Prometheus fremstår som et åpen kildekode system for overvåking, med fokus på metrikkdata. Systemet innhenter informasjon fra ulike tjenester og servere ved hjelp av HTTP-forespørsler mot definerte metrikkpunkter. De innsamlede dataene lagres i en tidsbasert database, hvor de er tilgjengelige for analyse og varsling.
Hvorfor er overvåking viktig?
- Overvåking muliggjør tidlig varsling om feil, ideelt sett før de oppstår, slik at relevante personer kan ta affære.
- Den gir et grunnlag for analyse, feilsøking og løsning av problemer.
- Overvåking hjelper med å identifisere trender og endringer over tid, som for eksempel antall aktive sesjoner. Denne informasjonen er verdifull for designbeslutninger og kapasitetsplanlegging.
Overvåking er ofte knyttet til spesifikke hendelser. Dette kan inkludere mottak av HTTP-forespørsler, sending av svar, disklesing eller brukerpålogging. En helhetlig overvåkingsstrategi omfatter profilering, logging, sporing, beregninger, varsling og visualisering.
Blackbox versus Whitebox-overvåking
Overvåking kan grovt deles inn i to hovedkategorier:
Blackbox-overvåking
Blackbox-overvåking fokuserer på å observere applikasjoner eller servere fra utsiden. Dette gir et begrenset innsyn i systemets funksjonalitet.
Whitebox-overvåking
Whitebox-overvåking, derimot, innebærer å overvåke de interne komponentene i en tjeneste. Dette gir detaljert innsikt i tilstanden og ytelsen til de interne elementene.
De fire fundamentale signalene
Ifølge Google, hvis du skal måle et begrenset antall beregninger i et brukersystem, bør du fokusere på de fire følgende signalene:
#1. Forsinkelse
Tidsforbruket for å fullføre en forespørsel, uavhengig av om den var vellykket eller mislykket. Det er viktig å registrere både vellykkede og mislykkede forespørsler.
#2. Trafikk
Dette måler belastningen på systemet ditt. For en webapplikasjon kan dette være antall HTTP-forespørsler per sekund.
#3. Feil
Frekvensen av mislykkede forespørsler.
#4. Metning
Dette viser hvor fullt systemet ditt er utnyttet. Økt forsinkelse indikerer ofte metning. Mange systemer opplever ytelsesforringelse lenge før de når 100% kapasitet.
Prometheus» metrikktyper
Prometheus bruker fire hovedtyper metrikk:
#1. Teller
En teller øker kontinuerlig og kan kun tilbakestilles til null. Hvis en skraping feiler, går dataene tapt for det tidsrommet, men den kumulative økningen vil være tilgjengelig ved neste lesing. Eksempler inkluderer totalt antall HTTP-forespørsler og antall unntak.
#2. Måler
En måler gir et øyeblikksbilde av en verdi på et bestemt tidspunkt. Den kan både øke og redusere. Ved feil i datahenting går dataene for den perioden tapt, men neste henting kan vise en annen verdi, som diskplass eller minnebruk.
#3. Histogram
Histogrammer lagrer observasjoner i forhåndsdefinerte bøtter. De brukes til å måle responstid eller størrelsen på svar. I stedet for å lagre hver enkelt varighet, lagres frekvensen av forespørsler som faller innenfor bestemte bøtter. For eksempel, for en HTTP-forespørsel kan bøttene være satt til 1 ms, 10 ms og 25 ms.
#4. Sammendrag
I likhet med histogrammer, samler sammendrag informasjon om varighet eller responsstørrelse. De gir en total telling av observasjoner og summen av alle observerte verdier, som gjør det mulig å beregne gjennomsnittet av de observerte verdiene. For eksempel, hvis tre forespørsler tok henholdsvis 2, 3 og 4 sekunder i løpet av ett minutt, vil summen være 9 og antallet være 3, som gir en gjennomsnittlig latens på 3 sekunder.
Komponenter i Prometheus» økosystem
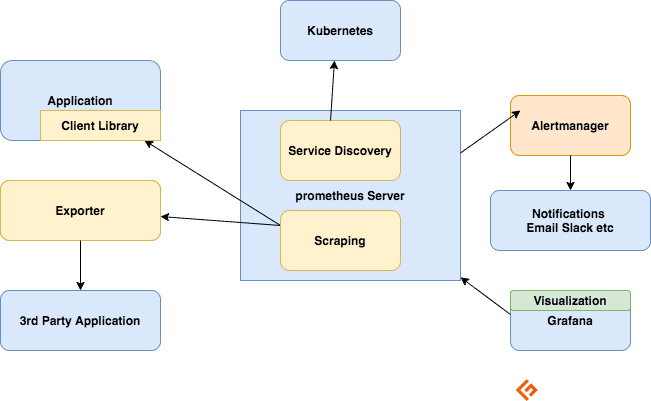
Prometheus-serveren
Denne samler inn metrikk, lagrer dem, gjør dem søkbare, og sender varsler basert på innsamlede data.
Skraping
Prometheus benytter en pull-basert tilnærming. For å hente metrikkdata, sender Prometheus en HTTP-forespørsel, kjent som en skrap. Skrapinger sendes til de definerte målene, basert på konfigurasjonen.
Hvert mål, som kan være statisk definert eller dynamisk oppdaget, skrapes med jevne mellomrom (skrapeintervall). Hver skrap henter data fra `/metrics` HTTP-endepunktet og oppdaterer den interne tidsbaserte databasen med de nyeste verdiene.
Det finnes flere alternativer for tidsbaserte databaser i overvåkingsløsninger som kan være verdt å utforske.
Klientbiblioteker
For å overvåke en tjeneste må instrumentering legges til i koden. Klientbiblioteker er tilgjengelige for de fleste populære språk og plattformer. Med bare noen få linjer kode kan du begynne å publisere metrikk. Dette kalles direkte instrumentering. Disse bibliotekene lar deg definere interne metrikk og publisere dem via et HTTP-endepunkt. Når Prometheus skraper dette endepunktet, sendes metrikkdataene til serveren.
Prometheus tilbyr offisielle klientbiblioteker for Go, Java, Python og Ruby, samt flere fellesskapsbygde biblioteker for C, PHP, Node.js, C#/.NET og andre språk.
Eksportører
Mange applikasjoner publiserer metrikk i formater som ikke er kompatible med Prometheus. For disse applikasjonene, eller applikasjoner du ikke har tilgang til koden for, kan ikke direkte instrumentering brukes. Eksempler inkluderer MySQL, Kafka, JMX, HAProxy og NGINX servere. I disse tilfellene brukes eksportører.
En eksportør fungerer som en proxy mellom applikasjonen og Prometheus. Den mottar forespørsler fra Prometheus, samler inn data fra applikasjonens logger og transformerer den til et kompatibelt format før den returneres til Prometheus-serveren.
Noen populære eksportører inkluderer:
- Windows – for Windows-servermetrikk
- Node – for Linux-servermetrikk
- Blackbox – for måling av DNS- og nettstedsytelse
- JMX – for metrikk fra Java-baserte applikasjoner
Når applikasjonene er instrumentert, eller eksportørene er satt opp, må du informere Prometheus om hvor disse enhetene befinner seg. Dette kan gjøres ved hjelp av en statisk konfigurasjon. I dynamiske miljøer er imidlertid tjenesteoppdagelse en mer egnet tilnærming.
Varsler
Varslingsprosessen i Prometheus består av to hoveddeler:
Varslingsregler sender varsler til Alertmanager.
Alertmanager håndterer disse varslene. Den sender ut varsler via en rekke integrasjoner som e-post, Slack, Hipchat og PagerDuty. Alertmanager kan også dempe eller aggregere varsler for å redusere antall meldinger.
Her er en veiledning for overvåking av en Linux-server ved hjelp av Prometheus og dashbord.
Visualisering med Dashboards
Prometheus tilbyr et sett med APIer som bruker PromQL-spørringer for å generere rådata som kan brukes til visualisering.
Selv om Prometheus har en innebygd uttrykksnettleser for enkle spørringer, er Grafana det mest anvendelige verktøyet. Grafana er fullt integrert med Prometheus og kan lage et bredt spekter av dashboards.
Du må konfigurere Prometheus som datakilde i Grafana.
Dashboards kan legges til ved å:
- Importere fellesskapsbaserte dashboards
- Bygge egne dashboards
- Bruke forhåndsdefinerte dashboards
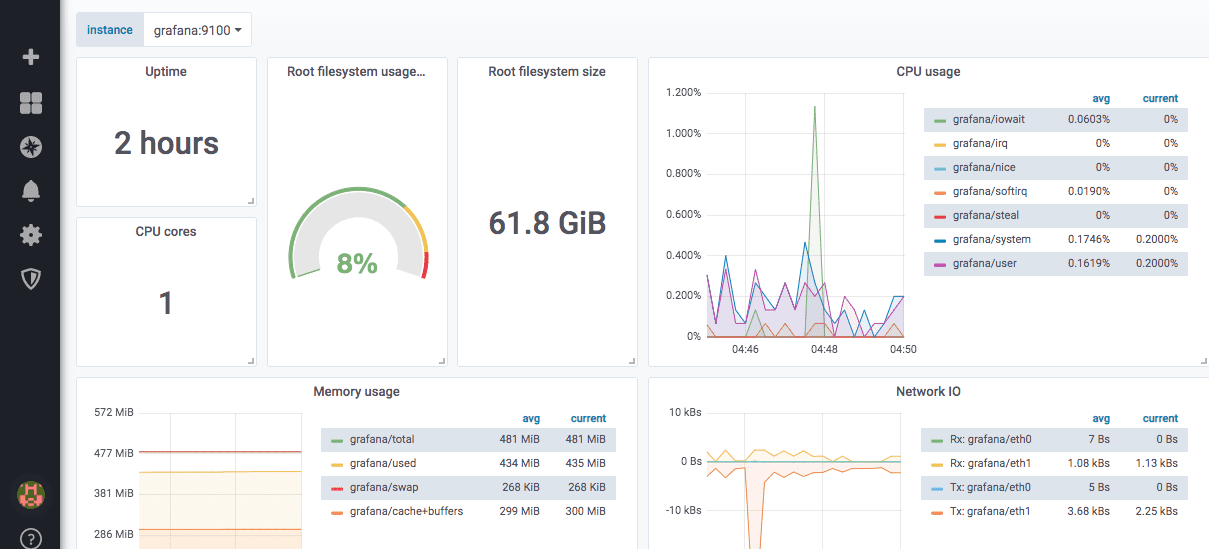
Slik ser et forhåndsdefinert dashbord for nodeeksportør ut:
Grafana har også en WorldPing-modul for overvåking av nettsteds- og DNS-ytelse globalt.
Oppsummering
Prometheus har relativt få krav til drift. Det er enkelt å kjøre siden det er en enkelt binærfil med en konfigurasjonsfil. Systemet er i stand til å håndtere tusenvis av mål og millioner av målinger per sekund. Prometheus er designet for å overvåke systemets helse og oppførsel.
Grafana er et ideelt visualiseringsverktøy for metrikk og er sømløst integrert med Prometheus.