Utforsk Dataanalyse med Naturlig Språk og PandasAI
Er du nysgjerrig på hvordan du kan analysere dataene dine ved hjelp av naturlig språk? La oss se på hvordan Python-biblioteket PandasAI kan hjelpe deg med det.
I dagens datadrevne verden er evnen til å forstå og analysere data avgjørende. Likevel kan tradisjonelle metoder for dataanalyse virke kompliserte og tidkrevende. Her kommer PandasAI inn i bildet. Dette biblioteket forenkler prosessen ved å la deg kommunisere med dataene dine på en måte som er mer naturlig for oss – ved å bruke naturlig språk.
PandasAI opererer ved å oversette dine spørsmål om data til kode som utfører analysen. Det er bygget på toppen av det populære Python-biblioteket pandas. PandasAI er et utvidelse til pandas som tilfører generativ AI-funksjonalitet, og det er ment å være et supplement til pandas, ikke en erstatning.
Med PandasAI får pandas og andre vanlige dataanalysebiblioteker en samtalebasert dimensjon. Du kan interagere med dataene dine gjennom spørsmål formulert på vanlig språk.
Denne guiden vil lose deg gjennom installasjonsprosessen av PandasAI, demonstrere hvordan du bruker det med et ekte datasett, generere visuelle fremstillinger, utforske snarveier, samt avdekke styrkene og begrensningene til dette kraftige verktøyet.
Etter å ha fullført denne veiledningen, vil du være i stand til å utføre dataanalyse på en mer tilgjengelig og intuitiv måte, ved hjelp av naturlig språk.
Så, la oss dykke ned i den spennende verdenen av dataanalyse ved bruk av naturlig språk med PandasAI!
Oppsett av Utviklingsmiljøet
For å komme i gang med PandasAI, starter du med å installere selve biblioteket.
I denne demonstrasjonen bruker jeg en Jupyter Notebook, men du kan også bruke Google Colab eller VS Code, avhengig av dine preferanser.
Hvis du planlegger å benytte deg av Open AI Large Language Models (LLM), er det også viktig å installere Open AI Python SDK for en problemfri opplevelse.
# Installerer PandasAI !pip install pandas-ai # PandasAI bruker OpenAI's språkmodeller, så du må installere OpenAI Python SDK !pip install openai
La oss nå importere alle de nødvendige bibliotekene:
# Importerer nødvendige biblioteker import pandas as pd import numpy as np # Importerer PandasAI og dets komponenter from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
En sentral del av dataanalysen med PandasAI er API-nøkkelen. Verktøyet er kompatibelt med flere store språkmodeller (LLMs) og LangChain-modeller som brukes for å generere kode fra naturlige språkspørringer. Dette gjør dataanalysen mer tilgjengelig og brukervennlig.
PandasAI er fleksibel og kan fungere med et bredt utvalg av modeller. Disse inkluderer Hugging Face-modeller, Azure OpenAI, Google PALM og Google VertexAI. Hver modell bidrar med sine unike styrker, og forbedrer PandasAIs samlede kapasitet.
Husk at for å bruke disse modellene, trenger du de relevante API-nøklene. Disse nøklene bekrefter forespørslene dine og lar deg dra nytte av disse avanserte språkmodellene i dine dataanalyseprosjekter. Så sørg for at du har API-nøklene klare når du setter opp PandasAI for dine prosjekter.
Du kan hente API-nøkkelen og definere den som en miljøvariabel.
I det neste trinnet skal vi se hvordan du kan bruke PandasAI med forskjellige store språkmodeller (LLM) fra OpenAI og Hugging Face Hub.
Anvende Store Språkmodeller
Du har to alternativer for å velge en LLM: enten ved å instansiere en modell og sende den til SmartDataFrame- eller SmartDatalake-konstruktøren, eller ved å definere en i pandasai.json-filen.
Hvis modellen forventer en eller flere parametere, kan du enten sende dem til konstruktøren eller spesifisere dem i pandasai.json-filen under llm_options-parameteren, slik:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}
Slik Bruker du OpenAI-modeller
For å bruke OpenAI-modeller, trenger du en OpenAI API-nøkkel. Du kan skaffe deg en her.
Når du har en API-nøkkel, kan du bruke den til å opprette et OpenAI-objekt:
# Vi har importert alle nødvendige biblioteker i forrige steg
llm = OpenAI(api_token="min-api-nøkkel")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Husk å erstatte «min-api-nøkkel» med din faktiske API-nøkkel.
Alternativt kan du sette miljøvariabelen OPENAI_API_KEY og instansiere OpenAI-objektet uten å sende API-nøkkelen:
# Setter miljøvariabelen OPENAI_API_KEY
llm = OpenAI() # ikke nødvendig å sende API-nøkkelen, den leses fra miljøvariabelen
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Hvis du er bak en eksplisitt proxy, kan du spesifisere openai_proxy når du instansierer OpenAI-objektet, eller definere at OPENAI_PROXY-miljøvariabelen skal benyttes.
Viktig merknad: Når du bruker PandasAI-biblioteket til dataanalyse med API-nøkkelen din, er det viktig å følge med på tokenbruken din for å håndtere kostnadene dine.
Lurer du på hvordan du gjør dette? Bare kjør følgende tokentellerkode for å få et klart bilde av tokenbruken din og de tilsvarende kostnadene. På denne måten kan du effektivt administrere ressursene dine og unngå overraskelser i faktureringen.
Du kan telle antall tokens som brukes av en melding slik:
"""Eksempel på bruk av PandasAI med en pandas dataframe"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False er ment å vise lavere bruk og kostnad
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Beregn summen av BNP for de nordamerikanske landene")
print(response)
print(cb)
Du vil få resultater som dette:
# Summen av BNP for de nordamerikanske landene er 19 294 482 071 552. # Tokens Brukt: 375 # Prompt Tokens: 210 # Completion Tokens: 165 # Total kostnad (USD): $0.000750
Ikke glem å holde oversikt over de totale kostnadene dine hvis du har begrenset kreditt!
Slik Bruker du Hugging Face-modeller
For å bruke HuggingFace-modeller, trenger du en HuggingFace API-nøkkel. Du kan opprette en HuggingFace-konto her og få en API-nøkkel her.
Når du har en API-nøkkel, kan du bruke den til å instansiere en av HuggingFace-modellene.
PandasAI støtter for øyeblikket følgende HuggingFace-modeller:
- Starcoder: bigcode/starcoder
- Falcon: tiiuae/falcon-7b-instruct
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="min-huggingface-api-nøkkel")
# eller
llm = Falcon(api_token="min-huggingface-api-nøkkel")
df = SmartDataframe("data.csv", config={"llm": llm})
Alternativt kan du sette miljøvariabelen HUGGINGFACE_API_KEY og instansiere HuggingFace-objektet uten å sende API-nøkkelen:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # ikke nødvendig å sende API-nøkkelen, den leses fra miljøvariabelen
# eller
llm = Falcon() # ikke nødvendig å sende API-nøkkelen, den leses fra miljøvariabelen
df = SmartDataframe("data.csv", config={"llm": llm})
Starcoder og Falcon er begge LLM-modeller tilgjengelige på Hugging Face.
Vi har nå satt opp utviklingsmiljøet og sett hvordan man bruker både OpenAI og Hugging Face LLMs-modeller. La oss nå gå videre med vår dataanalysereise.
Vi skal bruke datasettet Big Mart Sales Data, som inneholder informasjon om salget av ulike produkter i ulike butikker i Big Mart. Datasettet har 12 kolonner og 8524 rader. Du finner lenken på slutten av denne artikkelen.
Dataanalyse med PandasAI
Nå som vi har installert og importert alle de nødvendige bibliotekene, kan vi laste inn datasettet vårt.
Laste Inn Datasettet
Du kan enten velge en LLM ved å instansiere en og sende den til SmartDataFrame. Du finner lenken til datasettet på slutten av artikkelen.
# Laster inn datasettet fra enheten path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
Bruke OpenAIs LLM-modell
Etter å ha lastet inn dataene, skal jeg bruke OpenAIs LLM-modell til PandasAI
llm = OpenAI(api_token="API-Nøkkel") pandas_ai = PandasAI(llm, conversational=False)
Flott! La oss prøve noen meldinger.
Skriver Ut de 6 Første Radene i Datasettet Vårt
La oss prøve å laste de første 6 radene ved å gi en instruksjon:
Resultat = pandas_ai(df, "Vis de første 6 radene med data i tabellform") Resultat
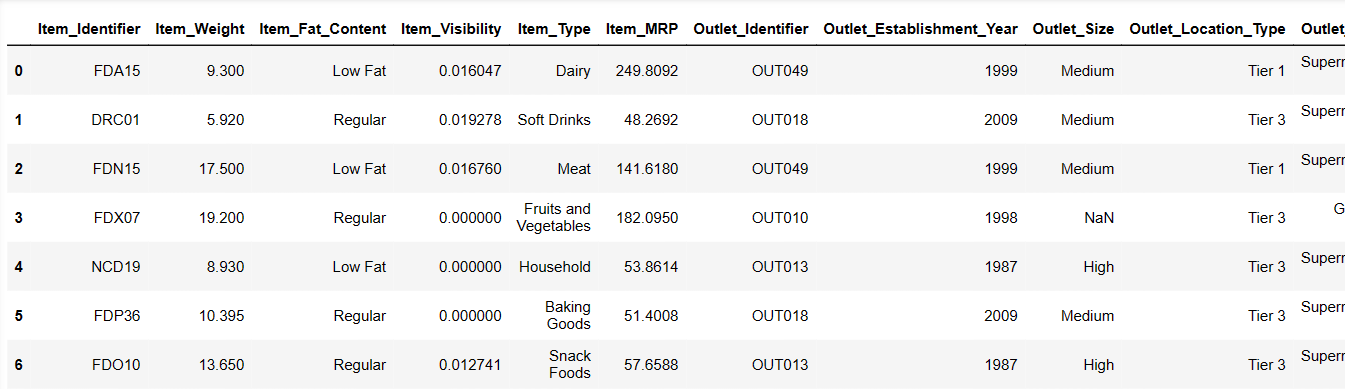 De første 6 radene fra datasettet
De første 6 radene fra datasettet
Det gikk veldig raskt! La oss analysere datasettet vårt.
Generere Beskrivende Statistikk for DataFrame
# For å få beskrivende statistikk Resultat = pandas_ai(df, "Vis beskrivelsen av dataene i tabellform") Resultat
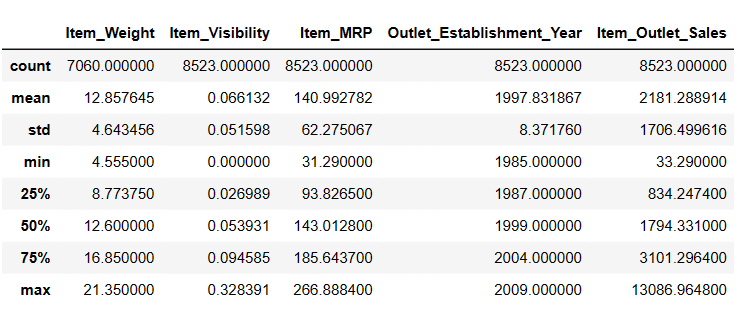 Beskrivelse
Beskrivelse
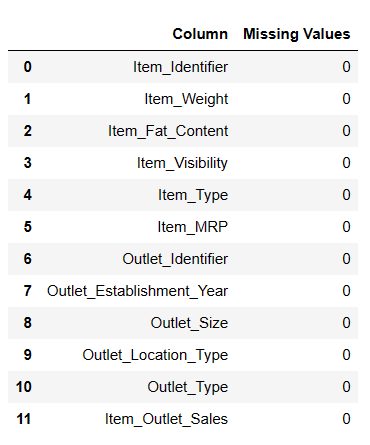
Det er 7060 verdier i Item_Weigth, så kanskje noen verdier mangler.
Finne Manglende Verdier
Det er to måter å finne manglende verdier ved hjelp av Pandas AI.
# Finner manglende verdier Resultat = pandas_ai(df, "Vis de manglende verdiene i dataene i tabellform") Resultat
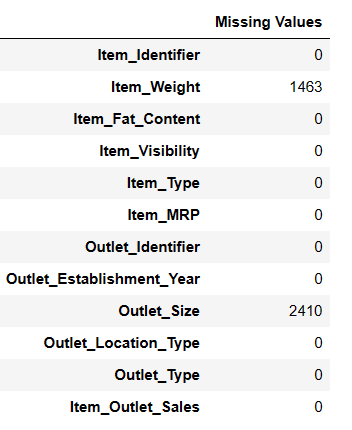 Finne manglende verdier
Finne manglende verdier
# Snarvei for Datavask
df = SmartDataframe('data.csv')
df.clean_data()
Denne snarveien utfører datavask på dataframe.
La oss nå fylle inn de manglende nullverdiene.
Fylle Inn Manglende Verdier
# Fylle inn manglende verdier resultat = pandas_ai(df, "Fyll Item Weight med median og Item outlet size nullverdier med modus og Vis de manglende verdiene i dataene i tabellform") resultat
 Utfylte nullverdier
Utfylte nullverdier
Det er en nyttig måte å fylle ut nullverdier, men jeg støtte på noen problemer når jeg forsøkte å fylle ut nullverdier.
# Snarvei for Å Fylle Nullverdier
df = SmartDataframe('data.csv')
df.impute_missing_values()
Denne snarveien setter inn manglende verdier i dataframe.
Fjerne Nullverdier
Hvis du ønsker å fjerne alle nullverdier fra df-en din, kan du prøve denne metoden.
resultat = pandas_ai(df, "Fjern radene med manglende verdier med inplace=True") resultat
Dataanalyse er avgjørende for å identifisere trender, både kortsiktige og langsiktige, som kan være uvurderlig for bedrifter, myndigheter, forskere og enkeltpersoner.
La oss prøve å finne en generell salgstrend gjennom årene siden etableringen.
Finne Salgstrender
# Finner trender i salg resultat = pandas_ai(df, "Hva er den generelle salgstrenden over årene siden butikken ble etablert?") resultat
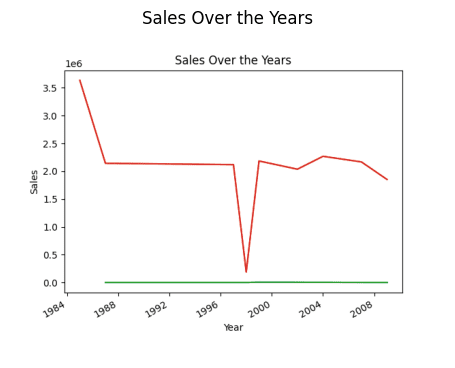 Salg gjennom året (Linjediagram)
Salg gjennom året (Linjediagram)
Den første plottprosessen var litt treg, men etter å ha startet kjernen på nytt og kjørt alt på nytt, gikk det raskere.
# Snarvei til Å Tegne Linjediagrammer
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Denne snarveien vil tegne et linjediagram over dataframen.
Du lurer kanskje på hvorfor det er en nedgang i trenden. Det er fordi vi mangler data fra 1989 til 1994.
Finne Året med Høyest Salg
La oss finne ut hvilket år som hadde høyest salg.
# Finner året med høyest salg resultat = pandas_ai(df, "Forklar hvilke år som hadde høyest salg") resultat

Så året med høyest salg er 1985.
Men jeg ønsker å finne ut hvilken varetype som genererer det høyeste gjennomsnittlige salget, og hvilken type som genererer det laveste gjennomsnittlige salget.
Høyeste og Laveste Gjennomsnittlige Salg
# Finner høyeste og laveste gjennomsnittlige salg resultat = pandas_ai(df, "Hvilken varetype genererer det høyeste gjennomsnittlige salget, og hvilken genererer det laveste?") resultat

Stivelsesholdige matvarer har det høyeste gjennomsnittlige salget, og andre har det laveste gjennomsnittlige salget. Hvis du ikke ønsker andre som det laveste salget, kan du forbedre spørsmålet etter behov.
Fantastisk! Nå ønsker jeg å finne ut fordelingen av salg på tvers av ulike utsalgssteder.
Fordeling av Salg på Tvers av Ulike Utsalgssteder
Det finnes fire typer utsalgssteder: Supermarked Type 1/2/3 og Dagligvarebutikker.
# Fordeling av salg på tvers av ulike utsalgssteder siden etableringen respons = pandas_ai(df, "Visualiser fordelingen av salg på tvers av ulike utsalgssteder siden etableringen ved hjelp av stolpediagram, plottstørrelse=(13,10)") respons
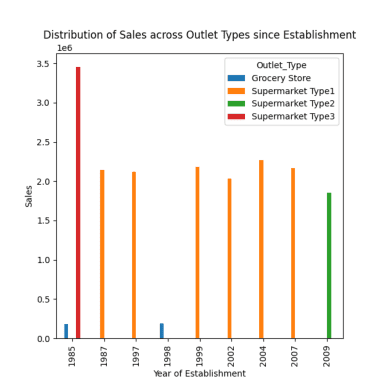 Fordeling av salg på tvers av ulike utsalgssteder
Fordeling av salg på tvers av ulike utsalgssteder
Som observert i tidligere meldinger, skjedde toppsalget i 1985, og dette plottet fremhever det høyeste salget i 1985 fra supermarked type 3-utsalgssteder.
# Snarvei for å tegne stolpediagram
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Denne snarveien vil tegne et stolpediagram over dataframen.
# Snarvei for å tegne histogram
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
Denne snarveien vil tegne et histogram over dataframen.
La oss nå finne ut hva som er gjennomsnittlig salg for varene med «Lavt fett» og «Vanlig» fettinnhold.
Finn Gjennomsnittlig Salg for Varer med Fettinnhold
# Finner indeksen for en rad ved hjelp av verdien av en kolonne resultat = pandas_ai(df, "Hva er det gjennomsnittlige salget for varene med 'Lavt fett' og 'Vanlig' fettinnhold?") resultat
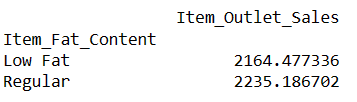
Ved å skrive meldinger som dette, kan du sammenligne to eller flere produkter.
Gjennomsnittlig Salg for Hver Varetype
Jeg ønsker å sammenligne alle produkter med deres gjennomsnittlige salg.
# Gjennomsnittlig salg for hver varetype resultat = pandas_ai(df, "Hva er det gjennomsnittlige salget for hver varetype de siste 5 årene?, bruk sektordiagram, størrelse=(6,6)") resultat
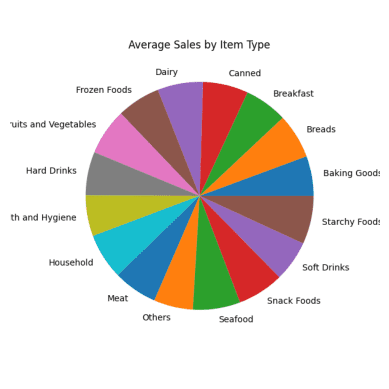 Gjennomsnittlig Salg Sektordiagram
Gjennomsnittlig Salg Sektordiagram
Alle deler av sektordiagrammet ser like ut fordi de har nesten de samme salgstallene.
# Snarvei for å tegne sektordiagram
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
Denne snarveien vil tegne et sektordiagram over dataframen.
Topp 5 Mest Solgte Varetyper
Selv om vi allerede har sammenlignet alle produktene basert på gjennomsnittlig salg, ønsker jeg nå å identifisere de 5 beste varene med høyest salg.
# Finner de 5 mest solgte varene resultat = pandas_ai(df, "Hva er de 5 mest solgte varetypene basert på gjennomsnittlig salg? Skriv i tabellform") resultat
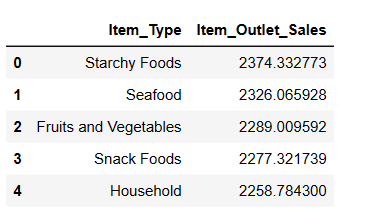
Som forventet, er stivelsesholdig mat den mest solgte varen basert på gjennomsnittlig salg.
Topp 5 Lavest Selgende Varetyper
resultat = pandas_ai(df, "Hva er de 5 lavest selgende varetypene basert på gjennomsnittlig salg?") resultat
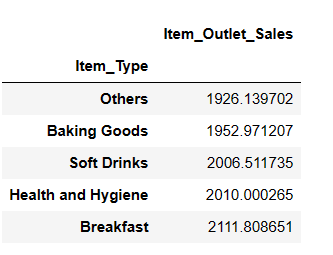
Du kan bli overrasket over å se brus i den lavest selgende kategorien. Det er imidlertid viktig å merke seg at disse dataene bare går frem til 2008, og trenden for brus tok av noen år senere.
Salg av Produktkategorier
Her brukte jeg ordet «produktkategori» i stedet for «varetype», og PandasAI opprettet fortsatt plottene, og demonstrerte sin evne til å forstå lignende ord.
resultat = pandas_ai(df, "Gi et stablet stolpediagram i stor størrelse av salget av de ulike produktkategoriene for siste regnskapsår") resultat
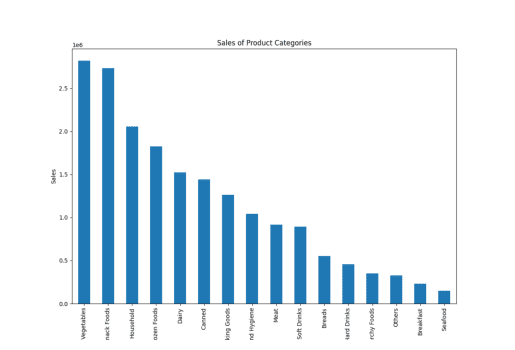 Salg av varetype
Salg av varetype
Du finner de resterende snarveiene våre her.
Du vil kanskje merke at når vi skriver en forespørsel og gir instruksjoner til PandasAI, gir den resultater basert utelukkende på den spesifikke forespørselen. Den analyserer ikke de tidligere spørsmålene dine for å gi mer nøyaktige svar.
Men med hjelp fra en chatagent, kan du også oppnå denne funksjonaliteten.
Chat Agent
Med chatagenten kan du delta i dynamiske samtaler der agenten husker konteksten gjennom hele diskusjonen. Dette gjør at du kan ha mer interaktive og meningsfulle utvekslinger.
Nøkkelfunksjonene som styrker denne interaksjonen, inkluderer kontekstbevaring, der agenten husker samtaleloggen, noe som gir sømløse, kontekstbevisste interaksjoner. Du kan bruke avklaringsspørsmåls-metoden for å be om avklaring på ethvert aspekt av samtalen, og sørge for at du fullt ut forstår informasjonen som gis.
I tillegg er forklar-metoden tilgjengelig for å få detaljerte forklaringer på hvordan agenten kom frem til en bestemt løsning eller svar, noe som gir åpenhet og innsikt i agentens beslutningsprosess.
Ta gjerne initiativ til samtaler, be om avklaringer og utforsk forklaringer for å forbedre interaksjonen din med chatagenten!
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
resultat = agent.chat("Hvilke er de 5 varene med høyest MRP?")
resultat
I motsetning til en SmartDataframe eller en SmartDatalake, vil en agent huske tilstanden til samtalen og kunne svare på flerleddede samtaler.
La oss se på fordelene og begrensningene til PandasAI
Fordeler med PandasAI
Å bruke Pandas AI gir flere fordeler som gjør det til et verdifullt verktøy for dataanalyse, slik som:
- Tilgjengelighet: PandasAI forenkler dataanalyse og gjør det tilgjengelig for et bredt spekter av brukere. Alle, uavhengig av deres tekniske bakgrunn, kan bruke det til å trekke ut innsikt fra data og svare på forretningsspørsmål.
- Naturlige språkspørringer: Muligheten til å stille direkte spørsmål og motta svar fra data ved hjelp av naturlige språkspørringer, gjør datautforskning og -analyse mer brukervennlig. Denne funksjonen lar selv ikke-tekniske brukere samhandle effektivt med data.
- Agentchat-funksjonalitet: Chat-funksjonen lar brukere engasjere seg interaktivt med data, mens agentchat-funksjonen benytter tidligere chatlogg for å gi kontekstbevisste svar. Dette fremmer en dynamisk og samtalebasert tilnærming til dataanalyse.
- Datavisualisering: PandasAI tilbyr en rekke datavisualiseringsalternativer, inkludert varmekart, spredningsplott, stolpediagram, sektordiagram, linjediagram og mer. Disse visualiseringene bidrar til å forstå og presentere datamønstre og trender.
- Tidsbesparende snarveier: Tilgjengeligheten av snarveier og tidsbesparende funksjoner strømlinjeformer dataanalyseprosessen og hjelper brukerne med å jobbe mer effektivt.
- Filkompatibilitet: PandasAI støtter ulike filformater, inkludert CSV, Excel, Google Sheets og mer. Denne fleksibiliteten gjør at brukerne kan jobbe med data fra en rekke kilder og formater.
- Egendefinerte forespørsler: Brukere kan lage egendefinerte forespørsler ved hjelp av enkle instruksjoner og Python-kode. Denne funksjonen gir brukerne muligheten til å skreddersy interaksjonene med data for å møte spesifikke behov og spørsmål.
- Lagre endringer: Muligheten til å lagre endringer som er gjort i dataframes, sikrer at arbeidet blir bevart, og at du kan gå tilbake til og dele analysen når som helst