Llama 2 er en betydelig åpen kildekode språkmodell (LLM), utviklet av Meta. Den utmerker seg som en kraftig og tilgjengelig LLM, og demonstrerer en ytelse som overgår flere proprietære modeller, som GPT-3.5 og PaLM 2. Modellen er tilgjengelig i tre forskjellige størrelser, med henholdsvis 7 milliarder, 13 milliarder og 70 milliarder parametere, både i forhåndstrente og finjusterte versjoner.
I denne veiledningen vil vi utforske Llama 2s evne til å forstå og generere naturlig språk ved å konstruere en interaktiv chatbot, der vi kombinerer Llama 2 med Streamlit.
Lær om Llama 2: Egenskaper og fordeler
Hva skiller Llama 2 fra sin forgjenger, Llama 1?
- Utvidet modellkapasitet: Med opptil 70 milliarder parametere er Llama 2 betydelig større, noe som muliggjør mer sofistikert læring av forhold mellom ord og setninger.
- Forbedret interaksjonsevne: Ved å implementere forsterkningslæring fra menneskelig tilbakemelding (RLHF) er modellens evne til å generere menneskelignende tekst og engasjere seg i naturlige dialoger kraftig forbedret.
- Hurtigere inferens: Ved hjelp av en ny metode kalt grouped-query attention, er inferensprosessen betydelig akselerert, noe som åpner for et bredere spekter av praktiske anvendelser, som chatbots og virtuelle assistenter.
- Økt effektivitet: Llama 2 er mer ressurseffektiv enn sin forgjenger, både når det gjelder minnebruk og datakraft.
- Åpen kildekode og ikke-kommersiell lisens: Som en åpen kildekode-modell er Llama 2 fritt tilgjengelig for forskere og utviklere, med muligheten for tilpasning og videreutvikling uten restriksjoner.
Llama 2 markerer et betydelig sprang fremover sammenlignet med sin forgjenger, med forbedringer på alle sentrale områder. Dette gjør den til et verdifullt verktøy for et mangfold av bruksområder, inkludert utvikling av chatbots, virtuelle assistenter og avansert naturlig språkforståelse.
Oppsett av Streamlit-miljø for Chatbot-utvikling
For å starte utviklingen, må du konfigurere et dedikert utviklingsmiljø. Dette bidrar til å holde prosjektet isolert fra eventuelle eksisterende prosjekter på datamaskinen.
Først, opprett et virtuelt miljø ved hjelp av Pipenv-biblioteket ved å kjøre kommandoen:
pipenv shell
Deretter installerer du de nødvendige bibliotekene:
pipenv install streamlit replicate
Streamlit er et åpen kildekode Python-bibliotek som gjør det raskt og enkelt å bygge webapper for maskinlæring og dataanalyse.
Replicate er en skybasert plattform som gir tilgang til avanserte maskinlæringsmodeller med åpen kildekode for rask implementering.
Skaff deg Llama 2 API-token fra Replicate
For å få tilgang til en Replicate-token, må du først registrere en konto på Replicate ved hjelp av en GitHub-konto.
Naviger til «Utforsk» og søk etter «Llama 2-chat» for å finne llama-2-70b-chat-modellen.
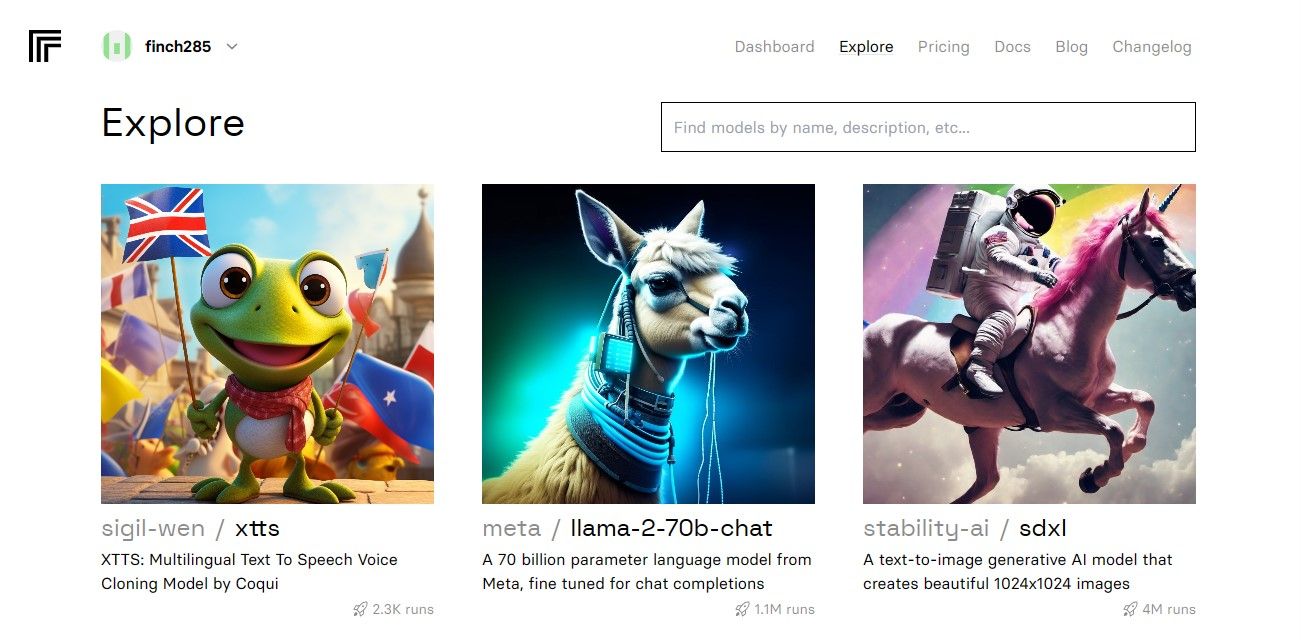
Klikk på llama-2-70b-chat-modellen for å vise API-endepunktene. Klikk deretter på «API»-knappen i navigasjonslinjen og velg «Python»-knappen til høyre. Her vil du finne API-tokenet som kreves for Python-applikasjoner.
Kopier din «REPLICATE_API_TOKEN» og lagre den på et trygt sted.
Utvikling av Chatbot
Opprett en ny Python-fil kalt «llama_chatbot.py» og en «.env»-fil. All koding vil skje i «llama_chatbot.py», mens sensitive nøkler og API-tokens skal lagres i «.env»-filen.
I «llama_chatbot.py» importerer du nødvendige biblioteker:
import streamlit as st
import os
import replicate
Deretter setter du globale variabler for Llama 2-modellene:
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
I «.env»-filen legger du til Replicate-tokenet og modellendepunktene i følgende format:
REPLICATE_API_TOKEN='Ditt_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Lagre .env-filen etter å ha limt inn ditt Replicate-token.
Design av Chatbotens samtalefløde
Definer en startmelding for å konfigurere Llama 2-modellen, avhengig av den rollen du vil at den skal utføre. I dette tilfellet skal den fungere som en hjelpsom assistent.
PRE_PROMPT = "Du er en hjelpsom assistent. Du skal ikke svare som 'Bruker' eller late som om du er 'Bruker'. " \
" Du svarer bare én gang som Assistent."
Sett opp sidekonfigurasjonen for chatbot-applikasjonen:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Lag en funksjon som initialiserer og setter opp variabler i sesjonstilstand:
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Velg en LLaMA2-modell:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Denne funksjonen setter de essensielle variablene i sesjonstilstanden, som «chat_dialogue», «pre_prompt», «llm», «top_p», «max_seq_len» og «temperatur». Den håndterer også valg av Llama 2-modell basert på brukerens preferanse.
Skriv en funksjon for å vise sidepanelinnholdet i Streamlit-appen:
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperatur:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Maksimal sekvenslengde:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Startmelding før chat. Rediger her om ønskelig:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Denne funksjonen genererer overskriften og justerbare innstillinger for Llama 2 chatbot.
Lag en funksjon for å vise chatloggen i hovedinnholdsområdet i Streamlit-appen:
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Funksjonen går gjennom «chat_dialogue» som er lagret i sesjonstilstanden, og viser hver melding med sin tilhørende rolle («bruker» eller «assistent»).
Håndter brukerens innspill med følgende funksjon:
def handle_user_input():
user_input = st.chat_input(
"Skriv ditt spørsmål her for å snakke med LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Denne funksjonen gir brukeren et inndatafelt for å sende meldinger eller stille spørsmål. Når brukeren sender inn meldingen, legges den til «chat_dialogue» med rollen «bruker».
Lag en funksjon som genererer svar fra Llama 2-modellen og viser dem i chatteområdet:
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "Bruker" if dict_message["role"] == "user" else "Assistent"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistent: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Denne funksjonen genererer en logg med både bruker- og assistentmeldinger før den kaller «debounce_replicate_run» for å generere assistentens svar. Svaret vises kontinuerlig i brukergrensesnittet for å gi en dynamisk chat-opplevelse.
Skriv en hovedfunksjon som er ansvarlig for å vise hele Streamlit-appen:
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Denne funksjonen kaller alle tidligere definerte funksjoner for å sette opp sesjonstilstanden, vise sidepanelet, chatloggen, håndtere brukerinndata og generere assistentsvar.
Definer en funksjon for å starte «render_app» og starte applikasjonen:
def main():
render_app()if __name__ == "__main__":
main()
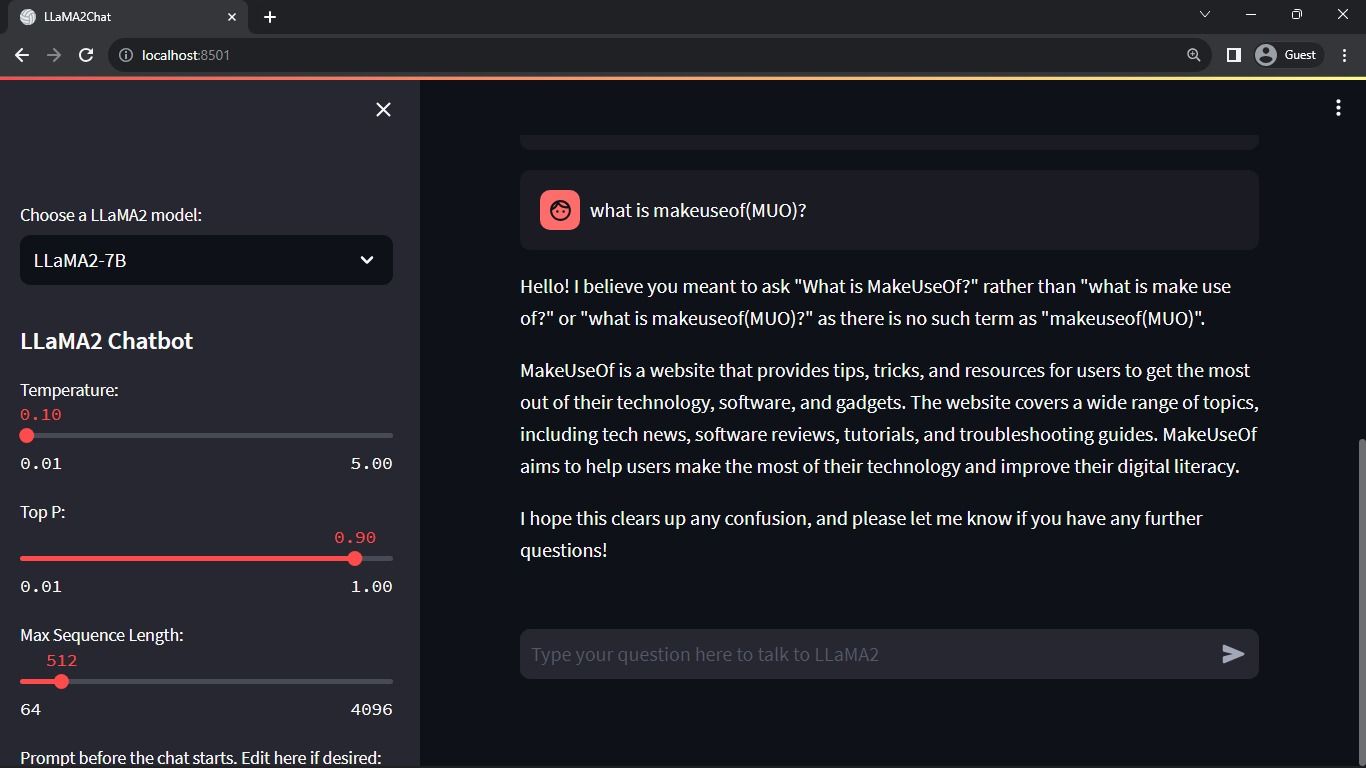
Nå skal applikasjonen være klar til bruk.
Håndtering av API-forespørsler
Opprett en «utils.py»-fil i prosjektkatalogen og legg til følgende funksjon:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("Siste kalletid: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Debouncing")
return "Hei! Dine forespørsler er for raske. Vennligst vent noen få" \
" sekunder før du sender en ny forespørsel."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistent: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Denne funksjonen implementerer en «debounce»-mekanisme for å begrense hyppige API-kall fra brukerens innspill.
Importer funksjonen «debounce_replicate_run» i «llama_chatbot.py»:
from utils import debounce_replicate_run
Kjør applikasjonen:
streamlit run llama_chatbot.py
Forventet resultat:
Applikasjonen vil vise en dialog mellom Llama 2-modellen og brukeren.
Praktiske Anvendelser av Streamlit og Llama 2 Chatbots
Noen praktiske anvendelser av Llama 2 inkluderer:
- Chatbots: Kan brukes til å lage chatbots med menneskelignende respons som kan holde samtaler i sanntid om en rekke emner.
- Virtuelle assistenter: Kan brukes til å utvikle virtuelle assistenter som forstår og reagerer på spørsmål i naturlig språk.
- Språkoversettelse: Kan brukes til språkoversettelse.
- Tekstoppsummering: Kan brukes til å oppsummere lange tekster til korte utdrag for enklere forståelse.
- Forskning: Kan brukes til forskningsformål ved å svare på spørsmål innen et bredt spekter av fagområder.
Fremtiden for AI
Med proprietære modeller som GPT-3.5 og GPT-4, kan det være vanskelig for mindre aktører å utvikle noe av betydning ved hjelp av LLM-er, da tilgangen til GPT-modellens API kan være ganske kostbar.
Tilgjengeliggjøringen av avanserte store språkmodeller, som Llama 2, for utviklerfellesskapet, er begynnelsen på en ny æra innen kunstig intelligens. Dette vil fremme mer kreative og innovative bruksområder for modellene i praktiske applikasjoner, og akselerere utviklingen mot kunstig superintelligens (ASI).