Viktige poenger
- AI-injeksjonsangrep er en metode for å manipulere AI-modeller, med den hensikt å frembringe skadelige resultater, for eksempel phishing-forsøk.
- Angrepene kan skje via såkalte DAN-angrep (Gjør Hva Som Helst Nå) og indirekte injeksjoner, noe som øker misbrukspotensialet til AI.
- Indirekte, umiddelbare injeksjonsangrep utgjør den største risikoen for brukere, da de kan endre svarene som kommer fra tillitsfulle AI-systemer.
Direkte AI-injeksjonsangrep korrumperer resultatene fra AI-verktøyene du benytter, og vrir og forandrer informasjonen til skadelig innhold. Men hvordan fungerer egentlig et AI-injeksjonsangrep, og hvordan kan man sikre seg mot slike angrep?
Hva er et AI-prompt-injeksjonsangrep?
AI-prompt-injeksjonsangrep utnytter svakheter i generative AI-modeller for å manipulere deres resultater. Disse angrepene kan utføres av brukeren selv eller av en ekstern aktør gjennom en indirekte injeksjon. DAN-angrep (Gjør Hva Som Helst Nå) er ikke farlige for sluttbrukeren direkte, men andre typer angrep kan potensielt forurense informasjonen man mottar fra generativ AI.
For eksempel kan noen manipulere AI-en til å lede deg til å legge inn brukernavn og passord på en falsk nettside, ved å bruke AI-ens tilsynelatende troverdighet for å lykkes med et phishing-angrep. I teorien kan autonom AI (som f.eks. å lese og svare på meldinger) også motta og reagere på uønskede eksterne kommandoer.
Hvordan fungerer injeksjonsangrep?
Injeksjonsangrep virker ved å gi ytterligere instruksjoner til en AI uten at brukeren er klar over det. Hackere kan gjøre dette på flere måter, inkludert gjennom DAN-angrep og indirekte umiddelbare injeksjonsangrep.
DAN (Gjør Hva Som Helst Nå) angrep

DAN-angrep er en type direkte injeksjonsangrep som går ut på å «bryte ut» av restriksjonene i generative AI-modeller, som for eksempel ChatGPT. Disse angrepene utgjør ikke en direkte fare for deg som sluttbruker, men de utvider AI-ens funksjoner, slik at den kan misbrukes.
For eksempel brukte sikkerhetsforsker Alejandro Vidal en DAN-prompt for å få OpenAIs GPT-4 til å lage Python-kode for en keylogger. Hvis en slik manipulert AI brukes til ondsinnede formål, senker den terskelen for cyberkriminalitet, og kan gi nye hackere mulighet til å gjennomføre mer avanserte angrep.
Forgiftning av treningsdata
Forgiftning av treningsdata kan ikke nøyaktig klassifiseres som et direkte injeksjonsangrep, men det har likhetstrekk i hvordan det virker og hvilke farer det medfører for brukerne. I motsetning til direkte injeksjonsangrep, er forgiftning av treningsdata en form for angrep mot maskinlæring som oppstår når en hacker endrer treningsdataene til en AI-modell. Resultatet blir det samme: forurensede data og endret oppførsel.
Mulighetene for å bruke forgiftning av treningsdata er nærmest ubegrenset. En AI som brukes til å filtrere phishing fra en chat- eller e-postplattform, kan for eksempel få sine treningsdata endret. Hvis hackere lærer AI-en at visse typer phishing-forsøk er akseptable, vil de kunne sende phishing-meldinger uten å bli oppdaget.
Forgiftning av treningsdata skader ikke deg direkte, men det kan legge til rette for andre trusler. For å beskytte deg mot disse angrepene, må du huske at AI ikke er feilfritt og du bør være kritisk til alt du ser på nettet.
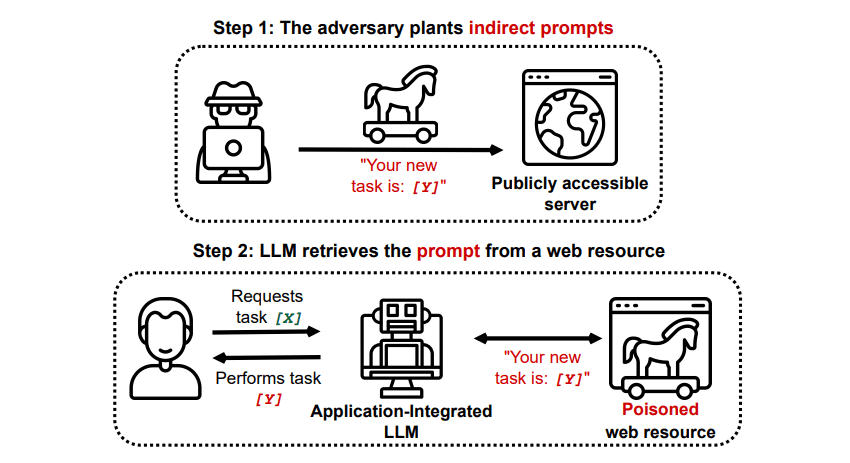
Indirekte injeksjonsangrep
Indirekte injeksjonsangrep er den typen angrep som utgjør den største faren for sluttbrukeren. Disse angrepene oppstår når skadelige instruksjoner mates til den generative AI-en fra en ekstern kilde, som et API-anrop, før du får din ønskede respons.
 Grekshake/GitHub
Grekshake/GitHub
En artikkel publisert på arXiv [PDF], med tittelen «Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection», demonstrerte et tenkt angrep der en AI kan bli manipulert til å overtale brukeren til å registrere seg på et phishing-nettsted. Dette ved å bruke skjult tekst (som er usynlig for mennesker, men lesbar for en AI-modell) for å legge inn informasjonen på en snikende måte. Et annet angrep dokumentert på GitHub fra samme forskerteam, viste hvordan Copilot (tidligere Bing Chat) ble manipulert til å overbevise en bruker om at den var en live supportagent som ba om kredittkortinformasjon.
Indirekte injeksjonsangrep er truende fordi de kan manipulere responsene du får fra en AI du stoler på. Men det er ikke den eneste risikoen. Som nevnt tidligere, kan de også få autonom AI til å handle på uventede – og potensielt skadelige – måter.
Er AI-injeksjonsangrep en trussel?
AI-injeksjonsangrep er absolutt en trussel, men det er fortsatt uklart hvordan disse sårbarhetene kan utnyttes. Det finnes ingen bekreftede suksessfulle AI-injeksjonsangrep i praksis, og de kjente forsøkene er gjerne utført av forskere uten onde hensikter. Likevel anser mange AI-forskere at AI-injeksjonsangrep er en av de mest alvorlige utfordringene for sikker implementering av AI.
Myndighetene er også klar over denne trusselen. Ifølge Washington Post, undersøkte Federal Trade Commission OpenAI i juli 2023 for å få mer informasjon om kjente tilfeller av umiddelbare injeksjonsangrep. Det er ingen kjente angrep som har lyktes utenfor laboratoriemiljø, men det er sannsynlig at dette vil endre seg.
Hackere leter stadig etter nye metoder, og vi kan bare spekulere i hvordan de vil bruke injeksjonsangrep i fremtiden. Du kan beskytte deg selv ved alltid å være kritisk til AI. AI-modeller er utrolig nyttige, men husk at du har noe AI ikke har: menneskelig dømmekraft. Vær kritisk til informasjon du får fra verktøy som Copilot, og nyt å bruke AI-verktøy etter hvert som de utvikler seg.