Er du usikker på hvordan du kan oppnå pålitelige og konsekvente data for analyse? Da bør du implementere disse strategiene for datavask nå!
Viktigheten av dine forretningsavgjørelser er knyttet til innsikten fra dataanalyser. Denne innsikten, som er hentet fra ulike datasett, er i sin tur avhengig av kvaliteten på de underliggende kildene. Utfordringer som dårlig kvalitet, unøyaktigheter, og inkonsekvente data er en stor belastning for både datavitenskap og analyseindustrien.
Derfor har eksperter utviklet en løsning: Datavask. Dette bidrar til å unngå data-drevne beslutninger som kan skade virksomheten din i stedet for å forbedre den.
Les videre for å lære mer om de mest effektive strategiene for datavask som erfarne dataforskere og analytikere bruker. I tillegg utforsker vi verktøy som kan tilby rene data for umiddelbare datavitenskapsprosjekter.
Hva innebærer datavask?
Datakvalitet har fem sentrale dimensjoner. Prosessen med å identifisere og rette opp feil i dataene dine, basert på disse dimensjonene, er det vi kaller datavask.
Disse fem dimensjonene for datakvalitet er som følger:
#1. Fullstendighet
Denne parameteren sikrer at datasettet har alle nødvendige komponenter, som overskrifter, rader, kolonner og tabeller, som er nødvendige for et datavitenskapelig prosjekt.
#2. Nøyaktighet
Nøyaktighet betyr at dataene samsvarer med den faktiske verdien av informasjonen. Data er nøyaktig når de samles inn i tråd med alle statistiske standarder.
#3. Gyldighet
Denne parameteren bekrefter at dataene følger de definerte forretningsreglene.
#4. Ensartethet
Ensartethet sjekker om dataene inneholder konsistent innhold. For eksempel, hvis du samler inn data om energiforbruk i USA, bør alle enhetene være i det britiske målesystemet. Hvis du bruker det metriske systemet for enkelte deler av samme undersøkelse, er ikke dataene ensartede.
#5. Konsistens
Konsistens sikrer at dataverdier er sammenfallende mellom ulike tabeller, datamodeller og datasett. Dette er særlig viktig når data flyttes mellom systemer.
Kort sagt, bruk disse kvalitetskontrollprosessene på rådata før de mates inn i et business intelligence-verktøy.
Hvorfor er datavask viktig?
Akkurat som du ikke kan drive en digital virksomhet med dårlig internettforbindelse, kan du heller ikke ta gode beslutninger basert på data av dårlig kvalitet. Hvis du bruker feilaktige data til å ta forretningsavgjørelser, kan du oppleve tap av inntekter eller dårlig avkastning.
En rapport fra Gartner viser at gjennomsnittlig tap som følge av dårlig datakvalitet er $12,9 millioner. Dette skyldes beslutninger tatt på grunnlag av feilaktige og dårlige data.
Den samme rapporten antyder at bruken av dårlige data koster USA et svimlende årlig tap på $3 billioner.
Kort sagt: Dårlig data inn, dårlig innsikt ut.
Derfor er det avgjørende å vaske rådata for å unngå økonomiske tap og ta effektive forretningsbeslutninger basert på dataanalyser.
Fordelene med datavask
#1. Unngå økonomiske tap
Ved å rense dataene dine, kan du beskytte virksomheten din mot økonomiske tap som følge av manglende overholdelse eller tap av kunder.
#2. Ta gode avgjørelser

Data av høy kvalitet gir verdifull innsikt. Slik innsikt hjelper deg å ta bedre forretningsbeslutninger knyttet til produktmarkedsføring, salg, lagerstyring, prissetting og lignende.
#3. Få et konkurransefortrinn
Ved å prioritere datavask over konkurrentene dine, vil du kunne dra nytte av å være en tidlig aktør i bransjen din.
#4. Effektiviser prosjekter
En effektiv datavaskprosess øker tilliten i teamet. Når teamet er trygge på dataene, kan de fokusere mer på selve dataanalysen.
#5. Spar ressurser
Ved å rense og trimme data reduseres størrelsen på databasen. Dermed frigjøres lagringsplass ved å fjerne unødvendige data.
Strategier for å vaske data
Standardiser visuelle data
Et datasett inneholder mange typer tegn, som tekst, tall og symboler. Det er viktig å bruke en enhetlig formatering for all tekst. For eksempel, ordet «Bill» med stor «B» refererer til et navn, mens «bill» med liten «b» er en faktura. Symboler bør også ha riktig koding, som Unicode eller ASCII.
Fjern dupliserte data
Dupliserte data kan forvirre analysesystemer, noe som kan forvrenge mønstre. Derfor er det viktig å fjerne duplikater fra datasettet.
Duplikater skyldes ofte manuelle dataregistreringsprosesser. Ved å automatisere denne prosessen kan du redusere antall duplikater.
Fiks uønskede avvik
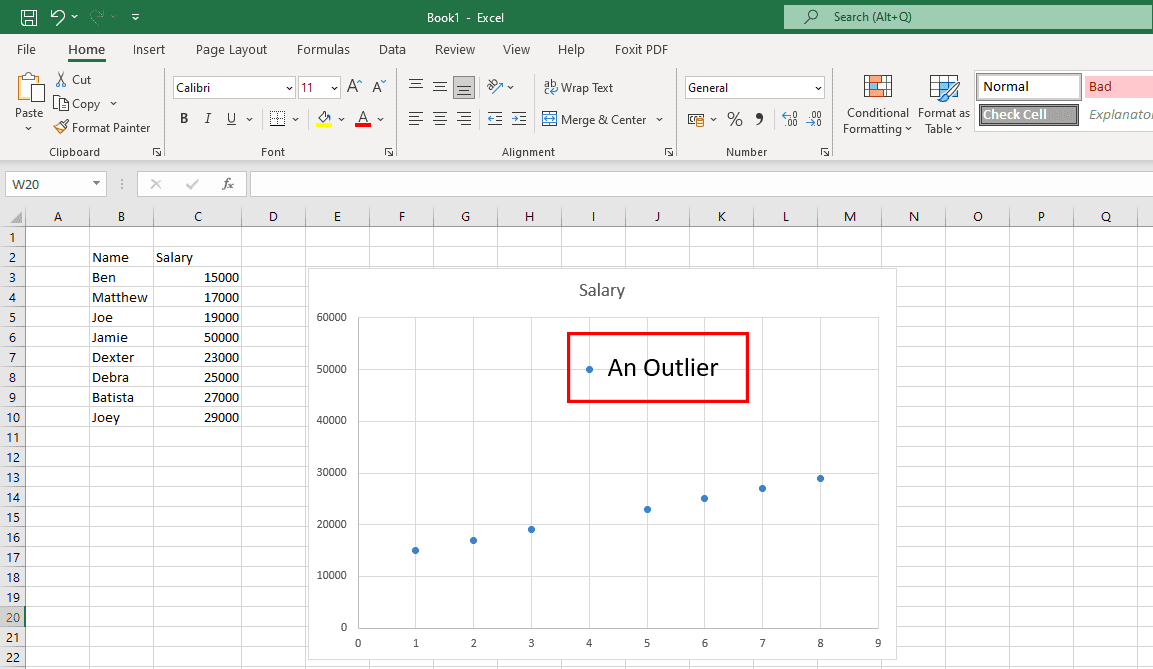
Avvik er datapunkter som faller utenfor det vanlige mønsteret. Ekte avvik er nyttige for å oppdage feil i undersøkelser, mens de som skyldes menneskelige feil bør fjernes.
Bruk grafer for å identifisere avvik, og undersøk kilden. Fjern avvik som skyldes menneskelig feil.
Fokus på strukturelle data
Det er viktig å finne og rette opp feil i strukturen til datasett.
For eksempel kan et datasett inneholde en kolonne med USD og flere med andre valutaer. Hvis dataene er for et amerikansk publikum, konverter alle andre valutaer til USD, og erstatt de opprinnelige verdiene.
Skann dataene dine
En stor database kan inneholde mange tabeller, men du trenger ikke nødvendigvis alle til prosjektet ditt.
Etter at du har hentet databasen, bør du bruke et skript for å finne de relevante tabellene. Slett de irrelevante for å redusere størrelsen på datasettet og lette mønstergjenkjenning.
Vask data i skyen
Hvis databasen din bruker «schema-on-write», konverter til «schema-on-read». Dette muliggjør datavask direkte i skylagringen, og gjør dataene klare for analyse.
Oversett fremmedspråk
Når du gjennomfører en global undersøkelse, vil du sannsynligvis motta data på forskjellige språk. Bruk et dataassistert oversettelsesverktøy (CAT) for å oversette tekst til ønsket språk.
Trinn-for-trinn datavask
#1. Identifiser viktige datafelt
Et datavarehus kan inneholde store mengder data. Du må analysere prosjektets mål for å trekke ut de relevante dataene.
Hvis prosjektet ditt for eksempel studerer e-handelstrender i USA, vil data fra fysiske butikker i samme arbeidsbok ikke være nyttige.
#2. Organiser data

Etter at du har identifisert de viktige datafeltene, kan du sortere dem på en organisert måte.
#3. Fjern duplikater
Rådata inneholder nesten alltid dupliserte oppføringer. Finn og slett disse.
#4. Fjern tomme verdier og mellomrom
Noen overskrifter og datafelt kan være tomme. Enten fjern disse eller erstatt de tomme verdiene med riktig data.
#5. Utfør finformatering
Datasett kan inneholde unødvendige mellomrom, symboler og tegn. Formater disse med formler for å gi et enhetlig utseende.
#6. Standardiser prosessen
Lag en standard operasjonsprosedyre (SOP) for datavask, som teamet kan følge. Den bør inkludere:
- Hyppighet for datainnsamling
- Veiledning for lagring og vedlikehold av rådata
- Hyppighet for datavask
- Veiledning for lagring og vedlikehold av vasket data
Her er noen populære verktøy for datavask som kan være til hjelp i datavitenskapelige prosjekter:
WinPure

WinPure er en pålitelig løsning for nøyaktig og rask datavask. Dette verktøyet tilbyr datavask på bedriftsnivå med høy hastighet og presisjon.
Det er designet for både individuelle brukere og bedrifter, og er enkelt å bruke. Programvaren bruker avansert dataprofilering for å analysere datatyper, formater, integritet og verdier. Den intelligente motoren finner de perfekte treffene med minimalt med falske treff.
I tillegg gir WinPure oversikt over data, gruppetreff og utelukkelser.
Det fungerer også som et sammenslåingsverktøy som kan slå sammen dupliserte poster til én hovedpost. Du kan definere regler for valg av hovedpost, og fjerne alle duplikater.
OpenRefine
OpenRefine er et gratis verktøy med åpen kildekode, som transformerer rotete data til et rent format. Det bruker fasett for å vaske store datasett, og opererer på filtrerte visninger.
Verktøyet slår sammen lignende verdier for å fjerne inkonsekvenser. Det tilbyr avstemmingstjenester for å matche datasett med eksterne databaser. Du kan også gå tilbake til en eldre versjon av datasettet ved behov.
Brukere kan gjenta operasjoner fra historikken. OpenRefine behandler dataene på maskinen din, så det er ingen overføring til skyen.
Trifacta Designer Cloud

Trifacta Designer Cloud forenkler datavask. Det tilbyr en ny tilnærming for å forberede data for analyse, slik at organisasjoner kan få mest mulig verdi ut av dem.
Det brukervennlige grensesnittet gjør det mulig for ikke-tekniske brukere å rense data for avansert analyse. Bedrifter kan bruke maskinlæringsdrevne forslag fra verktøyet.
Du bruker mindre tid på denne prosessen, og håndterer færre feil. Det krever også færre ressurser.
Cloudingo
Hvis du er Salesforce-bruker, kan du bruke Cloudingo for å vaske kundedata. Programmet hjelper deg med å administrere data ved hjelp av funksjoner som deduplisering, import og migrering.
Her kan du kontrollere sammenslåing av poster med tilpassbare filtre og regler, og standardisere data. Du kan slette ubrukelige data og oppdatere manglende datapunkter.
Cloudingo kan også deduplisere data automatisk. Med dette verktøyet kan du også sammenligne Salesforce-data med regneark.
ZoomInfo

ZoomInfo leverer datavaskløsninger som bidrar til produktivitet og effektivitet. Det eliminerer kostbare duplikater.
Det forenkler datakvalitetsstyring med automatisert deduplisering, matching og normalisering.
Brukere har fleksibilitet over kriterier for samsvar og sammenslåing, og det hjelper med å bygge et kostnadseffektivt system for datalagring.
Konkluderende ord
Datakvaliteten er avgjørende for datavitenskapelige prosjekter. Det er grunnlaget for store prosjekter som maskinlæring og kunstig intelligens. Hvis dataene er feil, vil resultatet også være dårlig.
Derfor bør du implementere en god strategi for datavask. Kvaliteten på dataene vil da forbedres.
Hvis du er opptatt, er det lurt å overlate datavask til eksperter, eller å bruke et av verktøyene nevnt ovenfor.
Du kan også vurdere et tjenestesystem for å implementere datavaskstrategier.