Datadeling, også kjent som sharding, er en metode for å oppnå horisontal skalering i omfattende systemer.
I praksis består nesten alle systemer av en database tjener som håndterer mange forespørsler om lesing og en betydelig mengde forespørsler om skriving. Dette kan føre til overbelastning og redusere systemets ytelse.
For å minske slike problemer og forbedre systemets effektivitet, finnes det teknikker som databasereplikasjon og datadeling. I denne veiledningen skal vi først se på metoder for å forbedre systemets ytelse, inkludert:
- Oppgradering av databaseserveren
- Databasereplikasjon
- Horisontal partisjonering
Etter å ha diskutert disse teknikkene, vil vi utforske hvordan datadeling fungerer, samt fordeler og ulemper ved denne metoden.
La oss begynne!
Metoder for å øke systemets ytelse
La oss starte med å se på hvordan vi kan forbedre systemets ytelse når databaseserveren skaper flaskehalser:
#1. Oppgradering av databaseserveren
Å oppgradere databaseserveren kan virke som en enkel løsning for å forbedre systemets ytelse. Dette innebærer å øke prosessorkraften, legge til mer RAM og lignende.
Denne metoden har imidlertid sine begrensninger. Vi kan ikke ha en server med ubegrenset lagringsplass og prosessorkraft. Etter et visst punkt vil forbedringene avta.
#2. Databasereplikasjon
Når databaseserveren blir overbelastet på grunn av mange forespørsler, kan databasereplikasjon være et alternativ.
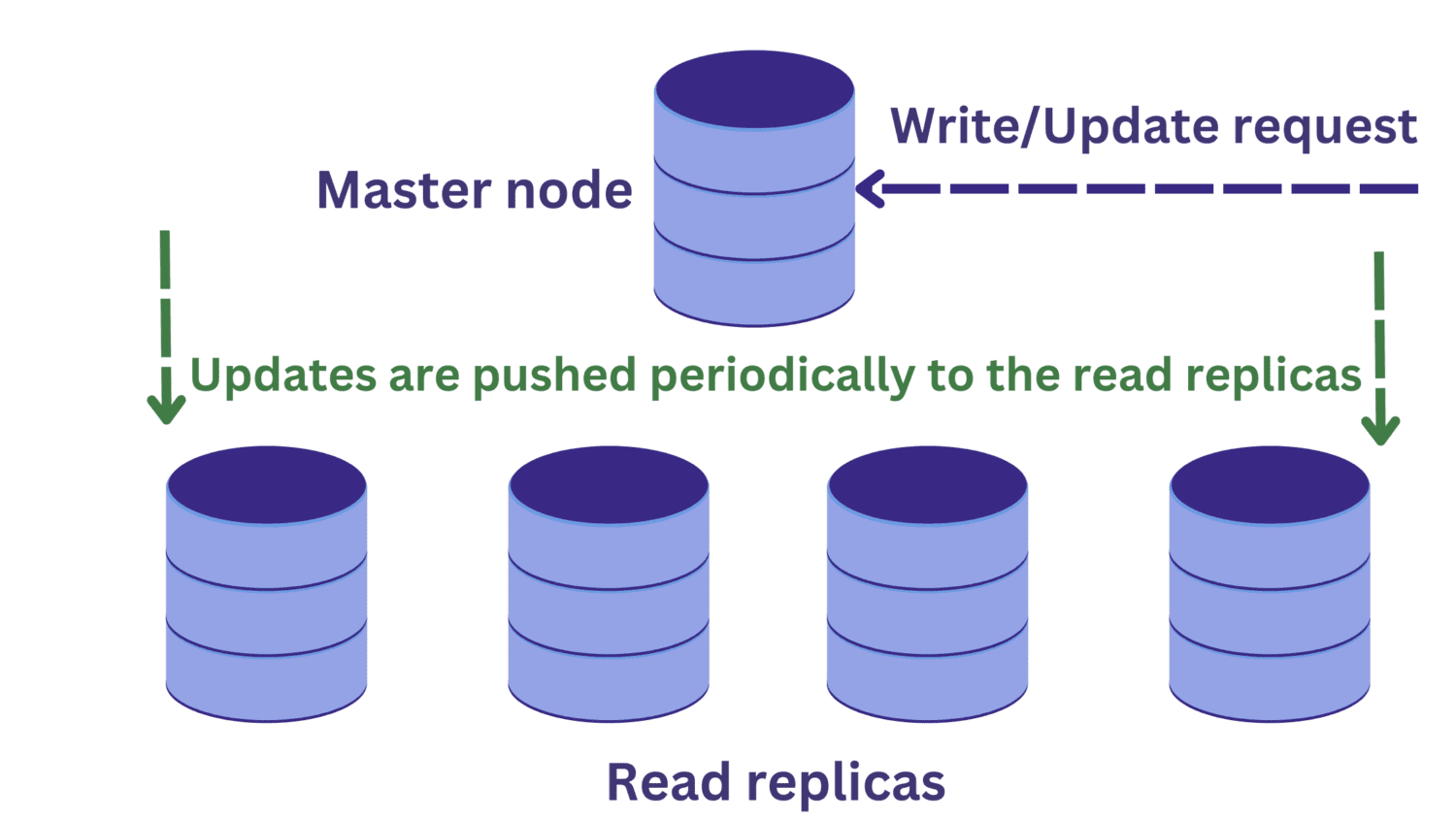
Ved databasereplikasjon har vi en hovednode som vanligvis håndterer skriveforespørsler, og flere lese-replikaer.
Dette øker tilgjengeligheten og reduserer belastningen på systemet. Flere spørringer kan behandles samtidig, da leseforespørsler kan rutes til en av lese-replikaene.
Men dette skaper et nytt problem. Skriveforespørsler til hovednoden kan endre data, og disse oppdateringene må spres til lese-replikaene jevnlig.
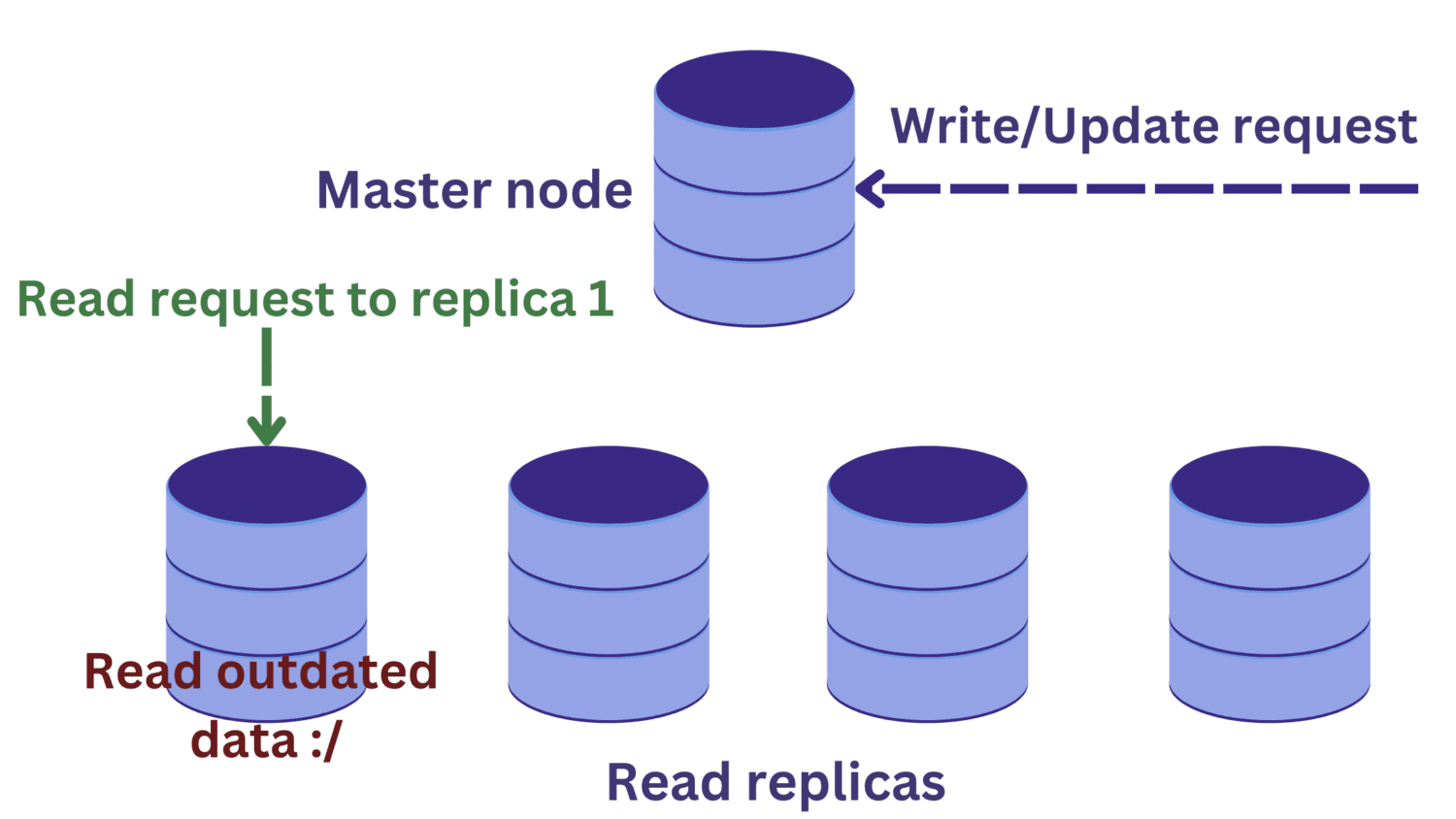
Anta at det kommer en leseforespørsel til en av lese-replikaene samtidig som en skriveoperasjon pågår på hovednoden.
Endringene i hovednoden vil ikke være overført til lese-replikaene ennå. I dette tilfellet kan vi lese utdaterte data, noe som ikke er ideelt.
#3. Horisontal partisjonering
Horisontal partisjonering er en annen teknikk for å forbedre systemets ytelse. Vi kan ha en stor tabell med milliarder av rader (som en tabell over kunder og transaksjonsdata).
Leseforespørsler fra en slik tabell går tregt. Men ved å bruke horisontal partisjonering kan den store tabellen deles opp i flere mindre partisjoner (eller mindre tabeller) som vi kan lese fra. Relasjonsdatabaser som PostgreSQL støtter partisjonering.
Alle partisjonene er likevel innenfor én databaseserver. Forskjellen er at vi nå kan lese fra partisjonene i stedet for den store tabellen.
Derfor kan serveren fortsatt ha problemer med å håndtere økt etterspørsel når antallet forespørsler øker.
Hvordan fungerer datadeling?
Nå som vi har diskutert metoder for å forbedre systemets ytelse og deres begrensninger, la oss se på hvordan datadeling fungerer.
Ved sharding deler vi den store databasen i flere mindre databaser, som hver kjører på en egen databaseserver. Hver av disse mindre databasene kalles en shard, og hver shard inneholder et unikt datasett.
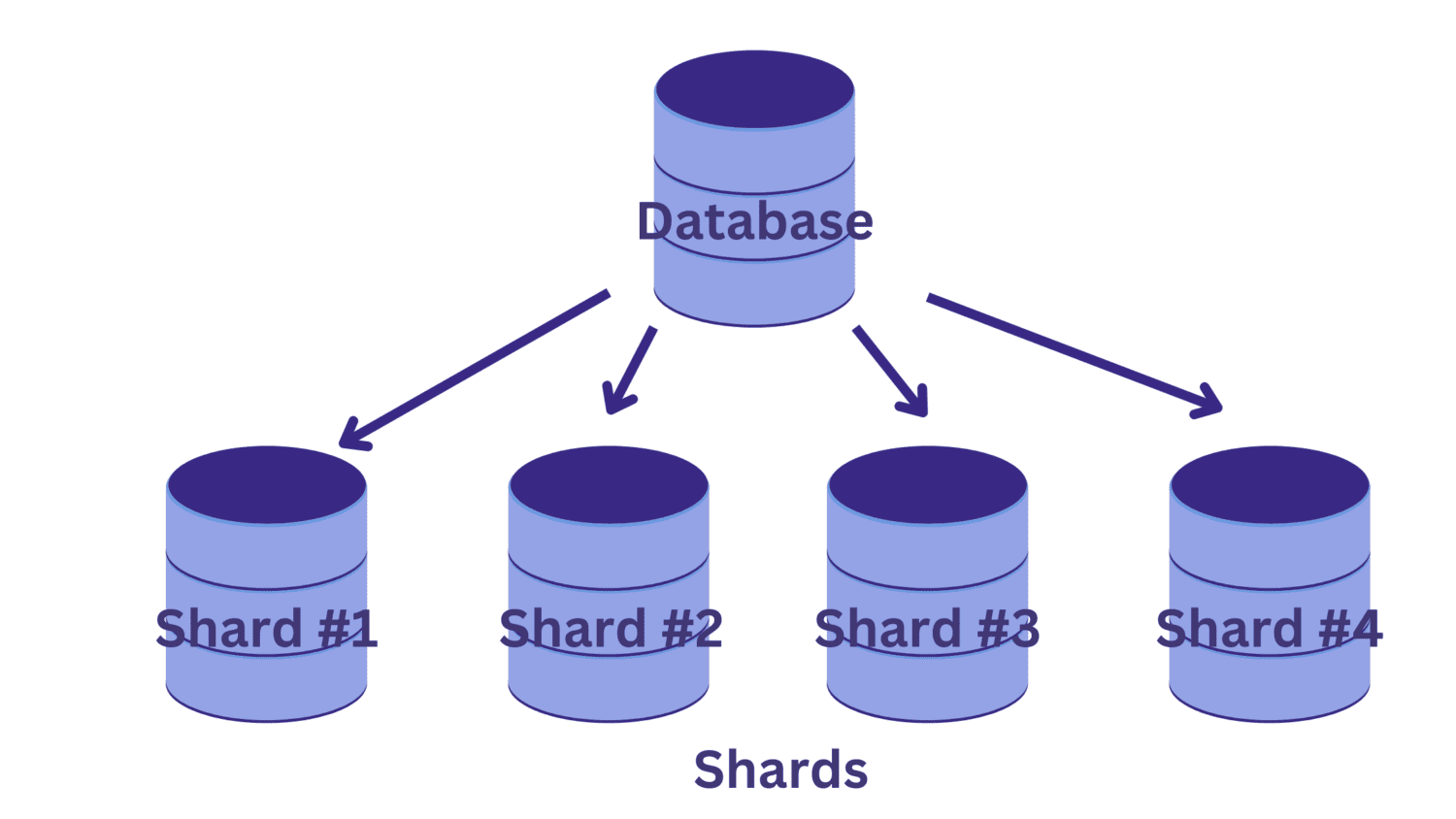
Men hvordan deler vi databasen i shards? Og hvordan bestemmer vi hvilke rader som skal til hvilke shards?
🔑 Her kommer sharding-nøkkelen inn i bildet.
Forstå sharding-nøkkelen
La oss se nærmere på rollen til sharding-nøkkelen.
Sharding-nøkkelen, som ofte er en kolonne (eller en kombinasjon av kolonner) i databasetabellen, bør velges slik at dataene fordeles jevnt over de forskjellige shards. Vi vil unngå at en shard blir mye større enn de andre.
I en database som lagrer informasjon om kunder og transaksjoner, er customer_ID en god kandidat for sharding-nøkkelen.
Når vi har valgt sharding-nøkkelen, kan vi bruke en hashfunksjon for å bestemme hvilke rader som skal til hvilke shards.
La oss si at vi må dele databasen i fem shards (shard #0 til shard #4) ved å bruke customer_ID som sharding-nøkkel. I dette tilfellet kan en enkel hashfunksjon være kunde_ID % 5.
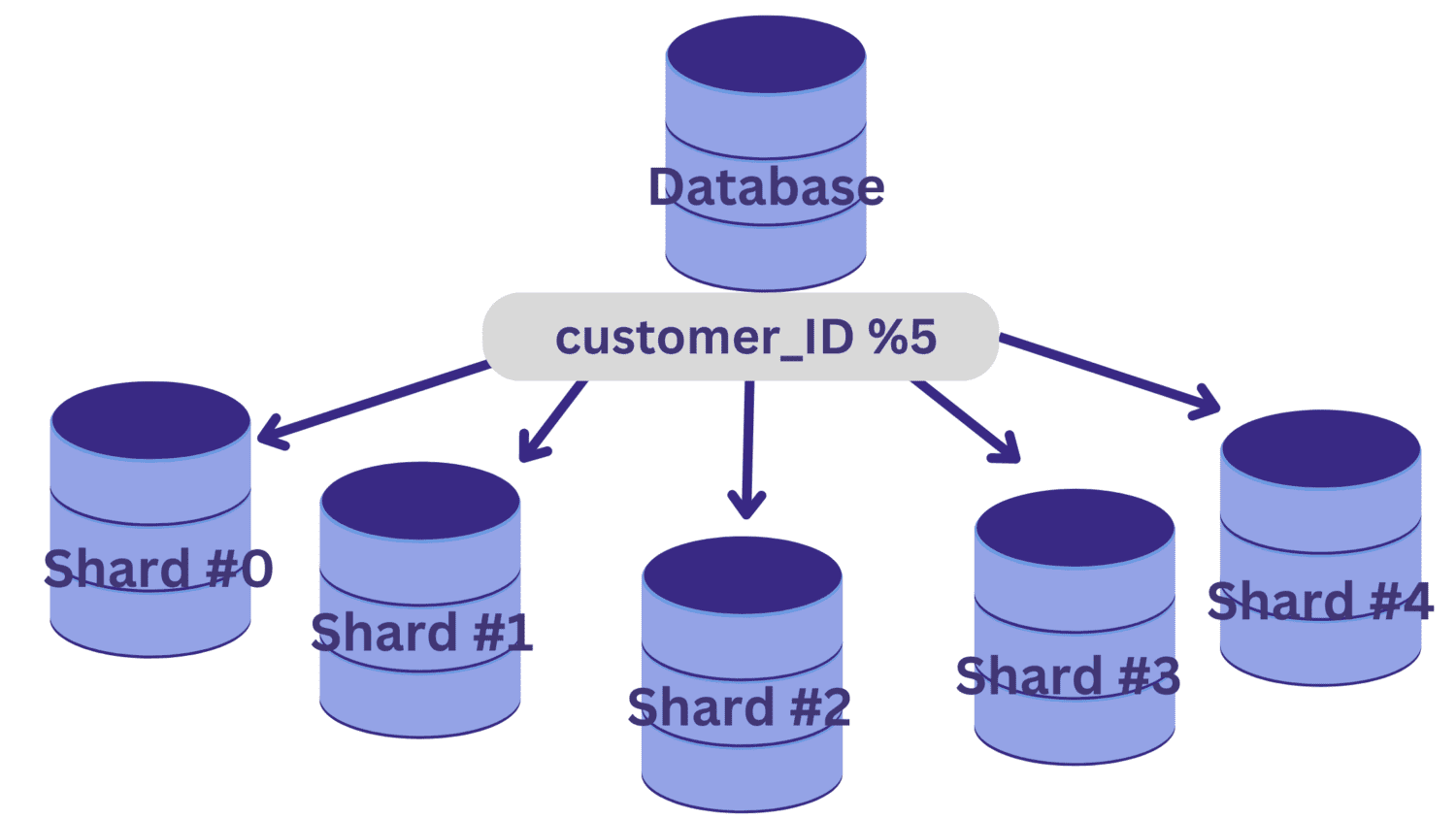
Alle customer_ID-verdier som gir null i rest når de deles på 5, vil plasseres i shard #0. Og customer_ID-verdier som gir rest 1 til 4, vil plasseres i henholdsvis shard #1 til shard #4.
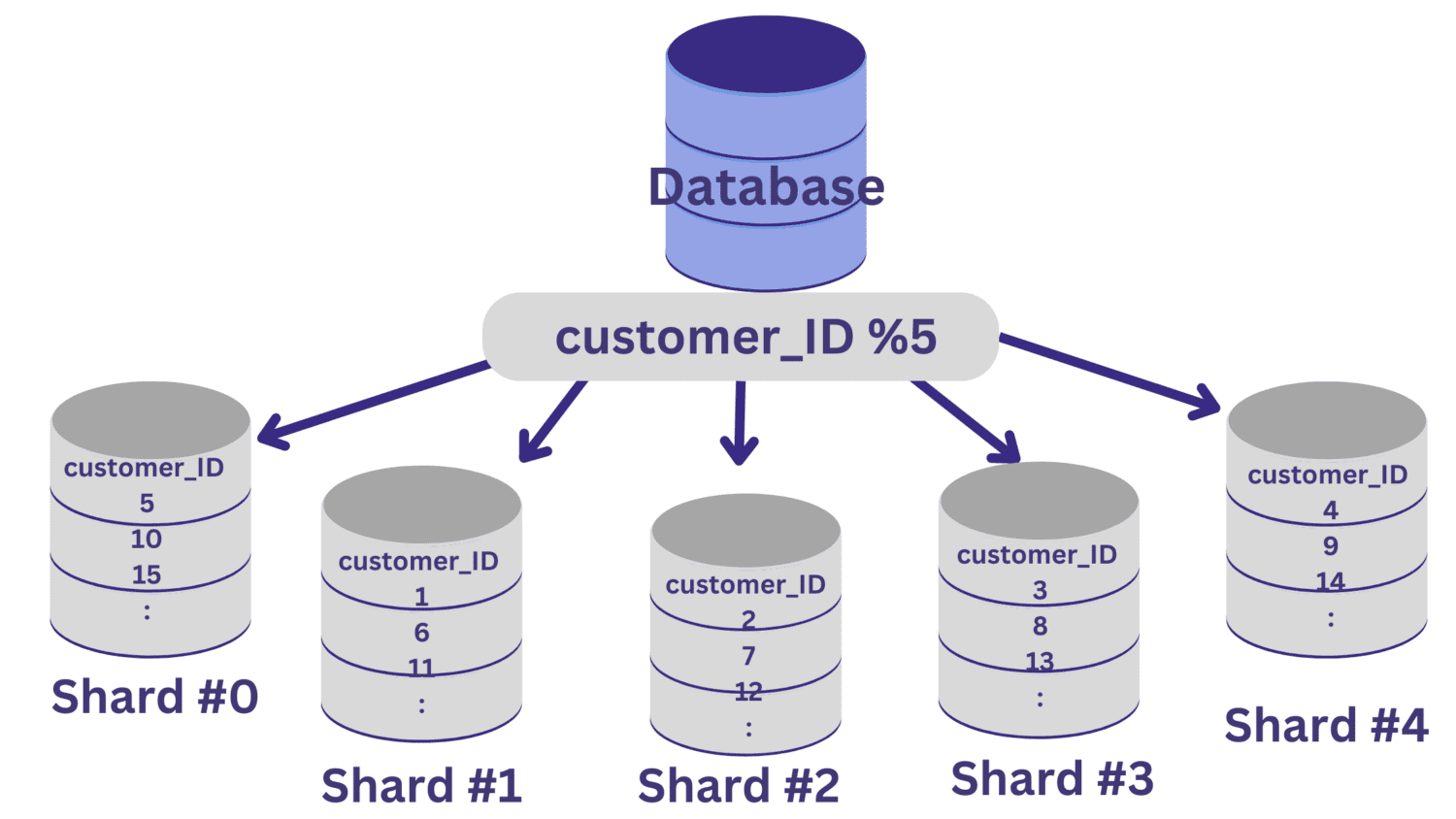
Etter at datadelingen er implementert, er det viktig å ha et rutinglag som sender forespørsler til riktig database shard.
Fordeler med datadeling
Her er noen av fordelene med datadeling:
#1. Høy skalerbarhet
Det er alltid mulig å dele en større database i flere mindre shards. Dermed gir datadeling horisontal skalerbarhet.
#2. Høy tilgjengelighet
Når én enkelt databaseserver håndterer alle forespørsler, har vi et enkelt sviktpunkt. Hvis serveren går ned, går hele applikasjonen ned.
Med datadeling er det mindre sannsynlig at alle shards er nede samtidig. Hvis en shard er nede, vil vi ikke kunne behandle forespørsler til den sharden, men de andre shards vil fortsatt være aktive. Dette gir høyere tilgjengelighet og økt feiltoleranse.
Ulemper med datadeling
La oss nå se på noen av ulempene med datadeling:
#1. Kompleksitet
Selv om sharding gir fordeler som skalerbarhet og feiltoleranse, øker det systemets kompleksitet.
Fra kartlegging av data til partisjoner, til implementering av et rutinglag for å sende spørringer til riktig shard, er det mye kompleksitet forbundet med datadeling.
#2. Omdeling
En annen ulempe med sharding er behovet for resharding.
Selv om vi bruker en hashfunksjon for å fordele data jevnt, kan det hende at en shard blir mye større enn de andre. Da må vi vurdere resharding, noe som kan være kostbart.
#3. Komplekse spørringer
Når vi skal kjøre analyser som involverer sammenslåinger, må vi bruke data fra flere shards i stedet for bare én database. Dette kan være en utfordring når det er behov for mange analytiske søk. Vi kan løse dette ved å denormalisere databasene, men det krever også ekstra arbeid.
Konklusjon
La oss avslutte med en oppsummering av hva vi har lært.
Å oppgradere maskinvaren er ikke alltid optimalt, og det er ikke anbefalt å forbedre serveren i det uendelige. Vi har også diskutert teknikker som databasereplikasjon og horisontal partisjonering, og deres begrensninger.
Vi lærte også hvordan datadeling fungerer, ved å dele en stor database i mindre og mer håndterbare shards. Vi diskuterte hvordan sharding-nøkkelen bør velges nøye for å få jevne partisjoner, og behovet for et rutelag for å sende forespørsler til riktig shard.
Datadeling gir fordeler som høy tilgjengelighet og skalerbarhet. Ulempene inkluderer kompleksiteten med å sette opp sharding og resharding når en shard blir full.
Vurder sharding når du mener at fordelene oppveier ulempene. Du kan deretter sammenligne de forskjellige relasjonsdatabasene på AWS.