

Amazon Glue blir stadig mer populær fordi mange selskaper har begynt å bruke tjenester for administrerte dataintegrering.
ETL er en prosess som overfører data fra en kildedatabase til et datavarehus. ETL er kompleks og vanskelig å implementere for alle bedriftsdata på grunn av kompleksiteten. Amazon introduserte AWS Glue for å løse dette problemet.
ETL-utviklere og dataingeniører bruker Glue til å bygge, overvåke og kjøre ETL-arbeidsflyter.
Innholdsfortegnelse
Hva er AWS-lim?
AWS Glue, en serverløs dataintegrasjonstjeneste, gjør det enkelt å finne, forberede, flytte og integrere data fra flere kilder. Dette er nyttig for maskinlæring (ML) og analyse.
Det reduserer dramatisk tiden det tar å forberede dataene for analyse. Den finner og lister opp dataene automatisk, genererer Scala- eller Python-kode for å overføre dataene fra kilden, og laster og transformerer jobben i henhold til de tidsbestemte hendelsene.
Dette gir mulighet for fleksibel planlegging og skaper et Apache Spark-miljø som kan skaleres for målrettet datalasting. I tillegg gir AWS Glue kompleks datastrømovervåking og endring. AWS Glue er en serverløs tjeneste som forenkler applikasjonsutviklingens kompliserte operasjoner.
Det gir mulighet for rask integrering av flere gyldige data. Den bryter også ned og autoriserer data raskt.
Hva brukes AWS-lim til?
Det er viktig å vite de beste stedene å bruke Amazon Glue. Dette er bare noen få eksempler på AWS Glue-bruk du bør vurdere.
- Glue er et verktøy som lar deg kjøre serverløse spørringer på Amazon S3-datainnsjøene. Amazon Glue er et flott verktøy for å komme i gang. Den gjør alle dataene dine tilgjengelige i ett grensesnitt, slik at du kan analysere dem uten å måtte flytte dem.
- Amazon Glue kan brukes til å forstå datamidlene dine. Amazon Glue gjør det enkelt for deg å søke i forskjellige AWS-datasett ved hjelp av datakatalogen. Du kan også lagre data på tvers av flere AWS-tjenester ved å bruke datakatalogen mens du fortsatt har en konsistent visning.
- Lim kan være nyttig når du bygger hendelsesdrevne ETL-arbeidsflyter. Du kan utføre ETL-operasjonene dine fra Amazon S3 ved å ringe Glue ETL-oppgavene dine via en AWS Lambda-tjeneste.
- AWS Glue kan også brukes til å rense, verifisere, formatere og organisere data for lagring i en datainnsjø eller et lager.
Hva er komponentene i AWS-lim?
Nedenfor er hovedkomponentene i AWS Glue:
- Datakatalog: Denne datakatalogen inneholder metadata og datastrukturen.
- Database: Dette er nøkkelen til å få tilgang til og opprette databasen for kilder og mål.
- Tabell: Lag en eller flere tabeller i databasen som kan brukes av både målet og kilden.
- Crawler og klassifisering: Crawleren henter data fra kilden ved å bruke enten innebygde eller tilpassede klassifikasjoner. Den oppretter/bruker forhåndsdefinerte metadatatabeller i datakatalogen.
- Jobb: Dette er jobben til forretningslogikk for å utføre en ETL-oppgave. Denne forretningslogikken er skrevet internt av Apache Spark ved bruk av python- og scala-språk.
- Trigger: En ETL-utløser er en enhet som initierer utførelse av en ETL-jobb på forespørsel eller på et bestemt tidspunkt.
- Endepunkt for utvikling: Dette skaper et miljø der ETL-jobbskriptet blir testet, utviklet og feilsøkt.
Fordeler med AWS-lim
Dette er fordelene ved å bruke det på din arbeidsplass eller i en organisasjon.
- AWS Glue skanner alle tilgjengelige data med en crawler.
- Endelig behandlet data kan lagres mange steder (Amazon RDS og Amazon Redshift, Amazon S3, etc.
- Det er en skybasert tjeneste. Det er ikke nødvendig å bruke penger på infrastruktur på stedet.
- Fordi det er en serverløs ETL, er det et kostnadseffektivt valg.
- Det er raskt. Den gir deg umiddelbart Python/Scala ETL-koden.
Toppfunksjoner til AWS Lim?
Amazon Glue har alle funksjonene du trenger for å integrere data slik at du kan få bedre innsikt og bruke kunnskapen din til å gjøre nye fremskritt i løpet av minutter i stedet for måneder. Her er noen av funksjonene du bør kjenne til.
- Dra og slipp-grensesnitt: En dra-og-slipp jobbredigerer lar deg lage en ETL-prosess. AWS Glue vil umiddelbart bygge koden som trengs for å trekke ut, konvertere og laste opp dataene.
- Automatisk Schema Discovery: For å lage crawlere som kobler til forskjellige datakilder, kan du bruke Glue-tjenesten. Den organiserer data og trekker ut relevant informasjon. Disse dataene kan deretter brukes til å overvåke ETL-prosesser ved ETL-oppgaver.
- Jobbplanlegging: Lim kan enten brukes på forespørsel eller i henhold til en planlagt tidsplan. Planleggeren kan brukes til å bygge komplekse ETL-rørledninger, og etablere avhengigheter mellom oppgaver.
- Kodegenerering: Glue Elastic Views lar deg enkelt lage materialiserte visninger som kombinerer og replikerer data fra forskjellige datakilder uten å måtte skrive noen proprietær kode.
- Innebygd maskinlæring: Lim kommer med en innebygd maskinlæringsfunksjon kalt «FindMatches». Den dedupliserer poster som ikke er perfekte kopier av hverandre.
- Utviklerendepunkter: Hvis du aktivt ønsker å utvikle ETL-koden din, gir Glue utviklerendepunkter som lar deg modifisere, feilsøke og teste koden den lager.
- Glue DataBrew: Det er et dataforberedelsesverktøy som kan brukes av dataanalytikere og dataforskere for å hjelpe dem med å rense og normalisere data. Den bruker Glue DataBrews aktive og visuelle grensesnitt.
Hvordan fungerer AWS limprising?
AWS Glue krever en timeavgift, som faktureres per sekund for crawlere (oppdage dataene) og ETL-jobber (behandling og lasting av data). En enkel månedlig avgift belastes for tilgang til og lagring av metadata i AWS Glue Data Catalog.
Amazon Glue starter på $0,44. Du kan velge mellom fire planer:
- ETL-oppgaver, utviklingsendepunkter og andre ETL-oppgaver er tilgjengelig for $0,44
- Crawlers interaktive økter er tilgjengelig for $0,44
- DataBrew-jobber starter på $0,48
- Månedlig lagring og forespørsler til datakatalogen koster $1,00
AWS tilbyr ikke en gratis Glue-plan. Hver time vil koste $0,44 per DPU. I gjennomsnitt vil det koste deg $21 per dag. Prisene kan variere avhengig av hvor du bor.
Trinn for å sette opp AWS Glue
Datakatalogen kan brukes til å raskt finne og søke i flere AWS-datasett uten å måtte flytte dataene. Etter at dataene er katalogisert, er de umiddelbart tilgjengelige for søk og søk ved hjelp av Amazon Athena og Amazon EMR.
 Ref: https://aws.amazon.com/glue/
Ref: https://aws.amazon.com/glue/
- Amazon Redshift, Amazon S3, Amazon RDS og databaser på Amazon EC2 – Oppdag dataene dine, lagre metadata og bruk AWS Glue Data Catalog for å oppdage dem
- AWS Glue Data Catalog – Administrer data med datakatalogen som fungerer som et sentralt depot for metadata
- AWS Glue ETL – Les og skriv metadata til datakatalogen din
- Amazon Athena og Amazon Redshift, Amazon EMR, Amazon ETL – Få datakatalogen for ETL, analyser og mer.
Hvordan konfigurere AWS Lim?
Først logger du på AWS Management Console og åpner IAM-konsollen. Klikk på Opprett rolle. For rolletype, finn Glue og velg Tillatelser.
Jeg velger AWSGlueServiceRole for generelle AWS Glue Studio- og AWS Glue-tillatelser og den AWS-administrerte policyen AmazonS3FullAccess for tilgang til Amazon S3-ressurser.
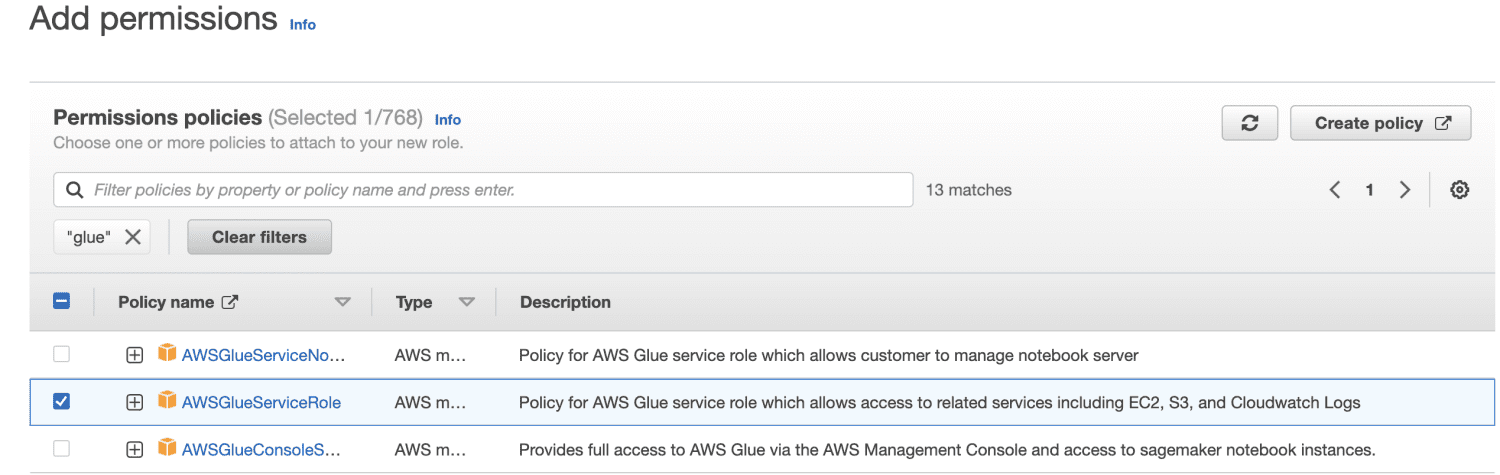
Skriv inn et rollenavn.
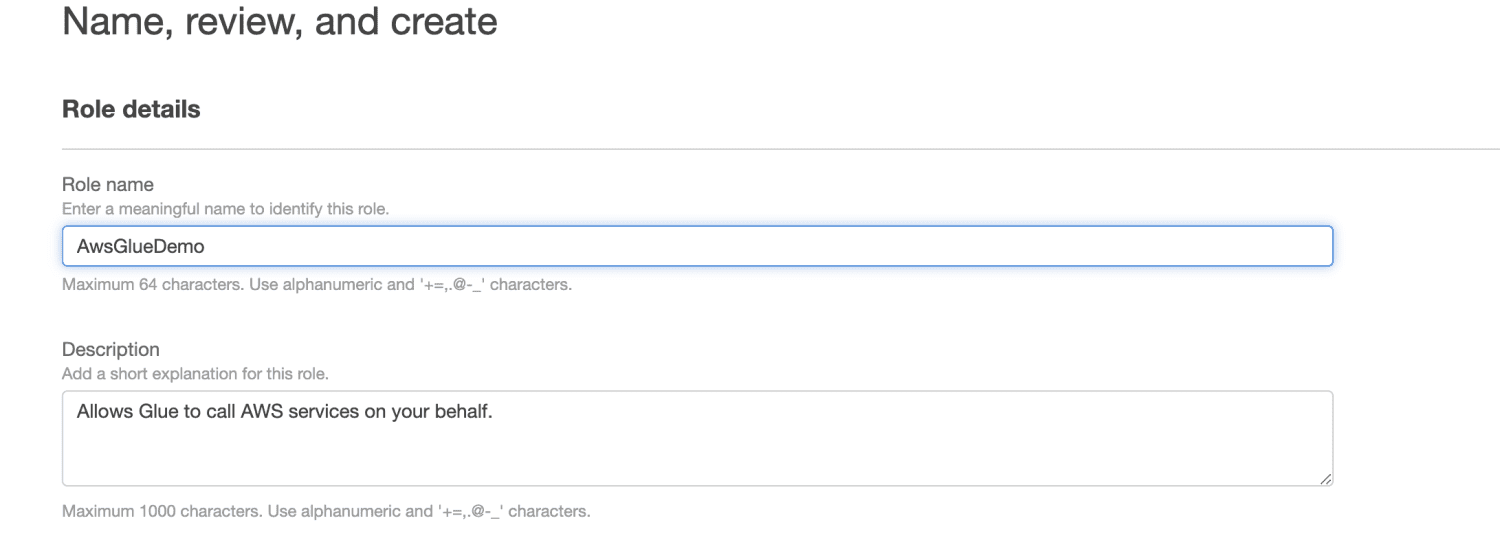
Klikk på Opprett rolle.
Lag en Amazon S3-bøtte.
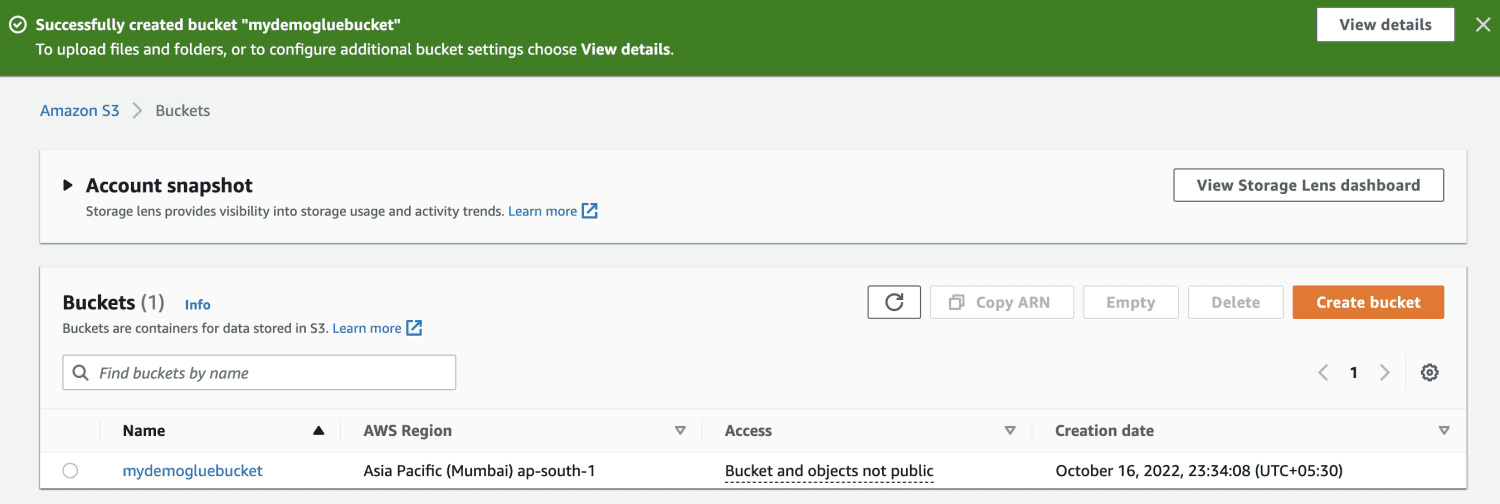
Lag en mappe inne i S3-bøtten.
Velg filen du vil laste opp.
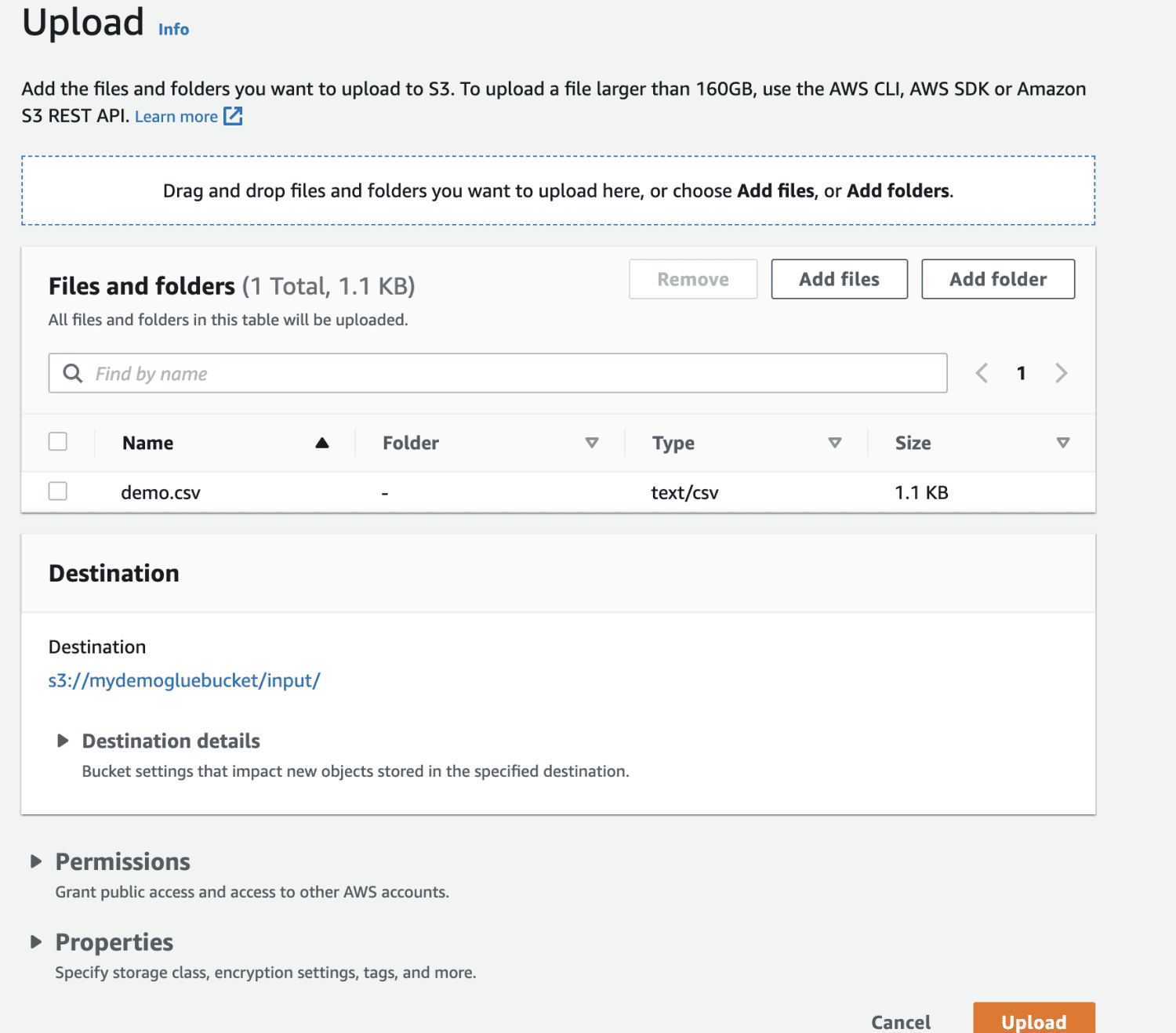
Til slutt laster du opp filen i bøtta.
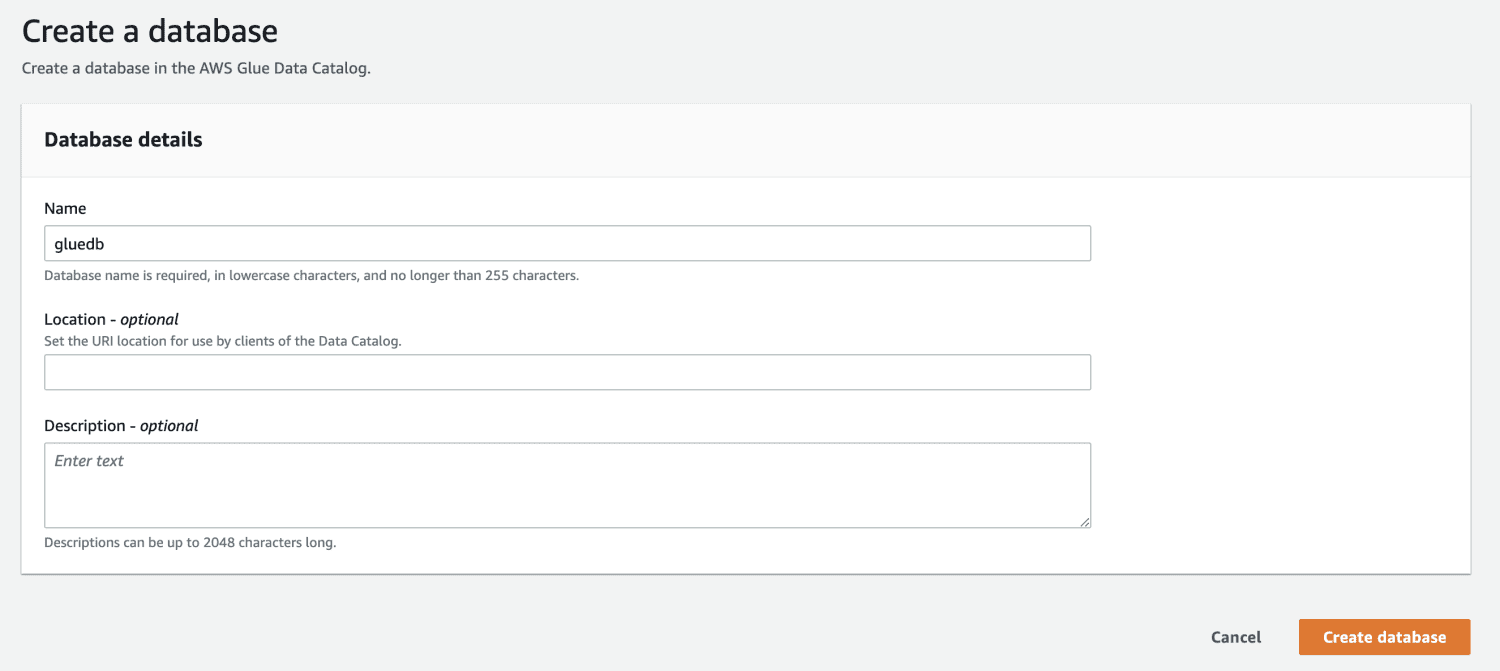
Deretter åpner du AWS Glue fra AWS-administrasjonskonsollen og oppretter en database.
Nå som du har en database i AWS Glue, lag en crawler.
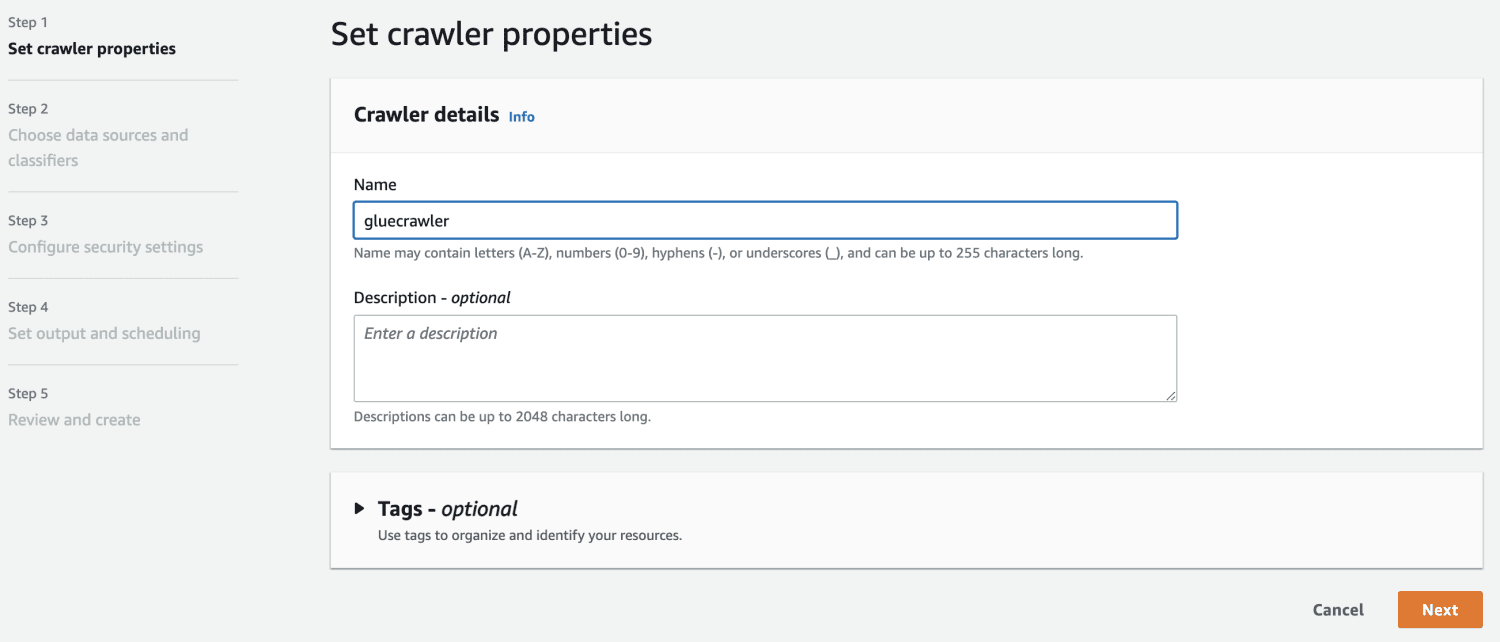
I datakilden velger du S3-bøtten du opprettet.
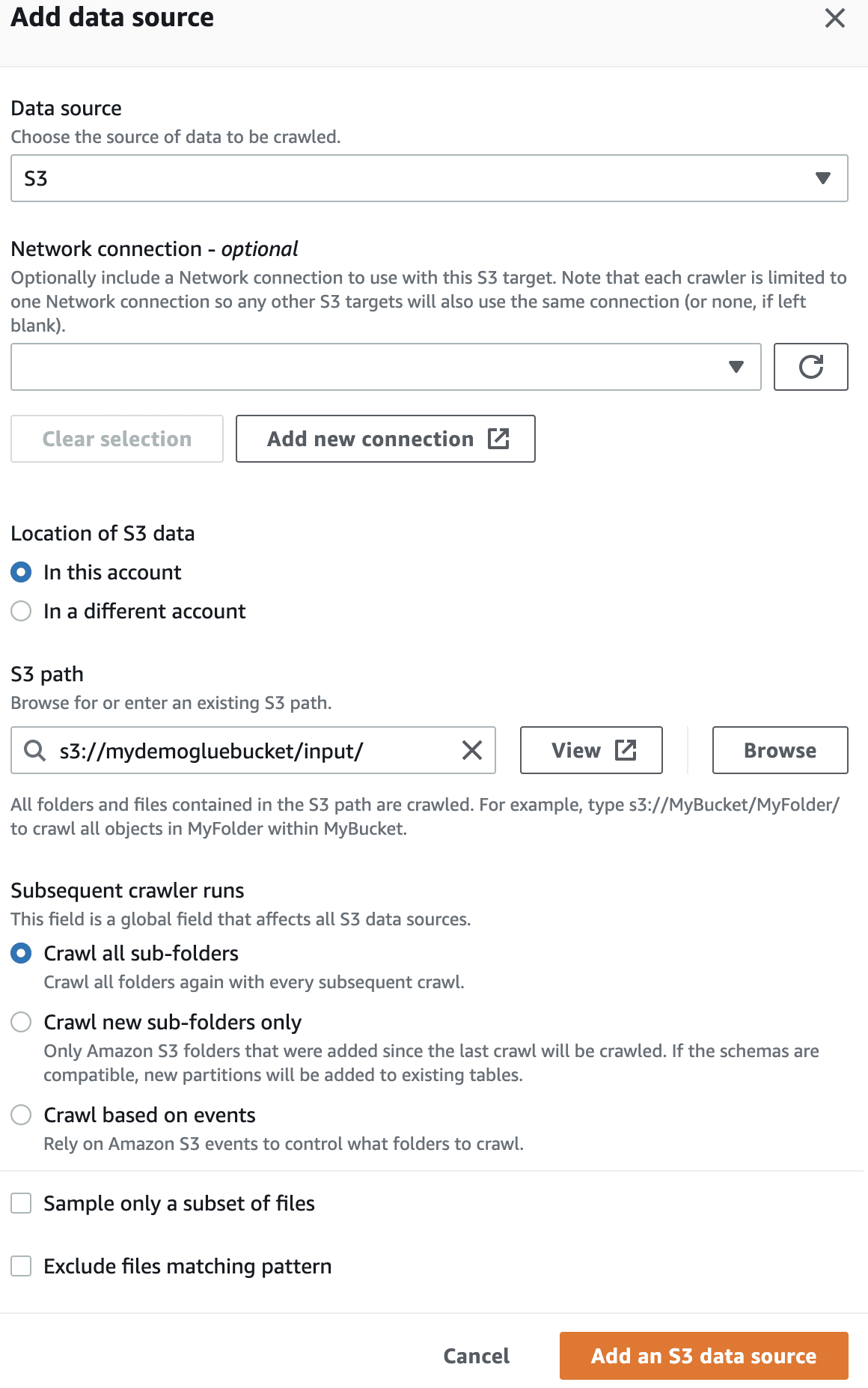
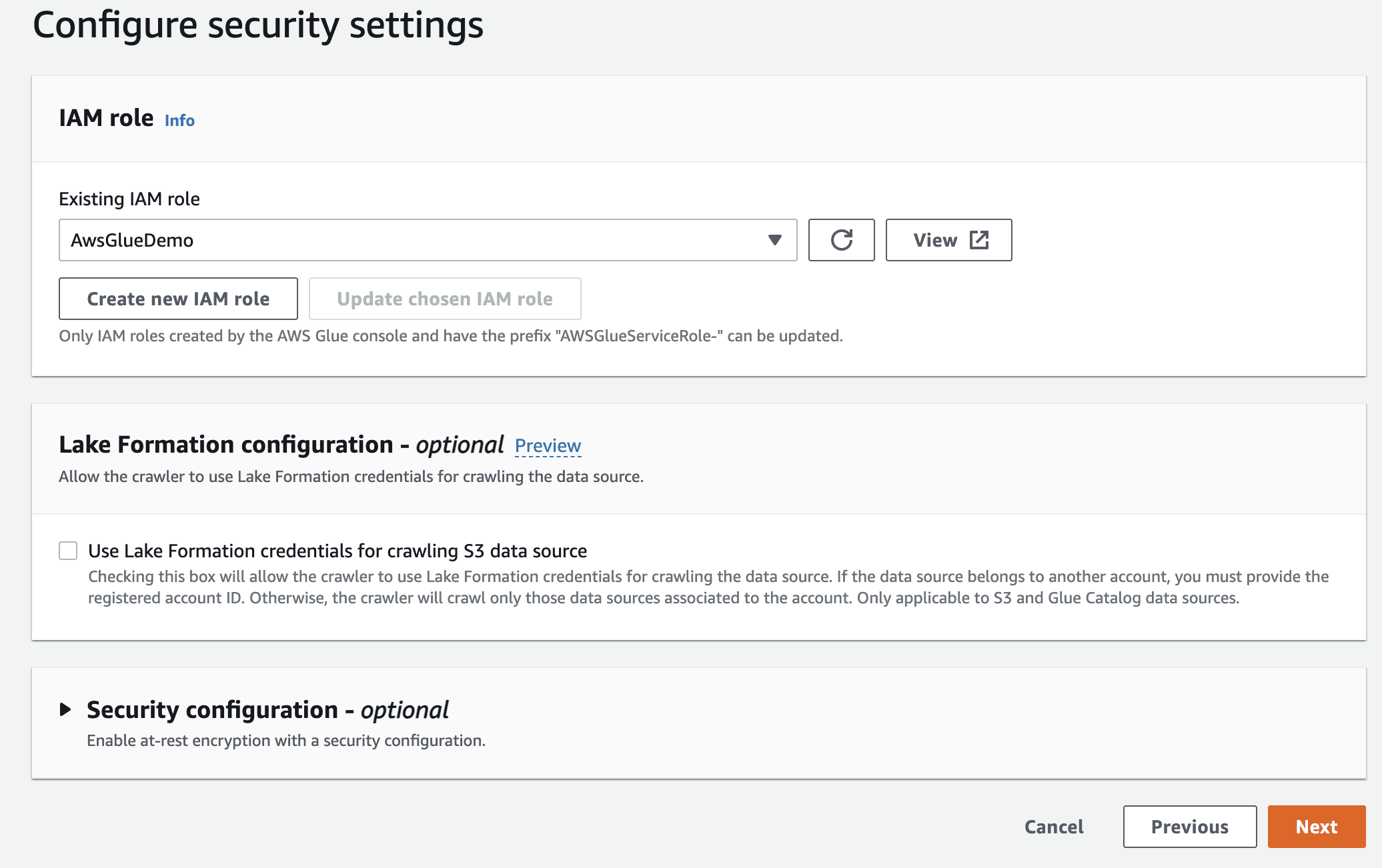
Deretter velger du IaM-rollen for AWS Glue som du opprettet i begynnelsen.
Til slutt, i utgangen, velg gluedb du opprettet.
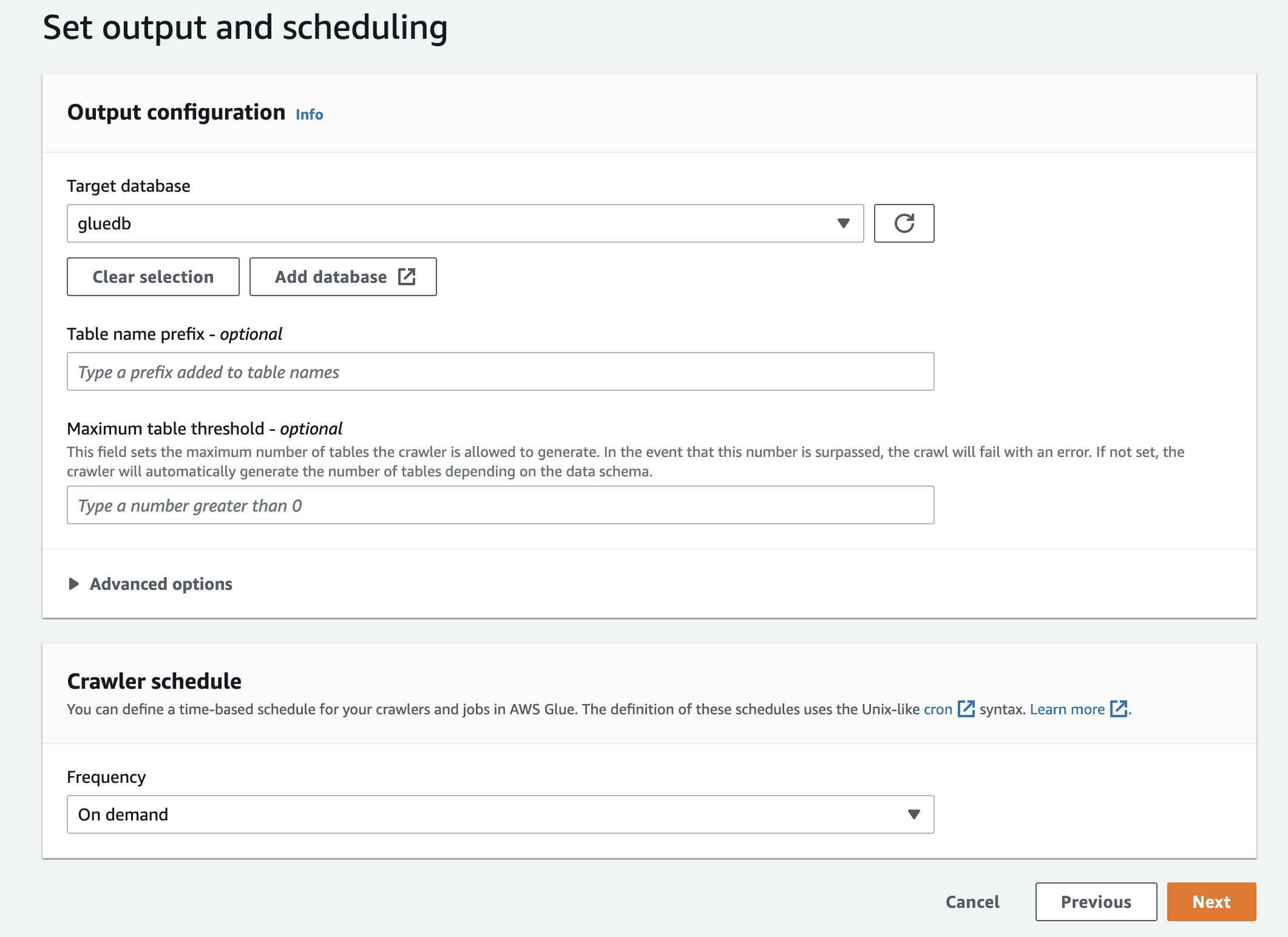
Se gjennom alle innstillingene og lag søkeroboten.
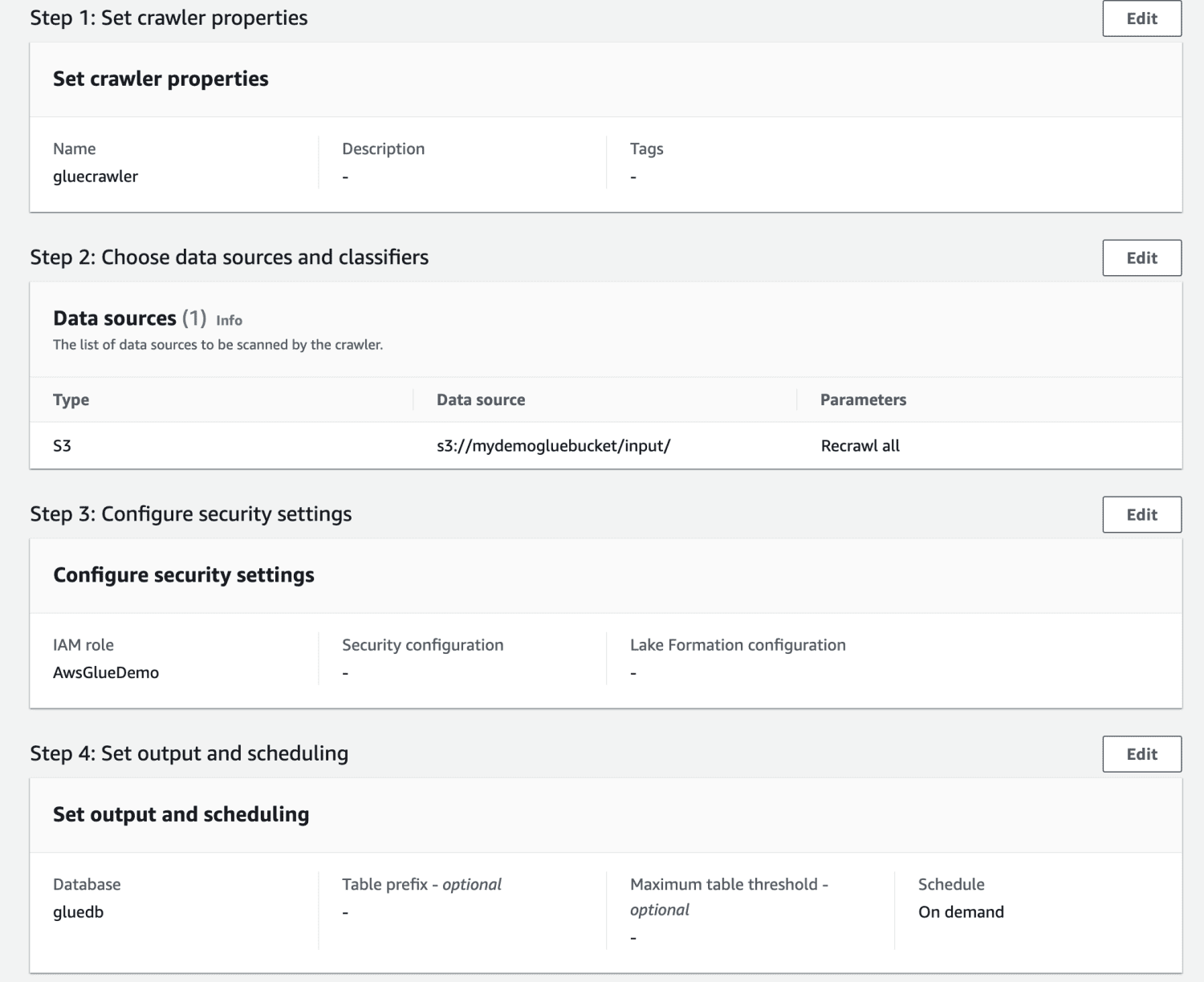
Når søkeroboten er opprettet, velger du den og klikker på Kjør. Etter en tid vil du få statusen klar.
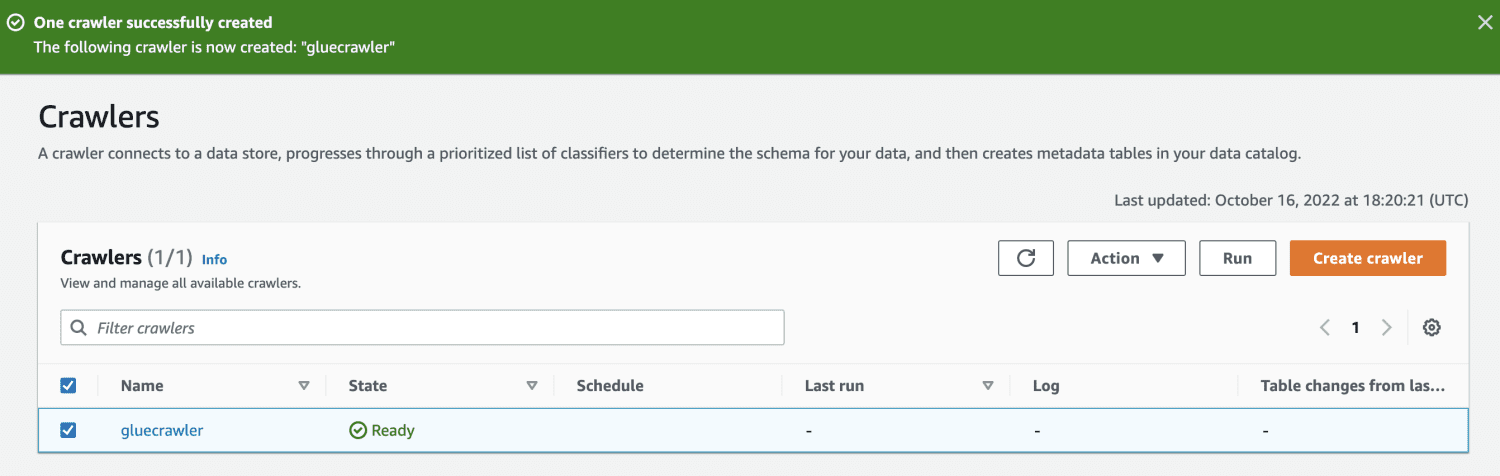
Ved å kjøre søkeroboten vil databasen få en tabell med alle dataene fra CSV-filen.
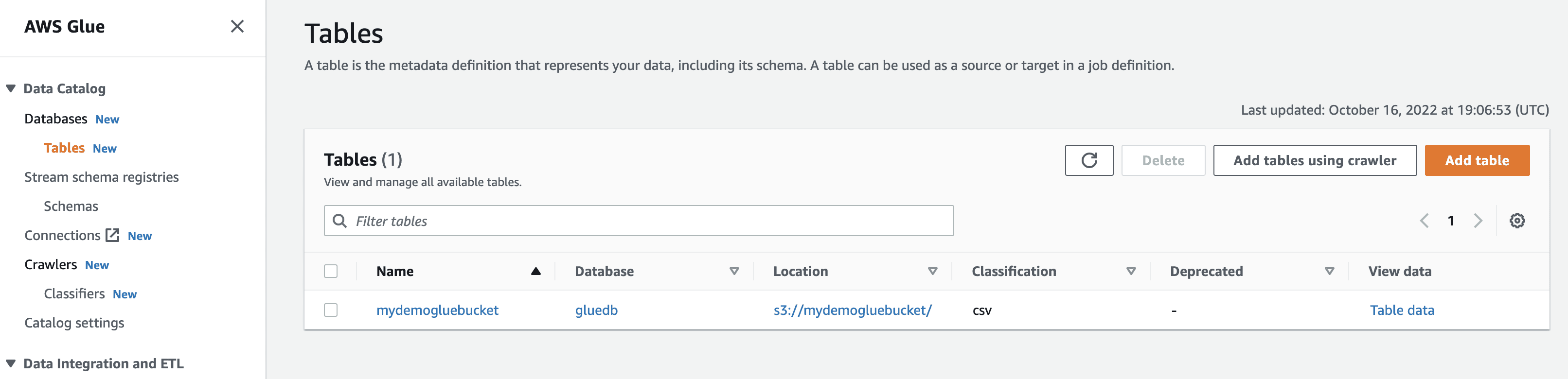
Når du klikker på vis data, blir du ført til Amazon Athena (spørringsredigering). Når du kjører spørringen, kan du se tabelldataene.
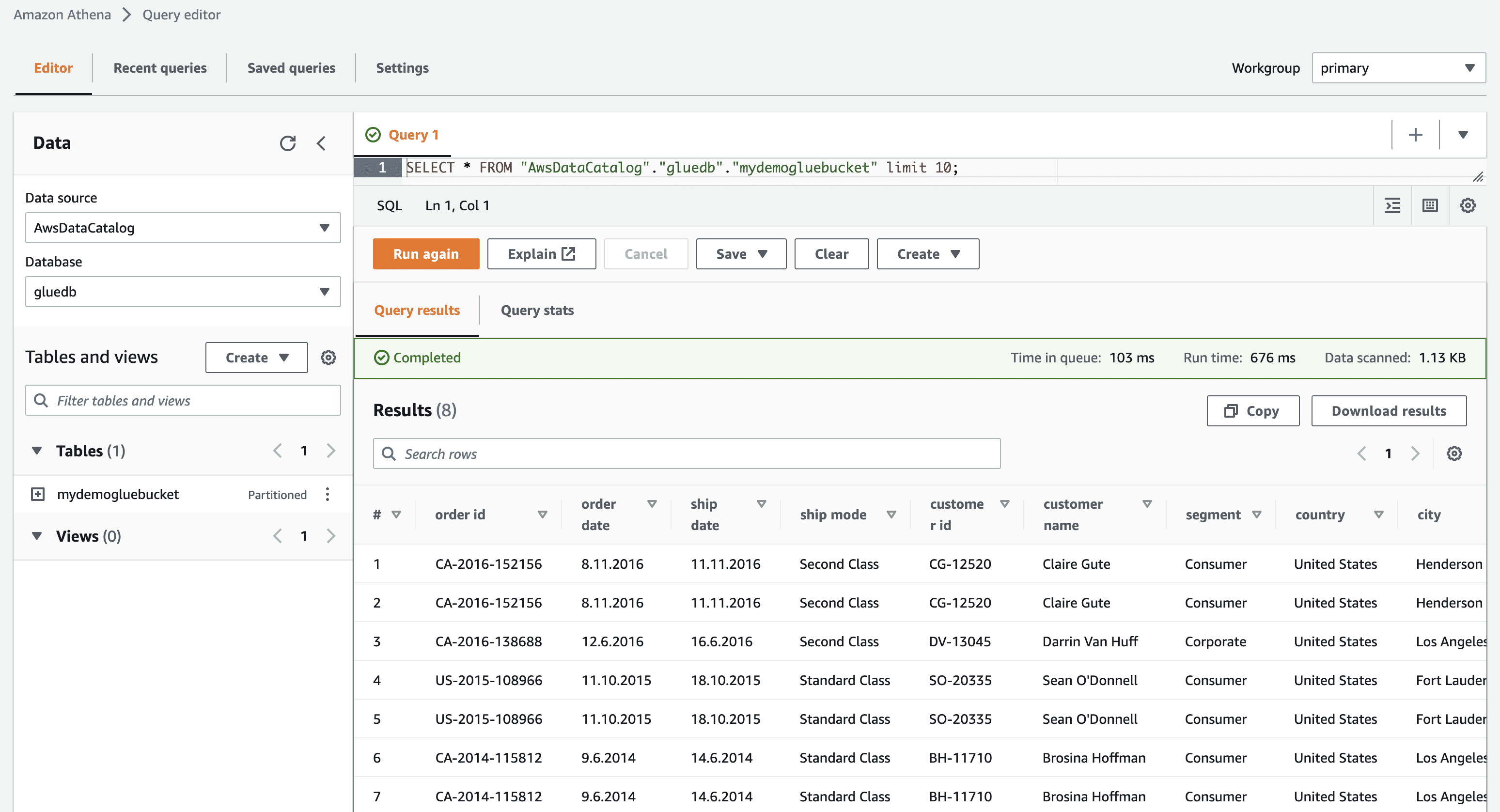
Nå kan du med hell bruke denne AWS Glue-crawleren i enhver ETL-jobb.
Hva er AWS Glue Databrew?
AWS Glue DataBrew lar brukere normalisere og rydde opp i data uten å skrive noen kode. DataBrew kan redusere tiden som kreves for å forberede data for maskinlæring og analyser med så mye som 80 prosent sammenlignet med spesialutviklet dataforberedelse.
Det er over 250 forhåndslagde datatransformasjoner som kan brukes til å automatisere dataklargjøringsoppgaver som å filtrere ut uregelmessigheter, korrigere ugyldige verdier og konvertere data til standardformater.
DataBrew gjør det enklere for dataforskere, forretningsanalytikere og ingeniører å samarbeide om å trekke ut innsikt fra rådata. DataBrew er serverløs, så du trenger ikke å administrere infrastruktur eller lage klynger for å utforske og transformere terabyte med rådata.
DataBrew-funksjoner for bedrifter
Visualisert dataforberedelse
DataBrew er en annen måte å vise data på som vanligvis vises i kolonneformede databaser som alfanumeriske tall. DataBrew visualiserer alle innlastede datakilder for å hjelpe deg med å forstå datarelasjonene og hierarkiet.
250+ dataforberedelsesautomatiseringer
Dataforskere forventes å følge en rekke repeterbare, isolerte arbeidsflyter som en del av jobben deres. Disse arbeidsflytene og prosessene har blitt modellert av AWS som språk- og dataagnostiske modulmoduler. Dette biblioteket inkluderer handlinger som kan brukes av sluttbrukere.
Dataavstamning
I likhet med revisjonslogger som brukes til å spore kundeaktivitet i et IT-nettverks IT-nettverk, lar datalinje deg spore datatransformasjonsaktivitetene i AWS DataBrew. Denne informasjonen inkluderer datakilden, transformasjonene som ble brukt og datautgangen, inkludert målplasseringen.
Datakartlegging
Databrew lar deg finne samsvarende felt i to datakilder. Når samsvarende felt er identifisert, kan de lastes inn i et skjema.
AWS Glue DataBrew: Fordeler
Nedenfor er funksjonene til AWS Glue DataBrew:
- Senk barriere for oppføring for dataforberedelse
- Automatisert dataprofilgenerering
- Automatiser 250+ dataforberedelsesprosesser
- Intelligente reseptbelagte forslag
Alternativer til AWS Lim
Luftstrøm
Luftstrøm tilhører delen Workflow Manager i en teknologistabel. Det er et åpen kildekodeverktøy som støtter GitHub-stjerner, GitHub-gafler og andre funksjoner. Airflow lar deg lage arbeidsflyter ved å bruke dirigerte asykliske diagrammer (DAGs). Airflow-planlegger utfører oppgavene dine ved å bruke en rekke arbeidere og følger de spesifiserte avhengighetene.
Matillion

Matillion ETL, et ETL/ELT-verktøy, ble designet eksplisitt for skydatabaseplattformer som Amazon Redshift og Google BigQuery. Det er et moderne nettleserbasert brukergrensesnitt med kraftige push-down ETL/ELT-funksjoner. Du kan være i gang på få minutter med et raskt oppsett.
Sting
Stitch er en åpen kildekode ETL-tjeneste som kobler sammen flere datakilder og replikerer data til foretrukne destinasjoner. Det er veldig enkelt å bruke, siden du ikke trenger noen kodekunnskap for å flytte data mellom kilder og destinasjoner i Stitch. Den er enkel å bruke, har en vennlig GUI, og den er rask.
Stitch lar deg ikke velge et ferdiglaget dashbord, i motsetning til andre ETL-verktøy. I stedet må du integrere dataene dine i de åpne datavarehusene du velger som destinasjon. Det kan være vanskelig å navigere i varelageret.
Alteryx

Alteryx er en analytisk automatiseringsplattform som hjelper med forberedelse og blanding av datainnsamling. Disse dataene kan brukes til å fremskynde prosesser og gi forretningsinnsikt. Fordi det er et dra-og-slipp-verktøy, trenger du ingen programmeringskunnskap. Alteryx er et flott sted å gå for råd og svar fra bransjefolk.
Konklusjon
Så det handlet om AWS Glue, som er en skybasert løsning som lar deg jobbe med ETL-rørledninger. For å oppsummere består AWS Glue-brukerinteraksjonsprosessen av tre faser. For å lage en datakatalog bruker du først datasøkeprogrammer. Deretter oppretter du ETL-koden som kreves av AWS-datapipeline. Til slutt opprettes ETL-planen. Jeg håper denne bloggen ga deg en god oversikt over Amazon Glue.
Du kan også utforske de beste tipsene for å sikre AWS S3-lagring.