer mot data lagret i Apache Hadoop (HBase og HDFS) eller Amazon S3. Interaksjon med Impala skjer gjennom HUE (Hadoop User Experience) nettgrensesnitt, ODBC, JDBC og Impala Shell-kommandolinjeskallet.
Impala er infrastrukturmessig avhengig av et annet populært SQL-on-Hadoop-verktøy, Apache Hive, som bruker metadatalageret. Spesielt lar Hive Metastore Impala vite om tilgjengeligheten og strukturen til databasene.
Når du oppretter, endrer og sletter skjemaobjekter eller laster data inn i tabeller via SQL-setninger, overføres de tilsvarende metadataendringene automatisk til alle Impala-noder ved hjelp av en spesialisert katalogtjeneste.
Nøkkelkomponentene til Impala er følgende kjørbare filer:
- Impalad eller Impala daemon er en systemtjeneste som planlegger og utfører spørringer på HDFS-, HBase- og Amazon S3-data. En impaladeprosess kjører på hver klyngennode.
- Statestore er en navnetjeneste som holder styr på plasseringen og statusen til alle impalade-forekomster i klyngen. Én forekomst av denne systemtjenesten kjører på hver node og hovedserveren (Name Node).
- Catalog er en metadatakoordineringstjeneste som sprer endringer fra Impala DDL- og DML-setninger til alle berørte Impala-noder, slik at nye tabeller eller nylastede data umiddelbart er synlige for enhver node i klyngen. Det anbefales at én forekomst av Catalog kjører på samme klyngevert som den statestorede demonen.
Hvordan fungerer Apache Impala
Impala, som Apache Hive, bruker et lignende deklarativt spørrespråk, Hive Query Language (HiveQL), som er en undergruppe av SQL92, i stedet for SQL.
Den faktiske utførelsen av forespørselen i Impala er som følger:
Klientapplikasjonen sender en SQL-spørring ved å koble til en hvilken som helst impalad gjennom standardiserte ODBC- eller JDBC-drivergrensesnitt. Den tilkoblede impaladen blir koordinator for gjeldende forespørsel.
SQL-spørringen analyseres for å bestemme oppgavene for impalad-forekomstene i klyngen; deretter bygges den optimale planen for utførelse av spørringer.
Impalad får direkte tilgang til HDFS og HBase ved å bruke lokale forekomster av systemtjenester for å levere data. I motsetning til Apache Hive, sparer en slik direkte interaksjon betydelig utføringstid for spørringer, ettersom mellomresultater ikke lagres.
Som svar returnerer hver demon data til den koordinerende impaladen, og sender resultatene tilbake til klienten.
Egenskaper til Impala
- Støtte for sanntidsbehandling i minnet
- SQL-vennlig
- Støtter lagringssystemer som HDFS, Apache HBase og Amazon S3
- Støtter integrasjon med BI-verktøy som Pentaho og Tableau
- Bruker HiveQL-syntaks
Apache Impala: Fordeler
Impala unngår mulig oppstartskostnader fordi alle systemdemonprosesser startes direkte ved oppstart. Det sparer betydelig tid for utføring av spørringer. En ytterligere økning i hastigheten til Impala er fordi dette SQL-verktøyet for Hadoop, i motsetning til Hive, ikke lagrer mellomresultater og får direkte tilgang til HDFS eller HBase.
I tillegg genererer Impala programkode ved kjøretid og ikke ved kompilering, slik Hive gjør. En bieffekt av Impalas høyhastighetsytelse er imidlertid redusert pålitelighet.
Spesielt hvis datanoden går ned under kjøringen av en SQL-spørring, vil Impala-forekomsten starte på nytt, og Hive vil fortsette å holde en tilkobling til datakilden, noe som gir feiltoleranse.
Andre fordeler med Impala inkluderer innebygd støtte for en sikker nettverksautentiseringsprotokoll Kerberos, prioritering og muligheten til å administrere køen av forespørsler og støtte for populære Big Data-formater som LZO, Avro, RCFile, Parquet og Sequence.
Hive vs Impala: likheter
Hive og Impala distribueres fritt under Apache Software Foundation-lisensen og refererer til SQL-verktøy for arbeid med data lagret i en Hadoop-klynge. I tillegg bruker de også det distribuerte HDFS-filsystemet.
Impala og Hive implementerer ulike oppgaver med felles fokus på SQL-behandling av store data lagret i en Apache Hadoop-klynge. Impala har et SQL-lignende grensesnitt, som lar deg lese og skrive Hive-tabeller, og dermed muliggjøre enkel datautveksling.
Samtidig gjør Impala SQL-operasjoner på Hadoop ganske raske og effektive, og gjør det mulig å bruke denne DBMS-en i forskningsprosjekter for Big Data-analyse. Når det er mulig, jobber Impala med en eksisterende Apache Hive-infrastruktur som allerede er brukt til å utføre langvarige SQL-batch-spørringer.
Dessuten lagrer Impala sine tabelldefinisjoner i en metastore, en tradisjonell MySQL- eller PostgreSQL-database, dvs. på samme sted der Hive lagrer lignende data. Den lar Impala få tilgang til Hive-tabeller så lenge alle kolonner bruker Impalas støttede datatyper, filformater og komprimeringskodeker.
Hive vs Impala: Forskjeller

Programmeringsspråk
Hive er skrevet i Java, mens Impala er skrevet i C++. Impala bruker imidlertid også noen Java-baserte Hive UDF-er.
Brukssaker
Dataingeniører bruker Hive i ETL-prosesser (Extract, Transform, Load), for eksempel for langvarige batchjobber på store datasett, for eksempel i reiseaggregatorer og flyplassinformasjonssystemer. På sin side er Impala hovedsakelig beregnet på analytikere og dataforskere og brukes hovedsakelig i oppgaver som business intelligence.
Opptreden
Impala utfører SQL-spørringer i sanntid, mens Hive er preget av lav databehandlingshastighet. Med enkle SQL-spørringer kan Impala kjøre 6-69 ganger raskere enn Hive. Imidlertid håndterer Hive komplekse spørsmål bedre.
Latens/gjennomstrømning
Gjennomstrømningen til Hive er betydelig høyere enn for Impala. LLAP-funksjonen (Live Long and Process), som muliggjør hurtigbufring av spørringer i minnet, gir Hive god ytelse på lavt nivå.
LLAP inkluderer langsiktige systemtjenester (demoner), som lar deg samhandle direkte med HDFS-datanoder og erstatte den tett integrerte DAG-spørringsstrukturen (Directed acyclic graph) – en grafmodell som brukes aktivt i Big Data-databehandling.
Feiltoleranse
Hive er et feiltolerant system som bevarer alle mellomresultater. Det påvirker også skalerbarheten positivt, men fører til en reduksjon i databehandlingshastigheten. På sin side kan Impala ikke kalles en feiltolerant plattform fordi den er mer minnebundet.
Kodekonvertering
Hive genererer spørringsuttrykk ved kompilering, mens Impala genererer dem under kjøring. Hive er preget av et «kaldstart»-problem første gang applikasjonen startes; spørringer konverteres sakte på grunn av behovet for å etablere en tilkobling til datakilden.
Impala har ikke denne typen oppstartskostnader. De nødvendige systemtjenestene (demoner) for å behandle SQL-spørringer startes ved oppstart, noe som fremskynder arbeidet.
Oppbevaringsstøtte
Impala støtter formatene LZO, Avro og Parkett, mens Hive fungerer med ren tekst og ORC. Begge støtter imidlertid formatene RCFIle og Sequence.
Apache HiveApache ImpalaLanguage JavaC++ Bruk CasesData Engineering Analyse og analyseYtelseHøy for enkle spørringer Forholdsvis lav LatencyMer ventetid på grunn av cachingMindre latent FeiltoleranseMere tolerant på grunn av MapReduceMindre tolerant på grunn av MPPConversionStartSlow på grunn av kaldO,AvcL-konvertering,Støtte for kaldO,O,O,Som
Siste ord
Hive og Impala konkurrerer ikke, men utfyller hverandre effektivt. Selv om det er betydelige forskjeller mellom de to, er det også ganske mye til felles, og å velge den ene fremfor den andre avhenger av dataene og de spesielle kravene til prosjektet.
Du kan også utforske head-to-head sammenligninger mellom Hadoop og Spark.
.