Data Vault: Fremtiden for Datavarehus
Ettersom virksomheter genererer stadig større mengder data, opplever de at tradisjonelle metoder for datavarehus blir mer komplekse og kostbare å vedlikeholde. Data Vault, en relativt ny tilnærming til datavarehus, presenterer en løsning på denne utfordringen ved å tilby en skalerbar, fleksibel og kostnadseffektiv metode for å håndtere store datamengder.
I denne artikkelen skal vi utforske hvorfor Data Vault er ansett som fremtiden for datavarehus, og hvorfor stadig flere selskaper adopterer denne tilnærmingen. I tillegg vil vi presentere ressurser for de som ønsker å fordype seg i dette spennende feltet!
Hva er Data Vault?
Data Vault er en modelleringsteknikk for datavarehus, spesielt egnet for smidig utvikling. Den gir høy fleksibilitet for utvidelser, full historisering av data, og muliggjør sterk parallellisering av datainnlastingsprosesser. Dan Linstedt utviklet Data Vault-modellering på 1990-tallet.
Etter den første offentliggjøringen i 2000, fikk metoden betydelig oppmerksomhet i 2002 gjennom en serie artikler. I 2007 anerkjente Bill Inmon, en pioner innen datavarehus, Data Vault som det «optimale valget» for sin Data Vault 2.0-arkitektur.
Enhver som arbeider med smidige datavarehus vil raskt oppdage Data Vault. Det som kjennetegner denne teknologien er dens fokus på virksomheters behov, da den tillater fleksible og enkle tilpasninger av et datavarehus.
Data Vault 2.0 tar hensyn til hele utviklingsprosessen og arkitekturen, og består av komponentene metode (implementering), arkitektur og modell. Fordelen er at denne tilnærmingen vurderer alle aspekter av forretningsintelligens med det underliggende datavarehuset under utvikling.
Data Vault-modellen tilbyr en moderne løsning for å overkomme begrensningene ved tradisjonelle datamodelleringsmetoder. Med sin skalerbarhet, fleksibilitet og smidighet, gir den et solid grunnlag for å bygge en dataplattform som kan håndtere kompleksiteten i moderne datamiljøer.
Data Vaults hub-and-spoke-arkitektur og separasjon av enheter og attributter muliggjør dataintegrasjon og harmonisering på tvers av flere systemer og domener, noe som støtter inkrementell og smidig utvikling.
En sentral rolle for Data Vault i å etablere en dataplattform er å skape en enkelt pålitelig kilde for alle data. Dens enhetlige datavisning og evne til å fange opp og spore historiske dataendringer gjennom satellittabeller, muliggjør samsvar, revisjon, overholdelse av regulatoriske krav og omfattende analyse og rapportering.
Data Vaults mulighet for dataintegrering i nær sanntid, via delta-lasting, forenkler håndtering av store datavolum i raskt skiftende miljøer som Big Data og IoT-applikasjoner.
Data Vault vs. Tradisjonelle Datavarehusmodeller
Third Normal Form (3NF) er en anerkjent tradisjonell datavarehusmodell, ofte brukt i store implementeringer. Dette samsvarer med ideene til Bill Inmon, en av pionerene innen datavarehus.
Inmon-arkitekturen, basert på relasjonsdatabasemodellen, eliminerer dataredundans ved å dele datakilder inn i mindre tabeller som lagres i datamarts og kobles sammen med primær- og fremmednøkler. Dette sikrer at data er konsistente og nøyaktige ved å håndheve referanseintegritet.
Formålet med normalformen var å etablere en omfattende, virksomhetsomfattende datamodell for kjernedatavarehuset. Imidlertid har den utfordringer med skalerbarhet og fleksibilitet på grunn av tette koblinger mellom datamarts, vanskeligheter med å laste data i nær sanntid, tunge spørringer og en «top-down» tilnærming til design og implementering.
Kimball-modellen, som brukes for OLAP (online analytical processing) og datamarts, er en annen kjent datavarehusmodell. Her inneholder faktatabeller aggregerte data, mens dimensjonstabeller beskriver lagrede data i et stjerne- eller snøfnuggskjemadesign. I denne arkitekturen er data organisert i fakta- og dimensjonstabeller som er denormalisert for å forenkle spørringer og analyser.
Kimball er basert på en dimensjonsmodell som er optimalisert for spørringer og rapportering, noe som gjør den velegnet for business intelligence-applikasjoner. Den har imidlertid problemer med isolering av emneorientert informasjon, dataredundans, inkompatible spørringsstrukturer, skalerbarhetsutfordringer, inkonsekvent granularitet i faktatabeller, synkroniseringsproblemer og behovet for en «top-down» design med «bottom-up» implementering.
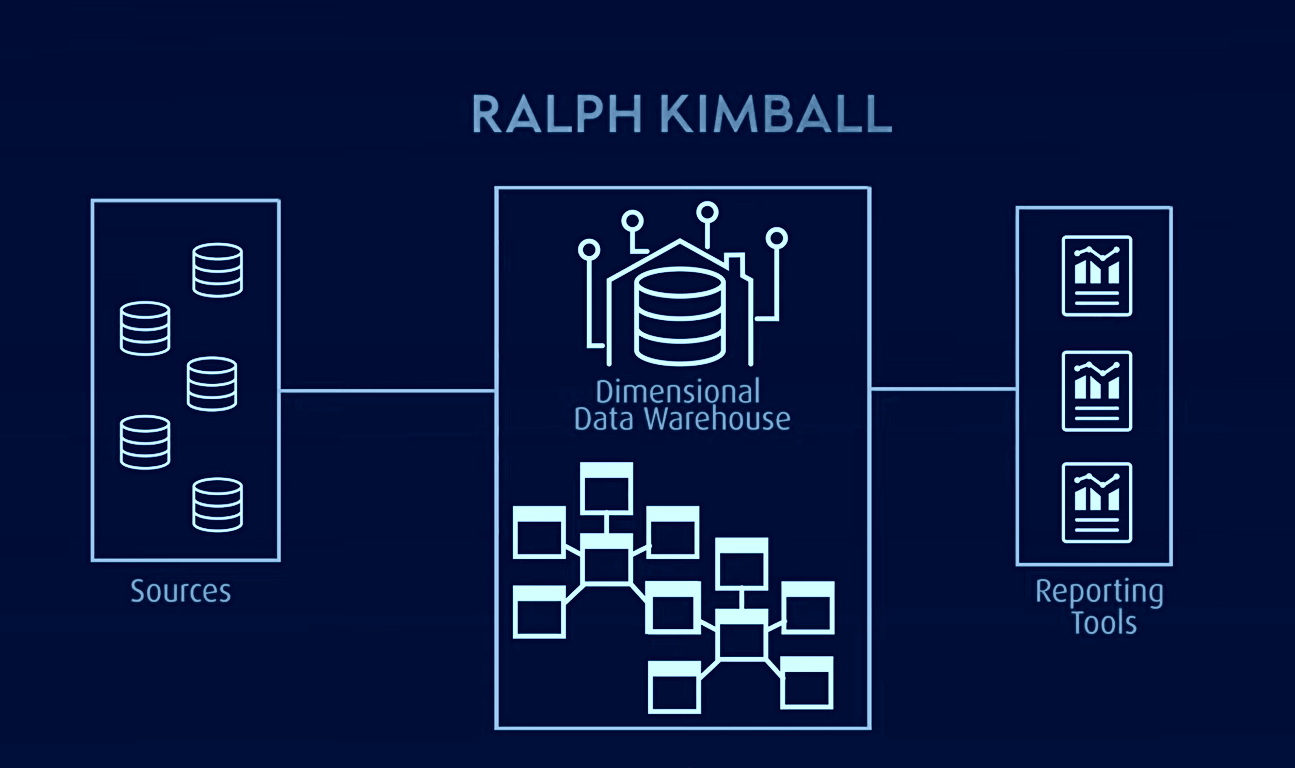
Data Vault-arkitektur er derimot en hybrid tilnærming som kombinerer elementer fra både 3NF- og Kimball-arkitekturer. Det er en modell basert på relasjonsprinsipper, datanormalisering og redundansmatematikk som representerer relasjoner mellom enheter annerledes og strukturerer tabellfelt og tidsstempler på en unik måte.
I denne arkitekturen lagres alle data i et rådatahvelv eller datasjø, mens de ofte brukte dataene lagres i et normalisert format i et forretningshvelv. Dette inneholder historiske og kontekstspesifikke data som kan brukes til rapportering.
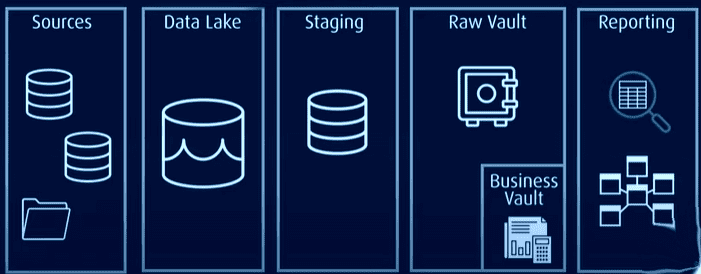
Data Vault løser utfordringene ved tradisjonelle modeller ved å være mer effektive, skalerbare og fleksible. Den gir mulighet for innlasting i nær sanntid, bedre dataintegritet og enkel utvidelse uten å påvirke eksisterende strukturer. Modellen kan også utvides uten at man trenger å migrere eksisterende tabeller.
| Modelleringstilnærming | Datastruktur | Designtilnærming |
| 3NF-modellering | Tabeller i 3NF | Bottom-up |
| Kimbal Modeling | Stjerneskjema eller Snøfnuggskjema | Top-down |
| Data Vault | Hub-and-Spoke | Bottom-up |
Arkitektur for Data Vault
Data Vault benytter en hub-and-spoke-arkitektur, bestående av tre hovedlag:
Staging Layer: Samler inn rådata fra kildesystemer som CRM eller ERP.
Datavarehuslag: Når modellert som en Data Vault-modell, inneholder dette laget:
- Rådatahvelv: Lagrer de rå dataene.
- Business Data Vault: Inkluderer harmoniserte og transformerte data basert på forretningsregler (valgfritt).
- Metrics Vault: Lagrer kjøretidsinformasjon (valgfritt).
- Operational Vault: Lagrer data som strømmer direkte fra driftssystemer inn i datavarehuset (valgfritt.)
Data Mart Layer: Dette laget modellerer data som stjerneskjema og/eller andre modelleringsteknikker. Det gir informasjon for analyse og rapportering.
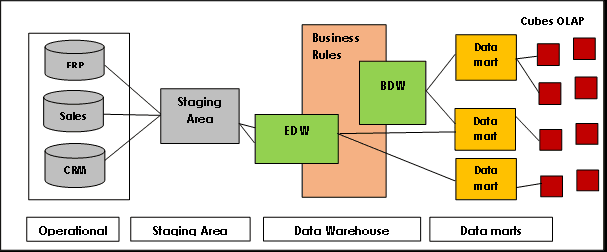
Bildekilde: Lamia Yessad
Data Vault krever ikke en ny arkitektur. Nye funksjoner kan bygges parallelt direkte ved å bruke konseptene og metodene til Data Vault, og eksisterende komponenter går ikke tapt. Rammeverk kan gjøre arbeidet betydelig enklere: de skaper et lag mellom datavarehuset og utvikleren, og reduserer dermed kompleksiteten i implementeringen.
Komponenter i Data Vault
Under modellering deler Data Vault all informasjon som tilhører objektet i tre kategorier, i motsetning til klassisk tredje normalformsmodellering. Denne informasjonen lagres deretter strengt atskilt fra hverandre. Funksjonsområdene kan kartlegges i Data Vault i såkalte huber, lenker og satellitter:
#1. Huber
Huber er kjernen i et forretningskonsept, som kunde, selger, salg eller produkt. Hubtabellen dannes rundt forretningsnøkkelen (butikknavn eller plassering) når en ny forekomst av denne nøkkelen først introduseres i datavarehuset.
Huben inneholder ingen beskrivende informasjon og ingen FK-er. Den består kun av forretningsnøkkelen, med en lagergenerert sekvens av ID- eller hashnøkler, lastedato/tidsstempel og postkilde.
#2. Lenker
Lenker etablerer relasjoner mellom forretningsnøklene. Hver oppføring i en lenke modellerer n:m-relasjoner til et hvilket som helst antall huber. Dette gir datahvelvet fleksibilitet til å reagere på endringer i forretningslogikken til kildesystemene, for eksempel endringer i relasjoners kardinalitet. Akkurat som navet, inneholder ikke lenken noen beskrivende informasjon. Den består av sekvens-ID-ene til hubene den refererer til, en lagergenerert sekvens-ID, lastedato/tidsstempel og postkilde.
#3. Satellitter
Satellitter inneholder beskrivende informasjon (kontekst) for en forretningsnøkkel som er lagret i en hub eller et forhold som er lagret i en lenke. Satellitter fungerer «bare inn», noe som betyr at hele datahistorikken er lagret i satellitten. Flere satellitter kan beskrive en enkelt forretningsnøkkel (eller relasjon). En satellitt kan imidlertid bare beskrive én nøkkel (hub eller link).
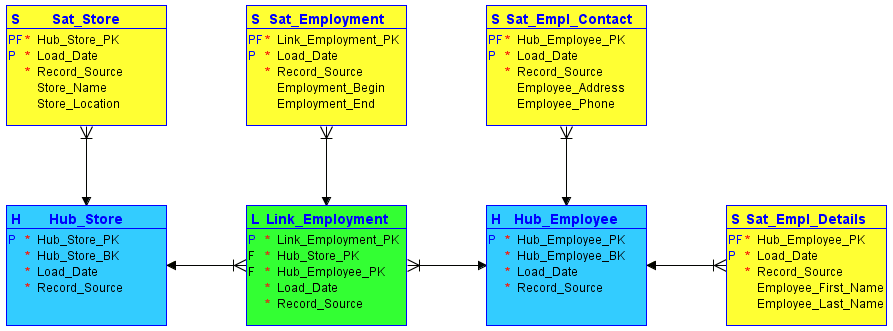
Bildekilde: Carbidfischer
Hvordan bygge en Data Vault-modell
Å bygge en Data Vault-modell involverer flere trinn, hver av dem er avgjørende for å sikre at modellen er skalerbar, fleksibel og kan møte virksomhetens behov:
#1. Identifiser enheter og attributter
Identifiser forretningsenhetene og deres tilhørende attributter. Dette innebærer å jobbe tett med virksomhetens interessenter for å forstå deres krav og hvilke data de trenger å fange opp. Når disse enhetene og attributtene er identifisert, deler du dem inn i huber, lenker og satellitter.
#2. Definer enhetsrelasjoner og opprett koblinger
Når du har identifisert enhetene og attributtene, defineres relasjonene mellom enhetene, og lenkene opprettes for å representere disse relasjonene. Hver lenke tildeles en forretningsnøkkel som identifiserer forholdet mellom enhetene. Satellittene legges deretter til for å fange opp attributtene til enhetene og relasjonene.
#3. Etabler regler og standarder
Etter å ha opprettet koblinger, bør et sett med regler og Data Vault-modelleringsstandarder etableres for å sikre at modellen er fleksibel og kan håndtere endringer over tid. Disse reglene og standardene bør gjennomgås og oppdateres regelmessig for å sikre at de forblir relevante og i samsvar med virksomhetens behov.
#4. Fyll ut modellen
Når modellen er opprettet, bør den fylles ut med data ved hjelp av en inkrementell lastemetode. Dette innebærer å laste dataene inn i huber, lenker og satellitter ved hjelp av delta-lastinger. Delta-lasting sikrer at bare endringene som er gjort i dataene lastes, noe som reduserer tiden og ressursene som kreves for dataintegrasjon.
#5. Test og valider modellen
Til slutt bør modellen testes og valideres for å sikre at den oppfyller virksomhetens krav og er skalerbar og fleksibel nok til å håndtere fremtidige endringer. Regelmessig vedlikehold og oppdateringer bør utføres for å sikre at modellen forblir i tråd med forretningsbehovene og fortsetter å gi en enhetlig oversikt over dataene.
Data Vault Læringsressurser
Å mestre Data Vault kan gi verdifulle ferdigheter og kunnskap som er svært etterspurt i dagens datadrevne bransjer. Her er en omfattende liste over ressurser, inkludert kurs og bøker, som kan hjelpe deg med å lære detaljene ved Data Vault:
#1. Modellering av datavarehus med Data Vault 2.0

Dette Udemy-kurset er en omfattende introduksjon til Data Vault 2.0-modelleringsmetoden, smidig prosjektledelse og Big Data-integrasjon. Kurset dekker det grunnleggende om Data Vault 2.0, inkludert arkitektur og lag, forretnings- og informasjonshvelv, samt avanserte modelleringsteknikker.
Du lærer å designe en Data Vault-modell fra bunnen av, konvertere tradisjonelle modeller som 3NF og dimensjonsmodeller til Data Vault, og forstå prinsippene for dimensjonsmodellering i Data Vault. Kurset krever grunnleggende kunnskap om databaser og grunnleggende SQL.
Med en høy vurdering på 4,4 av 5 og over 1700 anmeldelser, passer dette bestselgende kurset for alle som ønsker å bygge et sterkt fundament i Data Vault 2.0 og Big Data-integrasjon.
#2. Datahvelvmodellering forklart med brukstilfelle

Dette Udemy-kurset er designet for å veilede deg i å bygge en Data Vault-modell ved hjelp av et praktisk forretningseksempel. Det fungerer som en nybegynnerguide til Data Vault-modellering, som dekker nøkkelbegreper som egnede scenarier for bruk av Data Vault-modeller, begrensningene ved konvensjonell OLAP-modellering og en systematisk tilnærming til å konstruere en Data Vault-modell. Kurset er tilgjengelig for personer med minimal databasekunnskap.
#3. Data Vault Guru: en pragmatisk guide
Data Vault Guru av Patrick Cuba er en grundig guide til Data Vault-metodikken. Boken gir en unik mulighet til å modellere bedriftens datavarehus ved å bruke automatiseringsprinsipper som ligner de som brukes i programvarelevering.
Boken gir en oversikt over moderne arkitektur, og deretter en detaljert veiledning om hvordan man kan levere en fleksibel datamodell som tilpasser seg endringer i virksomheten med Data Vault.
I tillegg utvider boken Data Vault-metodikken ved å tilby automatiserte tidslinjekorreksjoner, revisjonsspor, metadatakontroll og integrasjon med smidige leveringsverktøy.
#4. Bygge et skalerbart datavarehus med Data Vault 2.0
Denne boken gir leserne en omfattende veiledning for å lage et skalerbart datavarehus fra start til slutt, ved hjelp av Data Vault 2.0-metoden.
Boken dekker alle de vesentlige aspektene ved å bygge et skalerbart datavarehus, inkludert Data Vault-modelleringsteknikken, som er designet for å forhindre typiske feil i datavarehus.
Boken inneholder en rekke eksempler for å hjelpe leserne å forstå konseptene tydelig. Med sin praktiske innsikt og eksempler fra virkeligheten, er denne boken en viktig ressurs for alle som er interessert i datavarehus.
#5. The Elephant in the Fridge: Guided Steps to Data Vault Success
The Elephant in the Fridge av John Giles er en praktisk veiledningsbok som har som mål å hjelpe lesere med å oppnå Data Vault-suksess ved å starte med virksomheten og avslutte med virksomheten.
Boken fokuserer på viktigheten av bedriftsontologi og forretningskonseptmodellering, og gir en trinn-for-trinn-veiledning om hvordan disse konseptene kan brukes til å lage en robust datamodell.
Gjennom praktiske råd og eksempler gir forfatteren en klar og ukomplisert forklaring på kompliserte emner, noe som gjør boken til en utmerket guide for de som er nye i Data Vault.
Siste ord
Data Vault representerer fremtiden for datavarehus, og tilbyr bedrifter betydelige fordeler når det gjelder fleksibilitet, skalerbarhet og effektivitet. Det er spesielt godt egnet for bedrifter som trenger å laste inn store datamengder raskt, og for de som ønsker å utvikle sine business intelligence-applikasjoner på en smidig måte.
I tillegg kan bedrifter med en eksisterende siloarkitektur ha stor nytte av å implementere et oppstrøms kjernedatavarehus ved hjelp av Data Vault.
Du er kanskje også interessert i å lære om datalinje.