En data lakehouse representerer en nyere tilnærming innen datahåndtering, og den forener det beste fra data lakes og data warehouses. Ved å implementere en data lakehouse-løsning, oppnår man evnen til å lagre et mangfold av datatyper på en felles plattform, samtidig som man kan utføre ACID-kompatible spørringer og analyser.
Hvorfor skulle man da velge en data lakehouse? Som en erfaren programvareingeniør, forstår jeg utfordringene som oppstår ved å administrere og vedlikeholde to separate systemer og flytte store datamengder mellom dem.
Dersom målet er å benytte data for forretningsanalyser og rapportering, er det vanlig å lagre strukturerte data i et data warehouse. Samtidig, for å oppbevare all data fra ulike kilder i sitt opprinnelige format, trengs en data lake. En data lakehouse eliminerer behovet for å vedlikeholde flere systemer, da den kombinerer fordelene fra begge disse tilnærmingene.
Betydningen av en Data Lakehouse

For å oppnå vekst og ekspansjon, må en organisasjon kunne lagre og analysere data uavhengig av format eller struktur. Data lakehouses spiller en sentral rolle i moderne datahåndtering ved å adressere begrensningene som finnes både i data lakes og data warehouses.
Data lakes kan fort bli til «data sumper» hvor data dumpes uten organisering eller kontroll. Dette gjør det vanskelig å finne og bruke dataen, og kan føre til problemer med datakvaliteten. På den annen side kan data warehouses være for rigide og kostbare i drift.
En data lakehouse kommer med en rekke egne kjennetegn. La oss se nærmere på disse.
Kjennetegn ved en Data Lakehouse
Før vi går dypere inn i data lakehouse-arkitekturen, skal vi utforske de viktigste funksjonene eller egenskapene til en data lakehouse.
- Den støtter transaksjoner: Ved bruk av en data lakehouse i større skala, vil det skje mange samtidige lese- og skriveoperasjoner. ACID-kompatibilitet sikrer at samtidige lese- og skriveoperasjoner ikke forstyrrer dataene.
- Støtte for Business Intelligence: Du kan integrere BI-verktøyene dine direkte mot de indekserte dataene. Behovet for å kopiere dataene til et annet sted elimineres. Dette gir deg tilgang til de mest oppdaterte dataene raskere og til en lavere kostnad.
- Atskilt datalagring og beregningslag: Når lagring og databehandling er separert, kan du skalere ett lag uavhengig av det andre. Hvis du trenger mer lagringskapasitet, kan du legge til dette uten å måtte skalere opp databehandlingen samtidig.
- Støtte for ulike datatyper: En data lakehouse er bygget på toppen av en data lake og støtter derfor et mangfold av datatyper og formater. Du kan lagre og analysere varierte datatyper som lyd, video, bilder og tekst.
- Åpenhet i lagringsformater: Data lakehouses benytter åpne og standardiserte lagringsformater, som Apache Parquet. Dette gjør det enkelt å koble til forskjellige verktøy og biblioteker for å få tilgang til dataene.
- Støtte for ulike arbeidsbelastninger: Ved å bruke dataene lagret i en data lakehouse, kan du utføre en rekke forskjellige oppgaver. Dette inkluderer spørringer via SQL, BI, analyse og maskinlæring.
- Støtte for sanntidsstrømming: Du slipper å opprette et eget datalager og kjøre en separat pipeline for sanntidsanalyse.
- Skjemastyring: Data lakehouses legger til rette for robust datastyring og revisjon.
Data Lakehouse Arkitektur
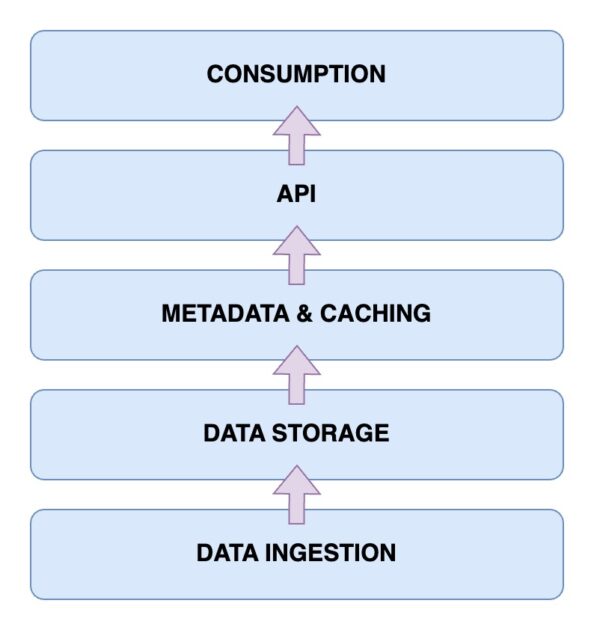
La oss nå se nærmere på arkitekturen til en data lakehouse. Å forstå denne arkitekturen er avgjørende for å forstå hvordan den fungerer. En data lakehouse-arkitektur består primært av fem hovedkomponenter. La oss gå gjennom dem en etter en.
Datainntakslag
Dette er laget hvor all data i forskjellige formater fanges opp. Dette kan være endringer i din primære database, data fra IoT-sensorer eller brukerdata i sanntid som strømmer gjennom datastrømmer.
Datalagringslag
Etter at data er hentet fra ulike kilder, er det på tide å lagre dem i de rette formatene. Dette er funksjonen til lagringslaget. Data kan lagres på forskjellige medier, som for eksempel AWS S3. Dette er i bunn og grunn din data lake.
Metadata- og bufferlag
Når datalagringslaget er på plass, trenger du et metadata- og dataadministrasjonslag. Dette laget gir en oversikt over alle dataene som finnes i data lake. Det er også dette laget som tilfører ACID-transaksjoner til den eksisterende data lake for å transformere den til en data lakehouse.
API-lag
Du kan få tilgang til de indekserte dataene fra metadatalaget ved hjelp av API-laget. Dette kan være i form av databasedrivere som lar deg utføre søk via kode, eller som endepunkter som er tilgjengelige fra alle klienter.
Dataforbrukslag
Dette laget består av dine analyse- og Business Intelligence-verktøy, som er hovedbrukerne av dataene fra data lakehouse. Her kan du kjøre maskinlæringsprogrammene dine for å hente verdifull innsikt fra dataene du har lagret og indeksert.
Nå har du en klar oversikt over arkitekturen til en data lakehouse. Men hvordan bygger du en?
Trinn for å bygge en Data Lakehouse
La oss se på hvordan du kan bygge din egen data lakehouse. Enten du allerede har en data lake eller et data warehouse, eller du bygger fra bunnen av, er trinnene stort sett de samme.
- Identifiser kravene: Dette inkluderer å definere hvilke typer data du skal lagre og hvilke bruksområder du vil dekke. Det kan være maskinlæringsmodeller, forretningsrapporter eller analyser.
- Opprett en inntakspipeline: Denne er ansvarlig for å hente data inn i systemet. Avhengig av kildesystemene som genererer data, kan det være nødvendig med meldingsbusser som Apache Kafka eller API-endepunkter.
- Bygg lagringslaget: Hvis du allerede har en data lake, kan denne fungere som lagringslag. Ellers kan du velge mellom alternativer som AWS S3, HDFS eller Delta Lake.
- Bruk databehandling: Her trekker du ut og transformerer dataene basert på forretningsbehov. Du kan bruke verktøy som Apache Spark for å kjøre forhåndsdefinerte periodiske jobber som henter og behandler data fra lagringslaget.
- Opprett metadatabehandling: Du må spore og lagre ulike datatyper og deres tilhørende egenskaper, slik at de enkelt kan katalogiseres og søkes etter ved behov. Det kan også være hensiktsmessig å opprette et bufferlag.
- Gi integrasjonsalternativer: Når din primære data lakehouse er klar, må du sørge for integrasjonspunkter der eksterne verktøy kan koble til og få tilgang til dataene. Dette kan inkludere SQL-spørringer, maskinlæringsverktøy eller Business Intelligence-løsninger.
- Implementer datastyring: Siden du skal arbeide med ulike typer data fra forskjellige kilder, må du etablere retningslinjer for datastyring, inkludert tilgangskontroll, kryptering og revisjon. Dette for å sikre datakvalitet, konsistens og samsvar med regelverket.
La oss se nærmere på hvordan du kan migrere til en data lakehouse dersom du allerede har en eksisterende datahåndteringsløsning.
Trinn for å migrere til en Data Lakehouse
Når du flytter dataarbeidsmengden til en data lakehouse-løsning, er det noen trinn som det er viktig å huske på. En god plan lar deg unngå uventede problemer.
Trinn 1: Analyser dataene
Det første og mest avgjørende trinnet for en vellykket migrering er dataanalyse. Med god analyse kan du definere omfanget av migreringen og identifisere eventuelle avhengigheter. Du vil da ha en bedre oversikt over miljøet og hva som skal migreres, noe som gir deg mulighet til å prioritere oppgavene dine.
Trinn 2: Forbered dataene for migrering
Det neste trinnet for en vellykket migrering er dataforberedelse. Dette inkluderer dataene som skal migreres, samt de nødvendige datarammene. Det kan spare verdifull tid og ressurser å vite hvilke datasett og kolonner som faktisk trengs, i stedet for å vente blindt på at all data skal være tilgjengelig.
Trinn 3: Konverter dataene til ønsket format
Du kan utnytte automatisk konvertering. Faktisk bør du prioritere verktøy for automatisk konvertering så langt som mulig. Datakonverteringer kan være komplekse ved migrering til en data lakehouse. Heldigvis kommer de fleste verktøy med lettleselig SQL-kode eller lavkodeløsninger. Verktøy som Alchemist kan hjelpe med dette.
Trinn 4: Valider dataene etter migrering
Etter at migreringen er fullført, er det på tide å validere dataene. Det er viktig å prøve å automatisere denne prosessen så mye som mulig, da manuell validering kan være tidkrevende og ineffektivt. Manuell validering bør kun brukes som en siste utvei. Det er også viktig å bekrefte at forretningsprosessene og datajobbene dine fortsetter å fungere som før etter migreringen.
Nøkkelfunksjoner i en Data Lakehouse
🔷 Komplett dataadministrasjon: Du får tilgang til funksjoner for datahåndtering som hjelper deg med å få mest mulig ut av dataene dine. Dette inkluderer datavask, ETL-prosesser (Extract-Transform-Load) og skjemahåndhevelse. Dermed kan du enkelt rense og forberede data for videre analyse og BI-verktøy.
🔷 Åpne lagringsformater: Data lagres i åpne og standardiserte formater. Dette betyr at data som samles inn fra ulike kilder lagres på samme måte, noe som forenkler arbeidsflyten. Det støttes formater som AVRO, ORC eller Parquet, i tillegg til tabellformater.
🔷 Separasjon av lagring: Du kan koble fra lagringen fra databehandlingsressursene ved å bruke separate klynger for begge. Dette gir mulighet til å skalere opp lagringsplassen etter behov uten å påvirke databehandlingsressursene.
🔷 Støtte for datastrømming: Datadrevet beslutningstaking innebærer ofte å konsumere datastrømmer i sanntid. En data lakehouse gir deg støtte for sanntids datainntak, noe som ikke er like vanlig i et standard data warehouse.
🔷 Datastyring: Sterk datastyring og revisjonsevner sikrer dataintegriteten.
🔷 Reduserte datakostnader: Driftskostnadene for en data lakehouse er relativt lavere enn for et data warehouse. Du kan få skyobjektlagring for dine voksende databehov til en lavere pris, og du får en hybridarkitektur som eliminerer behovet for å vedlikeholde flere datalagringssystemer.
Data Lake vs. Data Warehouse vs. Data Lakehouse
| Funksjon | Data Lake | Data Warehouse | Data Lakehouse |
| Datalagring | Lagrer rå eller ustrukturerte data | Lagrer behandlede og strukturerte data | Lagrer både rå og strukturert data |
| Dataskjema | Har ikke et fast skjema | Har et fast skjema | Bruker åpen kildekode-skjema for integrasjoner |
| Datatransformasjon | Data transformeres ikke | Omfattende ETL er nødvendig | ACID-kompatibel |
| Spørringsytelse | Vanligvis tregere, da data er ustrukturert | Veldig rask, grunnet strukturerte data | Rask, grunnet semi-strukturerte data |
| Kostnad | Lagring er kostnadseffektivt | Høyere lagrings- og spørringskostnader | Balanserte lagrings- og spørringskostnader |
| Datastyring | Krever nøye styring | Krever nøye styring | Sterk styring nødvendig |
| Brukssaker | Datalagring, utforskning, ML og AI | Rapportering og analyse ved bruk av BI | Både maskinlæring og analyse |
Konklusjon
Ved å kombinere styrkene til både data lakes og data warehouses på en sømløs måte, adresserer en data lakehouse de utfordringene som man ofte møter ved håndtering og analyse av data.
Du har nå lært om egenskapene og arkitekturen til en data lakehouse. Betydningen av en data lakehouse ligger i dens evne til å håndtere både strukturerte og ustrukturerte data, og tilby en enhetlig plattform for lagring, spørring og analyse, i tillegg til ACID-kompatibilitet.
Med trinnene som er beskrevet i denne artikkelen om å bygge og migrere til en data lakehouse, kan du utnytte fordelene ved en enhetlig og kostnadseffektiv plattform for dataadministrasjon. Hold deg oppdatert på det moderne landskapet for datahåndtering og ta datadrevne beslutninger, analyser og forretningsvekst.
Du kan også lese vår detaljerte artikkel om datareplikering.