Betydningen av Data og Datautvinning
Data er en kritisk komponent for bedrifter og organisasjoner, men deres verdi realiseres fullt ut når de er strukturert på en hensiktsmessig måte og administreres effektivt.
En undersøkelse viser at hele 95 % av dagens virksomheter opplever utfordringer med å styre og strukturere data som ikke er organisert.
Det er her datagruvedrift spiller en avgjørende rolle. Datagruvedrift er en prosess som omfatter identifisering, analyse og uthenting av relevante mønstre og verdifull innsikt fra store mengder ustrukturerte data.
Selskaper benytter seg av programvare for å oppdage trender i store datamengder. Dette gjør det mulig å lære mer om kundebasen og målgruppen, samt å utvikle effektive forretnings- og markedsføringsstrategier. Målet er å øke salget og redusere utgiftene.
I tillegg til de nevnte fordelene, er oppdagelse av svindel og avvik noen av de viktigste bruksområdene for datautvinning.
Denne artikkelen vil se nærmere på deteksjon av avvik og undersøke hvordan dette kan bidra til å forebygge dataangrep og uautorisert tilgang til nettverk, og dermed sikre datasikkerheten.
Hva er Anomali Deteksjon og Ulike Typer?
Mens datagruvedrift handler om å finne sammenhenger, relasjoner og trender, er deteksjon av anomalier en spesifikk metode for å finne uvanlige datapunkter eller avvik fra det normale i et nettverk.
Anomalier, i sammenheng med datagruvedrift, refererer til dataelementer som skiller seg betydelig fra de andre elementene i datasettet og som avviker fra det typiske atferdsmønsteret.
Anomalier kan kategoriseres i ulike typer og klassifikasjoner, inkludert:
- Endringer i hendelser: Dette omfatter plutselige eller systematiske endringer som avviker fra tidligere normal adferd.
- Utestående verdier (Outliers): Dette er små, uregelmessige mønstre som dukker opp på en ikke-systematisk måte i datasettet. Disse kan videre deles inn i globale, kontekstuelle og kollektive utestående verdier.
- Drift: Dette beskriver en gradvis, ikke-retningsbestemt og langsiktig endring i datasettet.
Anomali deteksjon er en svært verdifull databehandlingsteknikk som brukes til å identifisere svindelaktige transaksjoner, håndtere komplekse case-studier med ubalanse, og oppdage sykdommer. Dette gjør det mulig å utvikle robuste modeller for dataanalyse.
For eksempel kan et selskap analysere sine pengestrømmer for å identifisere uvanlige eller gjentatte transaksjoner til en ukjent bankkonto, for å avdekke potensielle svindel og foreta ytterligere undersøkelser.
Fordeler med Anomali Deteksjon
Å oppdage uregelmessigheter i brukeradferd bidrar til å styrke sikkerhetssystemer, og gjør dem mer presise og nøyaktige.
Det gir en strukturert analyse av den varierte informasjonen som sikkerhetssystemer genererer, slik at trusler og potensielle risikoer i nettverket kan identifiseres.
Her er noen av fordelene med anomali deteksjon for bedrifter:
- Sanntidsdeteksjon av cybersikkerhetstrusler og dataangrep, ettersom algoritmer for kunstig intelligens (AI) kontinuerlig analyserer dataene for å identifisere uvanlig atferd.
- Raskere og enklere sporing av unormal aktivitet og mønstre sammenlignet med manuell deteksjon av uregelmessigheter, noe som reduserer arbeidsmengden og tiden som kreves for å håndtere trusler.
- Minimering av operasjonell risiko ved å identifisere driftsproblemer, som for eksempel plutselig redusert ytelse, før de oppstår.
- Forebygging av omfattende forretningsmessige tap ved å oppdage uregelmessigheter tidlig, da det uten et system for avviksdeteksjon kan ta uker eller måneder for virksomheter å identifisere potensielle trusler.
Anomali deteksjon er en viktig ressurs for bedrifter som lagrer store mengder kunde- og forretningsdata, da det bidrar til å identifisere vekstmuligheter og eliminere sikkerhetsrisikoer og operasjonelle flaskehalser.
Teknikker for Anomali Deteksjon
Anomali deteksjon benytter en rekke metoder og maskinlæringsalgoritmer for å overvåke data og oppdage trusler.
Her er de sentrale teknikkene for anomali deteksjon:
#1. Maskinlæringsteknikker

Maskinlæringsteknikker bruker maskinlæringsalgoritmer til å analysere data og identifisere anomalier. De ulike typene maskinlæringsalgoritmer for anomali deteksjon inkluderer:
- Klyngealgoritmer
- Klassifiseringsalgoritmer
- Dyp læringsalgoritmer
Vanlige maskinlæringsteknikker som brukes for å identifisere avvik og trusler er supportvektormaskiner (SVM), k-means-klynger og autoenkodere.
#2. Statistiske Teknikker
Statistiske teknikker bruker statistiske modeller for å finne uvanlige mønstre i data (for eksempel uvanlige svingninger i ytelsen til en maskin). Formålet er å identifisere verdier som faller utenfor det forventede verdiområdet.
De vanligste statistiske metodene for anomali deteksjon inkluderer hypotesetesting, IQR (interkvartil rekkevidde), Z-score, modifisert Z-score, tetthetsestimering, boksplott, ekstremverdianalyse og histogram.
#3. Datagruvedriftsteknikker

Datagruvedriftsteknikker bruker dataklassifisering og klyngeanalyse for å identifisere anomalier i et datasett. Noen vanlige teknikker inkluderer spektral klynging, tetthetsbasert klynging og hovedkomponentanalyse.
Klyngealgoritmer brukes til å gruppere ulike datapunkter i klynger basert på deres likhet, for å identifisere datapunkter og anomalier som faller utenfor disse klyngene.
Klassifiseringsalgoritmer fordeler datapunkter til spesifikke, forhåndsdefinerte klasser, og identifiserer datapunkter som ikke passer inn i disse klassene.
#4. Regelbaserte Teknikker
Som navnet tilsier, bruker regelbaserte metoder et sett med forhåndsdefinerte regler for å oppdage anomalier i dataene.
Disse teknikkene er relativt enkle å sette opp, men kan være mindre fleksible og kanskje ikke like effektive til å tilpasse seg endret dataadferd og mønstre.
For eksempel kan man enkelt programmere et regelbasert system til å merke transaksjoner som overskrider et bestemt beløp som mistenkelige.
#5. Domenespesifikke Teknikker
Domenespesifikke teknikker kan brukes til å oppdage uregelmessigheter i definerte datasystemer. De kan være svært effektive i spesifikke domener, men mindre effektive i andre domener.
Man kan for eksempel utvikle teknikker spesielt rettet mot å oppdage uregelmessigheter i finansielle transaksjoner. Disse teknikkene vil sannsynligvis ikke fungere for å identifisere anomalier i en maskin.
Behovet for Maskinlæring i Anomali Deteksjon
Maskinlæring er svært viktig og nyttig innenfor anomali deteksjon.
De fleste selskaper og organisasjoner som benytter seg av anomali deteksjon, håndterer i dag store mengder data – fra tekst, kundeinformasjon og transaksjoner til mediefiler som bilder og videoinnhold.
Det er nesten umulig å manuelt gå gjennom alle banktransaksjoner og data som genereres hvert sekund for å skape meningsfull innsikt. I tillegg har mange bedrifter utfordringer med å strukturere ustrukturerte data og organisere dem på en måte som er nyttig for dataanalyse.
Det er her verktøy og teknikker som maskinlæring (ML) spiller en sentral rolle i innsamling, rensing, strukturering, organisering, analyse og lagring av enorme mengder ustrukturerte data.
Maskinlæringsteknikker og algoritmer behandler store datasett og gir fleksibilitet til å bruke og kombinere ulike teknikker og algoritmer for å oppnå de beste resultatene.
Maskinlæring bidrar også til å effektivisere anomali deteksjonsprosesser for praktiske formål, og sparer dermed ressurser.
Her er noen ytterligere fordeler og viktigheten av maskinlæring i anomali deteksjon:
- Det forenkler oppdagelse av avvik i skala ved å automatisere identifisering av mønstre og anomalier uten behov for eksplisitt programmering.
- Maskinlæringsalgoritmer er svært tilpasningsdyktige til endringer i datasettmønstre, noe som gjør dem effektive og robuste over tid.
- De håndterer store og komplekse datasett på en effektiv måte, noe som gjør anomali deteksjon effektiv selv med komplekse data.
- Tidlig identifisering og oppdagelse av uregelmessigheter ved å finne dem idet de oppstår, noe som sparer tid og ressurser.
- Maskinlæringsbaserte anomali deteksjonssystemer gir høyere nøyaktighet sammenlignet med tradisjonelle metoder.
Anomali deteksjon sammen med maskinlæring bidrar derfor til raskere og tidligere oppdagelse av uregelmessigheter, og forebygger sikkerhetstrusler og ondsinnet aktivitet.
Maskinlæringsalgoritmer for Anomali Deteksjon
Man kan oppdage anomalier og uteliggere i data ved hjelp av ulike datagruvedriftalgoritmer for klassifisering, klynging eller assosiasjonsregellæring.
Disse algoritmene er vanligvis delt inn i to kategorier – algoritmer for overvåket og uovervåket læring.
Veiledet Læring
Overvåket læring er en vanlig type læringsalgoritme, som inkluderer algoritmer som supportvektormaskiner, logistisk og lineær regresjon, og multiklasse-klassifisering. Denne type algoritme er trent på merkede data, noe som betyr at treningsdatasettet inneholder både normale inndata og de tilsvarende korrekte utdataene, eller unormale eksempler for å bygge en prediktiv modell.
Målet er å lage utgangsprediksjoner for usynlige og nye data, basert på mønstrene i treningsdatasettet. Anvendelser for overvåkede læringsalgoritmer inkluderer bilde- og talegjenkjenning, prediktiv modellering og naturlig språkbehandling (NLP).
Uovervåket Læring
Uovervåket læring er ikke trent på noen merkede data. I stedet identifiserer den komplekse prosesser og underliggende datastrukturer, uten veiledning fra treningsalgoritmen, og i stedet for å lage spesifikke spådommer.
Anvendelser for uovervåkede læringsalgoritmer inkluderer anomali deteksjon, tetthetsestimering og datakomprimering.
La oss nå se på noen populære maskinlæringsbaserte algoritmer for anomali deteksjon.
Local Outlier Factor (LOF)
Local Outlier Factor, eller LOF, er en anomali deteksjonsalgoritme som vurderer lokal datatetthet for å avgjøre om et datapunkt er en anomali.
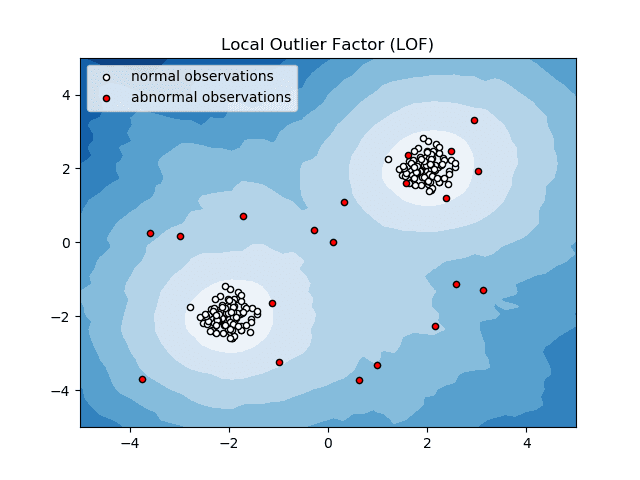
Den sammenligner den lokale tettheten til et objekt med den lokale tettheten til naboene for å analysere områder med tilsvarende tetthet og objekter med relativt lavere tetthet enn naboene – noe som indikerer anomalier eller uteliggere.
Enkelt sagt er tettheten rundt en uteligger eller et unormalt objekt forskjellig fra tettheten rundt naboene. Derfor kalles denne algoritmen også en tetthetsbasert algoritme for deteksjon av uteliggere.
K-Nærmeste Nabo (K-NN)
K-NN er en enkel klassifiserings- og overvåket algoritme for anomali deteksjon, som er lett å implementere. Den lagrer alle tilgjengelige eksempler og data, og klassifiserer de nye eksemplene basert på likheten i avstandsberegningene.
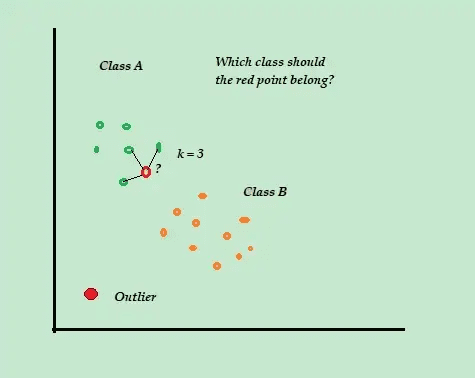
Denne klassifiseringsalgoritmen kalles også en lat elev, da den bare lagrer de merkede treningsdataene, uten å gjøre noe annet under treningsprosessen.
Når et nytt, umerket treningsdatapunkt ankommer, ser algoritmen på de K-nærmeste treningsdatapunktene og bruker dem til å klassifisere og bestemme klassen til det nye umerkede datapunktet.
K-NN-algoritmen bruker følgende deteksjonsmetoder for å finne de nærmeste datapunktene:
- Euklidisk avstand for å måle avstanden for kontinuerlige data.
- Hammingavstand for å måle likheten mellom to tekststrenger for diskrete data.
Anta for eksempel at treningsdatasettene dine består av to klasseetiketter, A og B. Hvis et nytt datapunkt kommer, vil algoritmen beregne avstanden mellom det nye datapunktet og alle datapunktene i datasettet, og velge de punktene som er nærmest det nye datapunktet.
Anta at K = 3, og 2 av 3 datapunkter er merket som A, vil det nye datapunktet også bli merket som klasse A.
K-NN-algoritmen fungerer best i dynamiske miljøer med hyppige behov for dataoppdatering.
Det er en populær algoritme for anomali deteksjon og tekstutvinning, som brukes i finans og næringsliv for å oppdage svindelaktige transaksjoner og øke suksessraten for svindeldeteksjon.
Support Vector Machine (SVM)
Support Vector Machine er en overvåket maskinlæringsbasert anomali deteksjonsalgoritme, som ofte brukes i regresjons- og klassifiseringsproblemer.
Den benytter et flerdimensjonalt hyperplan for å skille data i to grupper (nye og normale). Hyperplanet fungerer som en beslutningsgrense som skiller de normale dataobservasjonene fra de nye dataene.
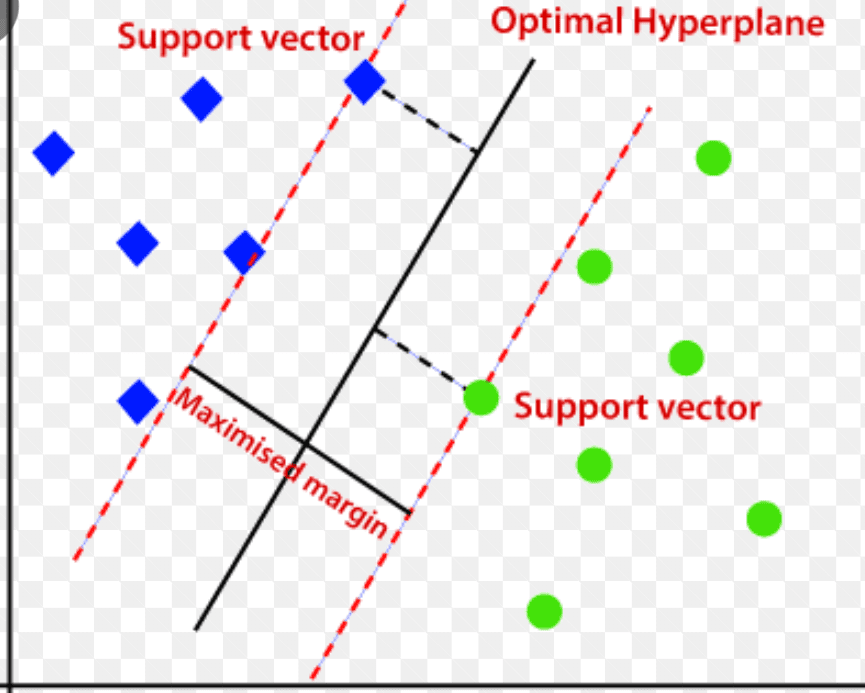
Avstanden mellom disse to datapunktene kalles marginer.
Målet er å øke avstanden mellom de to punktene, og SVM bestemmer det beste eller optimale hyperplanet med maksimal margin for å sikre at avstanden mellom de to klassene er så stor som mulig.
I forbindelse med anomali deteksjon, beregner SVM marginen til den nye datapunktobservasjonen fra hyperplanet for å klassifisere den.
Hvis marginen overskrider den angitte terskelen, klassifiseres den nye observasjonen som en anomali. Hvis marginen er mindre enn terskelen, klassifiseres observasjonen som normal.
SVM-algoritmer er svært effektive når det gjelder å håndtere høydimensjonale og komplekse datasett.
Isolasjonsskog
Isolasjonsskog er en uovervåket maskinlæringsalgoritme for anomali deteksjon basert på konseptet fra Random Forest Classifier.
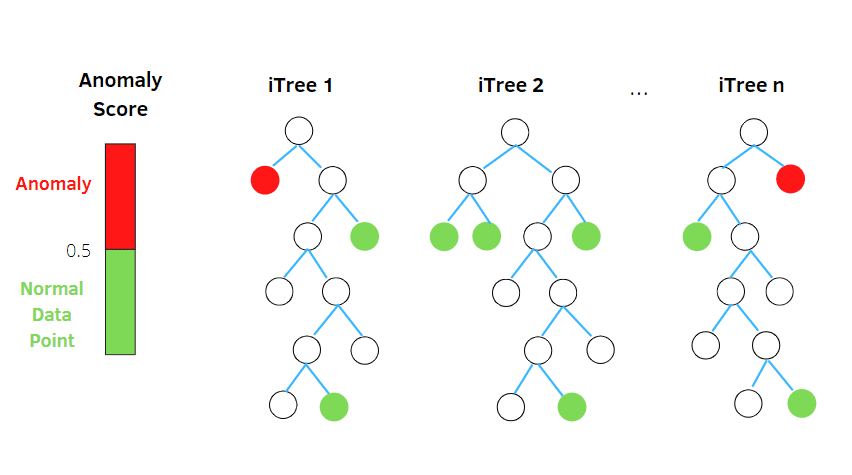
Algoritmen behandler tilfeldig utvalgte data i datasettet i en trestruktur, basert på tilfeldige attributter. Den konstruerer flere beslutningstrær for å isolere observasjoner, og anser en bestemt observasjon som en anomali hvis den er isolert i færre trær, basert på forurensningsraten.
På denne måten deler isolasjonsskogalgoritmen datapunktene opp i forskjellige beslutningstrær, og sikrer at hver observasjon er isolert fra en annen.
Anomalier befinner seg vanligvis langt fra datapunktklyngen, noe som gjør det lettere å identifisere uregelmessigheter sammenlignet med de vanlige datapunktene.
Isolasjonsskogalgoritmer kan enkelt håndtere kategoriske og numeriske data. De er raske å trene, og svært effektive til å oppdage uregelmessigheter i store og høydimensjonale datasett.
Interkvartil Rekkevidde
Interkvartilområdet eller IQR, brukes til å måle statistisk variabilitet eller spredning, for å finne uvanlige punkter i datasett ved å dele dem inn i kvartiler.
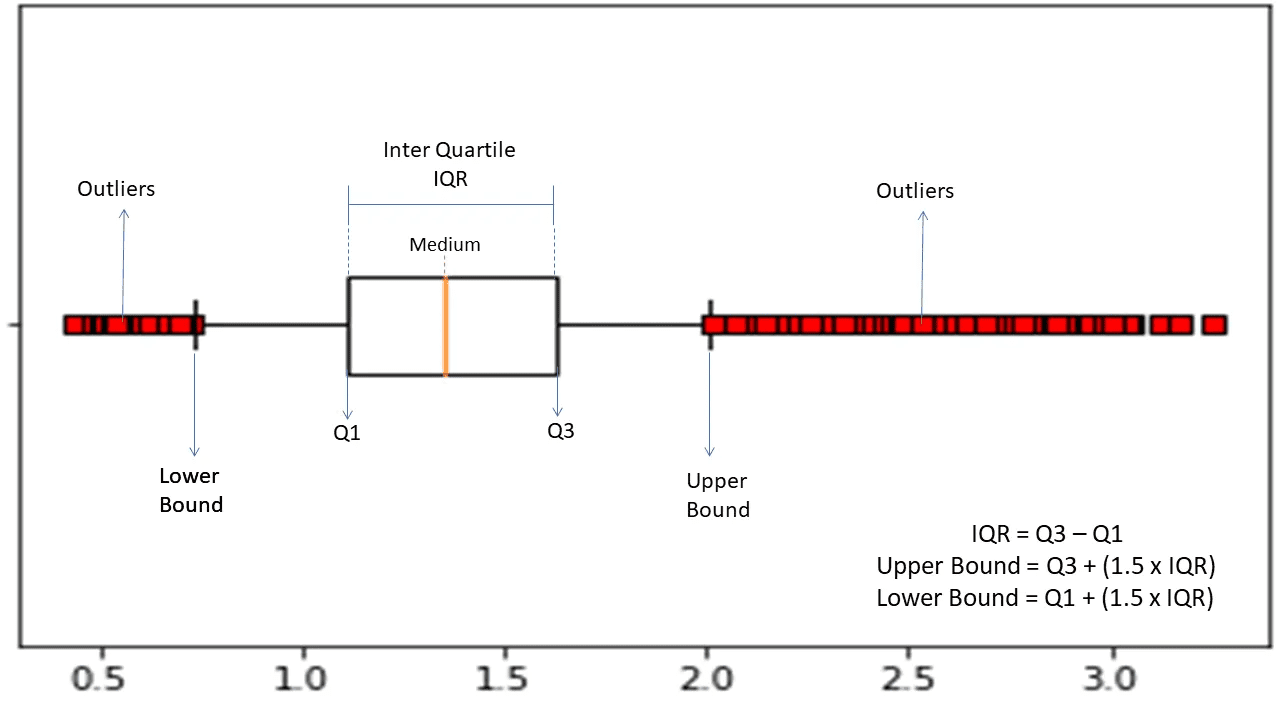
Algoritmen sorterer dataene i stigende rekkefølge og deler settet inn i fire like deler. Verdiene som skiller disse delene er Q1, Q2 og Q3 – henholdsvis den første, andre og tredje kvartilen.
Her er persentilfordelingen for disse kvartilene:
- Q1 representerer den 25. persentilen av dataene.
- Q2 representerer den 50. persentilen av dataene.
- Q3 representerer den 75. persentilen av dataene.
IQR er forskjellen mellom det tredje (75.) og det første (25.) persentildatasettet, som representerer 50 % av dataene.
For å bruke IQR til anomali deteksjon, må man beregne IQR for datasettet og definere de nedre og øvre grensene for dataene for å identifisere anomalier.
- Nedre grense: Q1 – 1,5 * IQR
- Øvre grense: Q3 + 1,5 * IQR
Observasjoner som faller utenfor disse grensene anses vanligvis som anomalier.
IQR-algoritmen er effektiv for datasett med ujevnt fordelte data, og når fordelingen ikke er godt forstått.
Avsluttende Ord
Cybersikkerhetsrisiko og dataangrep ser ikke ut til å avta i årene som kommer – og det forventes at denne risikofylte bransjen vil vokse ytterligere i 2023. Angrep mot IoT-enheter forventes alene å dobles innen 2025.
Cyberkriminalitet vil etter all sannsynlighet koste globale selskaper og organisasjoner rundt 10,3 billioner dollar årlig innen 2025.
Dette er grunnen til at behovet for anomali deteksjonsteknikker blir stadig mer utbredt for å oppdage svindel og forhindre uautorisert tilgang til nettverk.
Denne artikkelen gir en introduksjon til hva uregelmessigheter i datagruvedrift innebærer, ulike typer uregelmessigheter, og metoder for å forebygge uautorisert tilgang til nettverk ved hjelp av maskinlæringsbaserte anomali deteksjonsteknikker.
Nå kan du se nærmere på alt som har med forvirringsmatrisen i maskinlæring å gjøre.