Google JAX, eller «Just After Execution», er et rammeverk utviklet av Google for å akselerere maskinlæringsprosesser.
Det kan betraktes som et Python-bibliotek som bidrar til raskere utførelse av beregninger, vitenskapelig databehandling, transformasjon av funksjoner, dyp læring, nevrale nettverk og mer.
Om Google JAX
Den mest grunnleggende pakken for beregninger i Python er NumPy, som inneholder funksjoner for aggregeringer, vektoroperasjoner, lineær algebra, manipulering av n-dimensjonale arrayer og matriser, samt mange andre avanserte funksjoner.
Hva om vi kunne øke hastigheten på beregningene som utføres ved hjelp av NumPy enda mer, spesielt for store datasett?
Finnes det en løsning som fungerer like effektivt på ulike typer prosessorer som GPU eller TPU, uten at vi må endre koden?
Hva om systemet automatisk og mer effektivt kunne utføre sammensetbare funksjonstransformasjoner?
Google JAX er et bibliotek (eller et rammeverk, som Wikipedia definerer det) som gjør nettopp dette, og kanskje enda mer. Det ble konstruert for å optimalisere ytelsen og effektivt utføre oppgaver innen maskinlæring (ML) og dyp læring. Google JAX tilbyr følgende transformasjonsfunksjoner som skiller det fra andre ML-biblioteker og bidrar til avanserte vitenskapelige beregninger for dyp læring og nevrale nettverk:
- Automatisk differensiering
- Automatisk vektorisering
- Automatisk parallellisering
- Just-in-time (JIT) kompilering
Google JAX sine unike egenskaper
Alle transformasjonene bruker XLA (Accelerated Linear Algebra) for å oppnå høyere ytelse og optimalisere minnebruk. XLA er en domenespesifikk kompilatormotor som optimerer lineær algebra og akselererer TensorFlow-modeller. Bruken av XLA på toppen av Python-kode krever ingen betydelige endringer i koden!
La oss se nærmere på hver av disse funksjonene.
Funksjoner i Google JAX
Google JAX tilbyr viktige funksjoner for sammensetbare transformasjoner som forbedrer ytelsen og effektiviserer utførelsen av dyp læringsoppgaver. Et eksempel er automatisk differensiering, som gjør det mulig å finne gradienten til en funksjon og deriverte av hvilken som helst orden. På samme måte muliggjør automatisk parallellisering og JIT parallell utførelse av flere oppgaver. Disse transformasjonene er essensielle i applikasjoner som robotikk, spill og forskning.
En sammensetbar transformasjonsfunksjon er en ren funksjon som transformerer et sett med data til en annen form. De kalles sammensetbare fordi de er uavhengige (dvs. disse funksjonene har ingen avhengigheter til resten av programmet) og tilstandsløse (dvs. den samme inndataen vil alltid gi samme utdata).
Y(x) = T(f(x))
I ligningen ovenfor er f(x) den opprinnelige funksjonen som transformasjonen brukes på. Y(x) er funksjonen som oppstår etter at transformasjonen er anvendt.
Hvis du for eksempel har en funksjon kalt «total_bill_amt», og du ønsker å få resultatet som en funksjonstransformasjon, kan du enkelt anvende den ønskede transformasjonen, for eksempel gradient (grad):
grad_total_bill = grad(total_bill_amt)
Ved å transformere numeriske funksjoner med funksjoner som grad(), kan vi lett få høyere ordens deriverte, som vi kan bruke i dyp læringsoptimeringsalgoritmer som gradientnedstigning, og dermed gjøre algoritmene raskere og mer effektive. Ved å bruke jit() kan vi kompilere Python-programmer just-in-time (etter behov).
#1. Automatisk differensiering
Python bruker autograd-funksjonen for automatisk å differensiere NumPy og original Python-kode. JAX bruker en modifisert versjon av autograd (dvs. grad) og kombinerer den med XLA (Accelerated Linear Algebra) for å utføre automatisk differensiering og finne deriverte av enhver orden for GPU (Graphic Processing Units) og TPU (Tensor Processing Units).
En rask forklaring om TPU, GPU og CPU: CPU, eller sentral prosesseringsenhet, styrer alle operasjoner på datamaskinen. GPU er en ekstra prosessor som forbedrer datakraften og kjører avanserte operasjoner. TPU er en kraftig enhet som er spesielt utviklet for komplekse og krevende arbeidsbelastninger som AI og algoritmer for dyp læring.
I likhet med autograd-funksjonen, som kan differensiere gjennom løkker, rekursjoner, forgreninger og så videre, bruker JAX grad()-funksjonen for gradienter i reversmodus (tilbakepropagering). Vi kan også differensiere en funksjon til enhver orden ved å bruke grad:
grad(grad(grad(sin θ))) (1.0)
Automatisk differensiering av høyere orden
Som nevnt tidligere er grad nyttig for å finne partielle deriverte av en funksjon. En partiell derivert kan brukes til å beregne gradientnedstigningen til en kostnadsfunksjon med hensyn til de nevrale nettverksparametrene i dyp læring for å minimere tap.
Beregning av partiell derivert
Anta at en funksjon har flere variabler, x, y og z. Å finne den deriverte av en variabel mens de andre variablene holdes konstante kalles en partiell derivert. Anta at vi har en funksjon:
f(x,y,z) = x + 2y + z²
Eksempel for å illustrere partiell derivert
Den partielle deriverte av x vil være ∂f/∂x, som viser hvordan en funksjon endres for en variabel når de andre holdes konstante. Hvis vi utfører dette manuelt, må vi skrive et program for å differensiere, bruke det for hver variabel og deretter beregne gradientnedstigningen. Dette ville blitt en kompleks og tidkrevende oppgave for flere variabler.
Automatisk differensiering deler opp funksjonen i et sett med grunnleggende operasjoner som +, -, *, / eller sin, cos, tan, exp, osv., og bruker kjederegelen for å beregne den deriverte. Dette kan gjøres i både forover- og reversmodus.
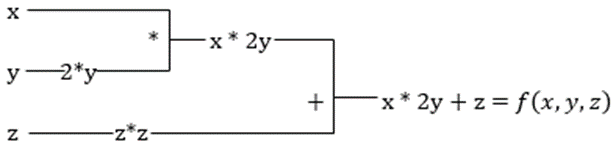
Og det er ikke alt! Alle disse beregningene skjer utrolig raskt (tenk på en million beregninger som ligner på de ovennevnte og tiden det kan ta!). XLA tar seg av hastigheten og ytelsen.
#2. Akselerert lineær algebra
La oss se på den forrige ligningen. Uten XLA vil beregningen involvere tre (eller flere) kjerner, der hver kjerne utfører en mindre oppgave. For eksempel:
Kjerne k1 –> x * 2y (multiplikasjon)
k2 –> x * 2y + z (addisjon)
k3 –> Reduksjon
Hvis den samme oppgaven utføres av XLA, vil en enkelt kjerne håndtere alle mellomoperasjonene ved å slå dem sammen. Mellomresultatene av elementære operasjoner strømmes i stedet for å lagres i minnet, noe som sparer minne og øker hastigheten.
#3. Just-in-time kompilering
JAX bruker den interne XLA-kompilatoren for å øke utførelseshastigheten. XLA kan øke hastigheten til CPU, GPU og TPU. Dette er muliggjort ved hjelp av JIT-kodekjøring. For å bruke dette, kan vi importere jit:
from jax import jit def my_function(x): …………noen linjer med kode my_function_jit = jit(my_function)
En annen måte er å bruke dekoratoren jit over funksjonsdefinisjonen:
@jit def my_function(x): …………noen linjer med kode
Denne koden kjører mye raskere fordi transformasjonen returnerer den kompilerte versjonen av koden til den som kaller den, i stedet for å bruke Python-tolken. Dette er spesielt nyttig for vektorinndata som matriser og tabeller.
Det samme gjelder for alle eksisterende Python-funksjoner også, for eksempel funksjoner fra NumPy-pakken. I dette tilfellet bør vi importere jax.numpy som jnp i stedet for NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Når dette er gjort, erstatter JAX-matrisen, kalt DeviceArray, den standard NumPy-matrisen. DeviceArray er «lat» – verdiene oppbevares i akseleratoren til de trengs. Dette betyr også at JAX-programmet ikke venter på at resultatene skal returneres til det kallende (Python-)programmet, og følger dermed en asynkron overføring.
#4. Automatisk vektorisering (vmap)
I maskinlæring har vi ofte datasett med en million eller flere datapunkter. Det er vanlig å utføre beregninger eller manipuleringer på hvert eller de fleste av disse datapunktene – noe som er en svært tid- og minnekrevende oppgave! Hvis du for eksempel vil finne kvadratet av hvert av datapunktene i et datasett, er den første tanken å lage en løkke og ta kvadratet ett etter ett – uff!
Hvis vi lager disse punktene som vektorer, kan vi utføre alle kvadratene på en gang ved å bruke vektor- eller matrisemanipulasjoner på datapunktene med NumPy. Og hvis programmet ditt kunne gjøre dette automatisk – kan du ønske deg noe mer? Det er akkurat det JAX gjør! Den kan automatisk vektorisere alle datapunktene dine slik at du enkelt kan utføre alle operasjoner på dem – noe som gjør algoritmene dine mye raskere og mer effektive.
JAX bruker vmap-funksjonen for autovektorisering. La oss se på følgende array:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Bare ved å utføre det ovennevnte, vil kvadratmetoden utføres for hvert punkt i matrisen. Men hvis du gjør følgende:
vmap(jnp.square(x))
Kvadratmetoden vil kun utføres én gang fordi datapunktene nå vektoriseres automatisk ved hjelp av vmap-metoden før funksjonen utføres. Dermed blir løkker presset ned til det elementære operasjonsnivået – noe som resulterer i en matrisemultiplikasjon i stedet for skalarmultiplikasjon og gir bedre ytelse.
#5. SPMD-programmering (pmap)
SPMD – eller Single Program Multiple Data-programmering – er viktig i dype læringskontekster. Ofte vil du bruke de samme funksjonene på forskjellige datasett som er plassert på flere GPUer eller TPUer. JAX har en funksjon kalt pmap, som muliggjør parallell programmering på flere GPUer eller en hvilken som helst akselerator. I likhet med JIT vil programmer som bruker pmap, bli kompilert av XLA og kjøres samtidig på tvers av systemene. Denne automatiske parallelliseringen fungerer for både forover- og bakoverberegninger.
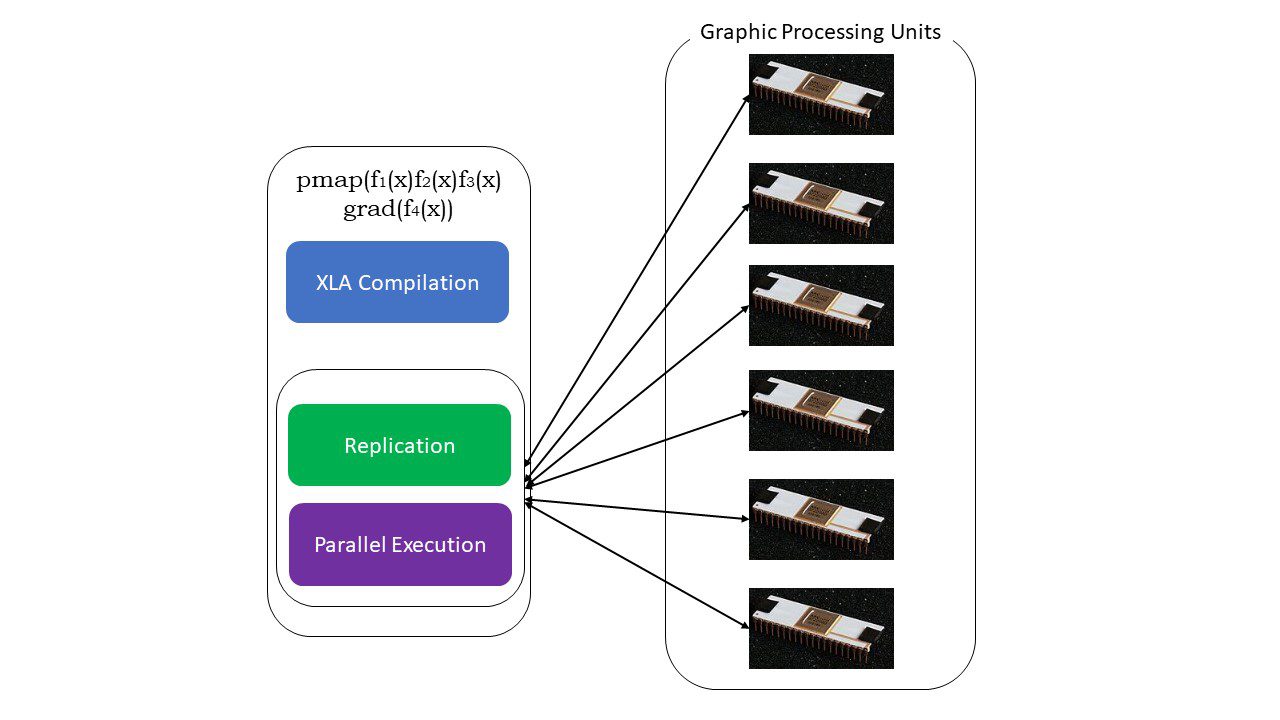 Slik fungerer pmap
Slik fungerer pmap
Vi kan også bruke flere transformasjoner samtidig i vilkårlig rekkefølge på en hvilken som helst funksjon som:
pmap(vmap(jit(grad (f(x)))))
Flere sammensetbare transformasjoner
Begrensninger ved Google JAX
Utviklerne av Google JAX har fokusert på å øke hastigheten på dyp læringsalgoritmer ved å introdusere alle disse fantastiske transformasjonene. De vitenskapelige beregningsfunksjonene og pakkene er på linje med NumPy, slik at du ikke trenger å bekymre deg for læringskurven. JAX har imidlertid følgende begrensninger:
- Google JAX er fortsatt i en tidlig utviklingsfase, og selv om hovedmålet er ytelsesoptimalisering, gir det ikke mye nytte for CPU-databehandling. NumPy ser ut til å fungere bedre, og bruk av JAX kan bare øke overheaden.
- JAX er fortsatt i en forsknings- eller tidlig fase og trenger mer finjustering for å nå infrastrukturstandardene til rammeverk som TensorFlow, som er mer etablerte og har flere forhåndsdefinerte modeller, åpen kildekode-prosjekter og læremateriell.
- Foreløpig støtter ikke JAX Windows-operativsystem – du trenger en virtuell maskin for å få det til å fungere.
- JAX fungerer kun med rene funksjoner – de som ikke har noen bivirkninger. For funksjoner med bivirkninger er JAX kanskje ikke et godt alternativ.
Slik installerer du JAX i Python-miljøet ditt
Hvis du har Python installert på systemet og ønsker å kjøre JAX på din lokale maskin (CPU), kan du bruke følgende kommandoer:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Hvis du vil kjøre Google JAX på en GPU eller TPU, følg instruksjonene på GitHub JAX-siden. For å installere Python, gå til den offisielle nedlastingssiden for Python.
Konklusjon
Google JAX er utmerket for å skrive effektive dyp læringsalgoritmer, robotikk og forskning. Til tross for begrensningene, brukes det mye sammen med andre rammeverk som Haiku, Flax og mange flere. Du vil kunne sette pris på hva JAX gjør når du kjører programmer og ser tidsforskjellene ved å utføre kode med og uten JAX. Du kan begynne med å lese den offisielle Google JAX-dokumentasjonen, som er ganske omfattende.