
Prometheus er et åpen kildekode, metrikkbasert overvåkingssystem. Den samler inn data fra tjenester og verter ved å sende HTTP-forespørsler på metriske endepunkter. Den lagrer deretter resultatene i en tidsseriedatabase og gjør den tilgjengelig for analyse og varsling.
Innholdsfortegnelse
Hvorfor overvåke?
- Aktiverer varsler når ting går galt, helst før det går galt. Slik at noen kan se på det.
- Det gir innsikt for å muliggjøre analyse, feilsøking og løsning av problemet.
- Den lar deg se trender/endringer over tid. For eksempel hvor mange aktive økter til enhver tid. Dette hjelper i designbeslutninger og kapasitetsplanlegging.
Overvåking er vanligvis knyttet til hendelser. En hendelse kan omfatte å motta en HTTP-forespørsel, sende et svar, lese fra disk, en brukerpålogging. Overvåking av et system kan omfatte profilering, logging, sporing, beregninger, varsling og visualisering.
Blackbox vs. Whitebox-overvåking
Overvåking faller inn under to hovedkategorier:
Blackbox-overvåking
I Blackbox-overvåking er overvåkingen på applikasjons- eller vertsnivå ettersom de observeres fra utsiden. Dette kan være ganske begrensende.
Whitebox-overvåking
Whitebox-overvåking betyr å overvåke det indre av en tjeneste. Det vil avsløre data om tilstanden og ytelsen til de interne komponentene.
De fire gylne signalene
Ifølge Googlehvis du bare kan måle fire beregninger av ditt brukervendte system, fokusere på følgende fire, kalt de fire gyldne signalene:
#1. Ventetid
Tiden det tar å levere en forespørsel – vellykket eller mislykket. Det er viktig å spore ikke bare vellykkede forespørsler, men også mislykkede.
#2. Trafikk
Et mål på hvor mye etterspørsel som stilles til systemet ditt. For en nettjeneste er dette vanligvis HTTP-forespørsler per sekund.
#3. Feil
Frekvensen av forespørsler som mislykkes.
#4. Metning
Hvor full tjenesten din er. Latensøkning er ofte en viktig indikator på metning. Mange systemer forringes i ytelse mye før de oppnår 100 % utnyttelse.
Prometheus metrikktyper
Prometheus-målinger er av fire hovedtyper:
#1. Disk
Verdien av en teller vil alltid øke. Den kan aldri reduseres, men den kan tilbakestilles til null. Så hvis en skraping mislykkes, betyr det bare et tapt datapunkt. Den kumulative økningen vil være tilgjengelig ved neste lesing. Eksempler:
- Totalt antall mottatte HTTP-forespørsler
- Antall unntak.
#2. Måler
En måler er et øyeblikksbilde på et gitt tidspunkt. Det kan både øke eller redusere. Hvis en datahenting mislykkes, mister du en prøve; neste henting kan vise en annen verdi: eksempler på diskplass, minnebruk.
#3. Histogram
Et histogram prøver observasjoner og teller dem i konfigurerbare bøtter. De brukes til ting som forespørselsvarighet eller svarstørrelser. Du kan for eksempel måle forespørselsvarigheten for en spesifikk HTTP-forespørsel. Histogrammet vil ha et sett med bøtter, for eksempel 1 ms, 10 ms og 25 ms. I stedet for å lagre hver varighet for hver forespørsel, vil Prometheus lagre frekvensen av forespørsler som faller inn i en bestemt bøtte.
#4. Sammendrag
I likhet med histogramprøveobservasjoner, forespør vanligvis varigheter eller svarstørrelser. Det vil gi en total telling av observasjoner og en sum av alle observerte verdier, slik at du kan beregne gjennomsnittet av observerte verdier. For eksempel, på ett minutt hadde du tre forespørsler som tok 2,3,4 sekunder. Summen vil være 9, og antallet vil være 3. Latensen vil være 3 sekunder.
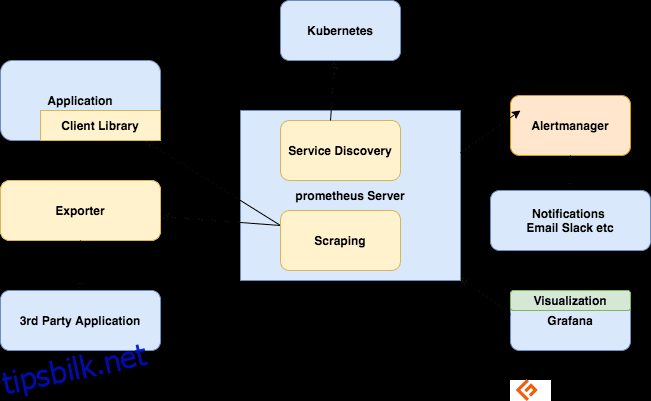
Komponenter av Prometheus-økosystemet
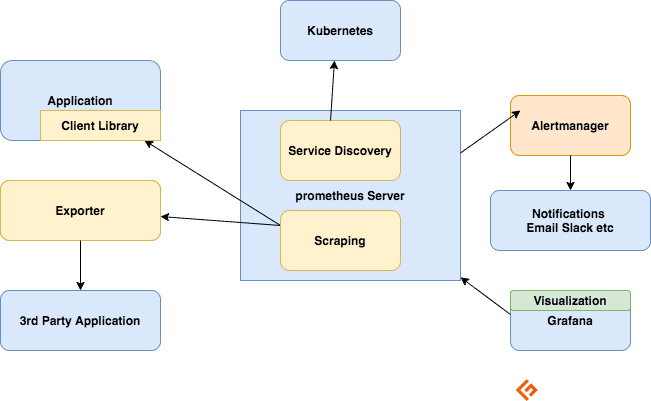
Prometheus-serveren
Samler inn beregninger, lagrer dem og gjør dem tilgjengelige for søk, sender varsler basert på innsamlede beregninger.
Skraping
Prometheus er et pull-basert system. For å hente beregninger, sender Prometheus en HTTP-forespørsel kalt en skrap. Den sender skraper til mål basert på konfigurasjonen.
Hvert mål (statisk definert, eller dynamisk oppdaget) skrapes med et regelmessig intervall (skrapeintervall). Hver skrap leser /metrics HTTP-endepunktet for å få den nåværende tilstanden til klientberegningene og opprettholder verdiene i Prometheus-tidsseriedatabasen.
Det er flere tidsseriedatabaser for overvåkingsløsninger du kanskje vil utforske.
Klientbiblioteker
For å overvåke en tjeneste, må du legge til instrumentering i koden din. Det er klientbiblioteker tilgjengelig for alle populære språk og kjøretider. Ved å bruke disse bibliotekene, når du legger til noen få linjer med kode, kan koden din begynne å sende ut beregninger. Dette kalles direkte instrumentering. Disse bibliotekene lar deg definere interne beregninger og også eksponere dem via et HTTP-endepunkt. Når Prometheus skraper metrikkene HTTP-endepunkt, sender klientbiblioteket metrikkene til serveren.
Offisielle klientbiblioteker tilbys av Prometheus for Go, Java, Python og Ruby. Prometheus har et åpent økosystem. Det finnes også fellesskapsbygde klientbiblioteker tilgjengelig for C, PHP, Node.js, C#/.NET og mange andre.
Eksportører
Mange applikasjoner viser beregninger i ikke-Prometheus-format. For disse og for applikasjoner du ikke eier eller som du ikke har tilgang til kode for, kan du ikke legge til instrumentering direkte. For eksempel MySQL, Kafka, JMX, HAProxy og NGINX server. I disse scenariene bruker du eksportører.
En eksportør er et verktøy du distribuerer sammen med applikasjonen du vil ha beregninger fra. En eksportør fungerer som en proxy mellom applikasjonen og Prometheus. Den vil motta forespørsler fra Prometheus-serveren, samle inn data fra tilgangsloggene, feilloggene til applikasjonen, transformere den til riktig format og til slutt gå tilbake til Prometheus-serveren.
Noen av de populære eksportørene er:
- Windows – for Windows-serverberegninger
- Node – for Linux-serverberegninger
- Svart boks – for DNS- og nettstedytelsesmålinger
- JMX – for Java-baserte applikasjonsberegninger
Når applikasjonene har blitt instrumentert, eller eksportørene er på plass, må du fortelle Prometheus hvor de er. Dette kan gjøres ved hjelp av statisk konfigurasjon. Ved dynamiske miljøer kan dette ikke gjøres; derfor benyttes tjenesteoppdagelse.
Varsler
Varsling med Prometheus består av to deler –
Varslingsregler sender varsler til Alertmanager.
Alertmanager administrerer deretter disse varslene. Den sender ut varsler ved å bruke mange ut-av-boksen integrasjoner som e-post, Slack, Hipchat og PagerDuty. Alertmanageren kan også utføre lyddemping eller aggregering for å redusere antall varsler.
Her er guiden for å overvåke Linux-serveren ved hjelp av Prometheus og Dashboard.
Visualisere med Dashboards
Prometheus har en rekke APIer som bruker PromQL-spørringer til å produsere rådata for visualiseringer.
Selv om Prometheus inkluderer en uttrykksnettleser som kan brukes til ad-hoc-spørringer, er det beste tilgjengelige verktøyet Grafana. Grafana integreres fullt ut med Prometheus og kan produsere et bredt utvalg av dashbord.
Du må konfigurere Prometheus som datakilde for Grafana.
Du kan legge til dashboards ved å:
- Importerer fellesskapsbygde instrumentbord
- Bygg din egen
- Bruke et forhåndsdefinert dashbord.
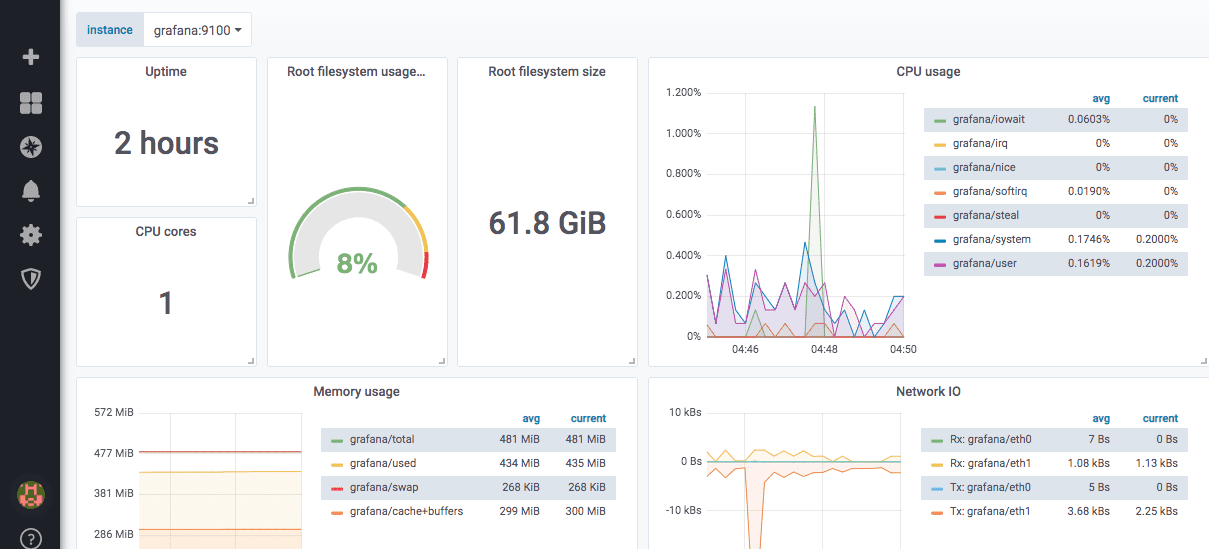
Slik ser et forhåndsdefinert nodeeksportør-dashbord ut:
Grafana har en worldPing-modul som lar deg overvåke nettsted- og DNS-ytelsesmålinger over hele verden.
Sammendrag
Prometheus har svært få krav. Det kan være ganske enkelt å kjøre siden det er en enkelt binær med en konfigurasjonsfil. Den kan håndtere tusenvis av mål og innta millioner av prøver per sekund. Prometheus er designet for å spore systemets generelle system, helse, oppførsel.
Grafana er det beste verktøyet tilgjengelig for visualisering av beregninger og integreres sømløst med Prometheus.