Utforsk Datastrukturer i Python
Ønsker du å forbedre dine programmeringsferdigheter? Start med å utforske datastrukturer i Python. Dette er et viktig skritt for å bli en dyktig utvikler.
Når man lærer et nytt programmeringsspråk, er det essensielt å forstå de grunnleggende datatypene og de innebygde datastrukturene som språket tilbyr. I denne guiden om datastrukturer i Python vil vi dekke:
- Hvorfor datastrukturer er fordelaktige
- De innebygde datastrukturene i Python, som lister, tupler, ordbøker og sett
- Hvordan implementere abstrakte datatyper som stabler og køer
La oss starte!
Hvorfor er Datastrukturer Nyttige?
Før vi dykker ned i de forskjellige datastrukturene, la oss se på hvordan bruken av datastrukturer kan være til hjelp:
- Effektiv databehandling: Riktig valg av datastruktur bidrar til mer effektiv databehandling. Hvis du for eksempel trenger å lagre en samling elementer av samme datatype, med rask tilgang og tett kobling, kan en array være det beste valget.
- Optimal minnehåndtering: I større prosjekter kan en datastruktur være mer minneeffektiv enn en annen for å lagre samme data. For eksempel, i Python, kan både lister og tupler brukes til å lagre samlinger av data. Men hvis du vet at samlingen ikke vil endres, kan du bruke en tuppel, som vanligvis krever mindre minne enn en liste.
- Organisert kode: Bruken av passende datastruktur for en spesifikk funksjonalitet gjør koden din mer oversiktlig. Andre utviklere som leser koden din vil forvente at du bruker bestemte datastrukturer avhengig av den ønskede oppførselen. Hvis du for eksempel trenger en nøkkel-verdi-mapping med rask tilgang og innsetting, bør du bruke en ordbok.
Lister
Lister er en sentral datastruktur i Python når vi trenger dynamiske matriser, og de brukes i alt fra kodeintervjuer til daglig bruk.
Python-lister er dynamiske beholdere som kan endres. Du kan legge til og fjerne elementer direkte, uten å måtte lage en ny kopi.
Når du jobber med Python-lister:
- Tilgang til et element via indeks er en operasjon som tar konstant tid.
- Å legge til et element på slutten av listen er en operasjon som tar konstant tid.
- Å sette inn et element på en spesifikk posisjon er en operasjon som tar lineær tid.
Det finnes flere innebygde listemetoder som hjelper oss med å utføre vanlige operasjoner effektivt. Følgende kodeeksempel viser hvordan du bruker disse operasjonene på en eksempel-liste:
>>> tall = [5,4,3,2] >>> tall.append(7) >>> tall [5, 4, 3, 2, 7] >>> tall.pop() 7 >>> tall [5, 4, 3, 2] >>> tall.insert(0,9) >>> tall [9, 5, 4, 3, 2]
Python-lister støtter også slicing og testing for medlemskap ved å bruke `in`-operatoren:
>>> tall[1:4] [5, 4, 3] >>> 3 in tall True
Listestrukturen er både fleksibel og enkel å bruke, og den tillater at du lagrer elementer av forskjellige datatyper. Python har også en dedikert array-datastruktur for effektiv lagring av elementer av samme datatype, som vi skal se på senere.
Tupler
Tupler er en annen populær datastruktur i Python. De er på mange måter lik lister, med rask tilgang til elementer via indeks og mulighet for å slice. En viktig forskjell er at tupler er uforanderlige, noe som betyr at du ikke kan endre dem direkte. La oss se på et eksempel:
>>> tall = (5,4,3,2)
>>> tall[0]
5
>>> tall[0:2]
(5, 4)
>>> 5 in tall
True
>>> tall[0] = 7 # Dette vil gi en feilmelding!
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
Når du trenger en uforanderlig samling som kan behandles effektivt, er tupler et godt valg. Hvis du trenger en samling som kan endres, bør du bruke en liste i stedet.
📋 Lær mer om likheter og forskjeller mellom lister og tupler i Python.
Matriser
Matriser er kanskje mindre kjente datastrukturer i Python. De ligner på lister når det gjelder operasjoner, som rask tilgang via indeks og innsetting av elementer. Den viktigste forskjellen er at matriser lagrer elementer av samme datatype, noe som gjør dem mer minneeffektive.
For å lage en matrise bruker vi konstruktøren `array()` fra `array`-modulen. Denne tar inn en streng som spesifiserer datatypen og selve elementene. Her ser du et eksempel med `nums_f`, en matrise med flyttall:
>>> from array import array
>>> nums_f = array('f',[1.5,4.5,7.5,2.5])
>>> nums_f
array('f', [1.5, 4.5, 7.5, 2.5])
Du kan få tilgang til elementer i en matrise på samme måte som i en liste:
>>> nums_f[0] 1.5
Matriser kan endres, så du kan oppdatere dem:
>>> nums_f[0]=3.5
>>> nums_f
array('f', [3.5, 4.5, 7.5, 2.5])
Men du kan ikke endre et element til å være av en annen datatype:
>>> nums_f[0]='null' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be real number, not str
Strenger
I Python er strenger uforanderlige samlinger av Unicode-tegn. I motsetning til noen andre programmeringsspråk har ikke Python en dedikert datatype for enkelttegn. Derfor er et tegn også en streng med lengde én.
Som nevnt er strenger uforanderlige:
>>> str_1 = 'python' >>> str_1[0] = 'c' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Python-strenger støtter slicing og har flere metoder for å formatere dem. Her er noen eksempler:
>>> str_1[1:4] 'yth' >>> str_1.title() 'Python' >>> str_1.upper() 'PYTHON' >>> str_1.swapcase() 'PYTHON'
⚠ Husk at alle operasjoner ovenfor returnerer en ny kopi av strengen og endrer ikke den opprinnelige strengen. Hvis du er interessert, kan du utforske mer om strengoperasjoner i Python.
Sett
I Python er sett samlinger av unike, hashbare elementer. Du kan bruke standard settoperasjoner som union, snitt og differanse:
>>> set_1 = {3,4,5,7}
>>> set_2 = {4,6,7}
>>> set_1.union(set_2)
{3, 4, 5, 6, 7}
>>> set_1.intersection(set_2)
{4, 7}
>>> set_1.difference(set_2)
{3, 5}
Sett er som standard endringsbare, så du kan legge til og fjerne elementer:
>>> set_1.add(10)
>>> set_1
{3, 4, 5, 7, 10}
📚 Les mer om sett i Python: En komplett guide med kodeeksempler.
Frosne Sett
Hvis du trenger et uforanderlig sett, kan du bruke et frossent sett. Du kan lage et frossent sett fra et eksisterende sett eller andre iterable:
>>> frozenset_1 = frozenset(set_1)
>>> frozenset_1
frozenset({3, 4, 5, 7, 10})
Fordi `frozenset_1` er frossent, vil et forsøk på å legge til elementer resultere i en feilmelding:
>>> frozenset_1.add(15) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'frozenset' object has no attribute 'add'
Ordbøker
En ordbok i Python fungerer som en hash-map. Ordbøker brukes til å lagre nøkkel-verdi-par. Nøklene i en ordbok må være hashbare, det vil si at hash-verdien ikke skal endre seg.
Du kan få tilgang til verdier ved hjelp av nøkler, legge til nye elementer og fjerne eksisterende elementer med raske operasjoner. Det finnes flere innebygde metoder for å utføre disse operasjonene:
>>> favoritter = {'bok':'Orlando'}
>>> favoritter
{'bok': 'Orlando'}
>>> favoritter['forfatter']='Virginia Woolf'
>>> favoritter
{'bok': 'Orlando', 'forfatter': 'Virginia Woolf'}
>>> favoritter.pop('forfatter')
'Virginia Woolf'
>>> favoritter
{'bok': 'Orlando'}
OrderedDict
Selv om Python-ordbøker gir nøkkel-verdi-mapping, er de i utgangspunktet uordnet. Siden Python 3.7 er rekkefølgen for innsetting bevart, men du kan gjøre dette mer eksplisitt med `OrderedDict` fra `collections`-modulen.
Som vist, bevarer `OrderedDict` rekkefølgen på nøklene:
>>> from collections import OrderedDict
>>> od = OrderedDict()
>>> od['første']='en'
>>> od['andre']='to'
>>> od['tredje']='tre'
>>> od
OrderedDict([('første', 'en'), ('andre', 'to'), ('tredje', 'tre')])
>>> od.keys()
odict_keys(['første', 'andre', 'tredje'])
Defaultdict
Nøkkelfeil er vanlige når man jobber med Python-ordbøker. Hver gang du prøver å få tilgang til en nøkkel som ikke finnes i ordboken, vil du få et `KeyError`-unntak. Med `defaultdict` fra `collections`-modulen kan du håndtere dette. Hvis du prøver å få tilgang til en nøkkel som ikke finnes, vil den legges til med en standardverdi.
>>> from collections import defaultdict >>> priser = defaultdict(int) >>> priser['gulrøtter'] 0
Stabler
En stack (stabel) er en LIFO-datastruktur (Last-In-First-Out). Du kan utføre følgende operasjoner på en stabel:
- Legge til elementer på toppen av stabelen (push)
- Fjerne elementer fra toppen av stabelen (pop)
Her er et eksempel som viser hvordan push- og pop-operasjoner fungerer:
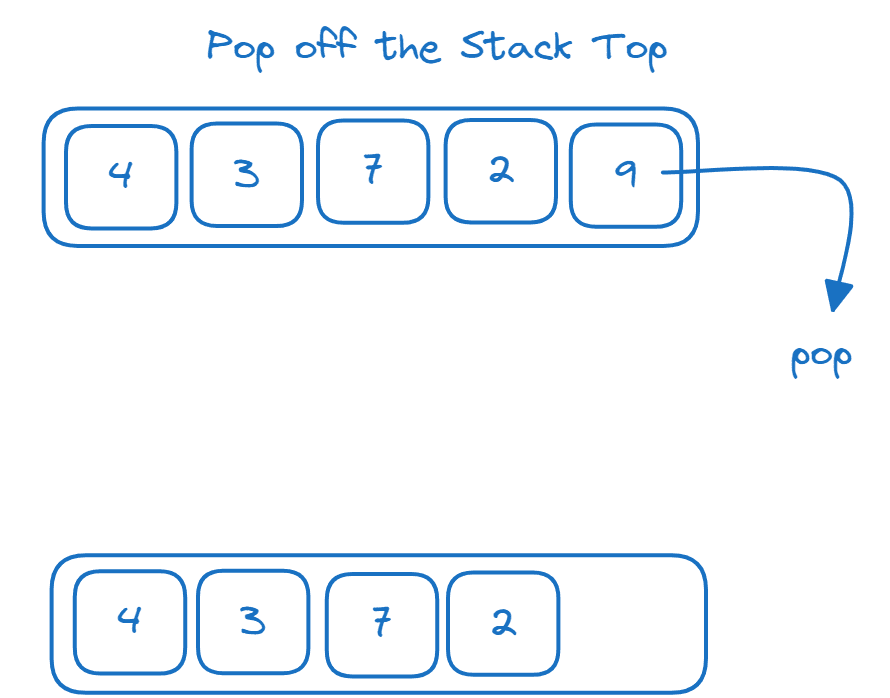
Hvordan Implementere en Stabel Ved Hjelp av en Liste
I Python kan vi implementere en stabel ved å bruke en liste.
| Operasjon på Stabel | Tilsvarende Listeoperasjon |
| Push (Legge til på toppen) | Legg til på slutten av listen med `append()` |
| Pop (Fjerne fra toppen) | Fjern og returner det siste elementet med `pop()` |
Følgende kodeeksempel viser hvordan vi kan etterligne oppførselen til en stabel ved hjelp av en liste:
>>> l_stk = [] >>> l_stk.append(4) >>> l_stk.append(3) >>> l_stk.append(7) >>> l_stk.append(2) >>> l_stk.append(9) >>> l_stk [4, 3, 7, 2, 9] >>> l_stk.pop() 9
Hvordan Implementere en Stabel Ved Hjelp av en Deque
En annen måte å implementere en stabel er å bruke `deque` fra `collections`-modulen. `Deque` står for «double-ended queue» og støtter tillegg og fjerning av elementer fra begge ender.
For å etterligne en stabel kan vi:
- Legge til elementer på slutten av `deque` ved hjelp av `append()`
- Fjerne det sist lagte elementet ved hjelp av `pop()`
>>> from collections import deque >>> stk = deque() >>> stk.append(4) >>> stk.append(3) >>> stk.append(7) >>> stk.append(2) >>> stk.append(9) >>> stk deque([4, 3, 7, 2, 9]) >>> stk.pop() 9
Køer
En kø er en FIFO-datastruktur (First-In-First-Out). Elementer legges til på slutten av køen og fjernes fra begynnelsen (hodet) som vist her:
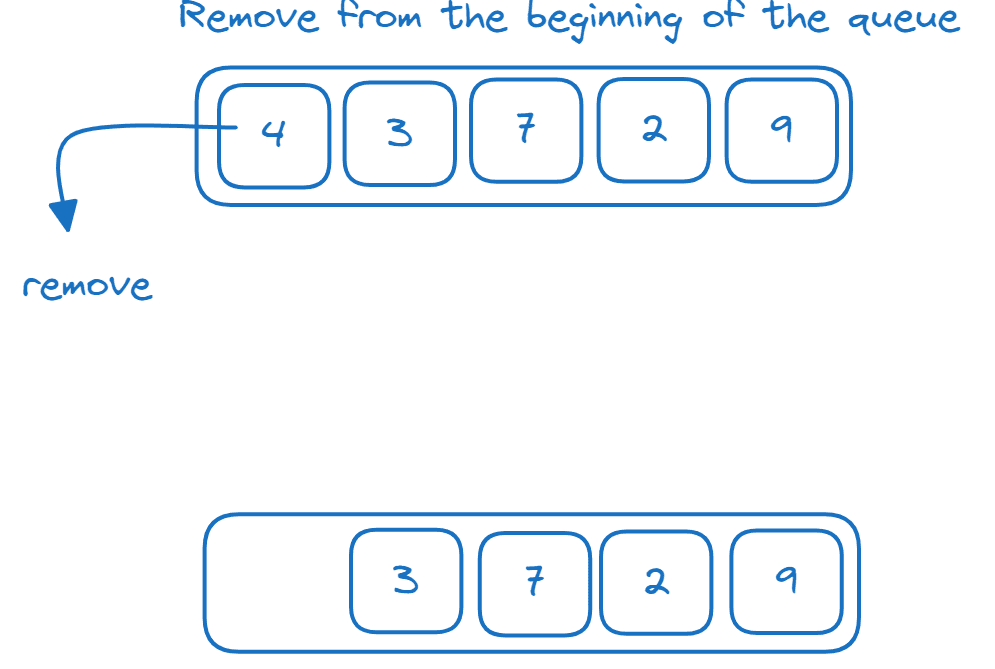
Vi kan implementere en kø ved å bruke en `deque`:
- Legg til elementer på slutten av køen ved hjelp av `append()`
- Bruk `popleft()`-metoden for å fjerne elementet fra begynnelsen av køen
>>> from collections import deque >>> q = deque() >>> q.append(4) >>> q.append(3) >>> q.append(7) >>> q.append(2) >>> q.append(9) >>> q.popleft() 4
Dynger
I denne delen skal vi diskutere binære dynger, med fokus på min-dynger.
En min-dyng er et komplett binært tre, der hver node er mindre enn sine barn. La oss bryte ned hva et komplett binært tre betyr:
- Et binært tre er en trestruktur hvor hver node har maksimalt to barn.
- «Komplett» betyr at treet er helt fylt, bortsett fra kanskje det siste nivået. Hvis det siste nivået er delvis fylt, fylles det fra venstre mot høyre.
Fordi hver node er mindre enn sine barn, vil roten i en min-dyng alltid være det minste elementet.
Her er et eksempel på en min-dyng:
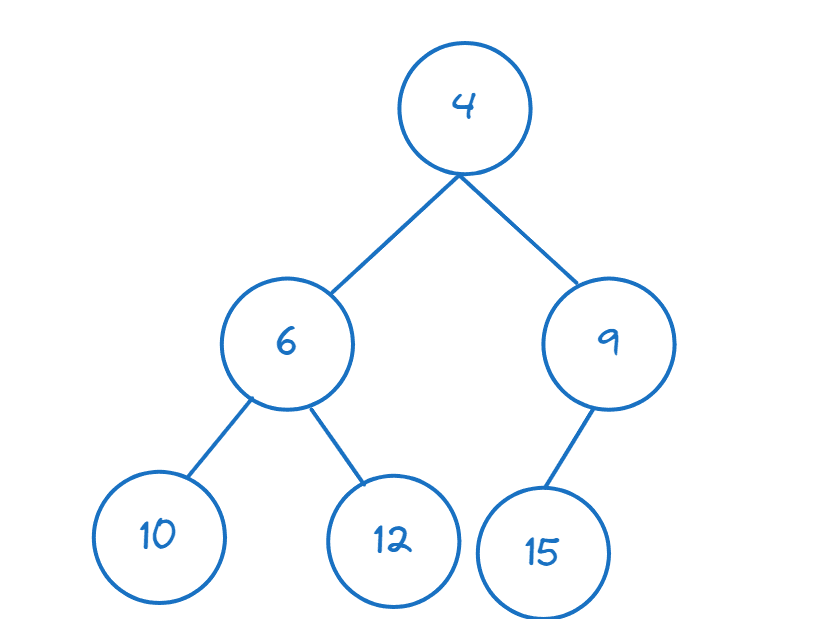
I Python hjelper `heapq`-modulen oss med å konstruere dynger og utføre operasjoner på dem. La oss importere nødvendige funksjoner:
>>> from heapq import heapify, heappush, heappop
Hvis du har en liste eller en annen iterabel, kan du lage en dyng ved å kalle `heapify()`:
>>> tall = [11,8,12,3,7,9,10] >>> heapify(tall)
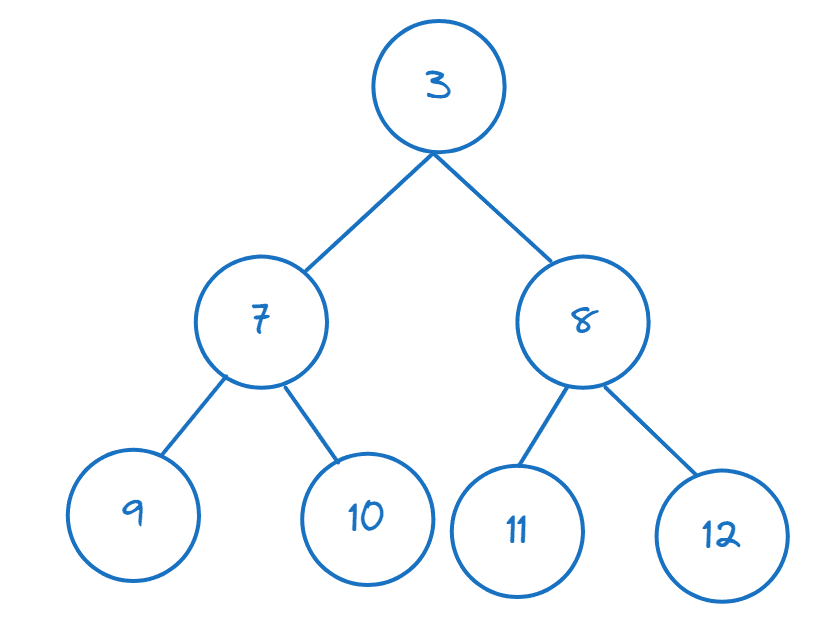
Du kan sjekke at det første elementet er det minste:
>>> tall[0] 3
Hvis du legger til et nytt element i dyngen, vil nodene omorganiseres for å opprettholde min-dyng-egenskapen.
>>> heappush(tall,1)
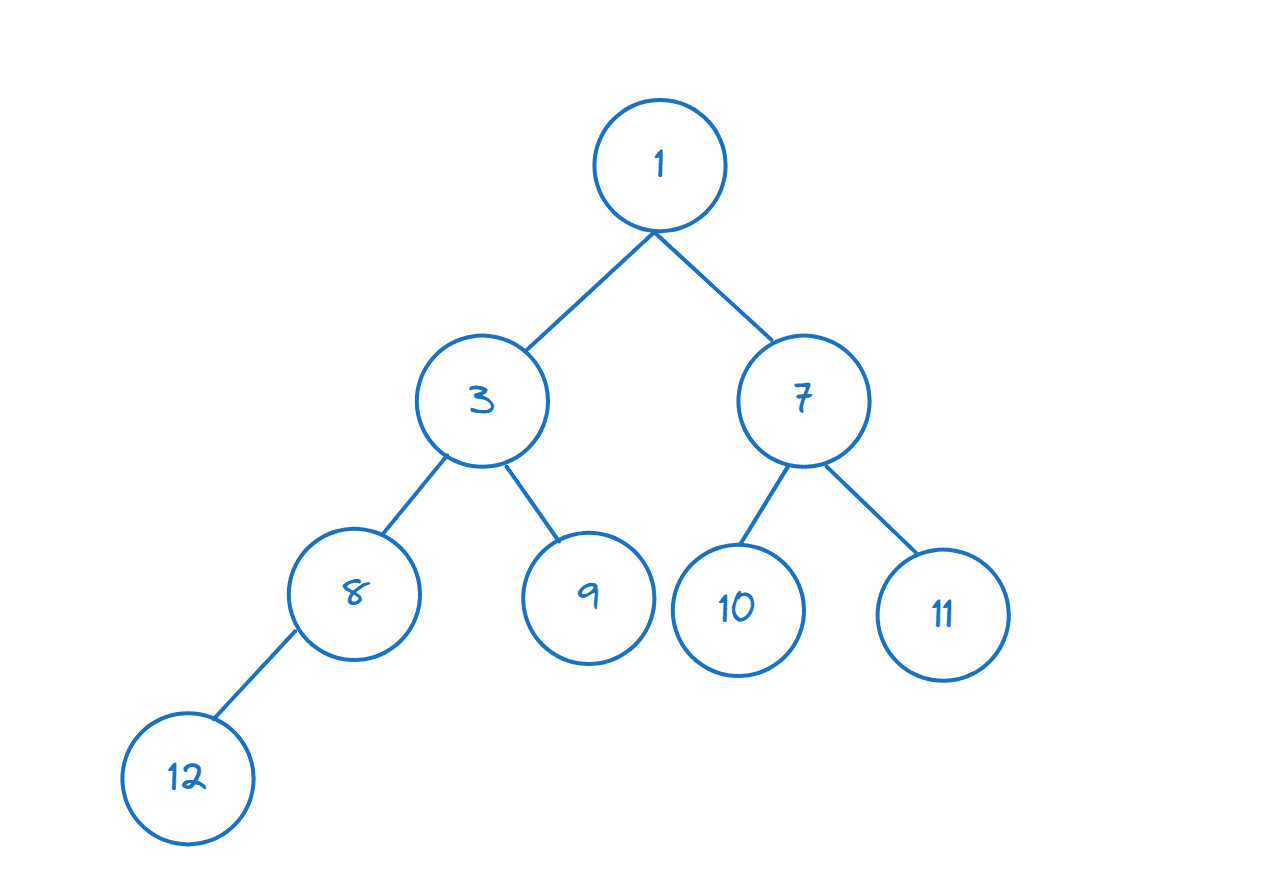
Etter å ha lagt til 1, ser vi at `tall[0]` nå returnerer 1, som er det minste elementet:
>>> tall[0] 1
Du kan fjerne elementer fra min-dyngen med `heappop()`:
>>> while tall: ... print(heappop(tall)) ...
# Output 1 3 7 8 9 10 11 12
Max-Dynger i Python
Nå som du kjenner til min-dynger, kan du kanskje gjette hvordan man implementerer en max-dyng?
Vi kan konvertere en min-dyng til en max-dyng ved å gange hvert tall med -1. Negerte tall i en min-dyng tilsvarer de opprinnelige tallene i en max-dyng.
I Python kan vi gange elementene med -1 når vi legger dem til i dyngen med `heappush()`:
>>> maxHeap = [] >>> heappush(maxHeap,-2) >>> heappush(maxHeap,-5) >>> heappush(maxHeap,-7)
Rotnoden (multiplisert med -1) vil være det maksimale elementet:
>>> -1*maxHeap[0] 7
Når du fjerner elementer fra dyngen, bruk `heappop()` og multipliser med -1 for å få den opprinnelige verdien:
>>> while maxHeap: ... print(-1*heappop(maxHeap)) ...
# Output 7 5 2
Prioriterte Køer
La oss avslutte med å se på prioritetskøer i Python.
Som vi vet, fjernes elementer fra en vanlig kø i den rekkefølgen de ble lagt til. Men en prioritetskø betjener elementer basert på prioritet. Dette er nyttig i planleggingsapplikasjoner. Elementet med høyest prioritet returneres først.
Vi kan definere prioritet ved å bruke nøkler. Her vil vi bruke numeriske vekter for nøklene.
Implementere Prioriterte Køer med Heapq
Her er hvordan du implementerer en prioritetskø ved hjelp av `heapq` og en Python-liste:
>>> from heapq import heappush,heappop >>> pq = [] >>> heappush(pq,(2,'skrive')) >>> heappush(pq,(1,'lese')) >>> heappush(pq,(3,'kode')) >>> while pq: ... print(heappop(pq)) ...
Når elementene fjernes, betjener køen elementet med høyest prioritet (1,’lese») først, deretter (2,’skrive») og til slutt (3,’kode»).
# Output (1, 'lese') (2, 'skrive') (3, 'kode')
Implementere Prioritetskøer med PriorityQueue
For å implementere en prioritetskø kan vi også bruke `PriorityQueue`-klassen fra `queue`-modulen. Denne bruker også en dyng internt.
Her er den tilsvarende implementeringen med `PriorityQueue`:
>>> from queue import PriorityQueue >>> pq = PriorityQueue() >>> pq.put((2,'skrive')) >>> pq.put((1,'lese')) >>> pq.put((3,'kode')) >>> pq <queue.PriorityQueue object at 0x00BDE730> >>> while not pq.empty(): ... print(pq.get()) ...
# Output (1, 'lese') (2, 'skrive') (3, 'kode')
Oppsummering
I denne opplæringen har du lært om de ulike innebygde datastrukturene i Python og operasjonene de støtter. Vi har også sett på implementasjoner av stabler, køer og prioriterte køer ved hjelp av funksjonalitet fra `collections`-modulen.
Nå kan du utforske flere nybegynnervennlige Python-prosjekter.