Det er forholdsvis greit å skape én enkelt maskinlæringsmodell, men å utvikle hundrevis eller tusenvis av modeller og samtidig forbedre de eksisterende, er en langt mer kompleks oppgave.
Det kan lett oppstå forvirring i en slik prosess. Denne utfordringen blir ytterligere komplisert når man jobber i team, der det er nødvendig å holde oversikt over hva hver enkelt bidrar med. For å skape orden i dette, må hele teamet følge en strukturert prosess og dokumentere sine aktiviteter. Dette er kjernen i det vi kaller MLOps.
Hva er MLOps?
Kilde: ml-ops.org
Ifølge MLOps.org er Machine Learning Operationalization en tilnærming for å etablere en helhetlig utviklingsprosess for maskinlæring. Denne prosessen skal sikre at ML-drevet programvare kan designes, bygges og administreres på en reproduserbar, testbar og videreutviklbar måte. MLOps kan i hovedsak betraktes som anvendelsen av DevOps-prinsipper på maskinlæring.
Akkurat som i DevOps, er automatisering en sentral idé i MLOps. Målet er å redusere manuelle trinn og dermed øke effektiviteten. MLOps inkluderer både kontinuerlig integrasjon (CI) og kontinuerlig leveranse (CD), akkurat som DevOps. I tillegg til disse, omfatter MLOps også kontinuerlig trening (CT). CT innebærer å jevnlig trene modellene med nye data og distribuere dem på nytt.
Derfor kan MLOps beskrives som en ingeniørkultur som fremmer en systematisk tilnærming til utvikling av maskinlæringsmodeller, samtidig som de ulike trinnene i prosessen automatiseres. Denne prosessen omfatter i hovedsak uthenting av data, analyse, forberedelse, opplæring av modeller, evaluering, distribusjon av modeller og overvåking.
Fordeler med MLOps
Generelt sett gir bruk av MLOps-prinsipper de samme fordelene som standard driftsprosedyrer. Fordelene kan oppsummeres som følger:
- En klar definert prosess gir et veikart over alle de nødvendige trinnene i modellutviklingen, noe som sikrer at ingen viktige trinn blir oversett.
- Det blir lettere å identifisere og automatisere trinn i prosessen som egner seg for automatisering, noe som reduserer gjentakende arbeid og øker utviklingshastigheten. Dette minsker også risikoen for menneskelige feil samtidig som arbeidsmengden reduseres.
- Det blir lettere å vurdere fremdriften i modellutviklingen ved å spore hvilken fase i prosessen modellen befinner seg i.
- Kommunikasjonen innad i teamet forbedres takket være et felles vokabular for de ulike utviklingstrinnene.
- Den samme prosessen kan brukes gjentatte ganger for å utvikle mange modeller, noe som gir en effektiv måte å håndtere kompleksitet på.
Kort sagt, MLOps har som formål å tilby en systematisk tilnærming til modellutvikling som kan automatiseres så mye som mulig.
Plattformer for å bygge prosesser
For å hjelpe deg med å implementere MLOps i dine prosesser, finnes det en rekke plattformer du kan bruke. Selv om de har ulike funksjoner, bidrar de i hovedsak til å:
- Lagre alle modellene dine sammen med tilhørende metadata, som konfigurasjoner, kode, nøyaktighet og eksperimenter. Dette inkluderer også versjonskontroll for de ulike modellversjonene.
- Lagre metadata for datasett, for eksempel data som er brukt til å trene modellene.
- Overvåke modeller i produksjon for å oppdage problemer som modellavvik.
- Distribuere modeller til produksjon.
- Bygge modeller i miljøer med lite eller ingen kode.
La oss se nærmere på noen av de mest populære MLOps-plattformene.
MLFlow

MLFlow er kanskje den mest anerkjente plattformen for styring av maskinlæringssykluser. Den er gratis og åpen kildekode, og den tilbyr følgende funksjoner:
- Sporing for registrering av maskinlæringseksperimenter, kode, data, konfigurasjoner og resultater.
- Prosjekter for å pakke koden din i et format som er lett å reprodusere.
- Distribusjon for å gjøre maskinlæringsmodellene dine tilgjengelige.
- Et register for å lagre alle dine modeller i en sentralisert database.
MLFlow integreres med populære maskinlæringsbiblioteker som TensorFlow og PyTorch, samt plattformer som Apache Spark, H20.ai, Google Cloud, Amazon SageMaker, Azure Machine Learning og Databricks. Den fungerer også med forskjellige skytjenesteleverandører som AWS, Google Cloud og Microsoft Azure.
Azure Machine Learning
Azure Machine Learning er en komplett plattform for maskinlæring, som håndterer de ulike aktivitetene i MLOps-prosessen. Dette inkluderer forberedelse av data, utvikling og trening av modeller, validering og distribusjon av modeller, samt administrasjon og overvåking av distribusjoner.
Azure Machine Learning lar deg utvikle modeller ved hjelp av din foretrukne IDE og rammeverk, enten det er PyTorch eller TensorFlow.
Den integreres også med ONNX Runtime og DeepSpeed for å optimalisere treningen og konklusjonen, noe som forbedrer ytelsen. Plattformen benytter seg av AI-infrastrukturen på Microsoft Azure, som kombinerer NVIDIA GPU-er og Mellanox-nettverk, for å hjelpe deg med å bygge maskinlæringsklynger. Med AML kan du opprette et sentralt register for å lagre og dele modeller og datasett.
Azure Machine Learning integreres med Git og GitHub Actions for å skape effektive arbeidsflyter. Den støtter også hybrid- eller multiskymiljøer, og kan integreres med andre Azure-tjenester som Synapse Analytics, Data Lake, Databricks og Security Center.
Google Vertex AI

Google Vertex AI er en samlet data- og AI-plattform som gir deg verktøyene du trenger for å utvikle både tilpassede og forhåndstrente modeller. Den fungerer også som en helhetlig løsning for implementering av MLOps. For å gjøre den mer brukervennlig, integreres den med BigQuery, Dataproc og Spark for sømløs datatilgang under trening.
I tillegg til et API tilbyr Google Vertex AI et verktøymiljø med lite og ingen kode, slik at det kan brukes av både utviklere og ikke-utviklere som forretningsanalytikere og dataingeniører. API-et gir utviklere mulighet til å integrere plattformen med eksisterende systemer.
Med Google Vertex AI kan du også utvikle generative AI-applikasjoner ved hjelp av Generative AI Studio. Plattformen gjør distribusjon og administrasjon av infrastruktur enklere og raskere. Google Vertex AI egner seg spesielt godt til å sikre databeredskap, funksjonsutvikling, opplæring og finjustering av hyperparametere, distribusjon av modeller, modelljustering og -forståelse, modellovervåking og modelladministrasjon.
Databricks

Databricks er et datavarehus som lar deg forberede og behandle data. Med Databricks kan du styre hele maskinlæringsløpet, fra eksperimentering til produksjon.
Databricks tilbyr i hovedsak administrert MLFlow med funksjoner som datalogging og versjonskontroll av ML-modeller, eksperimentell sporing, modellvisualisering, et modellregister og sporingsberegning. Modellregisteret lar deg lagre modeller for reproduserbarhet, og registret gir deg oversikt over versjonene og hvor de befinner seg i livssyklusen.
Distribusjon av modeller med Databricks kan gjøres med et enkelt klikk, og du får tilgang til REST API-endepunkter for å generere prediksjoner. I tillegg integreres plattformen godt med eksisterende forhåndstrente generativ og store språkmodeller, som dem fra biblioteket med klemmeransikts transformatorer.
Databricks tilbyr kollaborative notatbøker som støtter Python, R, SQL og Scala. I tillegg forenkles administrasjonen av infrastruktur ved at plattformen tilbyr forhåndskonfigurerte klynger som er optimalisert for maskinlæringsoppgaver.
AWS SageMaker
AWS SageMaker er en skytjeneste fra AWS som gir deg verktøyene du trenger for å utvikle, trene og distribuere maskinlæringsmodellene dine. Hovedformålet med SageMaker er å automatisere det kjedelige og repeterende manuelle arbeidet som er involvert i å utvikle maskinlæringsmodeller.
Som et resultat tilbyr den verktøy for å bygge en produksjonspipeline for maskinlæringsmodeller ved å bruke forskjellige AWS-tjenester, som Amazon EC2-forekomster og Amazon S3-lagring.
SageMaker fungerer med Jupyter Notebooks installert på en EC2-instans sammen med alle vanlige pakker og biblioteker som er nødvendige for å kode en maskinlæringsmodell. For data henter SageMaker data fra Amazon Simple Storage Service.
Som standard får du implementeringer av vanlige maskinlæringsalgoritmer som lineær regresjon og bildeklassifisering. SageMaker inkluderer også en modellmonitor som gir kontinuerlig og automatisk innstilling for å finne de parameterne som gir best ytelse for dine modeller. Implementeringen er også enkel, siden du lett kan distribuere modellen din til AWS som et sikkert HTTP-endepunkt som du kan overvåke med CloudWatch.
DataRobot
DataRobot er en populær MLOps-plattform som muliggjør administrasjon på tvers av ulike stadier i maskinlæringsprosessen, som dataforberedelse, ML-eksperimentering, validering og styringsmodeller.
Plattformen har verktøy for å automatisere eksperimenter med ulike datakilder, teste tusenvis av modeller og evaluere de beste for distribusjon i produksjon. Den støtter bygging av modeller for ulike typer AI-modeller for å løse problemer innen tidsserier, naturlig språkbehandling og datasyn.
Med DataRobot kan du bygge modeller ved å bruke forhåndsdefinerte modeller, slik at du ikke trenger å skrive kode. Alternativt kan du velge en kode-først-tilnærming og implementere modeller ved hjelp av tilpasset kode.
DataRobot leveres med notatbøker for å skrive og redigere kode. Alternativt kan du bruke API-et for å utvikle modeller i en IDE etter eget valg. Ved hjelp av et grafisk brukergrensesnitt (GUI) kan du spore eksperimentene til modellene dine.
Run AI

Run AI forsøker å løse problemet med underutnyttelse av AI-infrastruktur, spesielt GPU-er. Det gjøres ved å forbedre synligheten til all infrastruktur og sørge for at den blir utnyttet under trening.
For å oppnå dette, fungerer Run AI som en mellommann mellom MLOps-programvaren og firmaets maskinvare. Alle treningsjobber utføres gjennom Run AI. Plattformen planlegger i sin tur når hver enkelt jobb skal utføres.
Det er ingen begrensning på om maskinvaren må være skybasert, lokalt eller en hybridløsning, som AWS og Google Cloud. Plattformen gir et abstraksjonslag til maskinlæringsteam ved å fungere som en GPU-virtualiseringsplattform. Du kan utføre oppgaver fra Jupyter Notebook, bash-terminal eller ekstern PyCharm.
H2O.ai
H2O er en åpen kildekode, distribuert maskinlæringsplattform. Den lar team samarbeide og skape et sentralt depot for modeller, der dataforskere kan eksperimentere og sammenligne forskjellige modeller.
Som MLOps-plattform tilbyr H20 en rekke nøkkelfunksjoner. H2O forenkler også distribusjonen av modeller til en server som et REST-endepunkt. Den tilbyr forskjellige distribusjonsmetoder, for eksempel A/B-testing, Champion-Challenger-modeller og enkeltdistribusjon.
Under trening lagrer og administrerer plattformen data, artefakter, eksperimenter, modeller og distribusjoner, noe som gjør modellene reproduserbare. Den muliggjør også tillatelsesadministrasjon på gruppe- og brukernivå for å styre modeller og data. Under drift tilbyr H2O sanntidsovervåking for modelloppdrift og andre operasjonelle målinger.
Paperspace Gradient
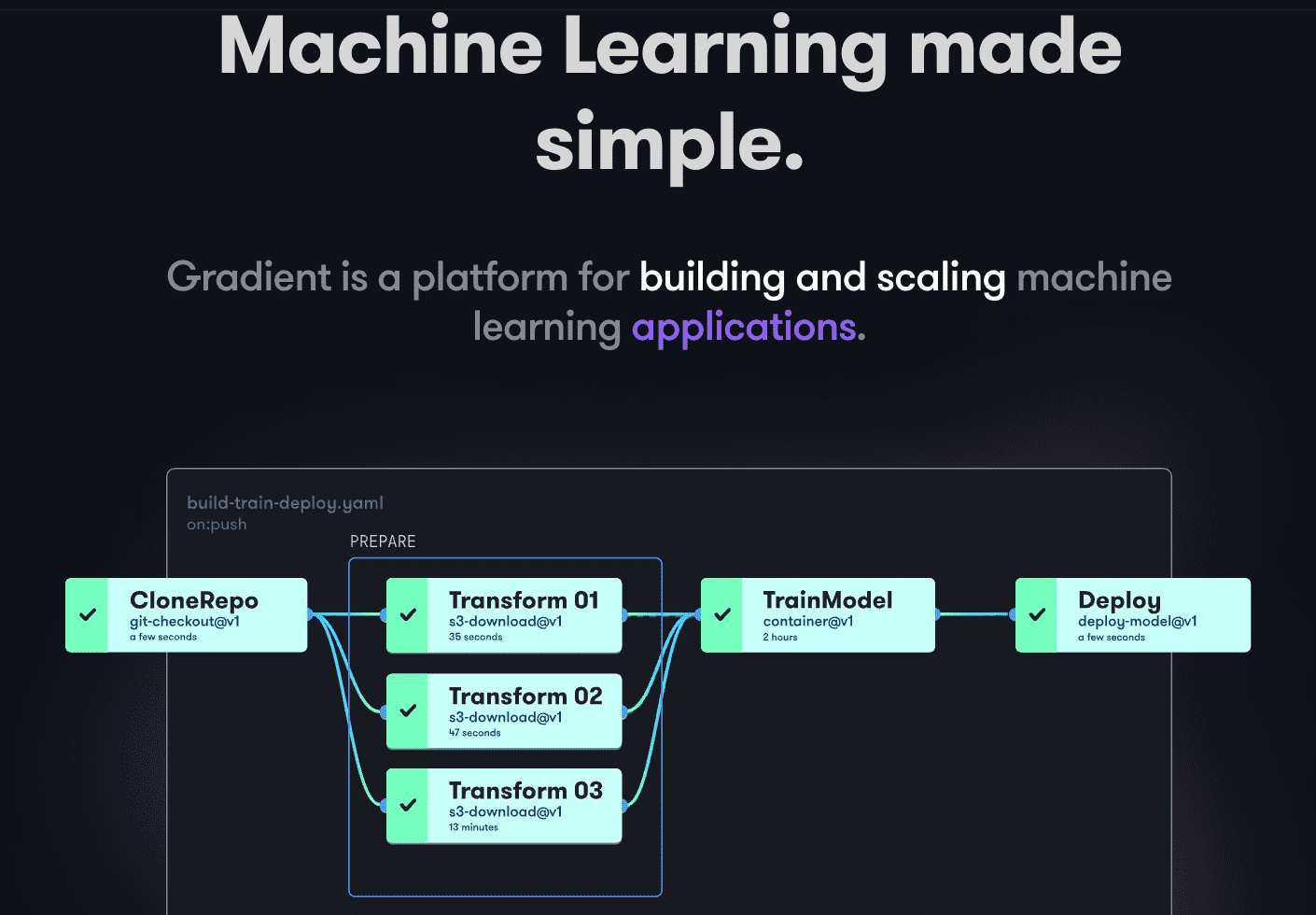
Gradient hjelper utviklere i alle faser av maskinlæringsutviklingen. Den tilbyr bærbare PC-er drevet av åpen kildekode Jupyter for modellutvikling og trening på skyen med kraftige GPU-er. Dette gjør det mulig å utforske og prototyputvikle modeller raskt.
Implementeringsprosesser kan automatiseres ved å lage arbeidsflyter. Disse arbeidsflytene defineres ved å beskrive oppgaver i YAML. Bruk av arbeidsflyter gjør det lett å replikere distribusjoner og visualisere modeller, noe som gir en skalerbar løsning.
Generelt tilbyr Gradient beholdere, maskiner, data, modeller, beregninger, logger og hemmeligheter for å hjelpe deg med å administrere ulike faser av utviklingsprosessen for maskinlæringsmodeller. Prosessene dine kjøres på Gradient-klynger, som kan befinne seg på Paperspace Cloud, AWS, GCP, Azure eller andre servere. Du kan samhandle med Gradient programmatisk via CLI eller SDK.
Siste ord
MLOps er en effektiv og allsidig tilnærming til utvikling, distribusjon og administrasjon av maskinlæringsmodeller i stor skala. MLOps er enkelt å bruke, skalerbart og sikkert, noe som gjør det til et godt valg for organisasjoner av alle størrelser.
I denne artikkelen har vi diskutert MLOps, hvorfor det er viktig å implementere dem, hva som er involvert og noen populære MLOps-plattformer.
Neste steg kan være å lese vår sammenligning av Databricks og Snowflake.