Utforsk Forskjellen Mellom Apache Hive og Impala
For de som er nye innen big data-analyse, kan mangfoldet av Apache-verktøy virke overveldende og forvirrende. Denne artikkelen tar sikte på å demystifisere to populære verktøy: Apache Hive og Impala, og forklare deres unike egenskaper og forskjeller.
Hva er Apache Hive?
Apache Hive er et grensesnitt for SQL-basert datatilgang som fungerer på toppen av Apache Hadoop-plattformen. Hive gir deg muligheten til å spørre, oppsummere og analysere data ved hjelp av velkjent SQL-syntaks. Den benytter et «lese ved tilgang»-skjema for data lagret i HDFS-filsystemet, slik at data kan behandles som vanlige tabeller i en relasjonsdatabase. Dine HiveQL-spørringer oversettes deretter til Java-kode for å kjøre MapReduce-jobber.
HiveQL, spørrespråket som brukes i Hive, er basert på SQL, men det støtter ikke fullstendig SQL-92-standarden. Likevel gir dette språket programmerere muligheten til å tilpasse sine spørringer når HiveQLs standardfunksjoner ikke er tilstrekkelige. HiveQL kan utvides gjennom brukerdefinerte skalarfunksjoner (UDF), aggregeringsfunksjoner (UDAF) og tabellfunksjoner (UDTF).
Hvordan fungerer Apache Hive?
Apache Hive konverterer HiveQL-kode til en eller flere oppgaver som kan utføres av MapReduce, Apache Tez eller Apache Spark. Disse tre motorene kan kjøres på Hadoop. Hive organiserer data i en struktur som er kompatibel med Hadoop Distributed File System (HDFS) for å utføre oppgaver på en klynge og generere et resultat.
Hive-tabeller er strukturert på lignende måte som relasjonsdatabaser, med data organisert fra det mest overordnede til det mest detaljerte nivået. Databaser består av partisjoner, som igjen kan deles inn i «bøtter».
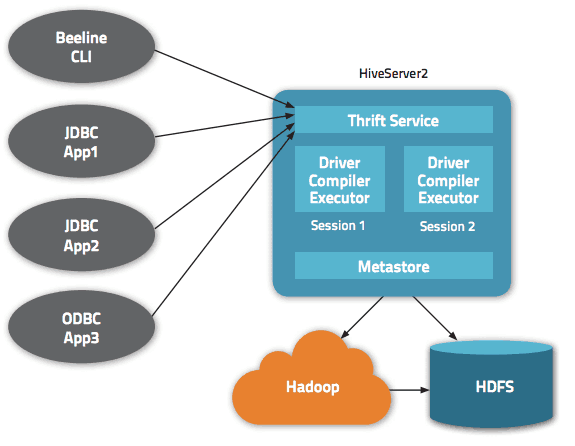
Dataene er tilgjengelige gjennom HiveQL. Hver database er nummerert, og hver tabell tilsvarer en katalog i HDFS. Apache Hive tilbyr flere grensesnitt for tilgang, inkludert webgrensesnitt, CLI og eksterne klienter.
Gjennom «Apache Hive Thrift»-serveren kan eksterne klienter sende kommandoer og forespørsler til Apache Hive ved hjelp av forskjellige programmeringsspråk. Hives sentrale katalog, kjent som «metastore,» inneholder all nødvendig informasjon. Kjernen i Hive, «driveren», kombinerer en kompilator og en optimizer for å finne den mest effektive utførelsesplanen.
Sikkerhet i Hive er basert på Hadoop, og bruker Kerberos for autentisering mellom klient og server. Tillatelsene for nyopprettede filer i Hive styres av HDFS, som tilbyr autorisasjon basert på brukere, grupper eller andre definerte roller.
Viktige funksjoner i Hive
- Støtter både Hadoop og Spark som datamotorer.
- Fungerer som et datavarehus, med HDFS som lagringsmedium.
- Benytter MapReduce og støtter ETL-prosesser.
- Arver feiltoleranse fra HDFS, lik den i Hadoop.
Fordeler med Apache Hive
Apache Hive er et utmerket verktøy for spørringer og dataanalyse. Det muliggjør dypere innsikt, gir et konkurransefortrinn, og hjelper bedrifter med å respondere raskt på markedets behov.
En av hovedfordelene med Hive er dens brukervennlighet, takket være det SQL-lignende språket. Hive fremskynder også den første datainnlastingen fordi dataene ikke trenger å leses fra disk i et internt databaseformat.
Siden dataene lagres i HDFS, kan Hive håndtere store datasett på flere hundre petabyte. Dette gjør løsningen mer skalerbar enn tradisjonelle databaser. Som en skytjeneste lar Hive brukere raskt starte virtuelle servere basert på svingninger i arbeidsmengden.
Hives sikkerhetsfunksjoner, som replikering av kritiske arbeidsbelastninger, gir ekstra beskyttelse. I tillegg er Hives arbeidsbelastningskapasitet bemerkelsesverdig, med evnen til å behandle opptil 100 000 forespørsler per time.
Hva er Apache Impala?
Apache Impala er en massivt parallell SQL-spørringsmotor designet for interaktiv utførelse av SQL-spørringer på data lagret i Apache Hadoop. Skrevet i C++ og distribuert under Apache 2.0-lisensen, er Impala ofte omtalt som en MPP (Massively Parallel Processing) motor eller en «SQL-on-Hadoop» databasestabel.

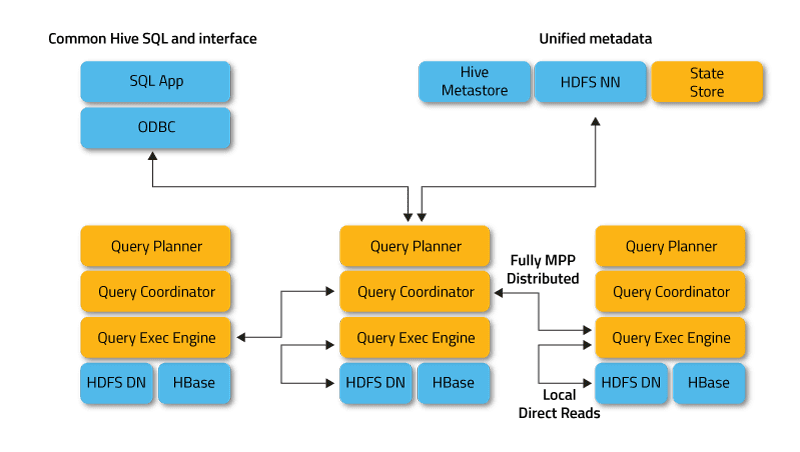
Impala opererer i en distribuert modus der prosessinstanser kjører på forskjellige noder i klyngen. Disse prosessene mottar, planlegger og koordinerer forespørsler fra klienter, og muliggjør parallell utførelse av SQL-spørringsfragmenter. Klienter interagerer med Impala gjennom HUE (Hadoop User Experience) webgrensesnitt, ODBC, JDBC, og Impala Shell kommandolinjegrensesnitt.
Impala er avhengig av Apache Hive for sin metadatatjeneste, som lar Impala identifisere tilgjengelige databaser og deres struktur. Når skjemaobjekter opprettes, endres eller slettes, eller når data lastes inn i tabeller, overføres metadataendringene automatisk til alle Impala-noder ved hjelp av en dedikert katalogtjeneste.
Nøkkeldelene i Impala inkluderer:
Impalad, en systemtjeneste som planlegger og utfører spørringer på data i HDFS, HBase og Amazon S3. Enimpalad-prosess kjører på hver klyngennode.Statestore, en navnetjeneste som overvåker plasseringen og statusen til alleimpalad-instanser i klyngen. Én instans av denne tjenesten kjører på hver node og masterserveren.Catalog, en metadatakoordineringstjeneste som sprer endringer fra Impala DDL- og DML-setninger til alle berørte Impala-noder, slik at nye tabeller eller data er umiddelbart tilgjengelig. Det anbefales å kjøre én instans avCatalogpå samme server somStatestore-demonen.
Hvordan fungerer Apache Impala?
Impala, i likhet med Apache Hive, bruker et deklarativt spørrespråk, Hive Query Language (HiveQL), som er en undergruppe av SQL92, i stedet for full SQL.
Utførelsen av en forespørsel i Impala skjer slik:
Klientapplikasjonen sender en SQL-spørring ved å koble til en vilkårlig impalad-instans via standardiserte ODBC- eller JDBC-drivere. Den tilkoblede impalad-instansen blir koordinatoren for den gjeldende forespørselen. SQL-spørringen analyseres for å finne ut hvilke oppgaver som skal utføres av impalad-instansene i klyngen, og deretter utarbeides en optimal plan for spørringsutførelse.
Impalad får direkte tilgang til HDFS og HBase ved hjelp av lokale systemtjenester for å hente data. Denne direkte interaksjonen reduserer utførelsestiden for spørringer betydelig, siden mellomresultater ikke lagres, i motsetning til Apache Hive.
Hver demon returnerer data til den koordinerende impalad-instansen, som deretter sender resultatet tilbake til klienten.
Viktige egenskaper ved Impala
- Støtter sanntids databehandling i minnet.
- SQL-vennlig grensesnitt.
- Støtter lagringssystemer som HDFS, Apache HBase og Amazon S3.
- Integreres med BI-verktøy som Pentaho og Tableau.
- Bruker HiveQL-syntaks.
Fordeler med Apache Impala
Impala unngår mulige oppstartskostnader siden alle systemdemoner startes direkte ved oppstart, noe som reduserer spørringsutførelsestiden. Hastighetsøkningen skyldes også at Impala, i motsetning til Hive, ikke lagrer mellomresultater og får direkte tilgang til HDFS eller HBase.
Impala genererer også programkode ved kjøretid, ikke under kompilering som Hive. En konsekvens av Impalas høye hastighet er redusert pålitelighet. Hvis en datanode går ned under utførelsen av en SQL-spørring, vil Impala-instansen starte på nytt, mens Hive vil opprettholde tilkoblingen til datakilden og sikre feiltoleranse.
Andre fordeler inkluderer innebygd støtte for Kerberos, en sikker autentiseringsprotokoll, prioritering og muligheten til å styre køen av forespørsler, samt støtte for populære big data-formater som LZO, Avro, RCFile, Parquet og Sequence.
Likheter mellom Hive og Impala
Både Hive og Impala distribueres gratis under Apache Software Foundation-lisensen og er SQL-verktøy for håndtering av data lagret i en Hadoop-klynge. De benytter også HDFS som filsystem.
Impala og Hive utfører ulike oppgaver, men deler et felles fokus på SQL-basert behandling av store datasett i Apache Hadoop-miljøet. Impala tilbyr et SQL-lignende grensesnitt som lar deg lese og skrive Hive-tabeller, noe som forenkler datautveksling.
Impala gjør SQL-operasjoner på Hadoop raskere og mer effektivt, noe som gjør det til et passende valg for forskningsprosjekter innen big data-analyse. Impala kan samarbeide med en eksisterende Apache Hive-infrastruktur, som allerede er i bruk for å utføre langvarige batch-spørringer.
Begge verktøy lagrer sine tabelldefinisjoner i en metastore, en tradisjonell MySQL- eller PostgreSQL-database. Dette gjør at Impala kan aksessere Hive-tabeller forutsatt at alle kolonner bruker datatyper, filformater og komprimeringskodeker som Impala støtter.
Forskjeller mellom Hive og Impala

Programmeringsspråk
Hive er skrevet i Java, mens Impala er skrevet i C++. Impala bruker imidlertid noen Java-baserte Hive UDF-er.
Bruksområder
Hive brukes ofte av dataingeniører i ETL-prosesser for langvarige batchjobber på store datasett, som for eksempel i reise- og flyplassinformasjonssystemer. Impala er derimot primært rettet mot analytikere og dataforskere for oppgaver som business intelligence.
Ytelse
Impala utfører SQL-spørringer i sanntid, mens Hive er kjent for sin lavere databehandlingshastighet. Impala kan kjøre 6-69 ganger raskere enn Hive for enkle SQL-spørringer, men Hive er bedre på komplekse spørringer.
Ventetid og gjennomstrømning
Hive har en høyere gjennomstrømning enn Impala. LLAP-funksjonen (Live Long and Process), som muliggjør hurtigbufring av spørringer i minnet, gir Hive god ytelse. LLAP består av langsiktige systemtjenester som kan kommunisere direkte med HDFS-datanoder, noe som erstatter den tett integrerte DAG-spørringsstrukturen.
Feiltoleranse
Hive er et feiltolerant system som beholder alle mellomresultater. Dette bidrar til økt skalerbarhet, men reduserer databehandlingshastigheten. Impala derimot, regnes ikke som like feiltolerant da den er mer minneavhengig.
Kodekonvertering
Hive genererer spørringsuttrykk ved kompilering, mens Impala genererer dem ved kjøretid. Hive har et «kaldstart»-problem den første gangen en applikasjon startes. Spørringer konverteres sakte på grunn av behovet for å etablere en tilkobling til datakilden. Impala har ikke dette problemet da de nødvendige systemtjenestene startes ved oppstart.
Lagringsstøtte
Impala støtter LZO, Avro og Parkett formater, mens Hive fungerer med ren tekst og ORC. Begge støtter formatene RCFile og Sequence.
| Apache Hive | Apache Impala | |
| Programmeringsspråk | Java | C++ |
| Bruksområder | Data Engineering | Analyse og utforsking |
| Ytelse | Høy for komplekse spørringer, Forholdsvis lav for enkle spørringer | Høy for enkle spørringer, Lav for komplekse spørringer |
| Ventetid | Høyere grunnet caching | Lavere |
| Feiltoleranse | Høy grunnet MapReduce | Lavere grunnet MPP |
| Kodekonvertering | Treg oppstart grunnet kaldstart | Rask oppstart |
| Lagringsstøtte | Ren tekst, ORC, RCFile, Sequence | LZO, Avro, Parkett, RCFile, Sequence |
Oppsummering
Hive og Impala konkurrerer ikke direkte, men utfyller hverandre. Selv om det er betydelige forskjeller mellom de to, har de også mye til felles. Valget av verktøy avhenger av dataene og de spesifikke kravene til prosjektet.
Du kan også utforske sammenligninger mellom Hadoop og Spark for å få et bredere perspektiv.