Utforsk datavitenskapens verden
Datavitenskap appellerer til de som liker å løse komplekse problemer og oppdage skjulte mønstre i tilsynelatende kaos.
Det kan sammenlignes med å søke etter nåler i en høystakk, men uten å måtte bli skitten på hendene. Datavitenskapsfolk bruker avanserte verktøy med fargerike visualiseringer, og analyserer store mengder tall for å avdekke verdifull innsikt som kan være avgjørende for virksomheter.
En typisk dataviters verktøykasse bør inkludere minst ett element fra hver av disse kategoriene: relasjonsdatabaser, NoSQL-databaser, rammeverk for stordata, visualiseringsverktøy, skrapingsverktøy, programmeringsspråk, IDE-er og verktøy for dyp læring.
Relasjonelle databaser
En relasjonsdatabase er organisert i tabeller med definerte attributter. Disse tabellene kan kobles sammen for å skape relasjoner og begrensninger, og dermed danne en datamodell. For å arbeide med slike databaser brukes ofte SQL (Structured Query Language).
Programvare som administrerer strukturen og dataene i relasjonsdatabaser kalles RDBMS (Relational DataBase Management Systems). Det finnes mange alternativer, og de mest populære har i det siste begynt å legge større vekt på datavitenskap, med funksjonalitet for å håndtere store datamengder og anvende dataanalyse og maskinlæringsteknikker.
SQL Server
Microsofts RDBMS har utviklet seg over 20 år, med kontinuerlig forbedring av bedriftsfunksjonalitet. Fra 2016 har SQL Server tilbudt en rekke tjenester som inkluderer støtte for integrert R-kode. I 2017 ble R Services omdøpt til Machine Language Services, og støtte for Python-språket ble lagt til.
Disse tilleggene er rettet mot datavitere som kanskje ikke har erfaring med Transact-SQL, det opprinnelige spørrespråket for Microsoft SQL Server.
SQL Server er ikke et gratis produkt. Lisenser kan kjøpes for installasjon på en Windows Server (prisen avhenger av antall brukere), eller det kan benyttes som en betalt tjeneste via Microsoft Azure-skyen. Det er relativt enkelt å lære seg Microsoft SQL Server.
MySQL
Innenfor åpen kildekode er MySQL en av de mest populære RDBMS-ene. Selv om Oracle nå eier den, er den fortsatt gratis og åpen kildekode under GNU General Public License. De fleste webapplikasjoner bruker MySQL som datalagring takket være dens samsvar med SQL-standarden.
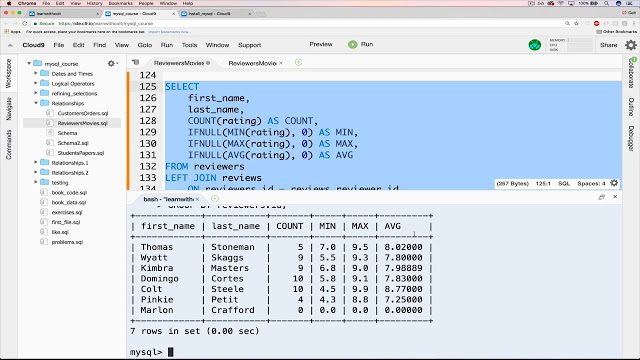
Enkel installasjon, et stort utviklerfellesskap, omfattende dokumentasjon og tredjepartsverktøy som phpMyAdmin bidrar til populariteten ved å forenkle daglige administrative oppgaver. Selv om MySQL ikke har innebygde funksjoner for dataanalyse, tillater åpenheten integrasjon med de fleste visualiserings-, rapporterings- og business intelligence-verktøy.
PostgreSQL
Et annet åpen kildekode RDBMS-alternativ er PostgreSQL. Selv om det ikke er like utbredt som MySQL, utmerker PostgreSQL seg med sin fleksibilitet, utvidbarhet og støtte for komplekse spørringer som går utover enkle SELECT-, WHERE- og GROUP BY-setninger.
Disse egenskapene gjør den populær blant datavitere. En annen viktig funksjon er støtten for flere miljøer, som tillater bruk i skyen, lokale miljøer eller hybride kombinasjoner.
PostgreSQL kan kombinere online analytisk prosessering (OLAP) med online transaksjonsbehandling (OLTP) i en modus som kalles hybrid transaksjonell/analytisk prosessering (HTAP). Den er også velegnet for stordata på grunn av tillegg som PostGIS for geografiske data og JSON-B for dokumenter. PostgreSQL støtter også ustrukturerte data, og fungerer dermed både som en SQL- og NoSQL-database.
NoSQL-databaser
Også kalt ikke-relasjonelle databaser, gir denne typen datalager raskere tilgang til data som ikke er tabellformet. Eksempler er grafer, dokumenter, brede kolonner og nøkkelverdier. NoSQL-datalagring prioriterer tilgjengelighet, partisjonering og tilgangshastighet over datakonsistens.
Siden det ikke benyttes SQL i NoSQL-databaser, er det nødvendig å bruke lavnivåspråk for å hente data, og det finnes ikke noe standardspråk som er like utbredt som SQL. Det finnes heller ingen standardspesifikasjoner for NoSQL. Ironisk nok begynner enkelte NoSQL-databaser å tilby støtte for SQL-skript.
MongoDB
MongoDB er et populært NoSQL-databasesystem som lagrer data i form av JSON-dokumenter. Fokuset ligger på skalerbarhet og fleksibilitet for lagring av data på en ustrukturert måte. Det betyr at det ikke finnes en fast feltliste som må følges for alle lagrede elementer. I tillegg kan datastrukturen endres over tid, noe som i relasjonsdatabaser kan medføre stor risiko for applikasjoner i drift.

Teknologien i MongoDB tillater indeksering, ad-hoc-spørringer og aggregering, noe som gir et sterkt grunnlag for dataanalyse. Databasens distribuerte natur gir høy tilgjengelighet, skalering og geografisk distribusjon uten behov for kompliserte verktøy.
Redis
Redis er et annet åpen kildekode NoSQL-alternativ. Det er i hovedsak et datastrukturlager som opererer i minnet, og fungerer i tillegg til databasetjenester som bufferminne og meldingsmegler.

Den støtter et bredt utvalg av ukonvensjonelle datastrukturer, inkludert hasher, geospatiale indekser, lister og sorterte sett. Det er godt egnet for datavitenskap på grunn av sin høye ytelse i dataintensive oppgaver som datasettkryss, sortering av lange lister og generering av komplekse rangeringer. Redis’ enestående ytelse skyldes at den opererer i minnet. Det kan konfigureres til å lagre data selektivt.
Rammeverk for stordata
Tenk deg at du skal analysere data fra Facebook-brukere i løpet av en måned. Det er bilder, videoer, meldinger, alt sammen. Med over 500 terabyte data som legges til det sosiale nettverket hver dag, er det vanskelig å forestille seg volumet av en hel måned med data.
For å håndtere slike enorme datamengder effektivt, trengs et passende rammeverk som kan behandle data i en distribuert arkitektur. To av de ledende rammeverkene er Hadoop og Spark.
Hadoop
Som et rammeverk for stordata, håndterer Hadoop kompleksiteten knyttet til henting, behandling og lagring av store datamengder. Hadoop opererer i et distribuert miljø med dataklynger som behandler enkle algoritmer. En orkestreringsalgoritme, kalt MapReduce, deler store oppgaver i mindre deler, som distribueres mellom tilgjengelige klynger.

Hadoop anbefales for datalager i bedriftsklassen som krever rask tilgang og høy tilgjengelighet til en lav pris. Det krever imidlertid en Linux-administrator med inngående Hadoop-kunnskap for å holde rammeverket i drift.
Spark
Hadoop er ikke det eneste rammeverket for håndtering av stordata. Et annet stort navn er Spark. Spark-motoren ble utviklet for å overgå Hadoop når det gjelder analysehastighet og brukervennlighet. Sammenligninger viser at Spark kan kjøre opptil 10 ganger raskere enn Hadoop ved bruk av disk, og 100 ganger raskere ved drift i minnet. Det krever også færre maskiner for å behandle samme datamengde.

I tillegg til hastighet, er en annen fordel med Spark støtten for strømbehandling. Denne typen databehandling, også kalt sanntidsbehandling, innebærer kontinuerlig inn- og utmating av data.
Visualiseringsverktøy
En vanlig spøk blant datavitere er at hvis du «torturerer» data lenge nok, vil de avsløre det du trenger å vite. I denne sammenhengen betyr «tortur» å manipulere data gjennom transformering og filtrering for å kunne visualisere dem bedre. Det er her visualiseringverktøy kommer inn. Disse verktøyene henter forhåndsbehandlede data fra flere kilder og viser informasjonen i grafiske, lett forståelige former.
Det finnes hundrevis av verktøy i denne kategorien. Det mest brukte er Microsoft Excel og dets diagramverktøy. Excel-diagrammer er tilgjengelige for alle som bruker Excel, men de har begrenset funksjonalitet. Det samme gjelder andre regnearkapplikasjoner som Google Sheets og Libre Office. Men her fokuserer vi på mer spesialiserte verktøy, spesielt utviklet for business intelligence (BI) og dataanalyse.
Power BI
Microsoft lanserte for ikke lenge siden sin visualiseringsapplikasjon Power BI. Den kan hente data fra ulike kilder, som tekstfiler, databaser, regneark og en rekke nettbaserte datatjenester, inkludert Facebook og Twitter. Dataene brukes til å generere oversikter fylt med diagrammer, tabeller, kart og andre visualiseringsobjekter. Objektene er interaktive, slik at du kan klikke på en dataserie i et diagram for å velge den og bruke den som et filter for andre objekter.
Power BI er en kombinasjon av en Windows-skrivebordsapplikasjon (del av Office 365-pakken), en webapplikasjon og en webtjeneste for å publisere og dele oversikter med andre brukere. Tjenesten lar deg opprette og administrere tillatelser for å gi tilgang til bestemte personer.
Tableau
Tableau er et annet alternativ for å lage interaktive oversikter fra flere datakilder. Det finnes en skrivebordsversjon, en nettversjon og en webtjeneste for deling av oversikter. Den hevder å fungere «på samme måte som du tenker», og er lett å bruke for ikke-teknisk personell, med mange opplæringsprogrammer og online videoer tilgjengelig.
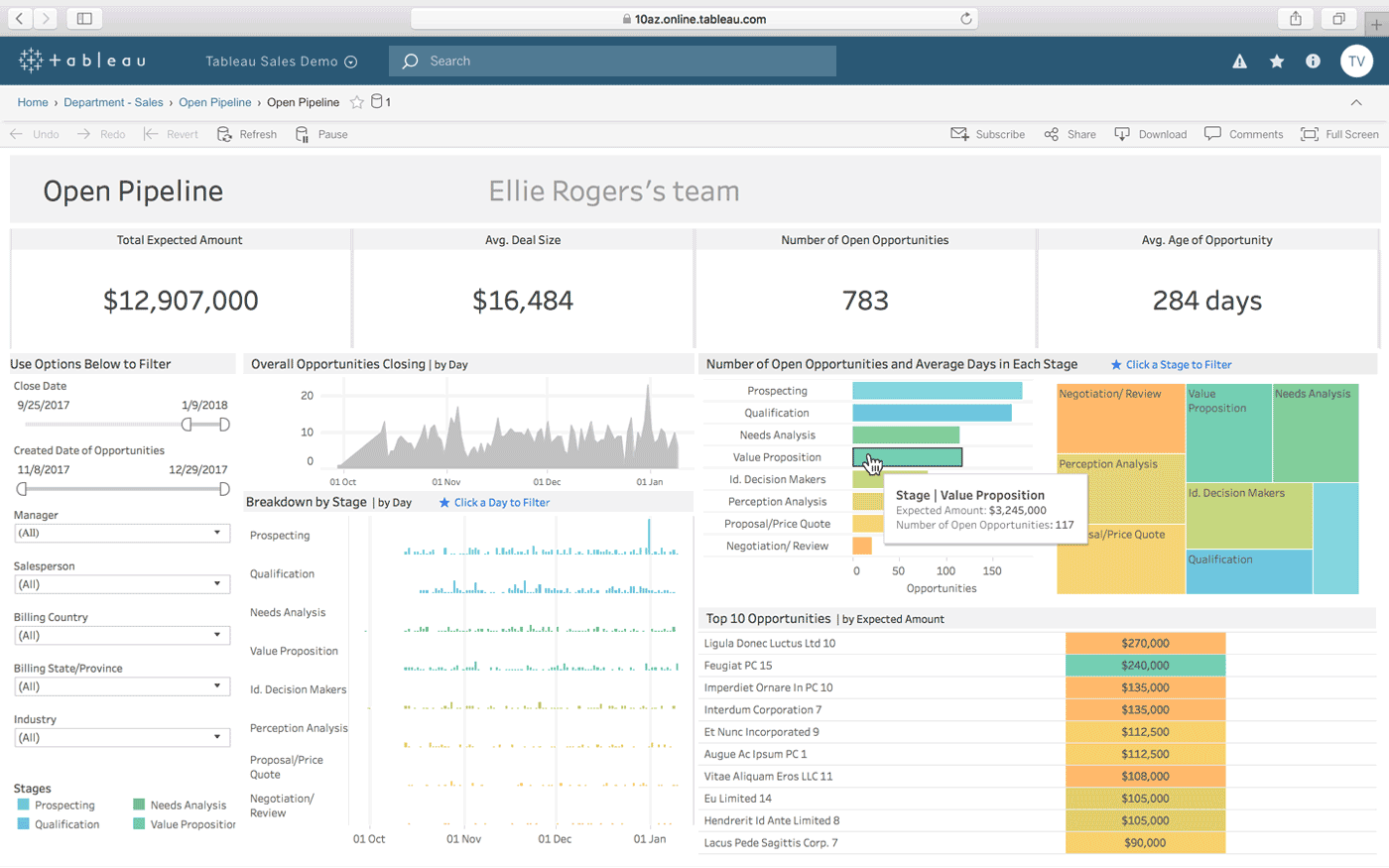
Noen av Tableaus mest fremtredende funksjoner er ubegrensede datatilkoblinger, live-data, minnebasert data og mobiloptimalisert design.
QlikView
QlikView tilbyr et brukervennlig grensesnitt for å hjelpe analytikere med å avdekke ny innsikt fra eksisterende data gjennom visuelle elementer som er enkle å forstå for alle.
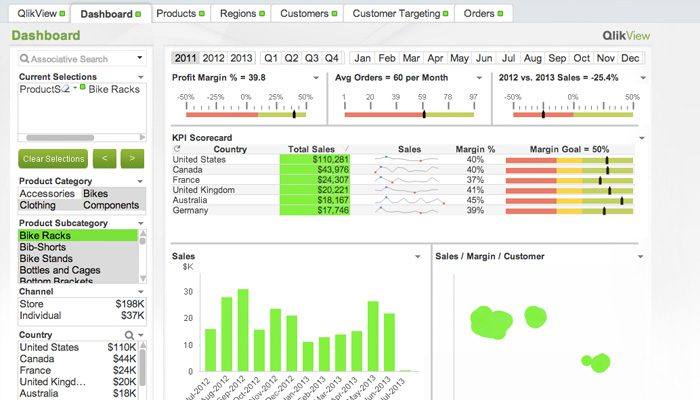
Dette verktøyet er kjent for å være en av de mest fleksible business intelligence-plattformene. En funksjon kalt Associative Search hjelper deg med å fokusere på viktig data, og sparer tid du ellers ville brukt på å lete. Med QlikView kan du samarbeide med partnere i sanntid og utføre sammenlignende analyser. All relevant data kan kombineres i en app, med sikkerhetsfunksjoner for å begrense tilgangen.
Skrapingsverktøy
I den tidlige internett-æraen begynte webcrawlere å samle informasjon. Etter hvert som teknologien utviklet seg, endret begrepet webcrawling seg til web-skraping, men prinsippet forble det samme: automatisk uthenting av informasjon fra nettsteder. Web-skraping utføres med automatiserte prosesser, eller roboter, som hopper fra en nettside til en annen, trekker ut data og eksporterer dem til ulike formater eller setter dem inn i databaser for videre analyse.
Her er en oversikt over tre av de mest populære web-skraperne som er tilgjengelige i dag.
Octoparse
Octoparse web scraper har innebygde verktøy for å hente informasjon fra nettsider som gjør det vanskelig for skraperoboter å jobbe. Det er en skrivebordsapplikasjon som ikke krever programmering, med et brukervennlig grensesnitt som lar deg visualisere uthentingsprosessen med en grafisk arbeidsflytdesigner.
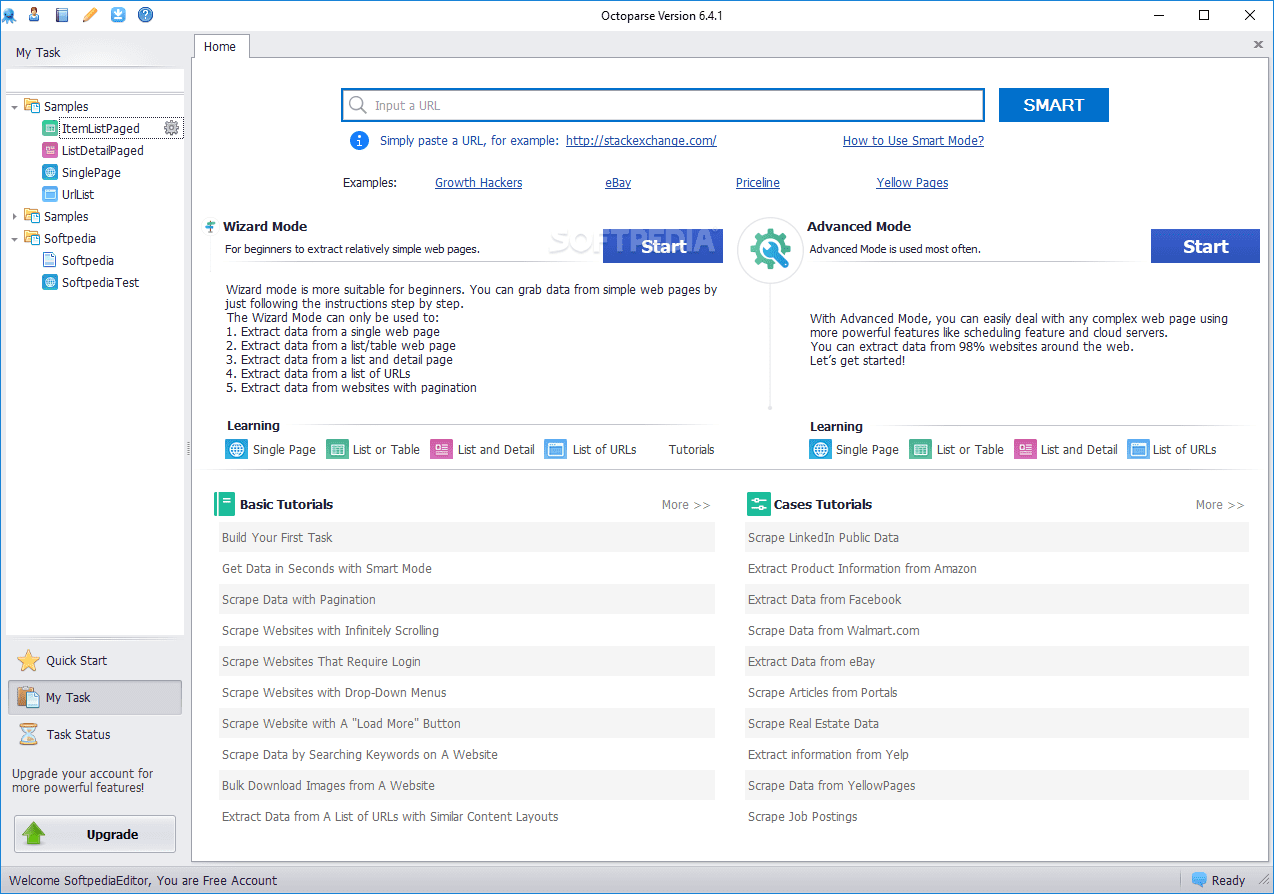
I tillegg til den frittstående applikasjonen tilbyr Octoparse en skybasert tjeneste for raskere datauthenting. Brukere kan oppleve en 4x til 10x hastighetsøkning ved bruk av skytjenesten i stedet for skrivebordsapplikasjonen. Skrivebordsversjonen av Octoparse er gratis. For skytjenesten må du velge en betalingsplan.
Content Grabber
Hvis du er på utkikk etter et funksjonsrikt skrapingsverktøy, bør du se nærmere på Content Grabber. I motsetning til Octoparse, krever Content Grabber avanserte programmeringsferdigheter. Til gjengjeld får du skriptredigering, feilsøkingsgrensesnitt og andre avanserte funksjoner. Med Content Grabber kan du bruke .Net-språk for å skrive regulære uttrykk, slik at du slipper å generere uttrykkene med et innebygd verktøy.
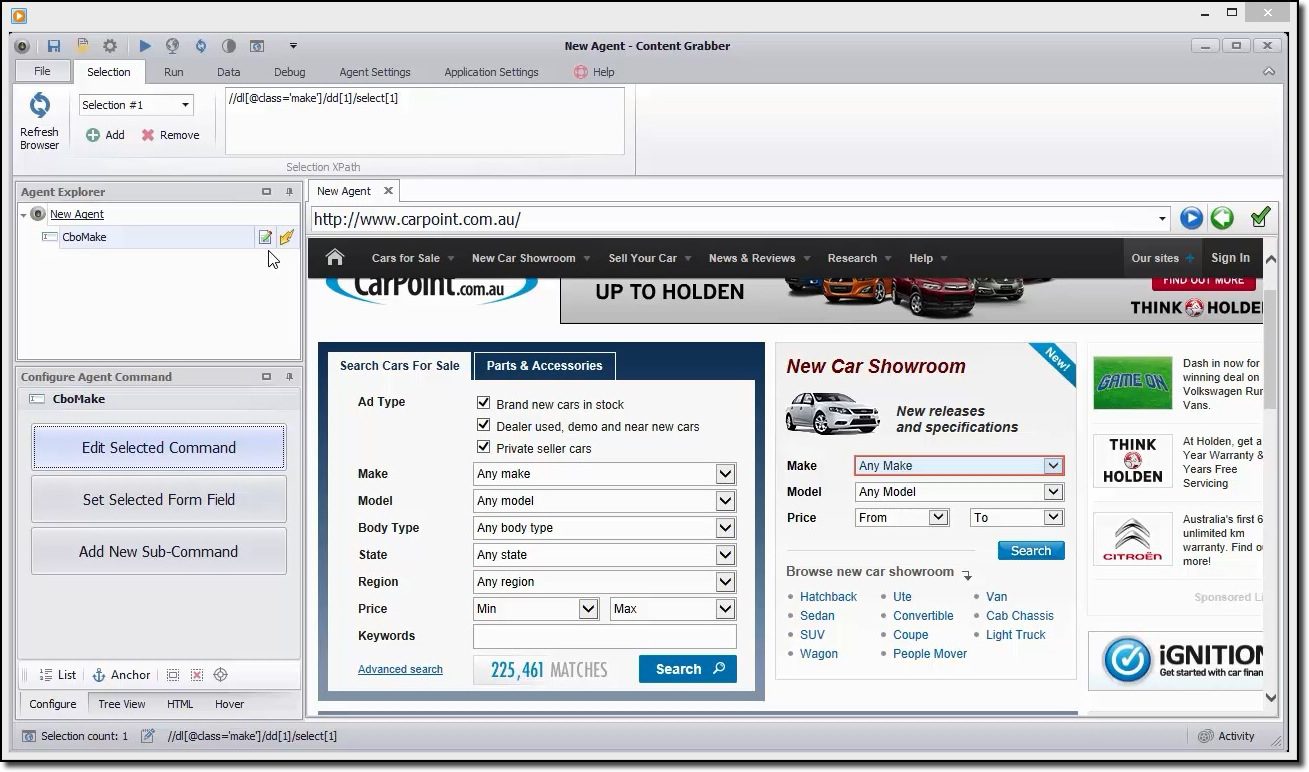
Verktøyet tilbyr et API (Application Programming Interface) som du kan bruke for å legge til skrapingsfunksjoner i skrivebords- og webapplikasjonene dine. For å bruke dette API-et må utviklere ha tilgang til Content Grabber Windows-tjenesten.
ParseHub
Denne skraperen kan håndtere et omfattende utvalg av innhold, inkludert forum, kommentarer, kalendere og kart. Den kan også håndtere sider med autentisering, Javascript, Ajax og mer. ParseHub kan brukes som en webapp eller et skrivebordsprogram som kan kjøres på Windows, macOS X og Linux.
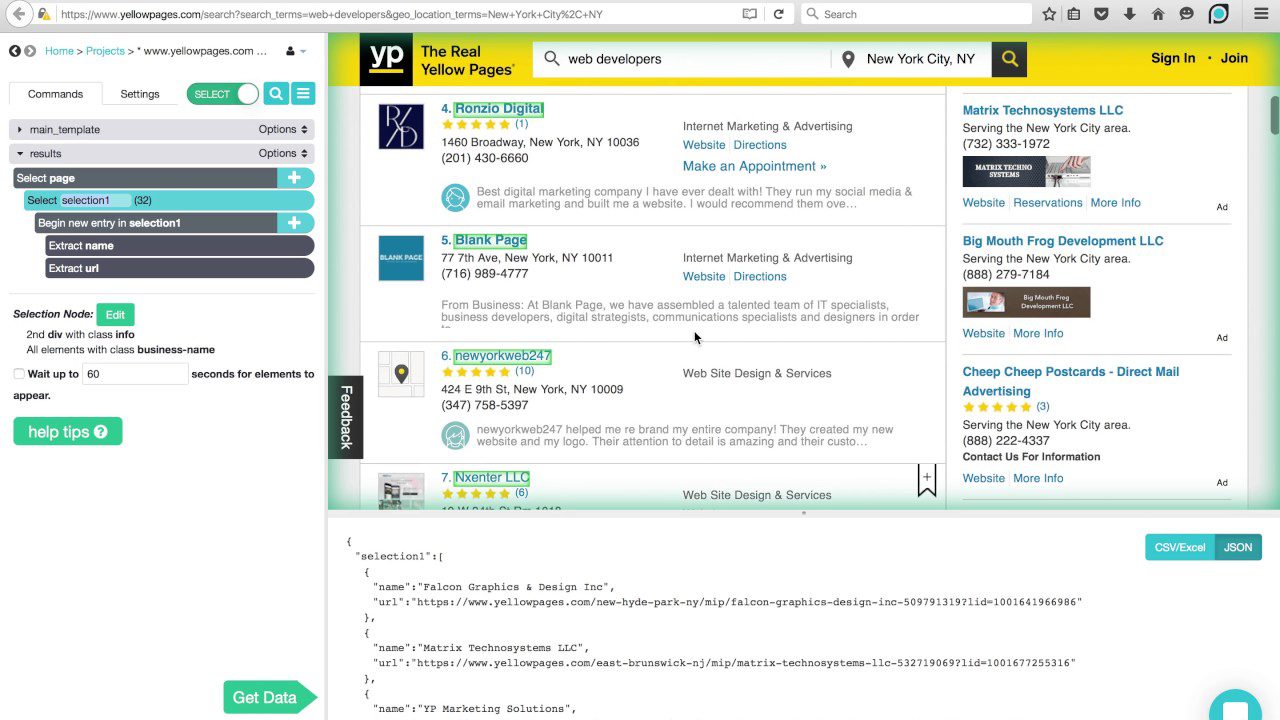
Som Content Grabber anbefales det å ha noe programmeringskunnskap for å få mest mulig ut av ParseHub. Det finnes en gratisversjon som er begrenset til 5 prosjekter og 200 sider per kjøring.
Programmeringsspråk
Akkurat som SQL ble utviklet for å brukes med relasjonsdatabaser, finnes det andre språk som er spesielt utviklet for datavitenskap. Disse språkene lar utviklere skrive programmer for å analysere store datamengder, statistikk og maskinlæring.
SQL er fortsatt en viktig ferdighet for datavitere, siden de fleste organisasjoner fortsatt har mye data i relasjonsdatabaser. De «ekte» datavitenskapelige språkene er R og Python.
Python

Python er et høynivå, tolket programmeringsspråk som er godt egnet for rask applikasjonsutvikling. Det har en enkel og lettlært syntaks som gjør at læringskurven er kort og reduserer kostnadene for programvedlikehold. Det er mange grunner til at det er det foretrukne språket for datavitenskap: skriptpotensial, detaljnivå, portabilitet og ytelse.
Dette språket er et godt utgangspunkt for datavitere som planlegger å eksperimentere før de begynner med selve dataanalysen, og som ønsker å utvikle komplette applikasjoner.
R
R-språket brukes hovedsakelig til statistisk databehandling og grafikk. Selv om det ikke er beregnet for å utvikle fullverdige applikasjoner, har R blitt svært populært de siste årene på grunn av potensialet for datautvinning og dataanalyse.

Takket være et stadig voksende bibliotek med fritt tilgjengelige pakker som utvider funksjonaliteten, kan R utføre alle typer dataanalyse, inkludert lineær/ikke-lineær modellering, klassifisering, statistiske tester, etc.
Det er ikke et lett språk å lære, men når du først har lært deg filosofien, kan du utføre statistisk databehandling som en proff.
IDE-er
Hvis du vurderer en karriere innen datavitenskap, må du velge et integrert utviklingsmiljø (IDE) som passer dine behov, siden du vil tilbringe mye tid sammen med IDE-en din.
En ideell IDE skal samle alle verktøyene du trenger i ditt daglige arbeid som koder: en tekstredigerer med syntaksutheving og autofullføring, en kraftig feilsøker, en objektleser og enkel tilgang til eksterne verktøy. Den må også være kompatibel med språket du foretrekker, så det kan være lurt å velge IDE etter at du har bestemt deg for hvilket språk du vil bruke.
Spyder
Denne generiske IDE-en er først og fremst beregnet for forskere og analytikere som også trenger å kode. For å gjøre det komfortabelt for dem, er det ikke begrenset til IDE-funksjonaliteten. Den gir også verktøy for datautforskning/visualisering og interaktiv utførelse som finnes i en vitenskapelig pakke. Redaktøren i Spyder støtter flere språk, og har også en klasseleser, vindusdeling, hopp-til-definisjon, automatisk kodefullføring og et kodeanalyseverktøy.
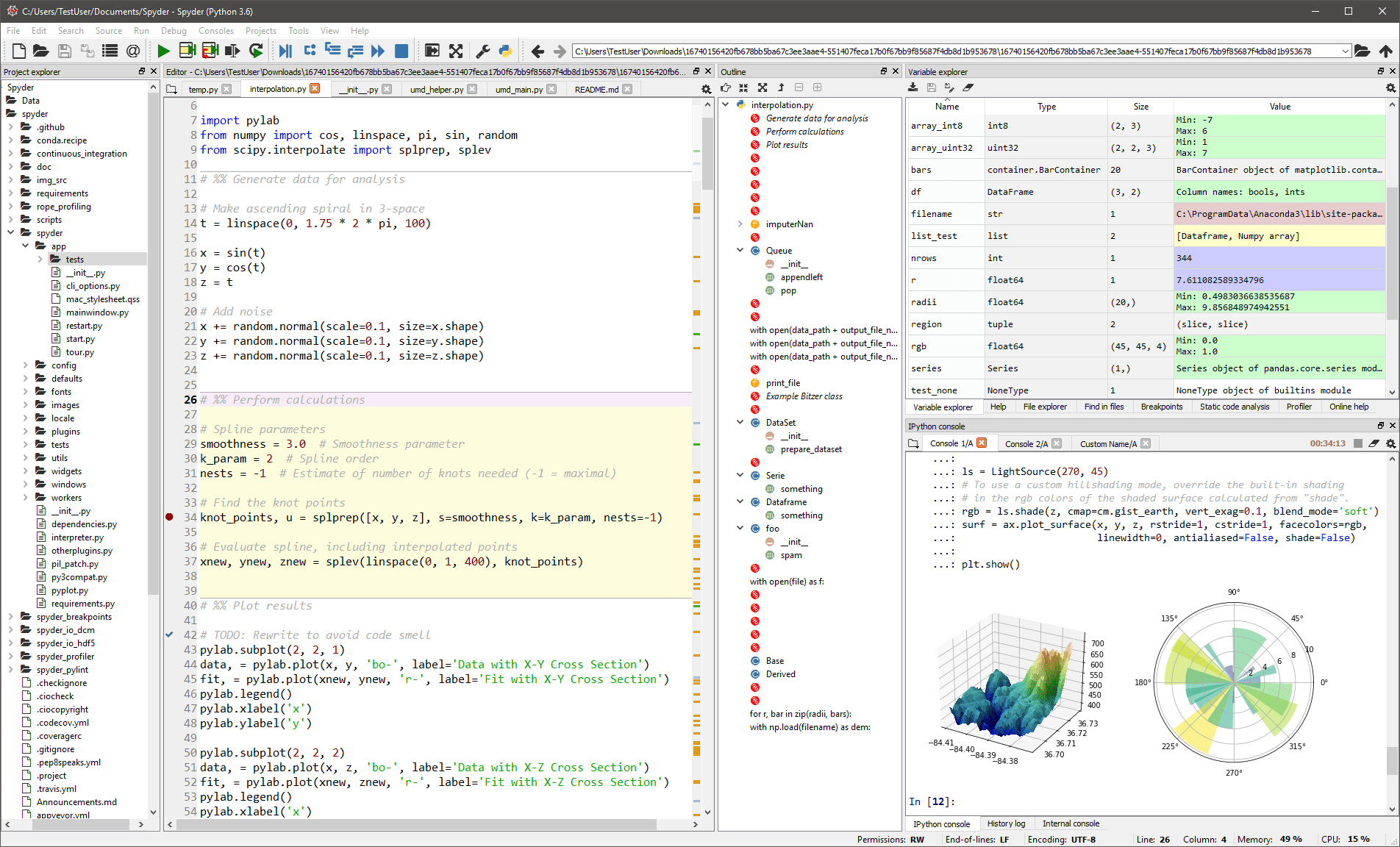
Feilsøkeren hjelper deg med å spore hver kodelinje interaktivt, og en profiler hjelper deg med å finne og eliminere ineffektivitet.
PyCharm
Hvis du programmerer i Python, er sjansen stor for at den valgte IDE-en vil være PyCharm. Den har en intelligent koderedigerer med smart søk, kodefullføring og feildeteksjon og retting. Med bare ett klikk kan du hoppe fra redigeringsprogrammet til et hvilket som helst kontekstuelt vindu, inkludert test, supermetode, implementering og erklæring. PyCharm støtter Anaconda og mange vitenskapelige pakker, som NumPy og Matplotlib.
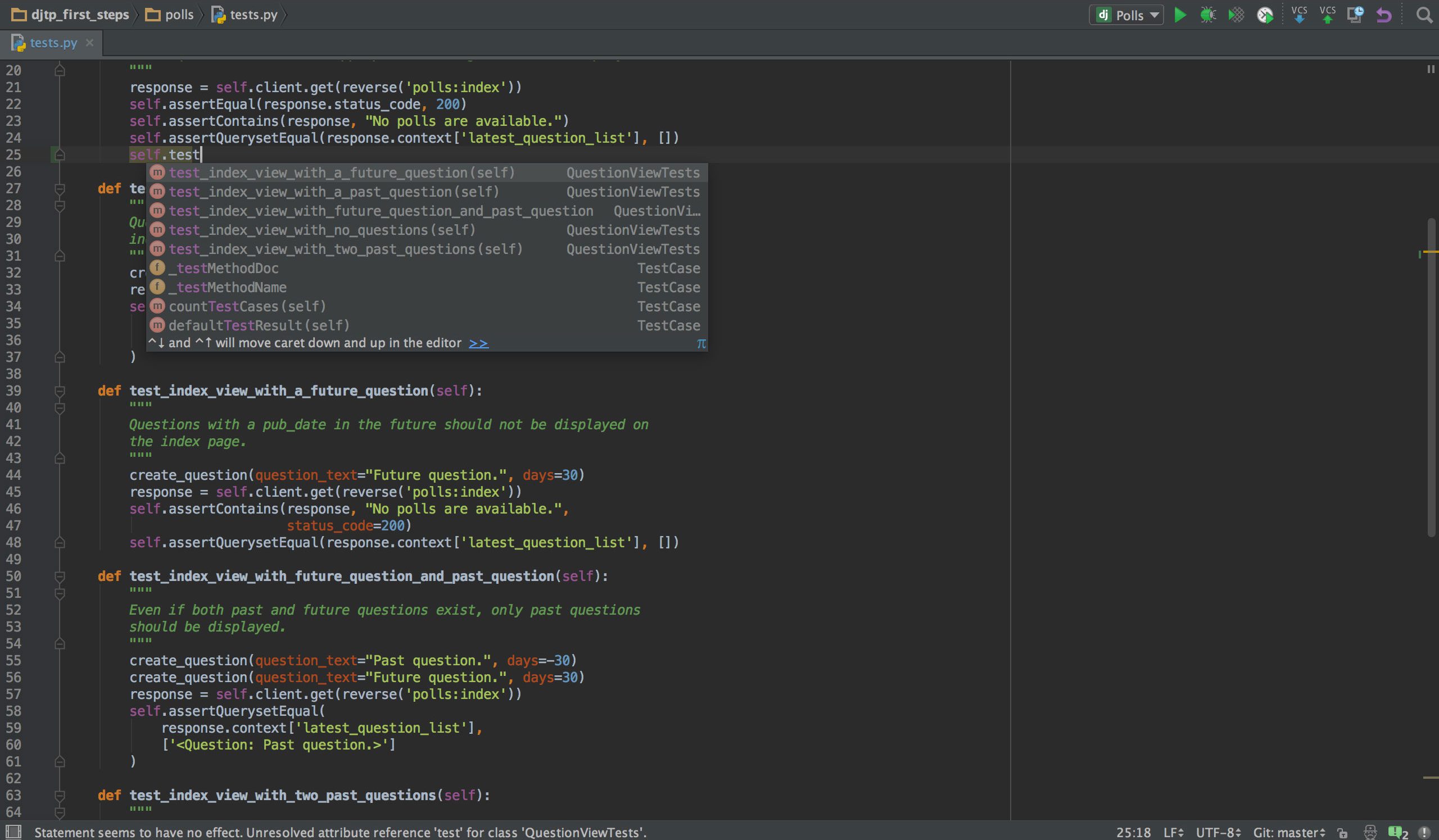
Den tilbyr integrasjon med de viktigste versjonskontrollsystemene, og også med en testløper, en profiler og en feilsøker. I tillegg integreres den også med Docker og Vagrant for å sørge for utvikling på tvers av plattformer og containerisering.
RStudio
For de datavitere som foretrekker R, er RStudio et godt IDE-valg på grunn av sine mange funksjoner. Det kan installeres på et skrivebord med Windows, macOS eller Linux, eller du kan kjøre det fra en nettleser hvis du ikke vil installere det lokalt. Begge versjonene tilbyr funksjoner som syntaksutheving, smart innrykk og kodefullføring. Det finnes en integrert datavisning som er nyttig når du skal bla gjennom tabellformet data.
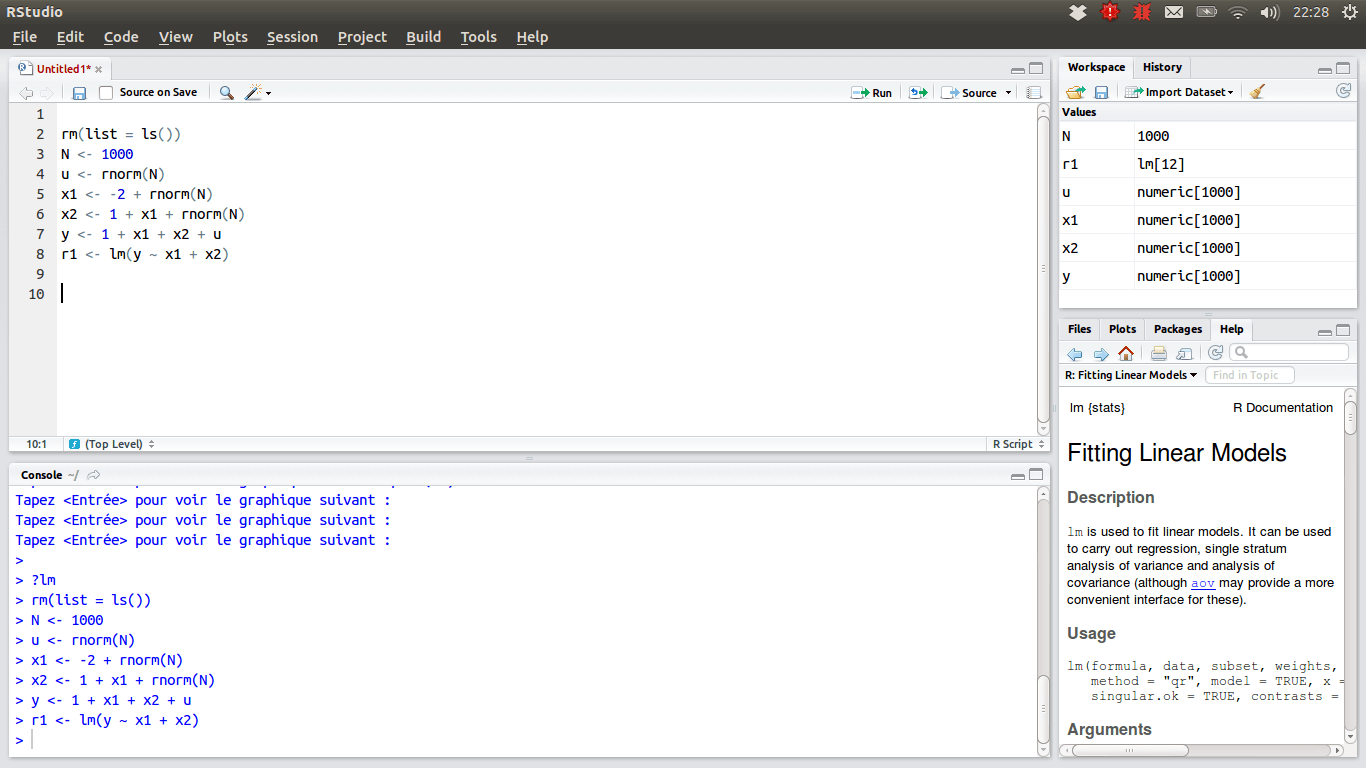
Feilsøkingsmodusen viser hvordan data oppdateres dynamisk når du kjører et program eller skript trinn for trinn. For versjonskontroll integrerer RStudio støtte for SVN og Git. En mulighet til å skrive interaktiv grafikk med Shiny- og GGplot2-bibliotekene er også et pluss.
Din egen verktøykasse
Nå har du en oversikt over verktøyene du trenger for å lykkes innen datavitenskap. Vi håper også at vi har gitt deg nok informasjon til å velge det mest hensiktsmessige alternativet i hver verktøykategori. Nå er det opp til deg. Datavitenskap er et felt i vekst, med gode muligheter for karriereutvikling. Men for å lykkes, må du følge med på endringer i trender og teknologi, da de skjer nesten daglig.