
Hvis du vil slå sammen data fra to tekstfiler ved å matche et felles felt, kan du bruke kommandoen Linux join. Det gir et dryss av dynamikk til de statiske datafilene dine. Vi viser deg hvordan du bruker den.
Innholdsfortegnelse
Matchende data på tvers av filer
Data er konge. Både selskaper, bedrifter og husholdninger kjører på det. Men data som er lagret i forskjellige filer og samlet av forskjellige personer, er en smerte. I tillegg til å vite hvilke filer du skal åpne for å finne informasjonen du vil ha, vil oppsettet og formatet på filene sannsynligvis være annerledes.
Du må også håndtere den administrative hodepinen for hvilke filer som må oppdateres, hvilke som må sikkerhetskopieres, hvilke som er eldre og hvilke som kan arkiveres.
I tillegg, hvis du trenger å konsolidere dataene dine eller utføre noen analyser på tvers av et helt datasett, har du et ekstra problem. Hvordan rasjonaliserer du dataene på tvers av de forskjellige filene før du kan gjøre det du trenger å gjøre med dem? Hvordan går du an til dataforberedelsesfasen?
Den gode nyheten er at hvis filene deler minst ett felles dataelement, kan Linux join-kommandoen trekke deg ut av myra.
Datafilene
Alle dataene vi skal bruke for å demonstrere bruken av join-kommandoen er fiktive, og starter med følgende to filer:
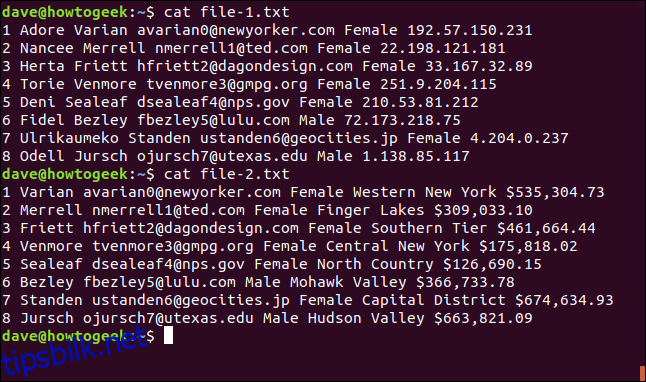
cat file-1.txt
cat file-2.txt
Følgende er innholdet i file-1.txt:
1 Adore Varian [email protected] Female 192.57.150.231 2 Nancee Merrell [email protected] Female 22.198.121.181 3 Herta Friett [email protected] Female 33.167.32.89 4 Torie Venmore [email protected] Female 251.9.204.115 5 Deni Sealeaf [email protected] Female 210.53.81.212 6 Fidel Bezley [email protected] Male 72.173.218.75 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 8 Odell Jursch [email protected] Male 1.138.85.117
Vi har et sett med nummererte linjer, og hver linje inneholder all følgende informasjon:
Et tall
Et fornavn
Et etternavn
En e-postadresse
Personens kjønn
En IP-adresse
Følgende er innholdet i fil-2.txt:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93 8 Jursch [email protected] Male Hudson Valley $663,821.09
Hver linje i file-2.txt inneholder følgende informasjon:
Et tall
Et etternavn
En e-postadresse
Personens kjønn
En region i New York
En dollarverdi
Kommandoen fungerer med «felt», som i denne sammenheng betyr en tekstdel omgitt av mellomrom, starten på en linje eller slutten av en linje. For at sammenføyning skal samsvare med linjer mellom de to filene, må hver linje inneholde et felles felt.
Derfor kan vi bare matche et felt hvis det vises i begge filene. IP-adressen vises bare i én fil, så det er ikke bra. Fornavnet vises bare i én fil, så det kan vi heller ikke bruke. Etternavnet er i begge filene, men det ville være et dårlig valg, siden forskjellige personer har samme etternavn.
Du kan heller ikke knytte dataene sammen med mannlige og kvinnelige oppføringer, fordi de er for vage. Regionene i New York og dollarverdiene vises også bare i én fil.
Vi kan imidlertid bruke e-postadressen fordi den finnes i begge filene, og hver er unik for en person. En rask titt gjennom filene bekrefter også at linjene i hver tilsvarer samme person, slik at vi kan bruke linjenumrene som vårt felt for å matche (vi bruker et annet felt senere).
Legg merke til at det er et forskjellig antall felt i de to filene, noe som er greit – vi kan fortelle hvilket felt som skal brukes fra hver fil.
Se imidlertid opp for felt som regionene i New York; i en mellomromseparert fil ser hvert ord i navnet på en region ut som et felt. Fordi noen regioner har to- eller treordsnavn, har du faktisk et annet antall felt i samme fil. Dette er greit, så lenge du matcher på felt som vises på linjen før New York-regionene.
Delta-kommandoen
Først må feltet du skal matche sorteres. Vi har stigende tall i begge filene, så vi oppfyller de kriteriene. Som standard bruker join det første feltet i en fil, som er det vi ønsker. En annen fornuftig standard er at join forventer at feltseparatorene er mellomrom. Igjen, vi har det, så vi kan gå videre og fyre opp med å bli med.
Siden vi bruker alle standardinnstillingene, er kommandoen vår enkel:
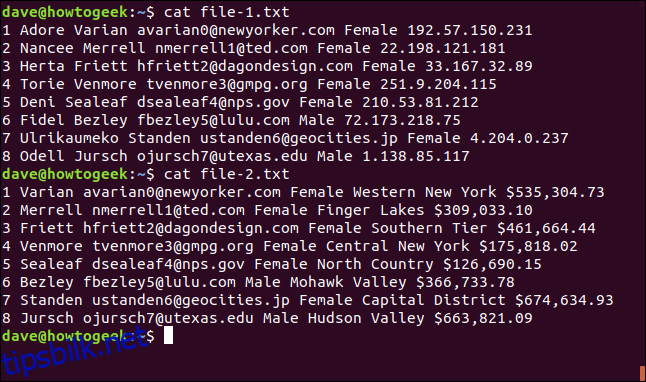
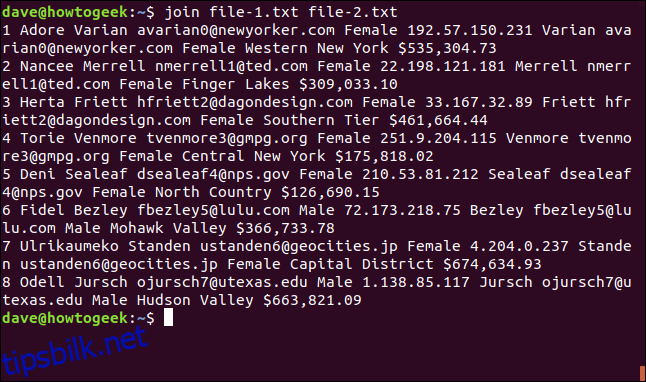
join file-1.txt file-2.txt
join anser filene som «fil en» og «fil to» i henhold til rekkefølgen de er oppført på kommandolinjen.
Utgangen er som følger:
1 Adore Varian [email protected] Female 192.57.150.231 Varian [email protected] Female Western New York $535,304.73 2 Nancee Merrell [email protected] Female 22.198.121.181 Merrell [email protected] Female Finger Lakes $309,033.10 3 Herta Friett [email protected] Female 33.167.32.89 Friett [email protected] Female Southern Tier $461,664.44 4 Torie Venmore [email protected] Female 251.9.204.115 Venmore [email protected] Female Central New York $175,818.02 5 Deni Sealeaf [email protected] Female 210.53.81.212 Sealeaf [email protected] Female North Country $126,690.15 6 Fidel Bezley [email protected] Male 72.173.218.75 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 Standen [email protected] Female Capital District $674,634.93 8 Odell Jursch [email protected] Male 1.138.85.117 Jursch [email protected] Male Hudson Valley $663,821.09
Utdataene formateres på følgende måte: Feltet linjene ble matchet på skrives ut først, etterfulgt av de andre feltene fra fil én, og deretter feltene fra fil to uten samsvarsfeltet.
Usorterte felt
La oss prøve noe vi vet ikke vil fungere. Vi legger linjene i én fil ute av rekkefølge, så join vil ikke kunne behandle filen riktig. Innholdet i fil-3.txt er det samme som fil-2.txt, men linje åtte er mellom linje fem og seks.
Følgende er innholdet i file-3.txt:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 8 Jursch [email protected] Male Hudson Valley $663,821.09 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
Vi skriver inn følgende kommando for å prøve å koble til file-3.txtto file-1.txt:
join file-1.txt file-3.txt
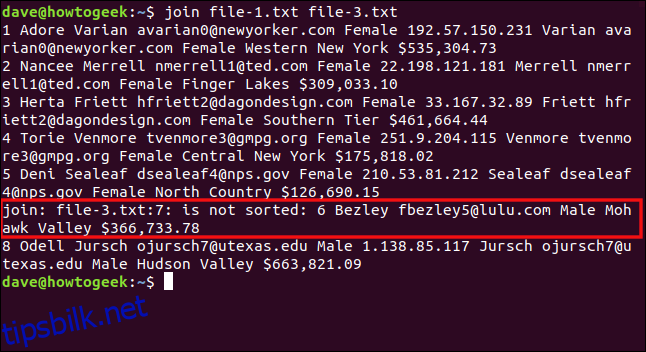
join rapporterer at den syvende linjen i file-3.txt er ute av drift, så den blir ikke behandlet. Linje sju er den som begynner med tallet seks, som skal komme før åtte i en riktig sortert liste. Den sjette linjen i filen (som begynner med «8 Odell») var den siste som ble behandlet, så vi ser utdataene for den.
Du kan bruke –sjekk-rekkefølge-alternativet hvis du vil se om join er fornøyd med sorteringsrekkefølgen til en fil – ingen sammenslåing vil bli forsøkt.
For å gjøre det skriver vi følgende:
join --check-order file-1.txt file-3.txt
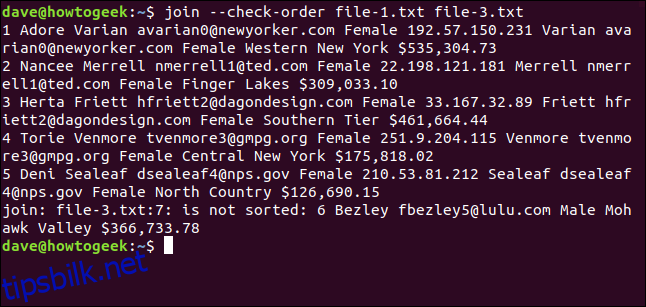
join forteller deg på forhånd at det kommer til å være et problem med linje sju i filen file-3.txt.
Filer med manglende linjer
I file-4.txt er den siste linjen fjernet, så det er ikke en linje åtte. Innholdet er som følger:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
Vi skriver følgende, og overraskende nok klager ikke join og behandler alle linjene den kan:
join file-1.txt file-4.txt
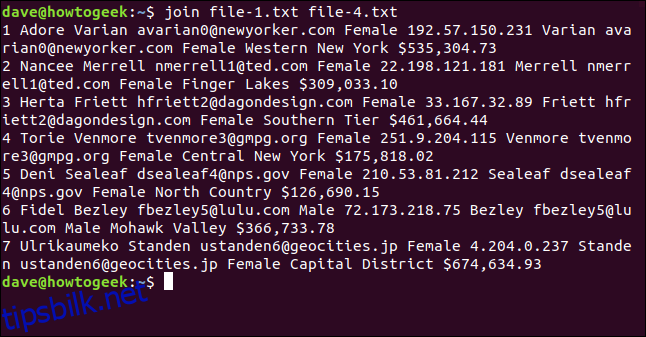
Utgangen viser syv sammenslåtte linjer.
Alternativet -a (utskrift kan ikke pares) forteller join å også skrive ut linjene som ikke kunne matches.
Her skriver vi følgende kommando for å fortelle join å skrive ut linjene fra fil en som ikke kan matches med linjene i fil to:
join -a 1 file-1.txt file-4.txt
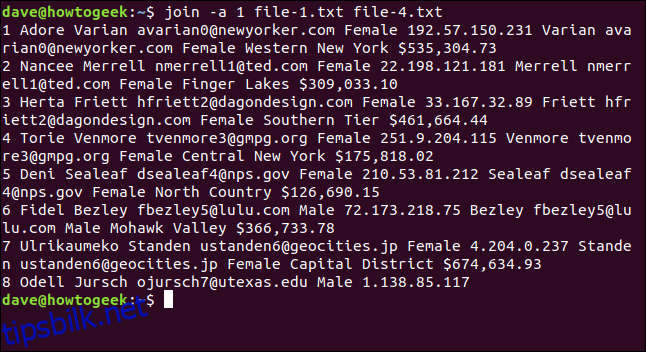
Sju linjer er matchet, og linje åtte fra fil én er skrevet ut, uten samsvar. Det er ingen sammenslått informasjon fordi file-4.txt ikke inneholdt en linje åtte som den kunne matches. Imidlertid vises det i det minste fortsatt i utdataene, slik at du vet at det ikke samsvarer i file-4.txt.
Vi skriver inn følgende kommando -v (undertrykk sammenføyde linjer) for å avsløre alle linjer som ikke samsvarer:
join -v file-1.txt file-4.txt

Vi ser at linje åtte er den eneste som ikke har samsvar i fil to.
Matche andre felt
La oss matche to nye filer på et felt som ikke er standard (felt én). Følgende er innholdet i file-7.txt:
[email protected] Female 192.57.150.231 [email protected] Female 210.53.81.212 [email protected] Male 72.173.218.75 [email protected] Female 33.167.32.89 [email protected] Female 22.198.121.181 [email protected] Male 1.138.85.117 [email protected] Female 251.9.204.115 [email protected] Female 4.204.0.237
Og følgende er innholdet i file-8.txt:
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
Det eneste fornuftige feltet å bruke for å bli med er e-postadressen, som er felt én i den første filen og felt to i den andre. For å imøtekomme dette kan vi bruke alternativene -1 (fil ett felt) og -2 (fil to felt). Vi følger disse med et nummer som angir hvilket felt i hver fil som skal brukes for å bli med.
Vi skriver følgende for å fortelle join å bruke det første feltet i fil én og det andre i fil to:
join -1 1 -2 2 file-7.txt file-8.txt
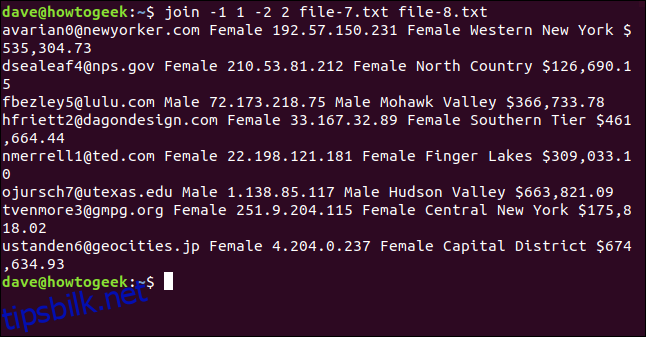
Filene slås sammen på e-postadressen, som vises som det første feltet på hver linje i utdataene.
Bruke forskjellige feltskillere
Hva om du har filer med felt som er atskilt med noe annet enn mellomrom?
De følgende to filene er kommadelte – det eneste mellomrommet er mellom stedsnavnene med flere ord:
cat file-5.txt
cat file-6.txt
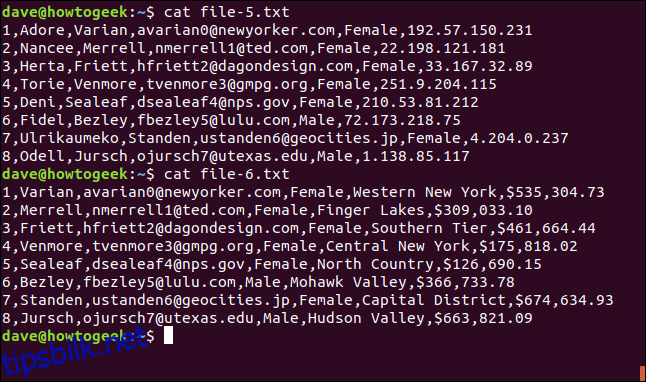
Vi kan bruke -t (skilletegn) for å fortelle join hvilket tegn som skal brukes som feltskilletegn. I dette tilfellet er det kommaet, så vi skriver inn følgende kommando:
join -t, file-5.txt file-6.txt
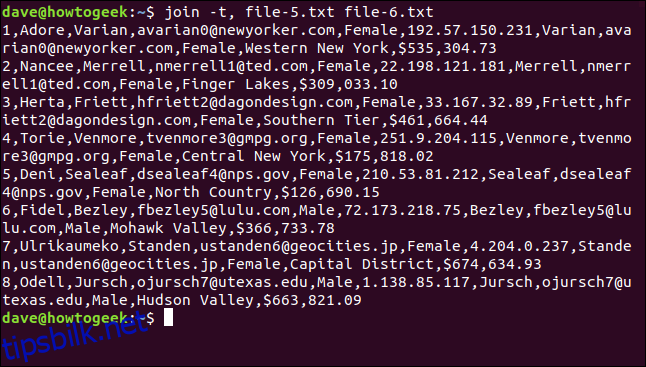
Alle linjene er matchet, og mellomrommene er bevart i stedsnavnene.
Ignorerer bokstaver
En annen fil, file-9.txt, er nesten identisk med file-8.txt. Den eneste forskjellen er at noen av e-postadressene har stor bokstav, som vist nedenfor:
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
Da vi ble med file-7.txt og file-8.txt, fungerte det perfekt. La oss se hva som skjer med file-7.txt og file-9.txt.
Vi skriver inn følgende kommando:
join -1 1 -2 2 file-7.txt file-9.txt
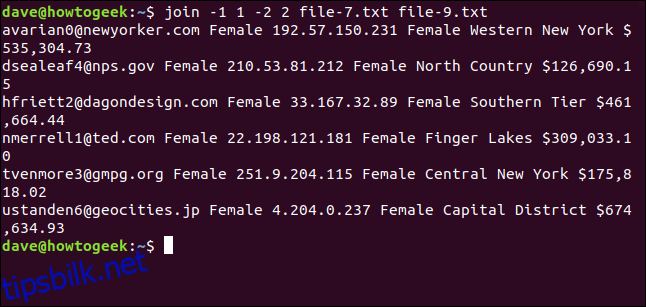
Vi matchet bare seks linjer. Forskjellene i store og små bokstaver forhindret at de to andre e-postadressene ble koblet sammen.
Vi kan imidlertid bruke alternativet -i (ignorer store og små bokstaver) for å tvinge sammen for å ignorere disse forskjellene og matche felt som inneholder samme tekst, uavhengig av store og små bokstaver.
Vi skriver inn følgende kommando:
join -1 1 -2 2 -i file-7.txt file-9.txt
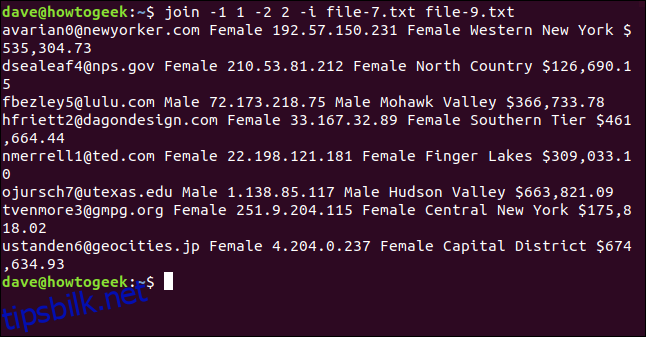
Alle åtte linjene er matchet og slått sammen.
Mix og match
Når du blir med, har du en mektig alliert når du sliter med vanskelige dataforberedelser. Kanskje du trenger å analysere dataene, eller kanskje du prøver å massere dem i form for å utføre en import til et annet system.
Uansett hvordan situasjonen er, vil du være glad for at du har blitt med i hjørnet ditt!