Grafdatabaser er optimalisert for å håndtere store mengder tett sammenkoblede data og utføre komplekse spørringer på en effektiv måte. Men hvordan vet du hvilken grafdatabase som passer best for dine behov? La oss utforske dette nærmere.
Det sies ofte at «data er den nye oljen». Enhver organisasjons vekst avhenger av evnen til å lagre og bruke data på en effektiv måte. I dag genereres det enorme mengder data – omtrent 2,5 kvintillioner byte hver eneste dag. Dette krever systemer som er feiltolerante og lagerløsninger som kan håndtere og lagre data på en effektiv måte. Tradisjonelt har relasjonsdatabaser vært brukt til dette formålet.
Etter hvert som tiden gikk, endret både mengden og typen data seg. Det ble et behov for å lagre video, lyd, bilder og andre formater. Dette førte til utviklingen av SQL, NoSQL-databaser, Hadoop og grafdatabaser. Hver av disse har sine egne bruksområder og håndterer forskjellige dataformater. Grafdatabaser er designet for å forenkle operasjoner på data og for å oppnå effektiv lagring.
Grafdatabaser
En graf er en datastruktur som består av noder og kanter. En database er en organisert samling av tabeller som lagrer data og relasjonene mellom dem. En grafdatabase lagrer data som noder, og relasjonene mellom disse dataene som kanter. Grafdatabaser er særlig gode til å håndtere sanntidsspørringer og administrere mange-til-mange-relasjoner mellom ulike enheter.
Det finnes flere populære grafdatamodeller, inkludert eiendomsgrafer og RDF-grafer. Analyse og spørringer gjøres ofte ved hjelp av eiendomsgrafer, mens RDF-grafer er mer brukt til dataintegrasjon. Den primære forskjellen er at RDF-grafer representeres som tripler bestående av subjekt, predikat og objekt.
I grafdatabaser lagres data i noder, og relasjonene mellom dataene i form av kanter mellom nodene. Disse kantene kan være rettet (enveiskommunikasjon) eller ikke-rettet (toveiskommunikasjon).
Selve spørringsbehandlingen foregår ved å navigere gjennom grafen. For å svare på spørsmål effektivt, brukes graftraversalalgoritmer for å finne veien fra en node til en annen, beregne avstanden mellom noder, identifisere mønstre, finne løkker og analysere muligheten for klynger.
Anvendelsesområder for grafdatabaser
Grafdatabaser er mye brukt innenfor svindeldeteksjon. Noder i denne sammenhengen kan representere personers navn, adresser, fødselsdatoer og andre elementer, mens falske IP-adresser og enhetsnumre kan være del av grafen. Når en falsk node interagerer med en legitim node, opprettes en kobling som merkes som mistenkelig.
Sosiale medier bruker grafdatabaser for å gi brukerne anbefalinger om personer de kanskje vil koble seg til og innhold de kan være interessert i. Dette gjøres ved hjelp av grafnavigasjon i databasen.
Grafdatabaser brukes også til å effektivt lagre og administrere nettverkskartlegging, infrastrukturadministrasjon og konfigurasjonselementer.
Grafdatabase kontra Relasjonsdatabase
I en grafdatabase erstattes tabeller med rader og kolonner med noder og kanter. Forholdet mellom data lagres i kantene i en grafdatabase.
En relasjonsdatabase lagrer relasjoner mellom tabeller ved hjelp av fremmednøkler. I en grafdatabase er det enkelt å hente ut data eller spørre, uten behov for komplekse sammenføyninger. Dette er ikke tilfellet i relasjonsdatabaser.
Relasjonsdatabaser er best egnet for transaksjonsbaserte applikasjoner, mens grafdatabaser er bedre egnet for relasjonsrike og dataintensive applikasjoner.
Grafdatabaser støtter strukturerte, semistrukturerte og ustrukturerte data. Relasjonsdatabaser krever et fast skjema.
Grafdatabaser kan tilpasses dynamiske krav, mens relasjonsdatabaser som oftest brukes for kjente og statiske problemer.
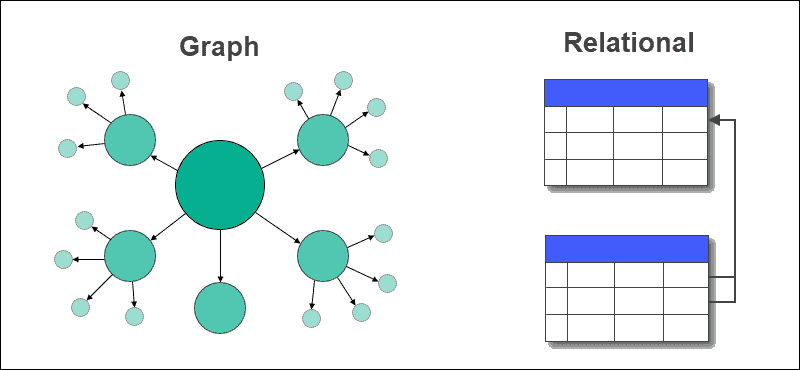 Graf vs. relasjonsdatabaser
Graf vs. relasjonsdatabaser
La oss se nærmere på noen av de beste grafdatabaseløsningene som finnes.
Cayley
Cayley er en åpen kildekode grafdatabase som er utviklet under Apache 2.0 lisensen. Den er bygget med Go og er designet for å jobbe med sammenkoblede data. Cayley er databasen som brukes i Googles Freebase og Knowledge Graph. Den støtter flere spørrespråk som MQL og Javascript, med et Gremlin-basert grafobjekt.
Cayley er kjent for å være enkel å bruke, rask og ha en modulær design. Den kan integreres med ulike backend-løsninger, som LevelDB, MongoDB og Bolt. Den støtter også tredjeparts API-er skrevet på ulike språk som Java, .NET, Rust, Haskell, Ruby, PHP, Javascript og Clojure. Distribusjon kan enkelt gjøres med Docker og Kubernetes. Cayley brukes ofte innen informasjonsteknologi, dataprogramvare og finansielle tjenester.
Amazon Neptune
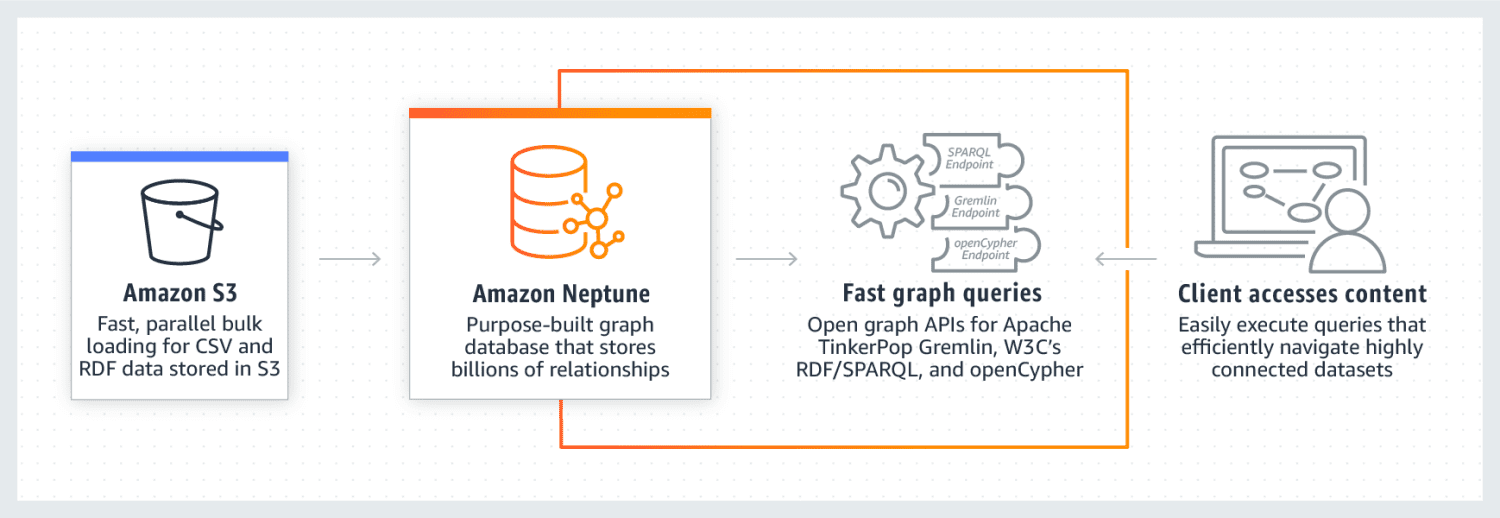
Amazon Neptune er kjent for sin gode ytelse med svært sammenkoblede datasett. Den er pålitelig, sikker, fullt administrert og støtter åpne graf-APIer. Den kan lagre milliarder av relasjoner og utføre spørringer med svært lav latenstid på bare noen millisekunder.
Neptunes grafdatamodell består av fire posisjoner: subjekt (S), predikat (P), objekt (O) og graf (G). Hver posisjon brukes til å lagre plasseringen til kildenoden, målnoden, forholdet mellom dem og deres egenskaper.
Neptune bruker også en hurtigbuffer som øker hastigheten på lesespørringer. Dataene lagres i form av DB-klynger. Hver klynge består av en primær DB-forekomst og lese-replikaer av DB-forekomster. Neptune er svært sikker, med IAM-autentisering, SSL-sertifisering og loggovervåking. Migrering av data fra andre kilder til Amazon Neptune er også enkelt. I tillegg sikrer Neptune robusthet ved å lage replikaer og periodiske sikkerhetskopier. Noen selskaper som bruker Neptune inkluderer Herren, Onedot, Juncture og Hi Platform.
Neo4j
Neo4j er en skalerbar, sikker og pålitelig grafdatabase som er tilgjengelig on-demand. Den er bygget med Java og bruker Cypher som spørrespråk. Den bruker Bolt-protokollen og alle transaksjoner skjer over et HTTP-endepunkt. Neo4j er vesentlig raskere til å svare på spørsmål sammenlignet med relasjonsdatabaser. Den har ikke overheaden som komplekse sammenføyninger medfører, og optimaliseringene fungerer godt når datasettet er stort og godt sammenkoblet. Neo4j gir fordelen med graflagring kombinert med ACID-egenskapene til en relasjonsdatabase.

Neo4j støtter flere språk som Java, .NET, Node.js, Ruby og Python ved hjelp av drivere. Den brukes også i arbeidsflyter for grafdatavitenskap, analyse og maskinlæring. Neo4j Aura DB er en feiltolerant og fullt administrert skygrafdatabase. Selskaper som Microsoft, Cisco, Adobe, eBay, IBM og Samsung bruker Neo4j.
ArangoDB
ArangoDB er en åpen kildekode multi-modell database. Multi-modell-tilnærmingen gjør det mulig å spørre etter data med hvilket som helst spørrespråk man ønsker. Nodene og kantene i ArangoDB er JSON-dokumenter, og hvert dokument har en unik id. Forholdet mellom to noder indikeres av kanter, der de unike ID-ene lagres. Den gode ytelsen skyldes tilstedeværelsen av en hash-indeks.

Gjennomganger, sammenføyninger og søk i databasen forbedres med denne indeksen. ArangoDB hjelper til med å designe, skalere og tilpasse ulike arkitekturer. Den spiller en viktig rolle i komplekse datavitenskapelige oppgaver som funksjonsutvinning og avansert søk.
ArangoDB kan kjøres i et skybasert miljø og er kompatibel med Mac OS, Linux og Windows. LDAP-autentisering, datamaskering og krypteringsalgoritmer sikrer at databasen er sikker. Den brukes ofte i risikostyring, IAM, svindeldeteksjon, nettverksinfrastruktur, anbefalingsmotorer og mer. Selskaper som Accenture, Cisco, Dish og VMware bruker ArangoDB.
DataStax
DataStax er en NoSQL skybasert databasetjeneste bygget på Apache Cassandra. Den er svært skalerbar og bruker skybasert arkitektur. Den er pålitelig og sikker. Hvert dokument som lagres i en DataStax har en indeks som gjør det enkelt å søke etter og hente data raskt. Dataene er delt opp i shards over de indekserte dataene. Ulike datakilder kan brukes for å bygge applikasjoner med DataStax Enterprise-verktøy, Kafka og Docker.
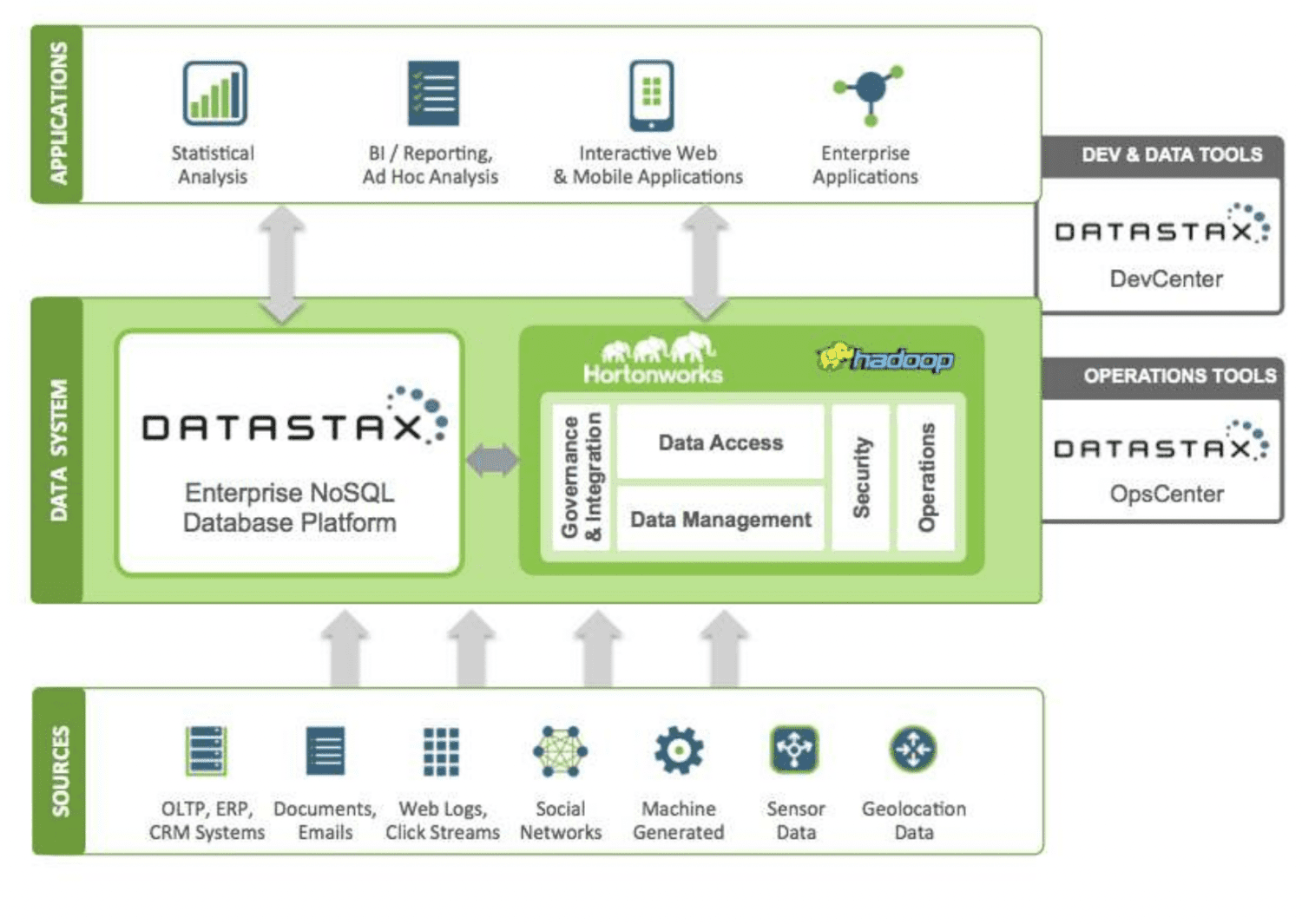
Data som samles inn fra kilder sendes til et Hadoop-økosystem og DataStax. Hadoop administrerer sikkerhet, drift, datatilgang og administrasjon ved å samhandle med DataStax. Dataene blir raffinert ved hjelp av DataStax utviklings- og driftsverktøy.
Den analyserte informasjonen brukes deretter til statistisk analyse, bedriftsapplikasjoner, rapportering og mer. Ettersom den er skybasert, betaler kundene for det de bruker, og prisen er rimelig. Selskaper som Verizon, CapitalOne, TMobile og Overstock bruker DataStax.
OrientDB
OrientDB er en grafdatabase som administrerer data effektivt og hjelper med å lage visuelle representasjoner for å vise data. Det er en grafdatabase med flere modeller og er bygget ved hjelp av Java. Den lagrer data i form av nøkkelverdi-par, dokumenter og objektmodeller. Den består av tre hovedkomponenter: grafredigerer, studiospørring og kommandolinjekonsoll.
En grafredigerer brukes til å visualisere og samhandle med data. Studio-spørringsgrensesnittet brukes til å utføre spørringer og gi umiddelbar utdata i bilde- og tabellformat. Kommandolinjekonsollen brukes for å søke etter data fra OrientDB. Den har en distribuert arkitektur med flere servere som kan utføre lese- og skriveoperasjoner. Replikaservere brukes til å utføre lese- og spørringsoperasjoner. OrientDB støtter indeksering og er også ACID-kompatibel. Selskaper som Comcast Corporation og Blackfriars Group bruker OrientDB.
Dgraph
Dgraph er en skygrafdatabase som støtter GraphQL. Den er bygget med Go. Den minimerer antall nettverksanrop og reduserer ventetiden ved å maksimere samtidig spørringsbehandling. Den sømløse integrasjonen av Dgraph med GraphQL forenkler utviklingen av GraphQL backend-applikasjoner.

En GraphQL-mutasjon sendes gjennom en Lambda-funksjon som interagerer med databasen og en datapipeline. Dette forenkler spørringsbehandlingen. Dgraph er horisontalt skalerbar, noe som betyr at antall ressurser økes med økende forespørsler og datamengde. Den har flere funksjoner som JWT-basert autorisasjon, datavisualisering, skyautentisering og sikkerhetskopiering av data. Selskaper som Intuit, Intel og Factset bruker Dgraph.
Tigergraph
Tigergraph er en eiendomsgrafdatabase utviklet med C++. Den er svært skalerbar og utfører avansert analyse på store mengder tilkoblede data. Den bruker en innebygd grafstruktur for datalagring og en grafbehandlingsmotor for databehandling. Databasen lagres både på disk og i minne, og bruker også en CPU-cache for rask gjenfinning. Den bruker Map Reduce-funksjonen for parallell databehandling.
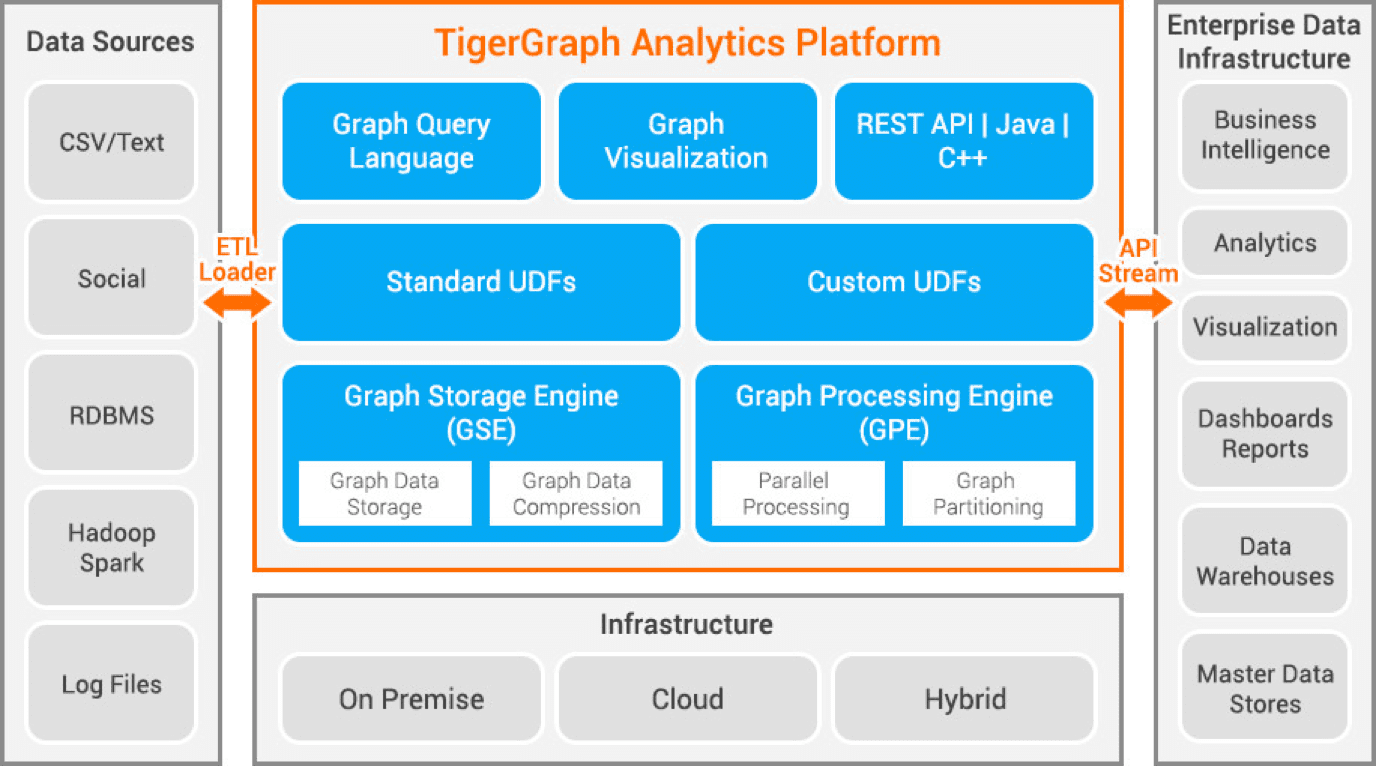
Tigergraph er svært rask og skalerbar. Den utfører parallelle beregninger og gir sanntidsoppdateringer. Den bruker datakomprimeringsteknikker og komprimerer dataene med opptil 10 ganger. Data partisjoneres automatisk på tvers av servere, noe som sparer tid og krefter for brukere. Tigergraph brukes til svindeloppdagelse, forsyningskjedestyring og for å forbedre helsetjenester. Selskaper som JPMorgan Chase, Intuit og United Health Group bruker Tigergraph.
AllegroGraph
AllegroGraph bruker entity-event kunnskapsgrafteknologi for å utføre analyser og beslutninger på svært sammenkoblede, komplekse og tette data. Data lagres i JSON- og JSON-LD-format i grafens noder. Den bruker REST-protokollarkitekturen. AllegroGraph håndterer også store datasett ved å dele dataene basert på spesifikke kriterier og spre dem over flere kunnskapsbaser.
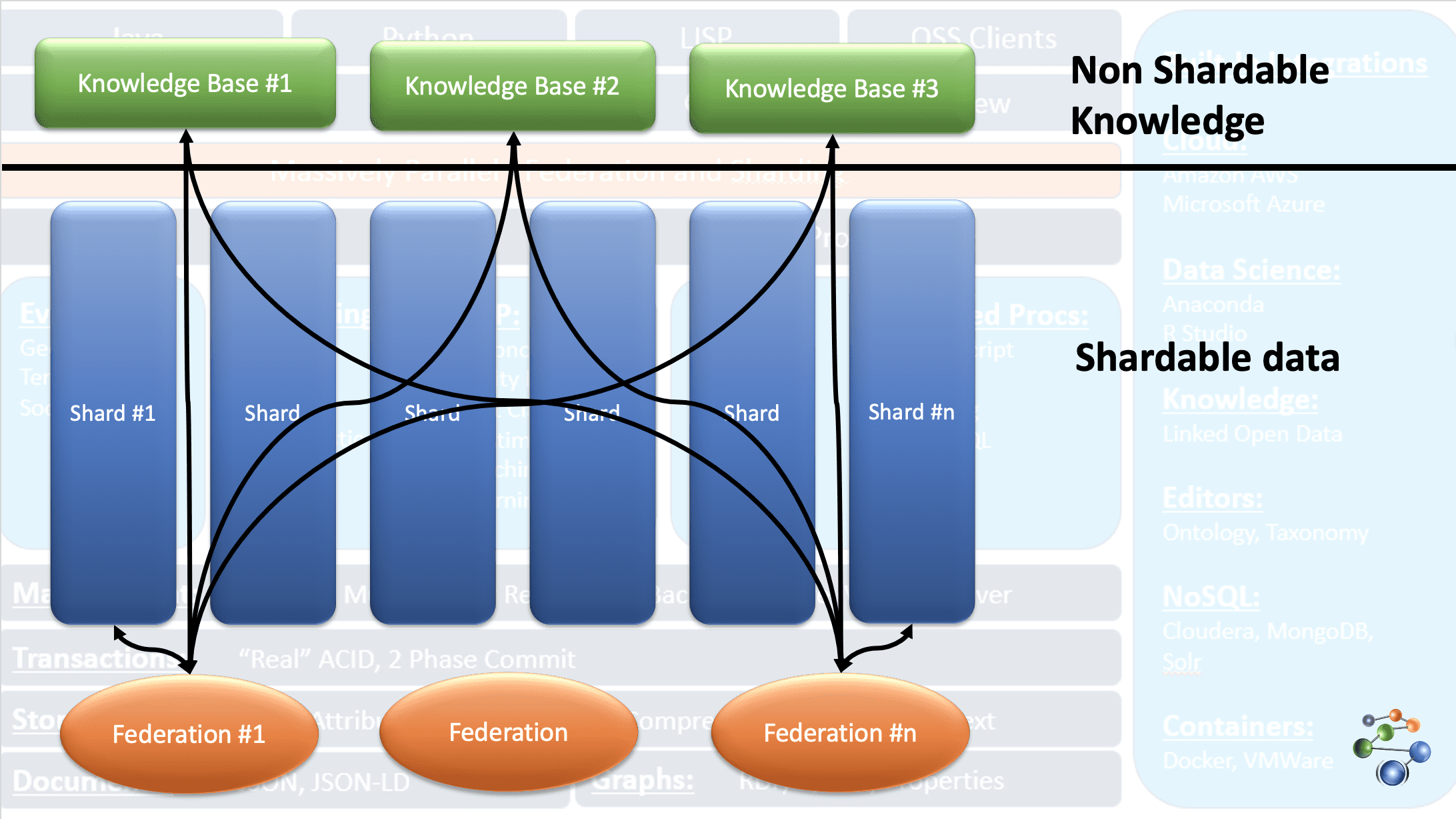
Dette er mulig takket være FedShard-funksjonen i AllegroGraph-databasen. Spørringer utføres ved å kombinere føderasjoner med kunnskapsbaserte repositories. AllegroGraph støtter XML-skjematyper og bruker trippelindekser. Den lagrer geospatiale data som breddegrader og lengdegrader og tidsdata som datoer, tidsstempel, osv. Den er også kompatibel med Windows, Mac og Linux. Den brukes i svindeldeteksjon, helsetjenester, enhetsidentifikasjon og risikoprediksjon.
Stardog
Stardog er en grafdatabase som utfører grafdatavirtualisering. Den kobler sammen data fra datavarehus og datasjøer uten å fysisk kopiere dataene til et nytt lagringssted. Stardog er bygget på RDF åpne standarder og støtter strukturerte, semistrukturerte og ustrukturerte data. Denne typen materialisering som utføres av Stardog gir fleksibilitet. Det er den eneste grafdatabasen som kombinerer kunnskapsgrafer og virtualisering.
Stardog bruker en inferensmotor drevet av kunstig intelligens for å behandle spørringer og gi effektive utdata. Det er en ACID-kompatibel grafdatabase, og støtter samtidig lesing og skriving. Den håndterer komplekse spørsmål med letthet takket være sin moderne arkitektur. Stardog brukes i IT-ressursadministrasjon, dataadministrasjon og analyse, og gir høy tilgjengelighet. Noen selskaper som bruker Stardog er Cisco, eBay, NASA og Finra.
Siste ord
Grafdatabaser forenkler spørringer i mange-til-mange-relasjoner og lagrer data på en effektiv måte. De er skalerbare, sikre og kan integreres med en rekke tredjepartsverktøy, API-er og språk. De siste årene har de blitt integrert med skyen og gir optimal ytelse.
Grafdatabaser forenkler komplekse sammenføyninger til enkle spørringer, noe som gjør det enklere for utviklere. Dataintensive oppgaver som IoT og Big Data er også viktige bruksområder. Grafdatabaser vil fortsette å utvikle seg og sannsynligvis bli brukt i enda flere områder i fremtiden.