
Tenk deg at du har en stor infrastruktur av ulike typer enheter som du trenger for å vedlikeholde regelmessig eller sikre at de ikke er farlige for det omkringliggende miljøet.
En måte å oppnå dette på er å regelmessig sende folk til hvert sted for å sjekke om alt er i orden. Dette er på en eller annen måte gjennomførbart, men også ganske dyrt med tid og ressurser. Og hvis infrastrukturen er stor nok, kan du kanskje ikke dekke den hele innen et år.
En annen måte er å automatisere den prosessen og la jobbene i skyen verifisere for deg. For at det skal skje, må du gjøre følgende:
👉 En rask prosess for hvordan du får bilder av enhetene. Dette kan fortsatt gjøres av personer, da det fortsatt er mye raskere å gjøre bare et bilde som å gjøre alle enhetsverifiseringsprosesser. Det kan også gjøres med bilder tatt fra biler eller til og med droner, i så fall blir det en mye raskere og mer automatisert bildeinnsamlingsprosess.
👉 Da må du sende alle de innhentede bildene til ett dedikert sted i skyen.
👉 I skyen trenger du en automatisert jobb for å plukke opp bildene og behandle dem gjennom maskinlæringsmodeller som er opplært til å gjenkjenne enhetsskader eller anomalier.
👉 Til slutt må resultatene være synlige for nødvendige brukere slik at reparasjon kan planlegges for enheter med problemer.
La oss se på hvordan vi kan oppnå anomalideteksjon fra bildene i AWS-skyen. Amazon har noen få forhåndsbygde maskinlæringsmodeller vi kan bruke til det formålet.
Innholdsfortegnelse
Hvordan lage en modell for visuell anomalideteksjon
For å lage en modell for oppdagelse av visuell anomali, må du følge flere trinn:
Trinn 1: Definer tydelig problemet du vil løse og hvilke typer avvik du vil oppdage. Dette vil hjelpe deg med å finne det riktige testdatasettet du trenger for å trene modellen.
Trinn 2: Samle et stort datasett med bilder som representerer normale og unormale forhold. Merk bildene for å indikere hvilke som er normale og hvilke som inneholder anomalier.
Trinn 3: Velg en modellarkitektur som passer for oppgaven. Dette kan innebære å velge en forhåndsopplært modell og finjustere den for ditt spesifikke bruksområde eller lage en tilpasset modell fra bunnen av.
Trinn 4: Tren modellen ved å bruke det forberedte datasettet og den valgte algoritmen. Dette betyr å bruke overføringslæring for å utnytte forhåndstrente modeller eller trene modellen fra bunnen av ved bruk av teknikker som konvolusjonelle nevrale nettverk (CNN).
Hvordan trene en maskinlæringsmodell
Kilde: aws.amazon.com
Prosessen med å trene AWS-maskinlæringsmodeller for visuell anomalideteksjon involverer vanligvis flere viktige trinn.
#1. Samle inn dataene
I begynnelsen må du samle og merke et stort datasett med bilder som representerer både normale og unormale forhold. Jo større datasettet er, jo bedre og mer presis kan modellen trenes. Men det innebærer også mye mer tid dedikert til å trene modellen.
Vanligvis vil du ha rundt 1000 bilder i et testsett for å få en god start.
#2. Forbered dataene
Bildedataene må først forhåndsbehandles for at maskinlæringsmodellene skal kunne plukke dem opp. Forbehandling kan bety forskjellige ting, som:
- Rensing av inngangsbildene i separate undermapper, korrigering av metadata osv.
- Endre størrelsen på bildene for å møte oppløsningskravene til modellen.
- Distribuere dem i mindre biter av bilder for mer effektiv og parallell behandling.
#3. Velg modell
Velg nå riktig modell for å gjøre den riktige jobben. Velg enten en forhåndsopplært modell, eller du kan lage en tilpasset modell som passer for den visuelle anomalideteksjonen på modellen.
#4. Evaluer resultatene
Når modellen behandler datasettet ditt, skal du validere ytelsen. Du vil også sjekke om resultatene er tilfredsstillende for behovene. Dette kan for eksempel bety at resultatene er korrekte på mer enn 99 % av inndataene.
#5. Distribuer modellen
Hvis du er fornøyd med resultatene og ytelsen, distribuer modellen med en spesifikk versjon i AWS-kontomiljøet slik at prosessene og tjenestene kan begynne å bruke den.
#6. Overvåk og forbedre
La den gå gjennom ulike testjobber og bildedatasett og evaluer hele tiden om de nødvendige parameterne for deteksjonsriktighet fortsatt er på plass.
Hvis ikke, trener modellen på nytt ved å inkludere de nye datasettene der modellen ga feil resultater.
AWS maskinlæringsmodeller
Se nå på noen konkrete modeller du kan utnytte i Amazon-skyen.
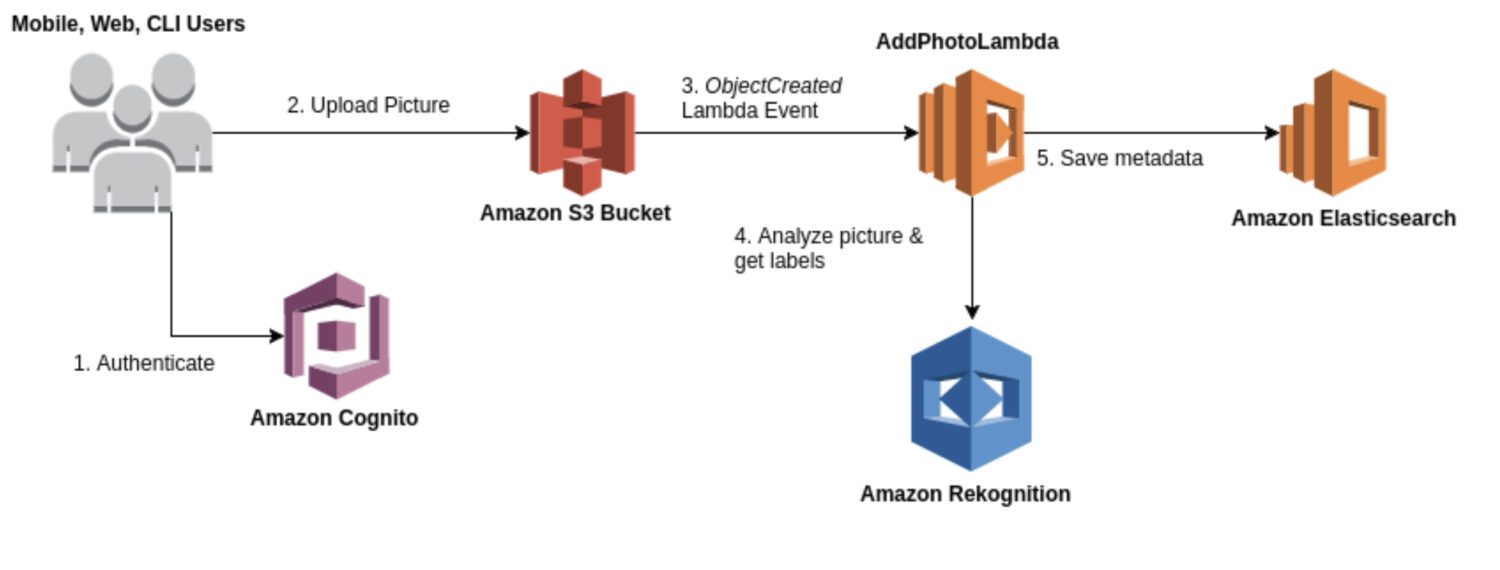
AWS-anerkjennelse
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Gjenkjenning er en generell bilde- og videoanalysetjeneste som kan brukes for ulike brukstilfeller, for eksempel ansiktsgjenkjenning, objektgjenkjenning og tekstgjenkjenning. Mesteparten av tiden vil du bruke gjenkjennelsesmodellen for en første rå generasjon av deteksjonsresultater for å danne en datainnsjø av identifiserte anomalier.
Den gir en rekke forhåndsbygde modeller du kan bruke uten trening. Rekognition leverer også sanntidsanalyse av bilder og videoer med høy nøyaktighet og lav ventetid.
Her er noen typiske brukstilfeller der gjenkjenning er et godt valg for avviksdeteksjon:
- Ha en generell brukssak for oppdagelse av uregelmessigheter, for eksempel å oppdage uregelmessigheter i bilder eller videoer.
- Utfør anomalideteksjon i sanntid.
- Integrer anomalideteksjonsmodellen din med AWS-tjenester som Amazon S3, Amazon Kinesis eller AWS Lambda.
Og her er noen konkrete eksempler på uregelmessigheter du kan oppdage ved hjelp av gjenkjenning:
- Anomalier i ansikter, for eksempel å oppdage ansiktsuttrykk eller følelser utenfor normalområdet.
- Manglende eller feilplasserte objekter i en scene.
- Feilstavede ord eller uvanlige tekstmønstre.
- Uvanlige lysforhold eller uventede gjenstander i en scene.
- Upassende eller støtende innhold i bilder eller videoer.
- Plutselige endringer i bevegelse eller uventede bevegelsesmønstre.
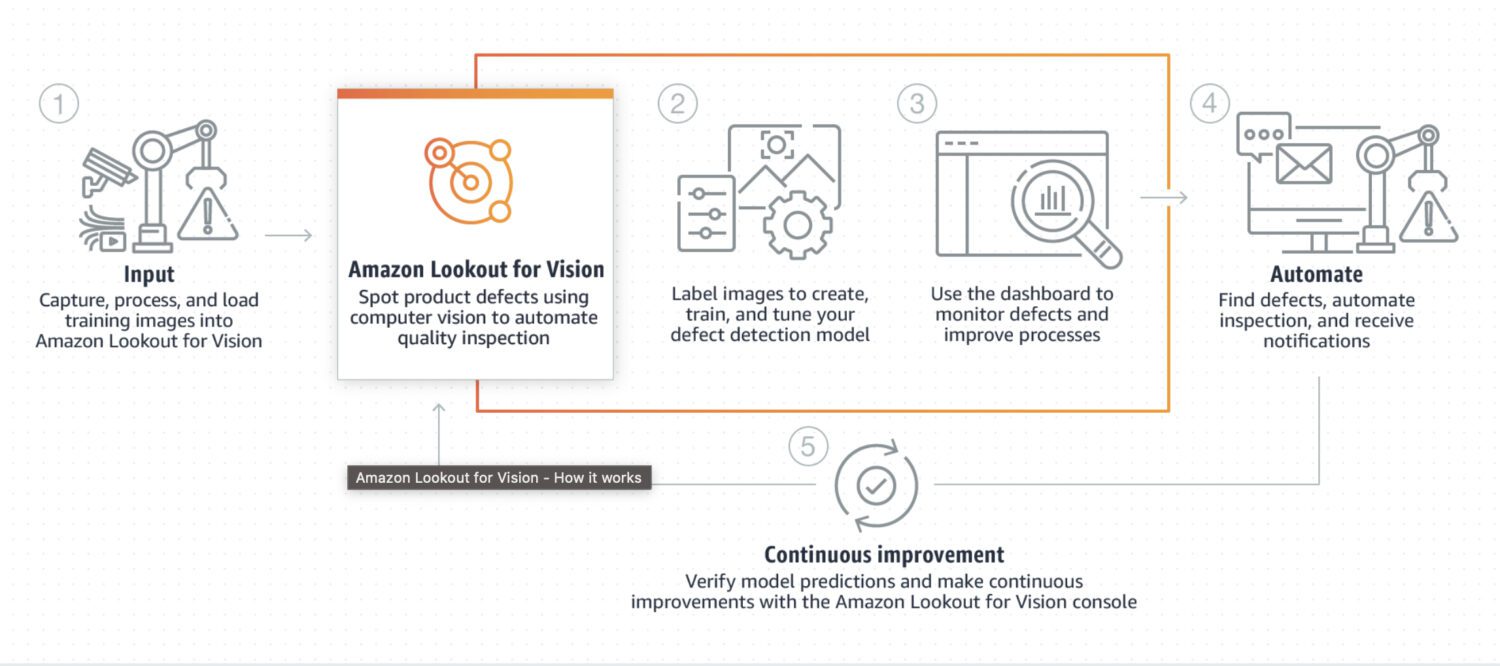
AWS Lookout for Vision
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Lookout for Vision er en modell som er spesielt utviklet for avviksdeteksjon i industrielle prosesser, som produksjons- og produksjonslinjer. Det krever vanligvis litt egendefinert kodeforbehandling og etterbehandling av et bilde eller en konkret utskjæring av bildet, vanligvis gjort ved hjelp av et Python-programmeringsspråk. Mesteparten av tiden spesialiserer den seg på noen helt spesielle problemer i bildet.
Det krever tilpasset opplæring på et datasett med normale og unormale bilder for å lage en tilpasset modell for avviksdeteksjon. Det er ikke så sanntidsfokusert; snarere er den designet for batch-behandling av bilder, med fokus på nøyaktighet og presisjon.
Her er noen typiske brukstilfeller der Lookout for Vision er et godt valg hvis du trenger å oppdage:
- Defekter i produserte produkter eller identifisering av utstyrsfeil i en produksjonslinje.
- Et stort datasett med bilder eller andre data.
- Sanntidsanomali i en industriell prosess.
- Anomali integrert med andre AWS-tjenester, for eksempel Amazon S3 eller AWS IoT.
Og her er noen konkrete eksempler på uregelmessigheter som du kan oppdage ved å bruke Lookout for Vision:
- Defekter i produserte produkter, som riper, bulker eller andre feil, kan påvirke kvaliteten på produktet.
- Utstyrsfeil i en produksjonslinje, for eksempel å oppdage ødelagte eller feilfungerende maskiner som kan forårsake forsinkelser eller sikkerhetsfarer.
- Kvalitetskontrollproblemer i en produksjonslinje inkluderer å oppdage produkter som ikke oppfyller de nødvendige spesifikasjonene eller toleransene.
- Sikkerhetsfarer i en produksjonslinje inkluderer å oppdage gjenstander eller materialer som kan utgjøre en risiko for arbeidere eller utstyr.
- Anomalier i en produksjonsprosess, for eksempel å oppdage uventede endringer i flyten av materialer eller produkter gjennom produksjonslinjen.
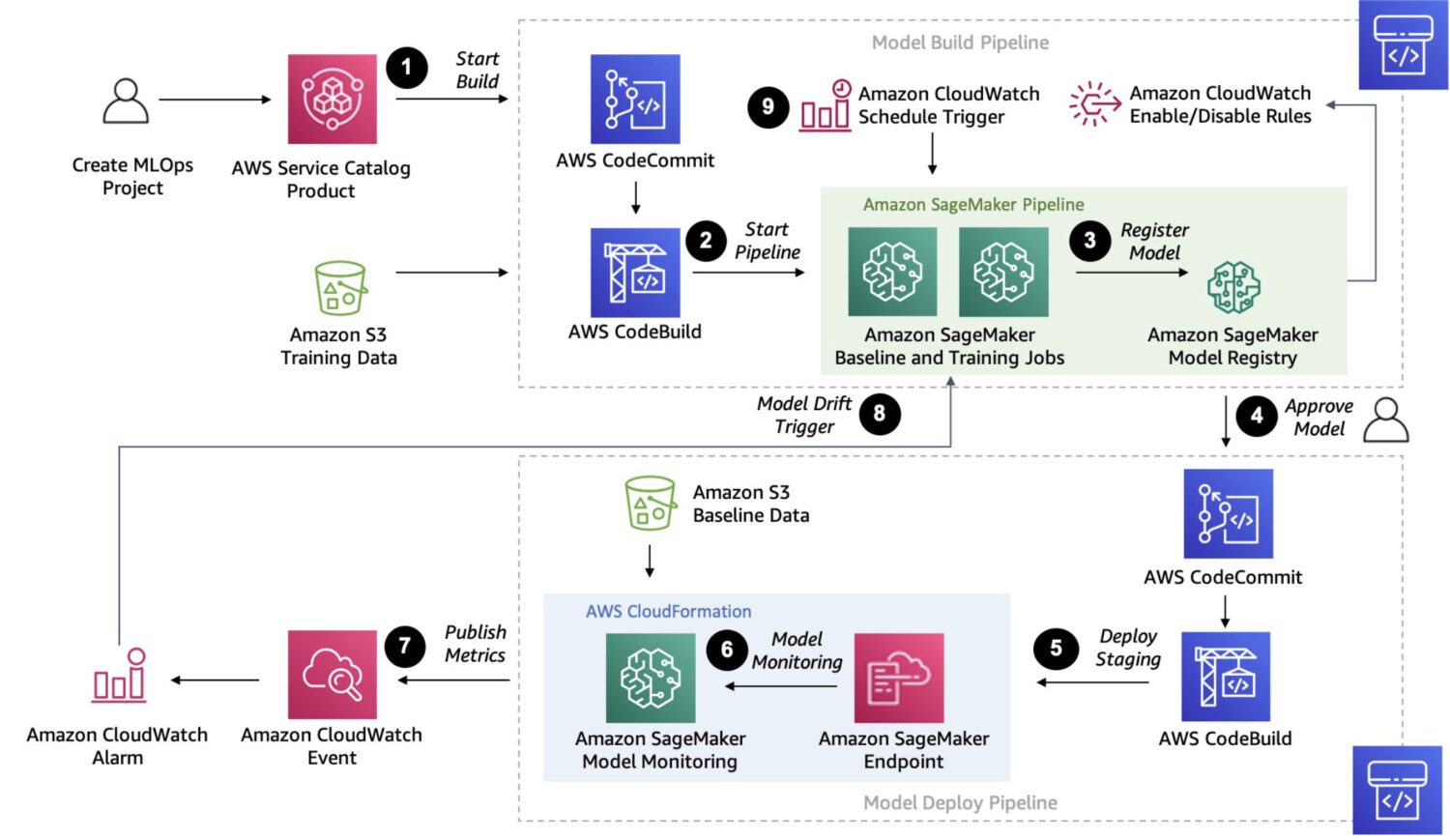
AWS Sagemaker
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Sagemaker er en fullt administrert plattform for å bygge, trene og distribuere tilpassede maskinlæringsmodeller.
Det er en mye mer robust løsning. Faktisk gir det en måte å koble sammen og utføre flere flertrinnsprosesser i én kjede med jobber som følger etter hverandre, omtrent som AWS Step Functions kan gjøre.
Men siden Sagemaker bruker ad-hoc EC2-instanser for sin behandling, er det ingen grense på 15 minutter for enkeltjobbbehandling, som i tilfellet med AWS lambda-funksjoner i AWS Step Functions.
Du kan også gjøre automatisk modellinnstilling med Sagemaker, som definitivt er en funksjon som gjør det til et alternativ som skiller seg ut. Endelig kan Sagemaker enkelt distribuere modellen i et produksjonsmiljø.
Her er noen typiske brukstilfeller der SageMaker er et godt valg for oppdagelse av anomalier:
- En spesifikk brukstilfelle som ikke dekkes av forhåndsbygde modeller eller APIer, og hvis du trenger å bygge en skreddersydd modell for dine spesifikke behov.
- Hvis du har et stort datasett med bilder eller andre data. Forhåndsbygde modeller krever litt forhåndsbehandling i slike tilfeller, men Sagemaker kan gjøre det uten.
- Hvis du trenger å utføre anomalideteksjon i sanntid.
- Hvis du trenger å integrere modellen din med andre AWS-tjenester, for eksempel Amazon S3, Amazon Kinesis eller AWS Lambda.
Og her er noen typiske anomalideteksjoner som Sagemaker er i stand til å utføre:
- Svindeloppdagelse i finansielle transaksjoner, for eksempel uvanlige forbruksmønstre eller transaksjoner utenfor normalområdet.
- Cybersikkerhet i nettverkstrafikk, som uvanlige mønstre for dataoverføring eller uventede tilkoblinger til eksterne servere.
- Medisinsk diagnose i medisinske bilder, for eksempel påvisning av svulster.
- Uregelmessigheter i utstyrsytelsen, for eksempel å oppdage endringer i vibrasjoner eller temperatur.
- Kvalitetskontroll i produksjonsprosesser, som for eksempel å oppdage feil i produkter eller identifisere avvik fra forventede kvalitetsstandarder.
- Uvanlige mønstre for energibruk.
Hvordan inkorporere modellene i serverløs arkitektur
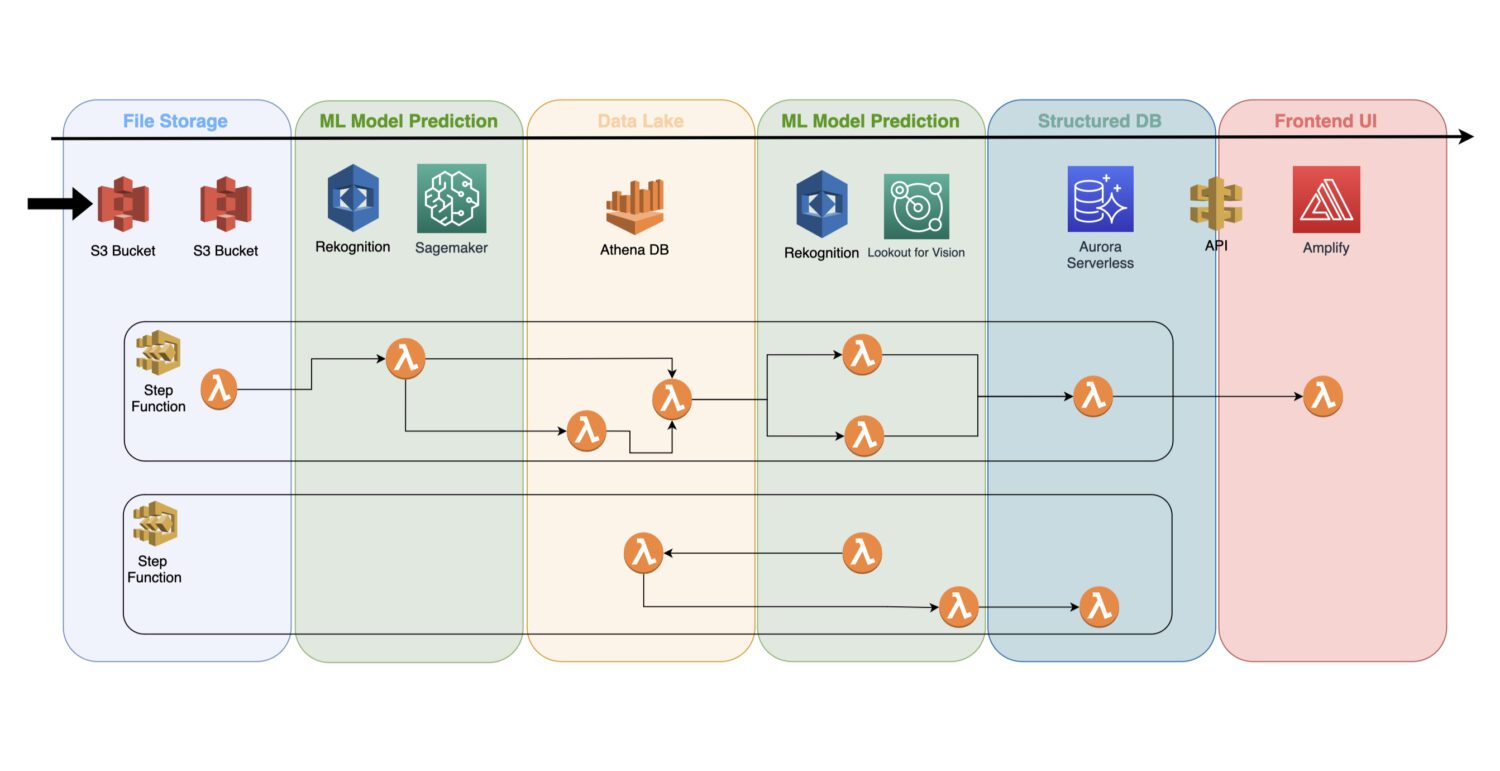
En trent maskinlæringsmodell er en skytjeneste som ikke bruker noen klyngeservere i bakgrunnen; dermed kan den enkelt inkluderes i en eksisterende serverløs arkitektur.
Automatisering gjøres via AWS lambda-funksjoner, koblet til en jobb med flere trinn inne i en AWS Step Functions-tjeneste.
Vanligvis trenger du innledende gjenkjenning rett etter at du har samlet bildene og forhåndsbehandlingen av dem på S3-bøtten. Det er der du vil generere atomavviksdeteksjon på inngangsbildene og lagre resultatene i en datainnsjø, for eksempel representert av Athena-databasen.
I noen tilfeller er ikke denne første deteksjonen nok for din konkrete brukssituasjon. Du trenger kanskje en annen, mer detaljert deteksjon. For eksempel kan den innledende (f.eks. gjenkjennelse) modellen oppdage et eller annet problem på enheten, men det er ikke mulig å pålitelig identifisere hva slags problem det er.
For det trenger du kanskje en annen modell med andre funksjoner. I et slikt tilfelle kan du kjøre den andre modellen (f.eks. Lookout for Vision) på undergruppen av bilder der den opprinnelige modellen identifiserte problemet.
Dette er også en god måte å spare noen kostnader på, siden du ikke trenger å kjøre den andre modellen på et helt sett med bilder. I stedet kjører du den bare på det meningsfulle undersettet.
AWS Lambda-funksjoner vil dekke all slik behandling med Python- eller Javascript-kode inne. Det er bare opp til prosessens natur og hvor mange AWS lambda-funksjoner du trenger å inkludere i en flyt. 15-minutters grensen for maksimal varighet av en AWS lambda-anrop vil avgjøre hvor mange trinn en slik prosess må inneholde.
Siste ord
Å jobbe med skymaskinlæringsmodeller er en veldig interessant jobb. Hvis du ser på det fra perspektivet til ferdigheter og teknologier, vil du finne ut at du trenger å ha et team med et stort utvalg av ferdigheter.
Teamet må forstå hvordan man trener en modell, enten den er forhåndsbygd eller laget fra bunnen av. Dette betyr at mye matematikk eller algebra er involvert i å balansere påliteligheten og ytelsen til resultatene.
Du trenger også noen avanserte Python- eller Javascript-kodingsferdigheter, database- og SQL-ferdigheter. Og etter at alt innholdsarbeidet er gjort, trenger du DevOps-ferdigheter for å koble det til en pipeline som vil gjøre det til en automatisert jobb klar for distribusjon og utførelse.
Å definere anomalien og trene modellen er én ting. Men det er en utfordring å integrere det hele i ett funksjonelt team som kan behandle resultatene av modellene og lagre dataene på en effektiv og automatisert måte for å betjene dem til sluttbrukerne.
Deretter kan du sjekke ut alt om ansiktsgjenkjenning for bedrifter.