Generative motstridende nettverk, ofte forkortet GAN, representerer en banebrytende teknologi med stort potensial på tvers av en rekke bruksområder. Fra å gjenopplive gamle fotografier og forbedre stemmekvaliteten til å muliggjøre ulike applikasjoner innen medisin og andre bransjer, er GAN-er i ferd med å transformere mange sektorer.
Denne avanserte teknologien kan være avgjørende i utformingen av produkter og tjenester. Den kan også bidra til å forbedre bildekvaliteten, og dermed bevare verdifulle minner.
Selv om GAN-er regnes som et fremskritt av mange, uttrykker enkelte bekymring for potensielle implikasjoner.
Men hva er egentlig denne teknologien, og hvordan fungerer den?
I denne artikkelen vil vi se nærmere på hva et GAN er, hvordan det fungerer, og hvilke bruksområder det har.
La oss sette i gang!
Hva er et generativt motstandsnettverk?
Et generativt motstandsnettverk (GAN) er et rammeverk for maskinlæring som involverer to nevrale nettverk i en konkurransesituasjon. Målet er å produsere mer nøyaktige prediksjoner, for eksempel bilder, original musikk, tegninger og lignende.
GAN-er ble utviklet i 2014 av informatikk- og ingeniørekspert, Ian Goodfellow, og hans medarbeidere. Disse unike, dyptgående nevrale nettverkene er i stand til å generere nye data som ligner på de dataene de er trent på. De opererer i et nullsumspill, der den ene agenten taper mens den andre vinner.
Opprinnelig ble GAN-er foreslått som en generativ modell for maskinlæring, primært for uovervåket læring. Likevel er GAN-er også anvendelige i fullt overvåket læring, semi-overvåket læring og forsterkende læring.
De to konkurrerende komponentene i et GAN er:
Generatoren: Et konvolusjonelt nevralt nettverk som produserer kunstige data som etterligner faktiske data.
Diskriminatoren: Et dekonvolusjonelt nevralt nettverk som identifiserer de kunstig genererte resultatene.
Nøkkelkonsepter
For å oppnå en grundigere forståelse av GAN-konseptet, la oss se på noen viktige tilknyttede begreper.
Maskinlæring (ML)

Maskinlæring er en gren av kunstig intelligens (AI) som fokuserer på utvikling av modeller som bruker data for å forbedre ytelse og nøyaktighet i oppgaver, beslutningstaking eller forutsigelser.
ML-algoritmer bygger modeller basert på treningsdata og forbedres gjennom kontinuerlig læring. De brukes i ulike områder, inkludert datasyn, automatisert beslutningstaking, e-postfiltrering, medisin, bank, datakvalitet, cybersikkerhet, talegjenkjenning og anbefalingssystemer.
Diskriminerende modell

I dyp læring og maskinlæring fungerer den diskriminerende modellen som en klassifiserer for å skille mellom ulike nivåer eller to klasser.
Et eksempel er å skille mellom ulike typer frukt eller dyr.
Generativ modell
I generative modeller undersøkes tilfeldige utvalg for å skape nye, realistiske bilder. Modellen lærer fra virkelige bilder av gjenstander eller levende vesener for å generere sine egne, realistiske kopier. Det finnes to typer av disse modellene:
Variasjonelle autokodere: De benytter kodere og dekodere som er separate nevrale nettverk. Et realistisk bilde går gjennom en koder som representerer bildet som vektorer i et latent rom. Deretter bruker en dekoder disse tolkningene for å produsere realistiske kopier. I utgangspunktet kan bildekvaliteten være lav, men den vil forbedres når dekoderen er fullt funksjonell, og koderen kan utelates.
Generative motstridende nettverk (GAN): Som diskutert tidligere, er et GAN et dypt nevralt nettverk som kan generere nye, lignende data basert på den innmatningen det får. Dette er en form for uovervåket maskinlæring, en type maskinlæring vi skal se nærmere på nedenfor.
Veiledet læring
I veiledet læring trenes en maskin ved hjelp av data som allerede er merket. Det betyr at noen data vil være merket med det korrekte svaret. Maskinen får noen data eller eksempler som gjør det mulig for den overvåkede læringsalgoritmen å analysere treningsdataene og produsere et nøyaktig resultat basert på de merkede dataene.
Uovervåket læring
Uovervåket læring innebærer å trene en maskin ved hjelp av data som ikke er merket eller klassifisert. Dette gjør at maskinlæringsalgoritmen kan jobbe med dataene uten veiledning. I denne typen læring er maskinens oppgave å kategorisere usorterte data basert på mønstre, likheter og forskjeller uten tidligere dataopplæring.
GAN-er er knyttet til uovervåket læring i ML. De har to modeller som automatisk kan oppdage og lære mønstre fra inndata. Disse to modellene er generator og diskriminator.
La oss se nærmere på disse.
Komponenter i et GAN
Begrepet «motstridende» i GAN viser til at det er to deler – en generator og en diskriminator – som konkurrerer mot hverandre. Hensikten er å fange opp, analysere og gjenskape variasjoner i et datasett. La oss undersøke disse to komponentene i et GAN nærmere.
Generator
En generator er et nevralt nettverk som kan lære å generere falske datapunkter, som bilder og lyd, som ser realistiske ut. Den brukes i treningsprosessen og forbedres kontinuerlig gjennom læring.
Dataene generert av generatoren brukes som et negativt eksempel for den andre delen – diskriminatoren – som vi skal se på neste gang. Generatoren tar en tilfeldig vektor med fast lengde som inndata for å produsere et utvalg. Målet er å presentere resultatet for diskriminatoren for å få den til å klassifisere utdataene som ekte eller falske.
Generatoren er trent med følgende komponenter:
- Støyende inndatavektorer
- Et generatornettverk som transformerer en tilfeldig inndata til en dataforekomst
- Et diskriminatornettverk som klassifiserer de genererte dataene
- Et generatortap for å straffe generatoren når den ikke klarer å lure diskriminatoren
Generatoren fungerer som en tyv som replikerer og skaper realistiske data for å lure diskriminatoren. Målet er å omgå flere kontroller. Selv om generatoren kan mislykkes i de innledende stadiene, forbedres den kontinuerlig til den genererer realistiske data av høy kvalitet og kan unngå testene. Når denne evnen er oppnådd, kan generatoren brukes alene uten å trenge en separat diskriminator.
Diskriminator

En diskriminator er også et nevralt nettverk som kan skille mellom falske og ekte bilder eller andre typer data. Akkurat som generatoren spiller den en viktig rolle i treningsfasen.
Den fungerer som politiet som fanger tyven (falske data fra generatoren). Målet er å oppdage falske bilder og avvik i en dataforekomst.
Som nevnt tidligere, lærer generatoren og forbedres kontinuerlig til den når et punkt der den kan produsere bilder av høy kvalitet som ikke trenger en diskriminator. Når data av høy kvalitet fra generatoren sendes gjennom diskriminatoren, kan den ikke lenger skille mellom et ekte og falskt bilde. Dermed kan du bruke generatoren alene.
Hvordan fungerer et GAN?
Et generativt motstridende nettverk (GAN) involverer tre elementer:
- En generativ modell som beskriver hvordan data genereres.
- En motstridende setting der en modell trenes.
- Dype nevrale nettverk som AI-algoritmer for trening.
GANs to nevrale nettverk – generator og diskriminator – spiller et motstridende spill. Generatoren tar inndata, for eksempel lydfiler, bilder osv., for å generere en lignende dataforekomst, mens diskriminatoren validerer ektheten til denne forekomsten. Diskriminatoren avgjør om dataforekomsten er ekte eller ikke.
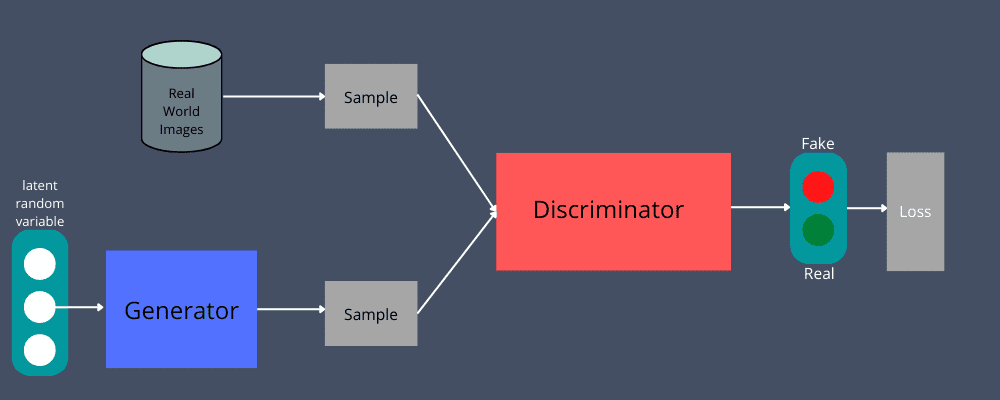
For eksempel vil du bekrefte om et gitt bilde er ekte eller falskt. Du kan bruke manuelt genererte data som inndata til generatoren. Generatoren vil lage nye, replikerte bilder som utdata.
I denne prosessen vil generatoren sørge for at alle bildene den genererer blir ansett som autentiske, selv om de er falske. Målet er å skape akseptable resultater, slik at den kan «lyve» uten å bli tatt.
Disse utdataene sendes deretter til diskriminatoren sammen med et sett med bilder fra virkelige data. Diskriminatoren vil avgjøre om bildene er autentiske eller ikke. Den motvirker generatorens innsats uansett hvor hardt den prøver å etterligne; diskriminatoren vil skille fakta fra forfalskning.
Diskriminatoren vil analysere både falske og ekte data for å returnere en sannsynlighet på 0 eller 1. Her representerer 1 autentisitet og 0 representerer falsk.
Det er to tilbakemeldingssløyfer i denne prosessen:
- Generatoren er koblet til en tilbakemeldingssløyfe med en diskriminator
- Diskriminatoren er koblet til en annen tilbakemeldingssløyfe med et sett med ekte bilder
GAN-trening fungerer fordi både generator og diskriminator er i trening. Generatoren lærer kontinuerlig ved å sende falske inndata, mens diskriminatoren lærer å forbedre sin evne til å oppdage falske data. Begge komponentene er dynamiske.
Diskriminatoren er et konvolusjonsnettverk som kan kategorisere bilder som leveres til det. Den fungerer som en binomisk klassifikator for å merke bilder som falske eller ekte.
På den annen side fungerer generatoren som et omvendt konvolusjonsnettverk som tar tilfeldige datautvalg for å produsere bilder. Diskriminatoren verifiserer data ved hjelp av nedsamplingsteknikker som maksimal pooling.
Begge nettverkene prøver å optimalisere en motstridende og annerledes taps- eller objektivfunksjon i et konkurrerende spill. Deres tap gjør at de utfordrer hverandre enda mer.
Typer GAN-er

Generative motstridende nettverk finnes i ulike typer basert på implementering. Her er de viktigste GAN-typene som brukes aktivt:
- Betinget GAN (CGAN): Dette er en teknikk for dyp læring som involverer spesifikke betingede parametere for å skille mellom ekte og falske data. Den inkluderer også en ekstra parameter, «y», i generatorfasen for å produsere tilsvarende data. Etiketter legges også til denne inndataen og sendes til diskriminatoren for å hjelpe den med å verifisere om dataene er autentiske eller falske.
- Vanilla GAN: En enkel GAN-type der diskriminatoren og generatoren er enklere og flerlags perceptroner. Algoritmene er enkle og optimaliserer den matematiske ligningen ved hjelp av stokastisk gradientnedstigning.
- Dype konvolusjonelle GAN (DCGAN): Dette er en populær og ansett som den mest vellykkede GAN-implementeringen. DCGAN består av ConvNets i stedet for flerlags perceptroner. Disse ConvNets brukes uten teknikker som maksimal pooling eller fullt tilkoblede lag.
- Superoppløsnings-GAN (SRGAN): En GAN-implementering som bruker et dypt nevralt nettverk sammen med et motstridende nettverk for å produsere bilder av høy kvalitet. SRGAN er spesielt nyttig for å effektivt oppskalere originale bilder med lav oppløsning, for å forbedre detaljene og minimere feil.
- Laplacisk pyramide-GAN (LAPGAN): Dette er en inverterbar og lineær representasjon som inkluderer flere båndpassbilder som er plassert med åtte mellomrom fra hverandre, med lavfrekvente rester. LAPGAN bruker flere diskriminator- og generatornettverk og flere laplaciske pyramide-nivåer.
LAPGAN brukes mye fordi den gir førsteklasses bildekvalitet. Disse bildene nedskales ved hvert pyramidelag først og deretter oppskalert ved hvert lag. Støy legges til i prosessen, helt til de når sin opprinnelige størrelse.
Anvendelser av GAN-er
Generative motstridende nettverk har mange bruksområder, som for eksempel:
Vitenskap

GAN-er kan gi en mer nøyaktig og raskere måte å modellere høyenergi-jetformasjon på, og utføre fysikkeksperimenter. Disse nettverkene kan også trenes til å estimere flaskehalser ved å utføre ressurskrevende partikkelfysikksimuleringer.
GAN-er kan akselerere simulering og forbedre simuleringens kvalitet. I tillegg kan GAN-er bidra til å studere mørk materie ved å simulere gravitasjonslinser og forbedre astronomiske bilder.
Videospill

Videospillindustrien har også tatt i bruk GAN-er for å oppskalere 2D-data med lav oppløsning som brukes i eldre videospill. Det gjør det mulig å gjenskape slike data i 4K eller enda høyere oppløsning gjennom bildeopplæring. Deretter kan dataene eller bildene nedskales for å tilpasses videospillets faktiske oppløsning.
Ved riktig opplæring kan GAN-modellene tilby skarpere og klarere 2D-bilder av imponerende kvalitet sammenlignet med de opprinnelige dataene, samtidig som de beholder detaljene i det opprinnelige bildet, som for eksempel farger.
Videospill som har brukt GAN-er inkluderer Resident Evil Remake, Final Fantasy VIII og IX, og flere.
Kunst og mote
Du kan bruke GAN-er til å generere kunst, for eksempel å lage bilder av mennesker som aldri har eksistert, fylle ut manglende deler i fotografier, produsere bilder av uvirkelige motemodeller og mye mer. Det brukes også i tegninger for å generere virtuelle skygger og skisser.
Reklame

Ved å bruke GAN-er til å utvikle og produsere reklame, kan du spare både tid og ressurser. Som vist tidligere, hvis du vil selge smykker, kan du bruke GAN til å skape en imaginær modell som ser ut som en ekte person.
På denne måten kan du bruke modellen til å vise frem smykkene dine til kundene. Dette sparer deg for kostnadene ved å ansette en modell og betale for denne tjenesten. Du kan også eliminere ekstra kostnader som transport, leie av studio, fotografer, makeupartister, og så videre.
Dette kan være en stor fordel hvis du er en ny bedrift og ikke har råd til å ansette en modell eller betale for reklameinfrastruktur.
Lydsyntese
Ved hjelp av GAN-er kan du skape lydfiler fra et sett med lydklipp. Dette er kjent som generativ lyd. Det må ikke forveksles med Amazon Alexa, Apple Siri eller andre AI-stemmer der stemmefragmenter er sydd sammen og produsert ved forespørsel.
Generativ lyd bruker i stedet nevrale nettverk for å studere de statistiske egenskapene til en lydkilde. Deretter gjenskaper den disse egenskapene direkte i en gitt kontekst. Her representerer modelleringen hvordan talen endres i løpet av millisekunder.
Overføringslæring

Avanserte studier av overføringslæring bruker GAN-er til å koordinere de nyeste funksjonsområdene, som for eksempel dyp forsterkende læring. Til dette formålet mates kildens innebygde egenskaper og den ønskede oppgaven til diskriminatoren for å bestemme konteksten. Deretter sendes resultatet tilbake via koderen. På denne måten fortsetter modellen å lære.
Andre bruksområder for GAN-er inkluderer:
- Diagnostisering av totalt eller delvis synstap ved å oppdage glaukomatiske bilder.
- Visualisering av industridesign, interiørdesign, klær, sko, vesker og mer.
- Gjenskape rettsmedisinske ansiktstrekk til en syk person.
- Lage 3D-modeller av en gjenstand fra et bilde, lage nye objekter som en 3D-punktsky og modellere bevegelsesmønstre i en video.
- Vise hvordan en person ser ut i forskjellige aldre.
- Dataforsterkning, som å forbedre DNN-klassifiseringen.
- Fylle ut manglende funksjoner i et kart, forbedre gatevisninger, overføre kartstiler og mer.
- Produsere bilder, forbedre bildesøkesystemer osv.
- Generere kontrollinndata for et ikke-lineært dynamisk system ved å bruke en GAN-variant.
- Analysere effekten av klimaendringer på et hus.
- Lage en persons ansikt fra stemmen deres.
- Lage nye molekyler for ulike proteinmål innen kreft, fibrose og betennelse.
- Animere GIF-er fra et vanlig bilde.
Det finnes mange flere bruksområder for GAN-er i ulike områder, og bruken av dem er stadig økende. Det finnes imidlertid også mange tilfeller av misbruk. GAN-baserte menneskebilder har blitt brukt til uetiske formål, for eksempel å produsere falske videoer og bilder.
GAN-er kan også brukes til å lage realistiske bilder og profiler av personer på sosiale medier som aldri har eksistert. Andre bekymringsverdige misbruk av GAN inkluderer produksjon av falsk pornografi uten samtykke fra de avbildede personene, distribusjon av falske videoer av politiske kandidater, og så videre.
Selv om GAN-er kan være en fordel på mange områder, kan misbruk være katastrofalt. Derfor må det innføres riktige retningslinjer for bruken av teknologien.
Konklusjon
GAN-er er et bemerkelsesverdig eksempel på moderne teknologi. De gir en unik og bedre måte å generere data på, og er nyttige i visuell diagnose, bildesyntese, forskning, dataforsterkning, kunst, vitenskap og mye mer.
Du kan også være interessert i lavkode- og kodefrie maskinlæringsplattformer for å bygge innovative applikasjoner.