Denne artikkelen presenterer og forklarer noen av de mest verdifulle Python-bibliotekene for forskere innen dataanalyse og team som arbeider med maskinlæring.
Python er et foretrukket programmeringsspråk i disse feltene, hovedsakelig på grunn av det brede utvalget av biblioteker som er tilgjengelige.
Disse bibliotekene er essensielle for datahåndtering, inkludert datainnlesing og -utskriving, analyse og manipulasjon, som er kritiske oppgaver for dataforskere og maskinlæringseksperter.
Hva er egentlig Python-biblioteker?
Et Python-bibliotek er en omfattende samling av forhåndsdefinerte moduler. Disse modulene inneholder ferdigskrevet kode, inkludert klasser og metoder, som gjør det unødvendig for utviklere å skrive kode fra bunnen av.
Python sin betydning innen datavitenskap og maskinlæring
Python tilbyr noen av de beste verktøyene for eksperter innen maskinlæring og datavitenskap.
Språkets enkle syntaks bidrar til effektiv implementering av komplekse maskinlæringsalgoritmer, og den korte læringskurven gjør det enkelt å forstå.
Python støtter også rask utvikling av prototyper og grundig testing av applikasjoner.
Det store og aktive fellesskapet rundt Python er en stor fordel for dataforskere, som lett kan finne hjelp og løsninger på sine spørsmål.
Hvor nyttige er egentlig Python-bibliotekene?
Python-biblioteker er avgjørende for utvikling av applikasjoner og modeller innen maskinlæring og datavitenskap.
Disse bibliotekene muliggjør gjenbruk av kode, slik at utviklere kan importere relevante funksjoner og unngå å skrive kode for vanlige oppgaver på nytt.
Python-biblioteker brukt i maskinlæring og datavitenskap
Dataforskere anbefaler en rekke Python-biblioteker som er viktige å kjenne til. Avhengig av prosjektets behov, bruker maskinlærings- og datavitenskapseksperter ulike Python-biblioteker for modelldistribusjon, datautvinning, databehandling og datavisualisering.
Denne artikkelen tar for seg noen av de mest brukte Python-bibliotekene innen datavitenskap og maskinlæring.
La oss se nærmere på disse:
NumPy
NumPy, forkortelse for Numerical Python, er bygget med optimalisert C-kode. Dette biblioteket er svært populært blant dataforskere på grunn av sin kapasitet for matematiske og vitenskapelige beregninger.
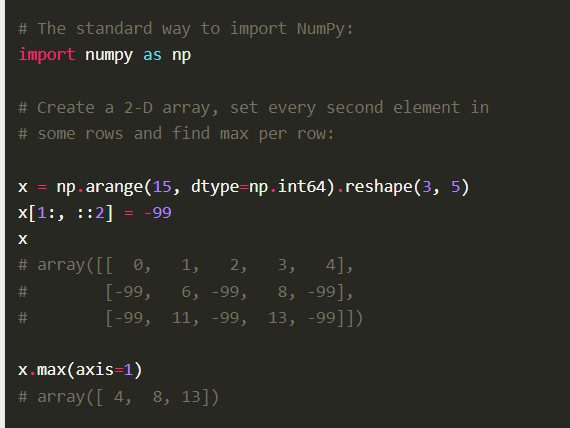
Nøkkelfunksjoner:
NumPy tilbyr også funksjoner for vektorisering av matematiske operasjoner, indeksering, og implementering av matriser.
Pandas
Pandas er et velkjent bibliotek innen maskinlæring som tilbyr avanserte datastrukturer og verktøy for å analysere store datasett på en effektiv og brukervennlig måte. Med bare noen få kommandoer kan komplekse operasjoner med data utføres.
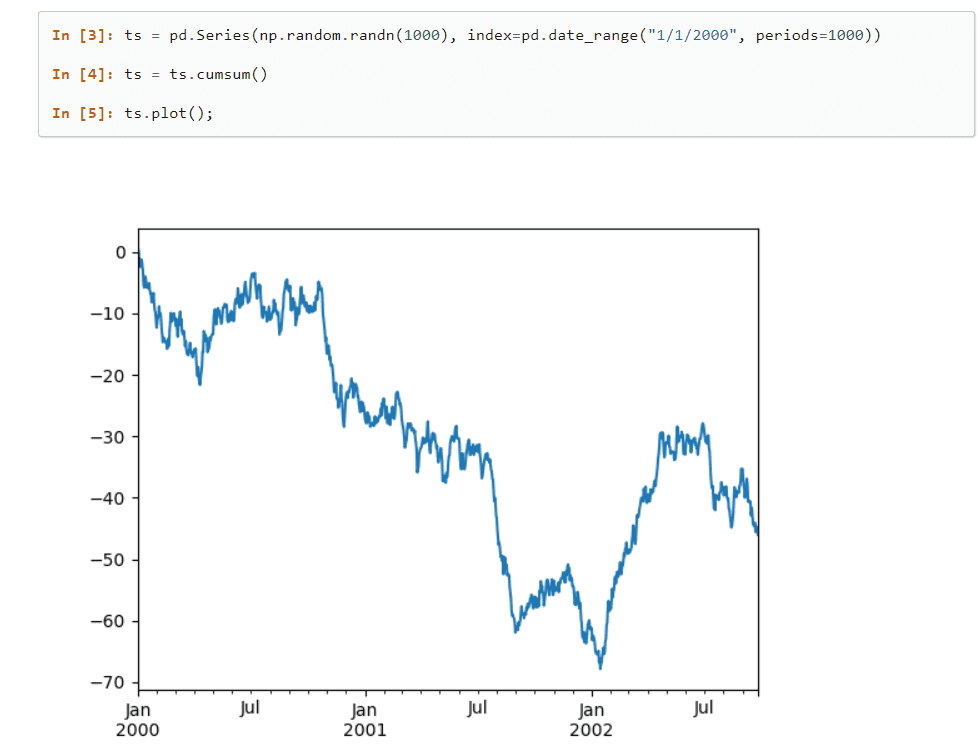
Biblioteket tilbyr innebygde metoder for å gruppere, indeksere, hente, dele, omstrukturere og filtrere data før de settes inn i enkelt- eller flerdimensjonale tabeller.
Hovedfunksjoner i Pandas:
Biblioteket er kjent for sin effektive dataanalysefunksjonalitet og høye fleksibilitet.
Matplotlib
Matplotlib er et 2D grafisk Python-bibliotek som enkelt kan håndtere data fra en rekke kilder. Det genererer statiske, animerte og interaktive visualiseringer som brukere kan zoome inn på, noe som gjør det effektivt for å lage diagrammer og grafer. Det tillater også tilpasning av layout og visuell stil.
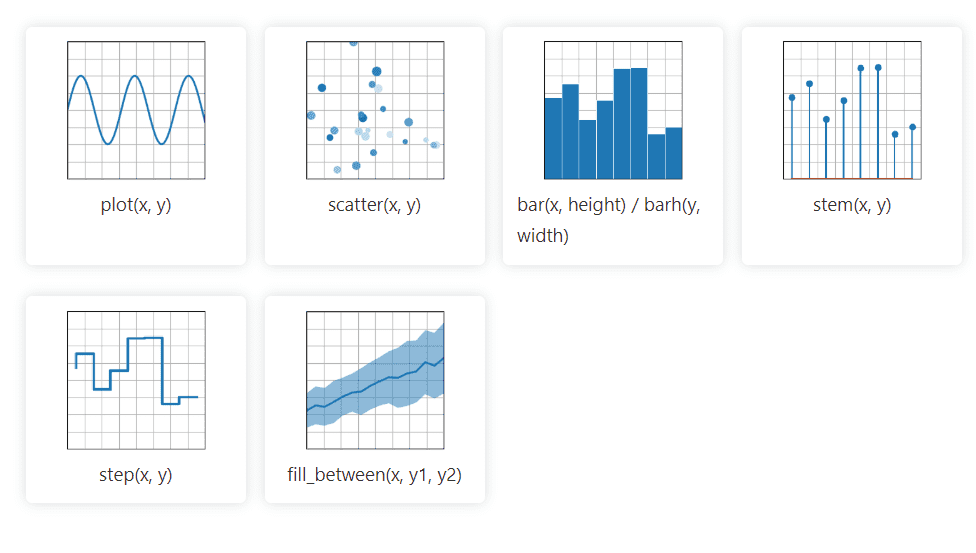
Dokumentasjonen er åpen kildekode og tilbyr en omfattende samling av verktøy som kreves for implementering.
Matplotlib importerer hjelpeklasser for å manipulere tidsseriedata, som år, måned, dag og uke.
Scikit-learn
Scikit-learn er det ideelle biblioteket for å jobbe med komplekse data, og brukes mye av maskinlæringseksperter. Dette biblioteket er ofte brukt sammen med NumPy, SciPy og Matplotlib. Det tilbyr både overvåkede og uovervåkede læringsalgoritmer som kan brukes for produksjonsapplikasjoner.

Funksjoner i Scikit-learn:
Scikit-learn er effektivt for funksjonsekstraksjon fra tekst- og bildedatasett. I tillegg kan man evaluere nøyaktigheten til overvåkede modeller på ukjente data. De mange algoritmene som er tilgjengelige muliggjør datautvinning og andre maskinlæringsoppgaver.
SciPy
SciPy (Scientific Python) er et maskinlæringsbibliotek som tilbyr moduler for matematiske funksjoner og algoritmer. Disse algoritmene brukes til å løse algebraiske ligninger, interpolasjon, optimalisering, statistikk og integrasjon.
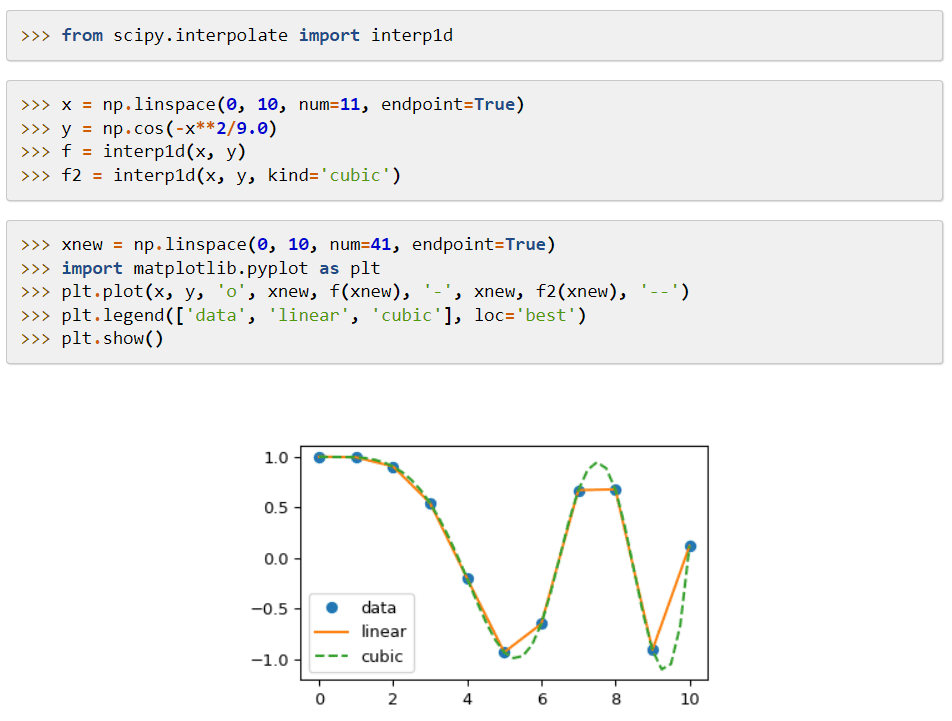
Hovedfunksjonen er å utvide NumPy med verktøy for å løse matematiske funksjoner, og tilby datastrukturer som sparse matriser.
SciPy bruker kommandoer og klasser på høyt nivå for å manipulere og visualisere data. Databehandlings- og prototypesystemene gjør det til et enda mer effektivt verktøy.
SciPys syntaks på høyt nivå gjør det enkelt for programmerere på alle nivåer å bruke biblioteket.
SciPys eneste begrensning er at det fokuserer kun på numeriske objekter og algoritmer, og tilbyr derfor ingen plottefunksjoner.
PyTorch
Dette allsidige maskinlæringsbiblioteket implementerer tensorberegninger med GPU-akselerasjon, skaper dynamiske beregningsgrafer og muliggjør automatisk gradientberegning. PyTorch er bygget på Torch-biblioteket, et åpen kildekode maskinlæringsbibliotek utviklet i C.

Nøkkelfunksjoner inkluderer:
PyTorch kan brukes til å utvikle NLP-applikasjoner.
Keras
Keras er et åpen kildekode maskinlæringsbibliotek for Python som brukes til å eksperimentere med dype nevrale nettverk.
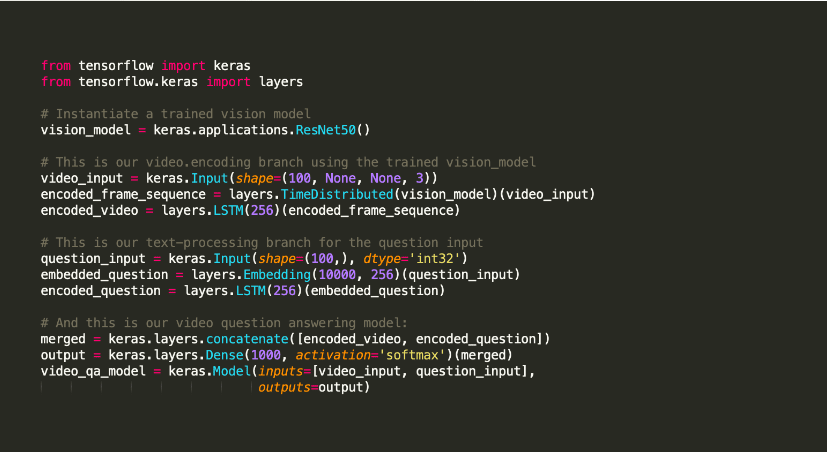
Keras er kjent for å tilby verktøy som støtter oppgaver som modellkompilering og grafvisualiseringer. Det bruker TensorFlow for backend, men kan også bruke Theano eller CNTK. Denne backend-infrastrukturen hjelper den med å lage beregningsgrafer som brukes for å implementere operasjoner.
Nøkkelfunksjoner i biblioteket:
Keras brukes blant annet til å bygge nevrale nettverk som lag og mål, samt for å jobbe med bilder og tekstdata.
Seaborn
Seaborn er et annet verdifullt verktøy for statistisk datavisualisering.
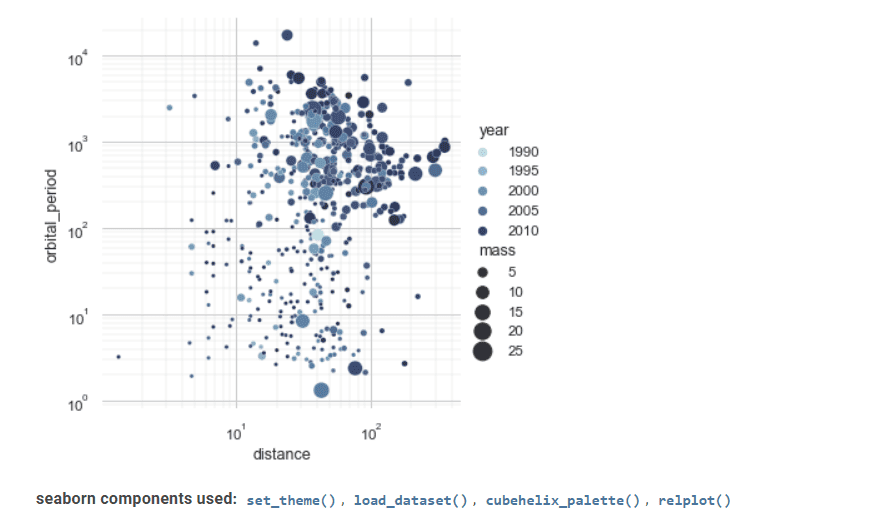
Det avanserte grensesnittet kan implementere attraktive og informative statistiske grafer.
Plotly
Plotly er et 3D nettbasert visualiseringsverktøy bygget på Plotly JS-biblioteket. Det har bred støtte for ulike diagramtyper som linjediagrammer, spredningsplott og boksplott.
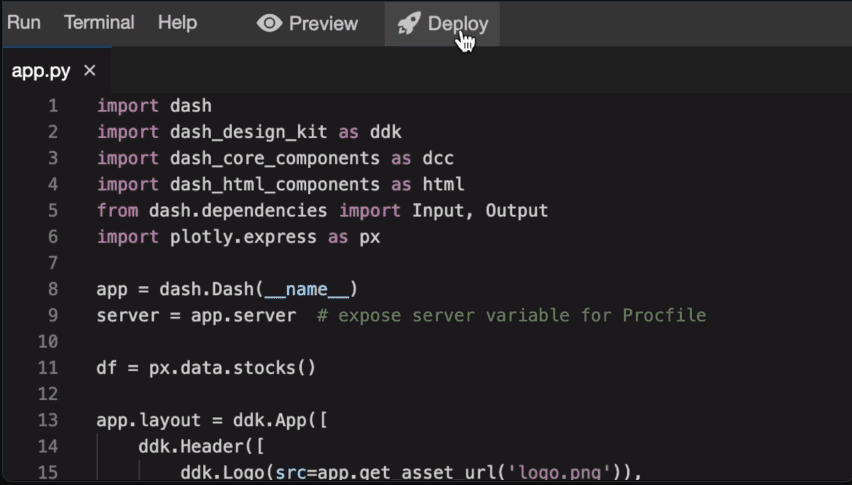
Plotly brukes blant annet til å lage nettbaserte datavisualiseringer i Jupyter-notatbøker.
Plotly er egnet for visualisering fordi det kan fremheve avvik eller abnormiteter i grafen med sveveverktøyet. Man kan også tilpasse grafene etter egne preferanser.
En ulempe med Plotly er at dokumentasjonen kan være utdatert, noe som kan gjøre det vanskelig å bruke den som veiledning. I tillegg har det en rekke verktøy som kan være utfordrende å lære seg.
Funksjoner i Plotly:
SimpleITK
SimpleITK er et bildeanalysebibliotek som tilbyr et grensesnitt til Insight Toolkit (ITK). Det er basert på C++ og er åpen kildekode.
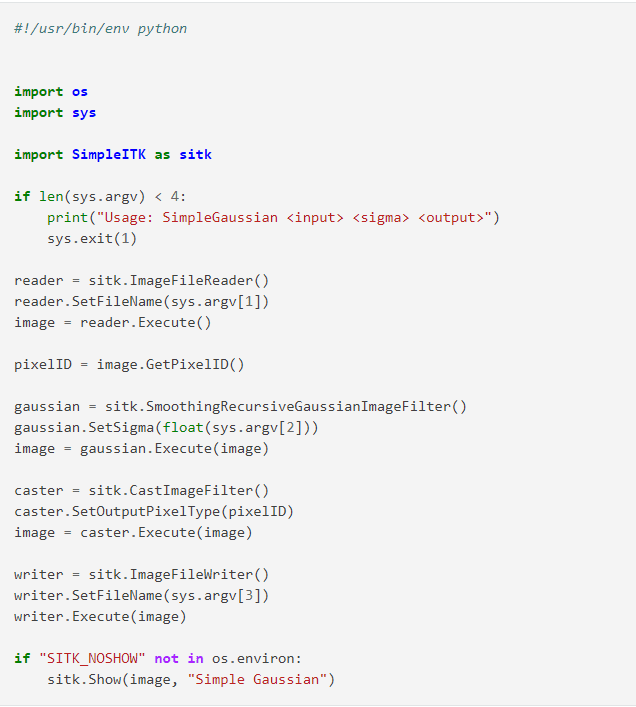
Funksjoner i SimpleITK-biblioteket:
Det forenklede grensesnittet er tilgjengelig på ulike programmeringsspråk som R, C#, C++, Java og Python.
Statsmodels
Statsmodels estimerer statistiske modeller, implementerer statistiske tester og utforsker statistiske data ved hjelp av klasser og funksjoner.
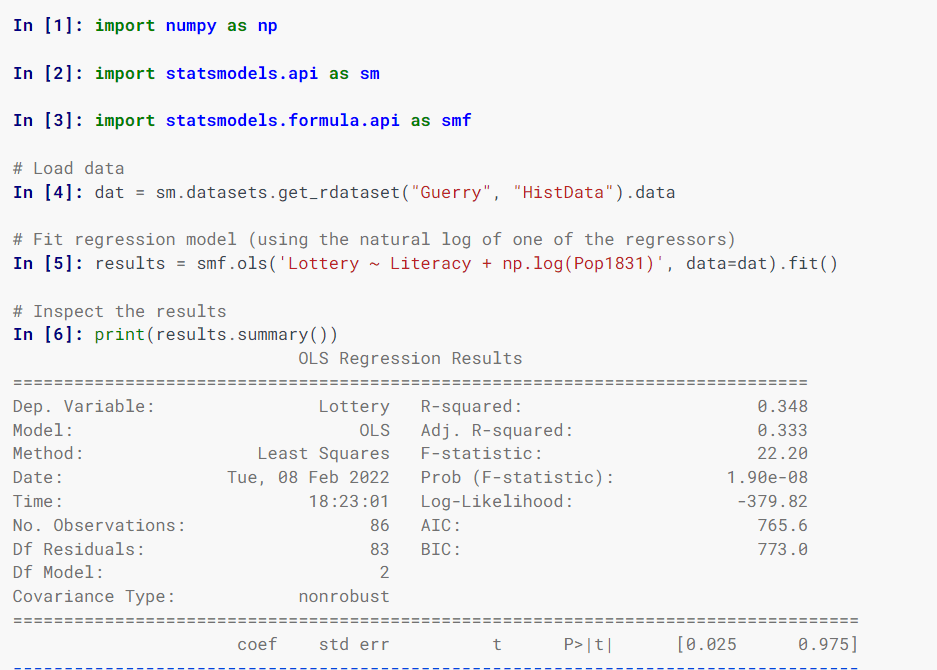
Modeller spesifiseres ved hjelp av R-stil formler, NumPy-matriser og Pandas-datarammer.
Scrapy
Denne åpen kildekode-pakken er et foretrukket verktøy for å hente (skrape) og gjennomsøke data fra nettsteder. Den er asynkron og derfor relativt rask. Scrapy har en arkitektur og funksjoner som gjør den effektiv.
En ulempe er at installasjonen varierer for ulike operativsystemer. Videre kan den ikke brukes på nettsteder bygget med JavaScript, og den fungerer kun med Python 2.7 eller nyere versjoner.
Dataforskere bruker Scrapy i datautvinning og automatisert testing.
Funksjoner:
Pillow
Pillow er et Python-bildebibliotek som brukes til å manipulere og behandle bilder.
Det legger til funksjoner for bildebehandling i Python-tolken, støtter ulike filformater og tilbyr en god intern representasjon.
Data som er lagret i grunnleggende filformater kan enkelt nås takket være Pillow.
Avslutning
Dette avslutter vår gjennomgang av noen av de beste Python-bibliotekene for dataforskere og maskinlæringseksperter.
Som denne artikkelen viser, har Python et stort utvalg av nyttige pakker for maskinlæring og datavitenskap. Python har også biblioteker som kan brukes i andre felt.
Det kan være nyttig å vite mer om noen av de beste notatbøkene for datavitenskap.
Lykke til med læringen!