Viktigheten av en Katastrofegjenopprettingsplan
En robust katastrofegjenopprettingsplan er avgjørende for enhver organisasjon, og fungerer som et sentralt tiltak for å takle uforutsette hendelser. I IT-sektoren innebærer dette å utvikle et detaljert dokument som skisserer planer, tiltak og prosedyrer som skal følges i tilfelle en katastrofe og i etterkant.
Katastrofer kan inntreffe uventet og kan komme i mange former, noe som skaper betydelige utfordringer for både enkeltpersoner og organisasjoner. Disse utfordringene kan omfatte økonomiske vanskeligheter og en negativ innvirkning på brukeropplevelsen.
Når et angrep inntreffer, er det avgjørende å være forberedt på å minimere konsekvensene og raskt gjenopprette virksomheten. En velutviklet katastrofegjenopprettingsplan kan være avgjørende for å redusere eller til og med forhindre katastrofale konsekvenser. Dette omfatter å redusere innvirkningen på brukeropplevelsen, minimere kostnader og forkorte nedetid.
I tillegg er det viktig å ha klare planer, ressurser, strategier, utstyr og systemer på plass for å sikre rask gjenoppretting av alle operasjoner. For å oppnå dette, er det viktig å ha en inngående forståelse av konseptet katastrofegjenoppretting.
I denne artikkelen vil vi se nærmere på katastrofegjenoppretting, inkludert nøkkelterminologi, slik at du kan være godt rustet til å møte ugunstige forhold og komme sterkere ut på den andre siden. La oss begynne!
Hva defineres som en Katastrofe?
En katastrofe er en plutselig og uforutsett hendelse som kan ramme hvor som helst, også i IT-bransjen. Den kan skyldes både naturlige årsaker og menneskelig aktivitet, og er i stand til å forstyrre et selskaps drift og undergrave den eksisterende infrastrukturen.
Konsekvensene av en katastrofe er vidtrekkende, og påvirker organisasjoner, deres kunder, leverandører, ansatte og partnere. Dette legger et betydelig press på organisasjonen, med tanke på økonomiske bekymringer, omdømme i bransjen, kundetillit og sikkerhet.
Det er derfor viktig å være forberedt på å overvinne slike scenarioer. Dette innebærer en umiddelbar gjenoppretting av alle operasjoner og data. Kort sagt, en organisasjon må være klar for å raskt gjenopprette alle funksjoner for kundene sine.
Katastrofer er mangfoldige og kan inkludere cyberangrep, sabotasje, terrorhandlinger, løsepengevirus eller fysiske trusler, orkaner, jordskjelv, branner, flom, industriulykker og strømbrudd, blant annet.
Hva innebærer Katastrofegjenoppretting?

Katastrofegjenoppretting refererer til prosessen med å gjenopprette normal drift etter en katastrofe. Dette innebærer å gjenopprette tilgang til maskinvare, programvare, utstyr, tilkobling, nettverk, strøm og data. For å forberede organisasjonen din før en katastrofe, må regler og prosedyrer settes i en dokumentert prosess.
Dersom organisasjonens lokaler blir skadet, kan det også være nødvendig å utvide enkelte aktiviteter ved å håndtere kommunikasjon, transport, innkjøp og alternative arbeidsplasser.
Hvorfor er en Katastrofegjenopprettingsplan Essensiell?
En grundig plan for å gjenopprette etter en katastrofe, enten den er naturlig eller menneskeskapt, er viktig for enhver IT-bedrift. Sørg for at du har det rette teamet og de rette verktøyene på plass for å implementere planen på en jevn måte.
La oss se nærmere på hvorfor katastrofegjenoppretting er så avgjørende:
Begrensning av Skader
Katastrofer er uforutsigbare. Ingen vet når de inntreffer. Men forberedelse på forhånd kan bidra til å kontrollere skadene på infrastrukturen din.
For eksempel, i flomutsatte områder, kan viktige dokumenter og utstyr plasseres i øverste etasje for å unngå vannskader. På samme måte kan viktig data sikkerhetskopieres for å forhindre cyberangrep som kompromitterer data.
Gjenoppretting av Tjenester
Med en solid katastrofegjenopprettingsplan er det raskt og enkelt å gjenopprette alle tjenester til normal drift. Dette betyr at du innen kort tid kan gjenopprette de fleste ressurser og tjenester.
Minimering av Avbrudd
Selv om fremtiden er usikker, kan en robust gjenopprettingsplan redusere bekymringene for konsekvensene av en katastrofe. Din infrastruktur kan opprettholde driften med minimale forstyrrelser.
Opplæring og Forberedelse

I en IT-infrastruktur jobber mange ansatte. Alle må være informert om gjenopprettingsprosedyrene for å reagere hensiktsmessig i en nødsituasjon. Riktig forberedelse reduserer stressnivået for alle involverte i organisasjonen. I tillegg kan ansatte trenes i å iverksette nødvendige tiltak ved uventede hendelser.
La oss se nærmere på terminologien knyttet til katastrofegjenoppretting for å få en bedre forståelse:
RTO (Recovery Time Objective)
Recovery Time Objective (RTO) refererer til den tidsrammen en organisasjon har fastsatt, basert på dens virksomhet, for å tolerere nedetid uten å påvirke den økonomiske veksten negativt.
Ved fastsettelse av RTO må en virksomhet evaluere nedetid som kan påvirke virksomheten på ulike måter. RTO brukes til å utvikle levedyktige strategier for å opprettholde virksomheten selv etter en katastrofe. Når brukere opplever forstyrrelser i applikasjonen, vil de ønske å vite hvor lang tid det tar før appen er tilbake. Dette er RTO for hver organisasjon.
Eksempelvis, i en nettbasert transaksjonsbedrift som PayPal eller Pioneer, er det avgjørende at RTO er rask for å gjenopprette driften etter uforutsette hendelser. I slike tilfeller er en RTO på en eller to timer avgjørende for å unngå betydelige økonomiske eller datarelaterte konsekvenser.
RPO (Recovery Point Objective)
Recovery Point Objective (RPO) representerer det tapet av data en IT-infrastruktur kan håndtere, både i tid og datamengde.
Tenk deg for eksempel en bankdatabase som registrerer transaksjoner som overføringer og betalinger. Hvis en katastrofe skulle inntreffe, må databasen gjenopprettes i sanntid. Forskjellen mellom tilstanden til databasen ved katastrofens inntreffen og tilstanden etter gjenoppretting bør være minimal. For noen selskaper kan det være akseptabelt å gjenopprette informasjon fra en sikkerhetskopi innen 24 timer, mens for andre kan dette være katastrofalt. Det er derfor avgjørende å tilpasse infrastrukturen til RPO-kravene, inkludert hyppigere sikkerhetskopiering og implementering av en standby-database.
Failover
Tenk deg at du er på en lang reise og uventet punkterer et dekk. Du vil være takknemlig for å ha et reservehjul og verktøy for å utføre dekkskiftet.
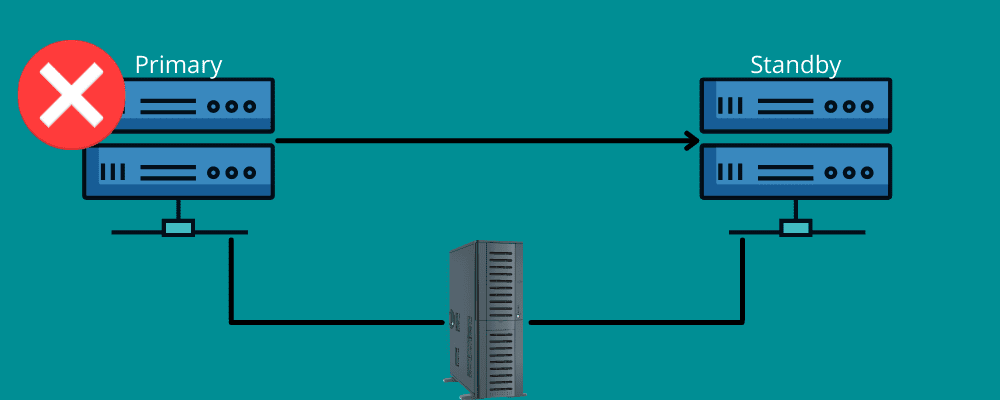
Failover fungerer på samme måte. Det betyr at du trenger en reserveforbindelse under en katastrofe. Failover sikrer tilgjengelighet av nettverk og systemer for overføring av informasjon til gjenopprettingssystemet i nødstilfeller.
Med failover kan tjenestene dine fortsette å fungere uten avbrudd, selv ved infrastruktur- eller maskinvarefeil. Dette forhindrer datatap og inntektsbortfall, samtidig som det sikrer at sluttbrukerne ikke opplever forstyrrelser. Du kan enten konfigurere failover manuelt eller automatisere den for å overføre data til en standby-server.
Failback
IT-failback er prosessen der den opprinnelige produksjonen gjenopprettes til sin opprinnelige plassering (system) etter en katastrofe. Under en katastrofe bruker bedrifter failover-operasjoner for å overføre arbeidsbelastninger til en replika av en virtuell maskin eller et sikkerhetssystem.
Når alt er gjenopprettet, er det viktig å overføre arbeidsbelastningene tilbake til sine opprinnelige VM-er eller systemer. Denne prosessen med å returnere arbeidsbelastningene til sin opprinnelige tilstand kalles failback, som også brukes til planlagt vedlikehold.
Failback skjer alltid etter en failover. Med andre ord, failover er det første trinnet, og failback er det andre trinnet i gjenopprettingsprosessen. Failback kan settes opp mellom sky-til-sky, lokalt-til-lokalt, lokalt-til-sky, eller en hvilken som helst kombinasjon av disse.
DR (Disaster Recovery)
Disaster Recovery (DR) innebærer å ha forhåndsdefinerte planer for å gjenopprette eiendeler innen en bestemt tidsramme.
DR gjør det mulig for en organisasjon å reagere raskt og gjenopprette tjenester etter uventede hendelser. Det innebærer formell dokumentasjon som gir instruksjoner for å iverksette tiltak i tilfelle uforutsette situasjoner.
BCP (Business Continuity Plan)
En Business Continuity Plan (BCP) er en etablert katastrofegjenopprettingsplan som gjør det mulig for IT-infrastruktur å utarbeide strategier for å håndtere IT-forstyrrelser på servere, mobile enheter, PC-er og nettverk.
BCP skiller seg litt fra Disaster Recovery ved at det fokuserer på å gjenopprette bedriftens programvare og produktivitet for å møte viktige forretningsbehov. En BCP innebærer å lage et gjenopprettingssystem for å håndtere potensielle trusler, som cyberangrep og naturkatastrofer. Den er utformet for å beskytte eiendeler og sikre rask gjenoppretting av alle tjenester.
BCM (Business Continuity Management)

Business Continuity Management (BCM) er en risikostyringsprosess som beskytter mot trusler mot forretningsprosesser. BCM er et neste steg i BCP og validerer gjenopprettingsplaner for å sikre at alle i virksomheten reagerer umiddelbart og gjenoppretter essensielle funksjoner.
BCM fungerer som et styringsrammeverk for å identifisere infrastrukturrisiko ved eksterne og/eller interne trusler. Det sørger også for at rammeverket fungerer effektivt gjennom regelmessige tester for å øke forutsigbarheten, redusere risiko og justere planen for fremtidige angrep.
BIA (Business Impact Analysis)
Business Impact Analysis (BIA) er prosessen med å analysere en virksomhets evne til å overleve ved å identifisere kritiske systemer, operasjoner og prosesser. Den vurderer virkningen en katastrofe vil ha på organisasjonen på grunn av driftsavbrudd.
BIA forutsier konsekvensene før et angrep inntreffer for å samle informasjon som kan hjelpe til med å utvikle solide gjenopprettingsstrategier. Den vurderer også kostnadene knyttet til avbruddene, inkludert erstatning av utstyr, tap av kontantstrøm og fortjeneste, lønnsutgifter, med mer. Når du oppretter en BIA-rapport, er det viktig å vurdere prosessene som er avgjørende for virksomheten, konsekvenser av forstyrrelser i ulike områder, akseptabel varighet og økonomiske kostnader.
Ring Tree
Et ringetre er en prosess som brukes til å lage en liste over ansatte som skal kontaktes i en nødssituasjon. Det følger en trelignende struktur, der en person kontakter en liten gruppe medlemmer med en hastemelding som så kontakter andre, og dermed sprer meldingen til alle ansatte. Målet er at alle ansatte skal bli informert under en trussel og begynne å jobbe med sine tildelte oppgaver for å gjenopprette funksjoner og prosesser i tide. Det er enkelt å lage en liste, men å implementere den i sanntid kan skape forvirring.
Regelmessige anropsøvelser er nødvendige for å holde alle nødhjelpsmedarbeidere beredt. Regelmessig testing kan også hjelpe med å identifisere endrede eller manglende tall som kan påvirke ytelsen. Et anropstre inneholder informasjon som skal brukes under en nødsituasjon for å levere instruksjoner. Det kan gjøres manuelt, men i dagens digitale verden brukes automatisering for å akselerere prosessen og varsle medlemmene.
Kommandosenter/Kontrollsenter
Et kommandosenter er en dedikert, enten fysisk eller virtuell, enhet som gir kommando og kontroll over gjenopprettingsplaner under en krise. Det kommuniserer med team for å administrere systemer og funksjoner under en katastrofe.
Tradisjonelt har infrastruktur vært avhengig av at kommandosentralen håndterer kriser uten en konkret tilnærming. I dag har organisasjoner perfeksjonert sine kontrollsentre, noe som gjør responsen til en kjernekompetanse. Så snart en katastrofe registreres, vil kommandosentralen raskt gå til gjenopprettingsfasen. I tillegg fungerer senteret som et rapporteringspunkt for tjenester, presse, forsyninger med mer, og samler folk fra ulike disipliner i krisesituasjoner.
Hendelsesrespons

Hendelsesrespons er et sett med tiltak for å håndtere et angrep. Det utføres ved hjelp av de riktige prosedyrene og personell for å sikre nettverks- og datasikkerhet effektivt og til rett tid.
Med en hendelsesresponsplan før en uventet hendelse inntreffer, kan en organisasjon beskytte dataene sine mot trusler i sanntid. Spesialister på hendelsesrespons er oppmerksomme på problemer og vet hvordan de skal reagere. De iverksetter tiltak for å unngå sikkerhetsbrudd og sikrer at de ikke hopper over et eneste trinn under katastrofegjenoppretting.
Først må kritiske data identifiseres og lagres i skyen eller et annet eksternt sted for sikker oppbevaring. Håndter de aktuelle infrastrukturbehov og utvikle cybertrusler ved å oppdatere hendelsesresponsplanene jevnlig.
Sikkerhetskopiering
Sikkerhetskopieringsløsninger hjelper IT-infrastruktur med å vedlikeholde kopier av data og lagre dem sikkert for bruk i nødstilfeller. Hvis du opplever databasekorrupsjon, utilsiktet sletting av data eller andre problemer, bør du ha en sikkerhetskopi for å gjenopprette data og fortsette tjenestene.

Dette innebærer å replikere filer og lagre dem på et trygt sted for å enkelt få tilgang til all data etter en uvanlig hendelse. Det er best å sikkerhetskopiere dataen din på flere steder for å sikre gjenoppretting selv om ett nettsted svikter.
Motstandsdyktighet
Katastrofemotstandskraft refererer til evnen til samfunn, stater, organisasjoner og enkeltpersoner til å motstå en katastrofe uten å kompromittere tjenester og systemer. En organisasjon må være forberedt på å håndtere stress forbundet med farer, og være i stand til å minimere tap gjennom bedre planlegging.
Hovedmålet er å bevare og gjenopprette viktige funksjoner og strukturer i tide. For å bli en motstandsdyktig organisasjon er det nødvendig å forberede seg på forhånd, forutse risikoer, tilpasse seg endringer, dele kunnskap og erfaringer, integrere ulike sektorer og håndtere risikonivåer.
SLA (Service Level Agreement)

En Service Level Agreement (SLA) er en katastrofeplan som skisserer for sluttbrukerne hvor lang tid det kan ta å gjenopprette tjenester i en nødsituasjon. Det garanterer også at kundenes data er trygge og ikke kompromitteres eller deles med tredjeparter. SLA er det primære kontaktpunktet for sluttbrukerhenvendelser.
Hver IT-infrastruktur gir en SLA til sine kunder, og det er derfor viktig å kommunisere med sluttbrukerne på forhånd.
SPOF (Single Point of Failure)
En Single Point of Failure (SPOF) er et element, det være seg utstyr, en person, ressurser eller applikasjoner, som mange andre systemer eller applikasjoner er koblet til. Hvis en SPOF svikter, vil alle de relaterte systemene også svikte, og påvirke hele prosessen og driften.
Det er derfor viktig å ha en strategi for å håndtere slike problemer for å holde organisasjonen operativ. Det første trinnet er å identifisere elementene som har størst potensial til å påvirke, deretter gjennomføre en konsekvensanalyse og risikovurdering for å være forberedt. Klassifiser deretter disse i henhold til gjenopprettingsprosessen, i tre kategorier: 1) enkle å gjenopprette, 2) vanskelig å gjenopprette, men mulig, og 3) umulig å gjenopprette.
Systemgjenoppretting
Ved maskinvarefeil må en gjenopprettingsprosess utføres for å bringe et spesifikt system eller en server tilbake til sin opprinnelige tilstand. Dette krever at du har gjenopprettingskrav, sikkerhetskopier, fastvarekompatibilitet og maskinvarekompatibilitet klare.
Systemgjenoppretting er en prosess som tilbakestiller maskinen til sine tidligere innstillinger eller opprinnelige tilstand. Dette vil fjerne virusinfeksjoner forårsaket av programvare eller applikasjoner som er installert på systemet ditt.
Denne prosessen inkluderer gjenopprettingsplanlegging for en IT-infrastruktur som følger spesifikke prosedyrer for å sikre datatilgjengelighet mot menneskeskapte eller naturlige forstyrrelser.
Systemgjenoppretting
Systemgjenoppretting er et gjenopprettingsverktøy som lar deg returnere spesifikke filer og informasjon til deres forrige tilstand. Dette inkluderer registernøkler, installerte programmer, drivere, systemfiler med mer, og fungerer som en livredder i mange katastrofer.
Testplan
En testplan er et dokument som inneholder informasjon om en teststrategi, estimater, ressurser, tidsfrister, mål og tidsplaner. Den fungerer som en blåkopi for å utføre tester for å sikre maskinvare- og programvaresikkerhet.
Dette omfatter ulike tester basert på prosedyrer og trinn som er planlagt for å håndtere konsekvensene av en katastrofe. Utfør regelmessige tester for å forberede deg og organisasjonen din for å sørge for at ingen trinn blir utelatt under prosessen. Dette gir en IT-infrastruktur mulighet til å identifisere mangler og forberede seg på utfordringer.
Konklusjon
Ingen kan forutse tidspunktet for en katastrofe. Det er derfor riktige sikkerhets- og sikkerhetstiltak er essensielle for enhver virksomhet.
Terminologier knyttet til katastrofegjenoppretting bidrar til å forstå hvordan en skal reagere på angrep og katastrofer. Det forbereder deg også på forhånd slik at du kan beskytte infrastrukturen din i tilfelle uventede hendelser. Ved å utvikle en effektiv katastrofegjenopprettingsstrategi, kan du spare betydelige ressurser og bevare kundenes tillit.