Introduksjon til Support Vector Machines
Support Vector Machine (SVM) er en populær algoritme innen maskinlæring. Den er kjent for sin effektivitet og evne til å trenes med begrensede datasett. Men hva nøyaktig er en SVM?
Hva er en Support Vector Machine (SVM)?
En supportvektormaskin er en maskinlæringsalgoritme som benytter veiledet læring for å utvikle en modell for binær klassifisering. Dette kan virke komplisert, men denne artikkelen vil gi en detaljert forklaring av SVM og hvordan det anvendes i naturlig språkbehandling. Vi starter med å se på hvordan en støttevektormaskin fungerer.
Hvordan fungerer SVM?
La oss se for oss et enkelt klassifiseringsproblem der dataene våre har to dimensjoner, x og y, og en resultatvariabel – en klassifisering som enten er rød eller blå. Vi kan visualisere dette med et hypotetisk datasett:
Oppgaven er å konstruere en beslutningsgrense for dette datasettet. Beslutningsgrensen er en linje som deler datapunktene inn i de to klassene. Her er det samme datasettet med en beslutningsgrense:
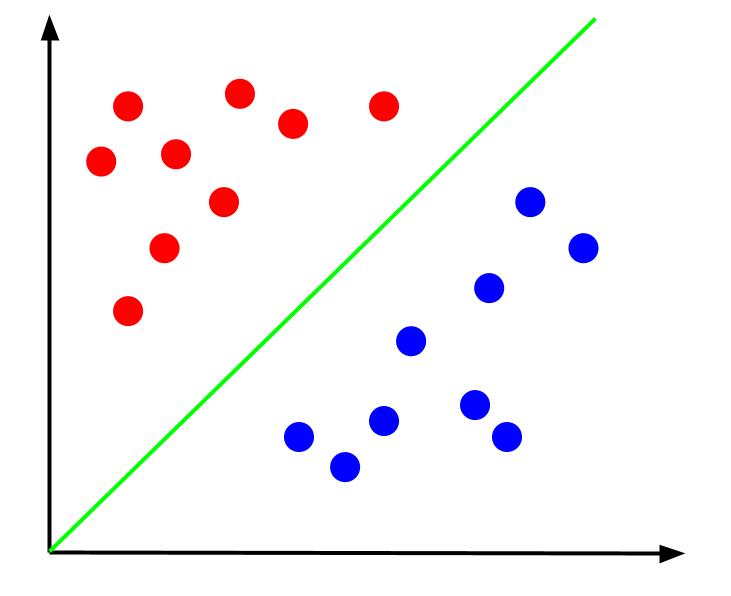
Med en slik beslutningsgrense kan vi forutsi hvilken klasse et nytt datapunkt tilhører, basert på hvor det ligger i forhold til grensen. Support Vector Machine-algoritmen forsøker å skape den mest optimale beslutningsgrensen for klassifisering av punkter.
Men hva betyr egentlig den «mest optimale» beslutningsgrensen?
Den mest optimale beslutningsgrensen er den som maksimerer avstanden til støttevektorene. Støttevektorer er de datapunktene i hver klasse som er nærmest den motsatte klassen. Disse punktene har høyest risiko for å bli feilklassifisert på grunn av deres nærhet til den andre klassen.
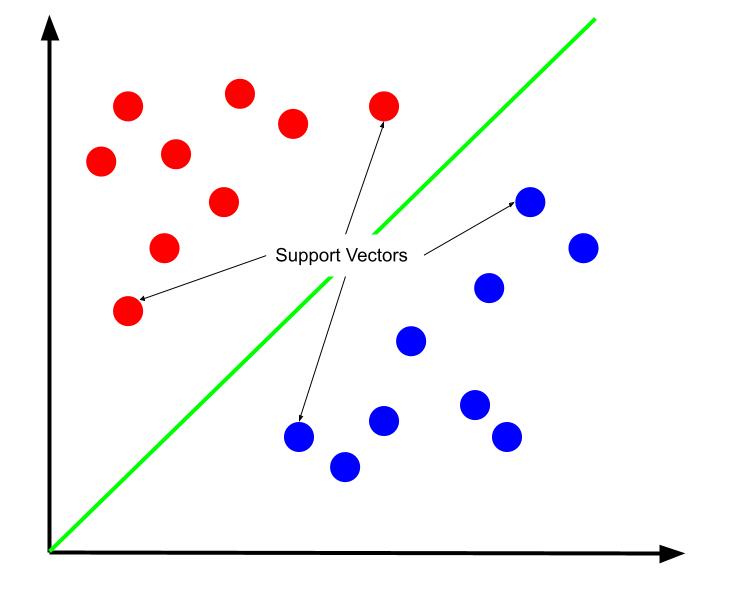
Trening av en supportvektormaskin innebærer derfor å finne en linje som gir størst mulig margin mellom støttevektorene.
Det er viktig å merke seg at beslutningsgrensen er plassert i forhold til støttevektorene. Dette betyr at det bare er støttevektorene som bestemmer posisjonen til beslutningsgrensen, og de andre datapunktene er irrelevante. Dermed krever treningen bare støttevektorene.
I dette eksemplet dannes beslutningsgrensen som en rett linje. Dette er fordi datasettet kun har to dimensjoner. Hvis datasettet har tre dimensjoner, vil beslutningsgrensen være et plan istedenfor en linje. Og med fire eller flere dimensjoner kalles beslutningsgrensen et hyperplan.
Data som ikke er lineært separerbare
Eksemplet ovenfor handlet om enkle data som kunne skilles med en lineær beslutningsgrense. La oss se på et annet tilfelle, der dataene er plottet som følger:
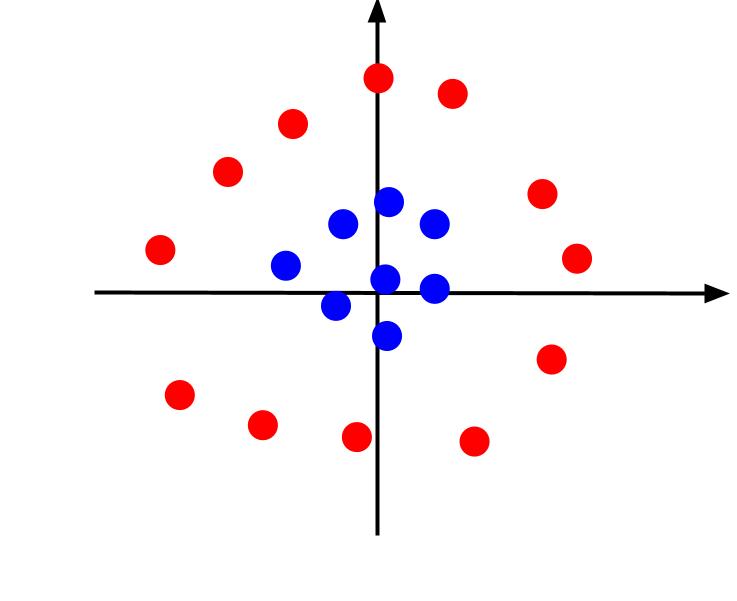
Her er det umulig å skille dataene med en rett linje. Men vi kan konstruere en ny funksjon, z. Denne funksjonen kan defineres som: z = x^2 + y^2. Vi kan legge til z som en tredje akse til planet for å gjøre det tredimensjonalt.
Når vi ser på det 3D-plottet fra en vinkel slik at x-aksen er horisontal og z-aksen er vertikal, får vi et bilde som ligner dette:
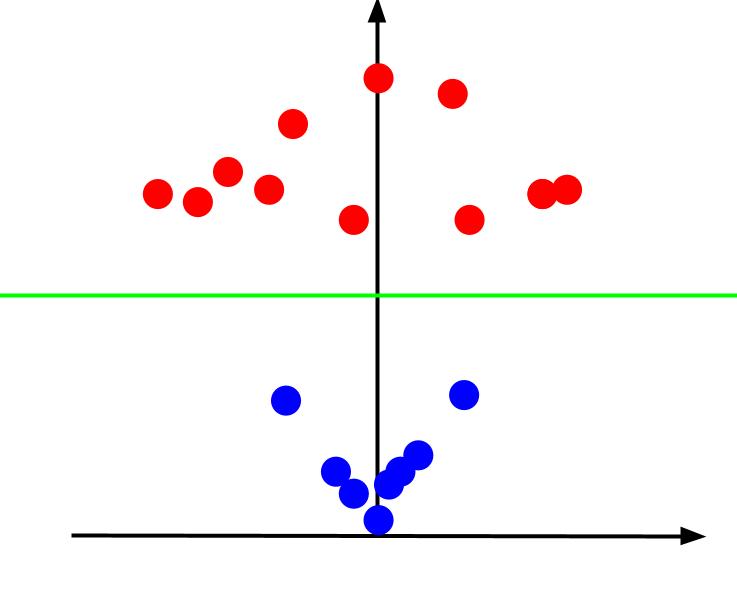
Z-verdien representerer avstanden til et punkt fra origo i forhold til de andre punktene i det originale XY-planet. De blå punktene nærmere origo vil ha lave z-verdier, mens de røde punktene som er lenger unna vil ha høyere z-verdier. Ved å plotte disse mot z-verdiene, får vi en klar klassifisering som kan avgrenses av en lineær beslutningsgrense, som vist.
Dette er en kraftfull idé som brukes i Support Vector Machines. Mer generelt handler det om å transformere data til et høyere antall dimensjoner slik at punktene kan skilles med en lineær grense. Funksjonene som utfører denne transformasjonen er kjernefunksjoner. Det finnes mange kjernefunksjoner, som sigmoid, lineær, ikke-lineær og RBF.
For å effektivisere denne prosessen bruker SVM et kjernetriks.
SVM i maskinlæring
Support Vector Machine er en av flere algoritmer som brukes i maskinlæring, sammen med populære algoritmer som beslutningstrær og nevrale nettverk. SVM er foretrukket fordi den fungerer godt med mindre datamengder sammenlignet med andre algoritmer. Den brukes ofte til:
- Tekstklassifisering: Kategorisering av tekstdata, for eksempel kommentarer og anmeldelser.
- Ansiktsgjenkjenning: Analyse av bilder for å identifisere ansikter, som for eksempel i filtre for utvidet virkelighet.
- Bildeklassifisering: SVM-er kan klassifisere bilder effektivt sammenlignet med andre metoder.
Utfordringen med tekstklassifisering
Internett er fylt med store mengder tekstdata. Mye av dette er imidlertid ustrukturert og ikke merket. For å kunne bruke og forstå disse tekstdataene bedre, er det behov for klassifisering. Eksempler på tekstklassifisering inkluderer:
- Kategorisering av tweets i emner.
- Klassifisering av e-poster som sosiale, reklame eller spam.
- Klassifisering av kommentarer som hatefulle eller usømmelige.
Hvordan SVM fungerer med naturlig språkklassifisering
Support Vector Machine brukes for å klassifisere tekst i kategorier som tilhører eller ikke tilhører et bestemt tema. Dette oppnås ved først å transformere tekstdataene til et datasett med flere dimensjoner.
En metode for dette er å lage en dimensjon for hvert unike ord i datasettet. For hvert tekst-datapunkt, registrerer vi frekvensen hvert ord forekommer. Hvis det finnes N antall unike ord i datasettet, vil vi ha N antall dimensjoner.
I tillegg må vi gi klassifiseringer for disse datapunktene. Disse klassifiseringene er ofte merket med tekst, men de fleste SVM-implementeringer forventer numeriske etiketter. Derfor må vi konvertere disse etikettene til tall før treningen. Når datasettet er klargjort med disse dimensjonene som koordinater, kan en SVM-modell brukes for å klassifisere teksten.
Opprette en SVM i Python
For å lage en supportvektormaskin i Python kan vi bruke SVC-klassen fra sklearn.svm-biblioteket. Her er et eksempel på hvordan du kan bruke SVC-klassen for å bygge en SVM-modell:
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
# Last inn datasettet
X = ...
y = ...
# Del opp dataene i trenings- og testsett
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Opprett en SVM-modell
model = SVC(kernel="linear")
# Tren modellen med treningsdataene
model.fit(X_train, y_train)
# Evaluer modellen på testdataene
accuracy = model.score(X_test, y_test)
print("Nøyaktighet: ", accuracy)
I dette eksemplet importerer vi først SVC-klassen fra sklearn.svm-biblioteket. Deretter laster vi inn datasettet og deler det opp i trenings- og testsett.
Vi oppretter en SVM-modell ved å instansiere et SVC-objekt og angi kjerneparameteren til «lineær». Modellen trenes med treningsdataene ved hjelp av fit()-metoden og evalueres deretter med testdataene ved hjelp av score()-metoden. Score()-metoden returnerer modellens nøyaktighet, som deretter skrives ut.
Du kan også spesifisere andre parametere for SVC-objektet, som C-parameteren som kontrollerer styrken på regulariseringen, og gamma-parameteren, som kontrollerer kjernekoeffisienten for visse kjerner.
Fordeler med SVM
Her er noen fordeler med å bruke supportvektormaskiner:
- Effektiv: SVM-er er generelt effektive å trene, spesielt når datamengden er stor.
- Robust mot støy: SVM-er er relativt robuste mot støy i treningsdataene, da de prøver å finne den maksimale marginen, som er mindre følsom for støy enn andre klassifikatorer.
- Minneeffektiv: SVM-er krever at bare en delmengde av treningsdataene er i minnet samtidig, noe som gjør dem mer minneeffektive enn andre algoritmer.
- Effektiv i høydimensjonale rom: SVM-er kan fungere godt selv når antallet funksjoner er større enn antallet datapunkter.
- Allsidig: SVM-er kan brukes til klassifiserings- og regresjonsoppgaver, og de kan håndtere ulike typer data, inkludert lineære og ikke-lineære data.
La oss nå se på noen gode ressurser for å lære mer om Support Vector Machines.
Læringsressurser
En innføring i støttevektormaskiner
Denne boken gir en omfattende og stegvis innføring i kjernebaserte læringsmetoder og et solid fundament for teorien bak Support Vector Machines.
Anvendelser av støttevektormaskiner
Mens den første boken fokuserte på teorien, fokuserer denne boken på de praktiske anvendelsene av Support Vector Machines. Den ser på hvordan SVM-er brukes i bildebehandling, mønstergjenkjenning og datasyn.
Støttevektormaskiner (informasjonsvitenskap og statistikk)
Denne boken gir en oversikt over prinsippene bak effektiviteten til SVM-er i ulike applikasjoner. Forfatterne fremhever flere faktorer som bidrar til suksessen, inkludert deres evne til å prestere godt med et begrenset antall justerbare parametere og deres motstandsdyktighet mot ulike typer feil.
Læring med kjerner
«Learning with Kernels» er en bok som introduserer leseren til supportvektormaskiner og relaterte kjerneteknikker. Boken har som mål å gi en grundig, men tilgjengelig introduksjon til SVM-er og kjernemetoder.
Støtt vektormaskiner med Sci-kit Learn
Dette onlinekurset fra Coursera viser hvordan man implementerer en SVM-modell ved hjelp av det populære maskinlæringsbiblioteket, Sci-Kit Learn. Du vil også lære teorien bak SVM-er og identifisere deres styrker og begrensninger. Kurset er på nybegynnernivå og tar omtrent 2,5 timer.

Støtt vektormaskiner i Python: Konsepter og kode
Dette betalte nettkurset fra Udemy gir opptil 6 timer med videoinstruksjon og en sertifisering. Det dekker SVM-er og hvordan de kan implementeres solid i Python. Det tar også for seg bruksområder for Support Vector Machines i næringslivet.

Maskinlæring og AI: Støtt vektormaskiner i Python
I dette kurset lærer du å bruke støttevektormaskiner for ulike praktiske applikasjoner, inkludert bildegjenkjenning, spamdeteksjon, medisinsk diagnose og regresjonsanalyse. Du vil bruke Python for å implementere ML-modeller for disse applikasjonene.

Avsluttende ord
I denne artikkelen har vi sett på teorien bak Support Vector Machines, deres anvendelse innen maskinlæring og naturlig språkbehandling. Vi har også sett på hvordan implementeringen med scikit-learn ser ut, og snakket om de praktiske bruksområdene og fordelene ved å bruke SVM-er.
Selv om denne artikkelen bare var en introduksjon, gir de anbefalte ressursene deg muligheten til å lære mer detaljert om Support Vector Machines. Med sin allsidighet og effektivitet er SVM-er en verdifull kunnskap for alle som jobber som dataforskere og ML-ingeniører.
Som neste steg kan du utforske de mest populære maskinlæringsmodellene.