I Linux-systemet spiller inoder en sentral rolle for filhåndtering. Disse ofte oversette elementene er grunnleggende for hvordan filsystemet fungerer. La oss se nærmere på hva inoder egentlig er og hvilken funksjon de har.
Grunnleggende om et filsystem
Et filsystem har som sin viktigste oppgave å lagre filer, samt å administrere kataloger. Filer organiseres i kataloger, og disse igjen kan inneholde underkataloger. Det er nødvendig med en mekanisme for å registrere hvor filene er plassert i filsystemet, deres navn, hvilke brukere som eier dem, deres rettigheter og mer. Denne informasjonen kalles metadata, da den beskriver annen data.
I Linux-filsystemer som ext4, samhandler inoder og katalogstrukturer for å etablere et rammeverk som håndterer all metadata for hver fil og katalog. Denne metadataen er tilgjengelig for systemkjernen, brukerapplikasjoner og Linux-verktøy som ls, stat og df.
Inoder og filsystemets kapasitet
Et filsystem trenger et stort antall inoder og katalogstrukturer. Hver fil og katalog krever en unik inode, og siden hver fil ligger i en katalog, trengs også en tilsvarende katalogstruktur. Disse katalogstrukturene omtales også som katalogoppføringer eller «dentries».
Hver inode er tildelt et inodenummer, som er unikt for et gitt filsystem. Selv om det samme inodenummeret kan finnes i flere filsystemer, vil kombinasjonen av filsystem-ID og inodenummer være unik i hele systemet, uavhengig av hvor mange filsystemer som er montert.
I Linux monterer man ikke selve harddisken eller partisjonen, men filsystemet som ligger på den. Dette betyr at et enkelt system kan ha flere filsystemer uten at det er åpenbart. Dette er typisk dersom systemet har flere harddisker eller partisjoner. Selv om disse benytter samme filsystemtype, for eksempel ext4, vil de likevel være separate filsystemer.
Alle inoder er lagret i en tabell. Ved å bruke et inodenummer kan filsystemet enkelt beregne posisjonen (offset) i inodetabellen hvor den spesifikke inoden befinner seg. Det er derfor «i» i inode står for indeks.
Inodenummeret er lagret som et 32-bits usignert heltall. Dette gir et teoretisk maksimalt antall på 2^32, eller 4.294.967.295 inoder, noe som er over 4 milliarder. Det praktiske antallet inoder i et ext4-filsystem bestemmes imidlertid når filsystemet opprettes. Standardforholdet er vanligvis én inode per 16 KB filsystemkapasitet. Katalogstrukturer opprettes dynamisk under bruk, etterhvert som filer og kataloger opprettes.
Kommandoen df med alternativet -i viser hvor mange inoder som finnes i et filsystem på systemet ditt.
For å se inodestatistikken for det første filsystemet på den første harddisken (sda1) kan vi skrive:
df -i /dev/sda1

Utdataene viser:
Filsystem: Filssystemet som rapporteres.
Inoder: Det totale antallet inoder i dette filsystemet.
IUsed: Antallet inoder som er i bruk.
IFree: Antallet ledige inoder.
IUse%: Prosentandelen av inoder som er i bruk.
Montert på: Monteringspunktet for dette filsystemet.
I dette tilfellet er 10% av inodene i bruk. Filer lagres på harddisken i diskblokker, og hver inode peker på diskblokkene som inneholder filens innhold. Hvis det er mange små filer, kan systemet gå tom for inoder før det går tom for diskplass. Dette er likevel uvanlig i moderne systemer.
Tidligere kunne epostservere som lagret epost som separate filer oppleve dette problemet. Ved å migrere til databasesystemer ble problemet løst. Det er lite sannsynlig at et gjennomsnittlig hjemmesystem går tom for inoder. I tillegg, i ext4-filsystemet, er det ikke mulig å legge til flere inoder uten å gjenopprette filsystemet.
For å sjekke størrelsen på diskblokkene i et filsystem, kan kommandoen blockdev benyttes med alternativet --getbsz:
sudo blockdev --getbsz /dev/sda

Diskblokkstørrelsen er 4096 byte.
La oss bruke -B-alternativet i kommandoen df til å angi blokkstørrelsen til 4096 byte, og så sjekke vanlig diskbruk:
df -B 4096 /dev/sda1

Utdataene viser:
Filsystem: Filsystemet som rapporteres.
4K-blokker: Det totale antallet 4 KB blokker i dette filsystemet.
Brukt: Antallet 4 KB blokker som er i bruk.
Tilgjengelig: Antallet ledige 4 KB blokker.
Bruk%: Prosentandelen av 4 KB blokker som er i bruk.
Montert på: Monteringspunktet for dette filsystemet.
I eksempelet over har lagring av filer (inkludert inoder og katalogstrukturer) brukt 28% av plassen og 10% av inodene. Systemet har dermed god margin.
Inode Metadata
Inodenummeret til en fil kan vises ved hjelp av kommandoen ls med alternativet -i:
ls -i geek.txt

Inodenummeret for denne filen er 1441801. Inoden inneholder metadata for denne filen samt pekere til diskblokkene hvor selve filen er lagret. Hvis filen er fragmentert eller veldig stor, kan noen av blokkene som inoden peker på inneholde pekere til andre blokker. Denne metoden løser begrensningen av at inoder har en fast størrelse og kun kan holde et begrenset antall pekere.
En nyere ordning benytter seg av «omfang» (extents), som registrerer start- og sluttblokk for sammenhengende blokker som lagrer filen. Dette er mer effektivt, spesielt for ufragmenterte filer, der bare startblokken og lengden trenger å lagres. Hvis filen er fragmentert, lagres start- og sluttblokk for hver del.
For å se om filsystemet bruker pekere til diskblokker eller omfang, kan vi undersøke en inode ved hjelp av kommandoen debugfs og dens -R (request) opsjon, kombinert med inodenummeret for filen, samt filsystemet der inoden er plassert.
En eksempelkommando ser slik ut:
sudo debugfs -R "stat" /dev/sda1

Kommandoen trekker ut inode-informasjon og presenterer den som nedenfor:
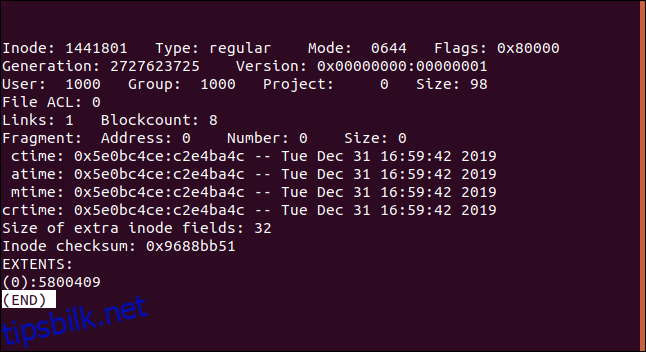
Informasjonen som vises er:
Inode: Nummeret på inoden som undersøkes.
Type: Filtypen (i dette tilfellet en vanlig fil).
Modus: Filrettighetene i oktal.
Flagg: Ulike egenskaper og funksjoner, der 0x80000 er flagget for «omfang» (extents).
Generasjon: Brukes i Network File System (NFS) for ekstern tilgang over nettverket. Inode- og generasjonsnummer brukes som en slags filhåndtak.
Versjon: Inode-versjonen.
Bruker: Eieren av filen.
Gruppe: Filens gruppe.
Prosjekt: Skal alltid være null.
Størrelse: Filstørrelsen.
Fil ACL: Access Control List for filen. Gir kontrollert tilgang til personer som ikke er i eiergruppen.
Lenker: Antall harde lenker til filen.
Blockcount: Mengden diskplass allokert til filen, angitt i 512-byte enheter. Filen i eksemplet er allokert 8 av disse, som er 4096 byte. Dermed opptar den 98-byte store filen en enkelt 4096-byte diskblokk.
Fragment: Viser at filen ikke er fragmentert. (Dette er et utdatert flagg.)
Ctime: Tidspunktet da filen ble opprettet.
Atime: Tidspunktet da filen sist ble åpnet.
Mtime: Tidspunktet da filen sist ble endret.
Crtime: Tidspunktet da filen ble opprettet.
Størrelse på ekstra inodefelt: Muligheten for å allokere en større inode på disken ved formatering. Verdien angir antall ekstra byte som inoden bruker. Denne ekstra plassen kan også brukes til nye funksjoner i kjernen eller til å lagre utvidede attributter.
Inode sjekksum: En sjekksum for inoden for å avdekke om den er ødelagt.
Omfang: Metadata om diskblokkbruk av filene, som indikerer start- og sluttblokk for hver del av en fragmentert fil. I eksemplet er det ett omfang, da filen passer i en diskblokk.
Hvor er filnavnet?
Selv om vi har mye informasjon om filen, mangler filnavnet. Det er her katalogstrukturen kommer inn. I likhet med filer har også kataloger en inode, men istedenfor å peke på diskblokker med fildata, peker de på diskblokker med katalogstrukturer.
Sammenlignet med en inode, inneholder en katalogstruktur en begrenset mengde informasjon om en fil. Den inneholder bare filens inodenummer, navn og lengden på navnet.
Inoden og katalogstrukturen inneholder all informasjonen som er nødvendig om en fil eller katalog. Katalogstrukturen er lagret i en katalogdiskblokk og gir filnavnet og inodenummeret. Inoden gir resten, inkludert tidsstempler, rettigheter og hvor fildataene er lokalisert i filsystemet.
Kataloginoder
Inodenummeret til en katalog kan sees like enkelt som for en fil.
I det følgende eksempelet bruker vi ls med alternativene -l (langt format), -i (inode) og -d (katalog) for å se på arbeidskatalogen:
ls -lid work/

Med -d-alternativet viser ls informasjon om selve katalogen, ikke dens innhold. Inoden for denne katalogen er 1443016.
For å gjøre det samme for hjemmekatalogen:
ls -lid ~

Inoden for hjemmekatalogen er 1447510, og arbeidskatalogen er i hjemmekatalogen. La oss se på innholdet i arbeidskatalogen. I stedet for -d (katalog) bruker vi -a (alle) for å vise skjulte oppføringer:
ls -lia work/
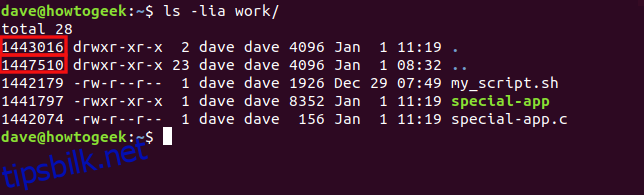
Med -a vises enkeltpunkt (.) og dobbeltpunkt (..). De representerer henholdsvis katalogen selv og dens overordnede katalog.
Enkeltpunktoppføringen har inodenummeret 1443016, det samme som for arbeidskatalogen. Dobbeltpunktoppføringen har samme inodenummer som hjemmekatalogen.
Dette er grunnen til at cd .. flytter deg opp et nivå i katalogtreet, og at ./ foran et program eller script-navn angir hvor programmet eller scriptet skal startes fra.
Inoder og lenker
For en korrekt og tilgjengelig fil i filsystemet kreves tre komponenter: filen, katalogstrukturen og inoden. Filen er selve dataene på disken, katalogstrukturen inneholder filens navn og inodenummer, mens inoden inneholder alle metadataene.
Symbolske lenker ser ut som filer, men er snarveier til eksisterende filer eller kataloger. La oss se hvordan dette fungerer.
La oss si at en katalog inneholder to filer, et script og en applikasjon:
Vi kan lage en myk lenke til script-filen med kommandoen ln og opsjonen -s:
ls -s my_script geek.sh

Vi har nå en lenke til my_script.sh som heter geek.sh. Vi kan se på de to script-filene ved hjelp av kommandoen ls:
ls -li *.sh
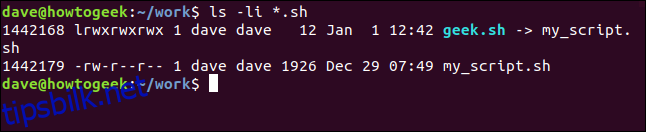
Oppføringen for geek.sh vises i blått. Det første tegnet er l for lenke og -> peker på my_script.sh, som indikerer at det er en lenke.
De to filene har forskjellige inodenumre, men tillatelsene for lenken geek.sh er mer liberale. Alle brukere har full tilgang.
Katalogstrukturen for geek.sh inneholder navnet på lenken og dens inode. Når lenken brukes, henvises det til inoden, akkurat som for en vanlig fil. Inoden peker på en diskblokk, men i stedet for filinnhold, inneholder diskblokken navnet på den opprinnelige filen. Filsystemet omdirigerer til den opprinnelige filen.
Vi sletter den opprinnelige filen og ser hva som skjer ved å skrive følgende for å se innholdet i geek.sh:
rm my_script.sh
cat geek.sh

Den symbolske lenken er ødelagt, og omdirigeringen mislykkes.
Vi lager en hard lenke til applikasjonsfilen ved å skrive:
ln special-app geek-app

For å se inodene:
ls -li
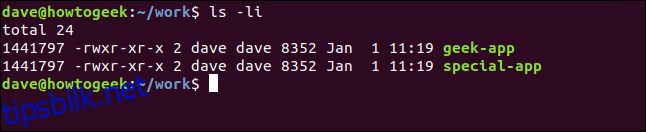
Begge filene ser ut som vanlige filer. geek-app er ikke merket som en lenke. I tillegg har geek-app samme tillatelser som originalen. Mer overraskende er det at begge applikasjonene har samme inodenummer: 1441797.
Katalogoppføringen for geek-app inneholder navnet geek-app og et inodenummer, som er det samme som originalen. Det betyr at vi har to oppføringer med forskjellige navn som peker til samme inode. Et ubegrenset antall oppføringer kan peke til samme inode.
Vi sjekker målfilen med stat:
stat special-app
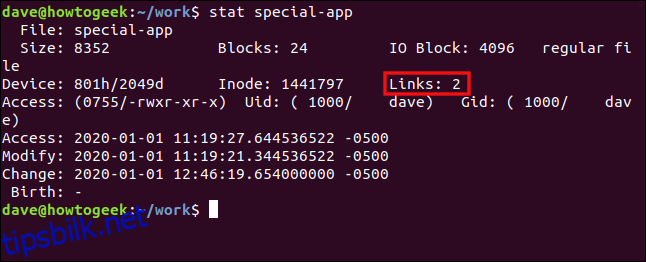
Vi ser at to harde lenker peker på filen. Dette lagres i inoden.
I følgende eksempel sletter vi den opprinnelige filen og prøver å kjøre lenken med et hemmelig passord:
rm special-app
./geek-app correcthorsebatterystaple

Overraskende nok kjører applikasjonen som forventet. Når en fil slettes, er inoden ledig for gjenbruk. Katalogstrukturen merkes med et inodenummer på null, og diskblokkene er tilgjengelige for en annen fil.
Hvis antallet harde lenker til inoden er større enn én, reduseres antallet med én, og inodenummeret i katalogstrukturen til den slettede filen settes til null. Filinnholdet og inoden er fremdeles tilgjengelig for de eksisterende harde lenkene.
Vi bruker stat på geek-app:
stat geek-app
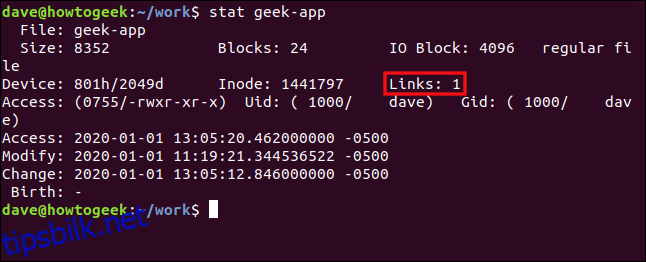
Detaljene er hentet fra samme inode (1441797) som den forrige stat-kommandoen. Antallet lenker er redusert med én.
Hvis vi sletter geek-app, vil filen slettes. Filsystemet frigjør inoden og merker katalogstrukturen med en inode på null. Ny data kan så skrive over lagringen på disken.
Inode Overhead
Dette er et ryddig system, men det medfører ekstra arbeid. For å lese en fil, må filsystemet:
- Finne riktig katalogstruktur
- Lese inodenummeret
- Finne riktig inode
- Lese inodeinformasjon
- Følge inode-lenkene eller omfangene til diskblokkene
- Lese fildataene
Ytterligere hopping er nødvendig dersom dataene ikke er sammenhengende.
Tenk på arbeidet som kreves for at kommandoen ls skal utføre en langformatfilliste over mange filer. Det er mye frem og tilbake for å få informasjonen som trengs for å generere utdata.
For å øke hastigheten på filsystemtilgang, forsøker Linux å benytte seg av forhåndsbufring av filer så mye som mulig. Dette hjelper mye, men til tider kan overheaden bli merkbar.
Nå vet du hvorfor.