Viktige poeng
- Generalisering er sentralt innen dyp læring for å sikre presise forutsigelser med nye datasett. Zero-shot læring hjelper med dette ved å la kunstig intelligens benytte eksisterende kunnskap til å lage nøyaktige forutsigelser på ukjente kategorier, uten behov for merkede data.
- Zero-shot læring etterligner menneskelig læring og databehandling. Ved å tilføre ekstra semantisk informasjon kan en forhåndstrent modell identifisere nye klasser presist, akkurat som en person kan lære å kjenne igjen en semiakustisk gitar ved å forstå dens spesifikke kjennetegn.
- Zero-shot læring forbedrer kunstig intelligens ved å forsterke generalisering, skalerbarhet, redusere overtilpasning og være kostnadseffektiv. Det åpner for trening av modeller på større datasett, tilegnelse av mer kunnskap via overføringslæring, bedre kontekstuell forståelse, og reduserer behovet for omfattende merkede data. I takt med utviklingen av kunstig intelligens vil zero-shot læring bli enda viktigere for å håndtere komplekse problemer på tvers av ulike områder.
Et sentralt mål med dyp læring er å utvikle modeller med bred generalisert kunnskap. Generalisering er viktig fordi den garanterer at modellen har lært meningsfulle mønstre, og dermed kan foreta korrekte forutsigelser eller beslutninger når den blir konfrontert med nye eller ukjente datasett. Utvikling av slike modeller krever ofte betydelige mengder merkede data. Slike data kan imidlertid være dyre, tidkrevende å skaffe, eller i visse tilfeller umulige å få tak i.
Zero-shot læring er utviklet for å bygge bro over dette gapet, ved å gjøre det mulig for kunstig intelligens å bruke sin eksisterende kunnskap til å generere rimelig presise forutsigelser til tross for mangelen på merkede data.
Hva er Zero-Shot Læring?
Zero-shot læring er en spesifikk type overføringslæring. Den fokuserer på å bruke en forhåndstrent modell for å identifisere nye eller tidligere ukjente klasser, ved å tilføre tilleggsinformasjon som beskriver detaljene i den nye klassen.
Ved å benytte seg av modellens generelle kunnskap om visse emner og gi den ekstra semantisk informasjon om hva den skal se etter, vil den være i stand til å identifisere det aktuelle emnet ganske nøyaktig.
La oss anta at vi skal identifisere en sebra. Vi har imidlertid ingen modell som er trent til å gjenkjenne sebraer. Vi bruker en eksisterende modell som er trent til å identifisere hester og informerer modellen om at hester med svarte og hvite striper er sebraer. Når vi deretter gir modellen bilder av sebraer og hester, er det stor sannsynlighet for at modellen vil identifisere hvert dyr korrekt.
Som mange teknikker innen dyp læring, etterligner zero-shot læring menneskets måte å lære og behandle data på. Mennesker er kjent for å være naturlige zero-shot læringseksperter. Hvis du for eksempel ble bedt om å finne en semiakustisk gitar i en musikkbutikk, kan du slite med å finne den. Men dersom du får vite at en semiakustisk gitar er en gitar med et f-formet hull på en eller begge sider, vil du sannsynligvis finne en umiddelbart.

La oss ta et praktisk eksempel med zero-shot klassifiseringsappen fra Hugging Face, en åpen kildekode-plattform for LLM-hosting, ved å bruke clip-vit-large-modellen.
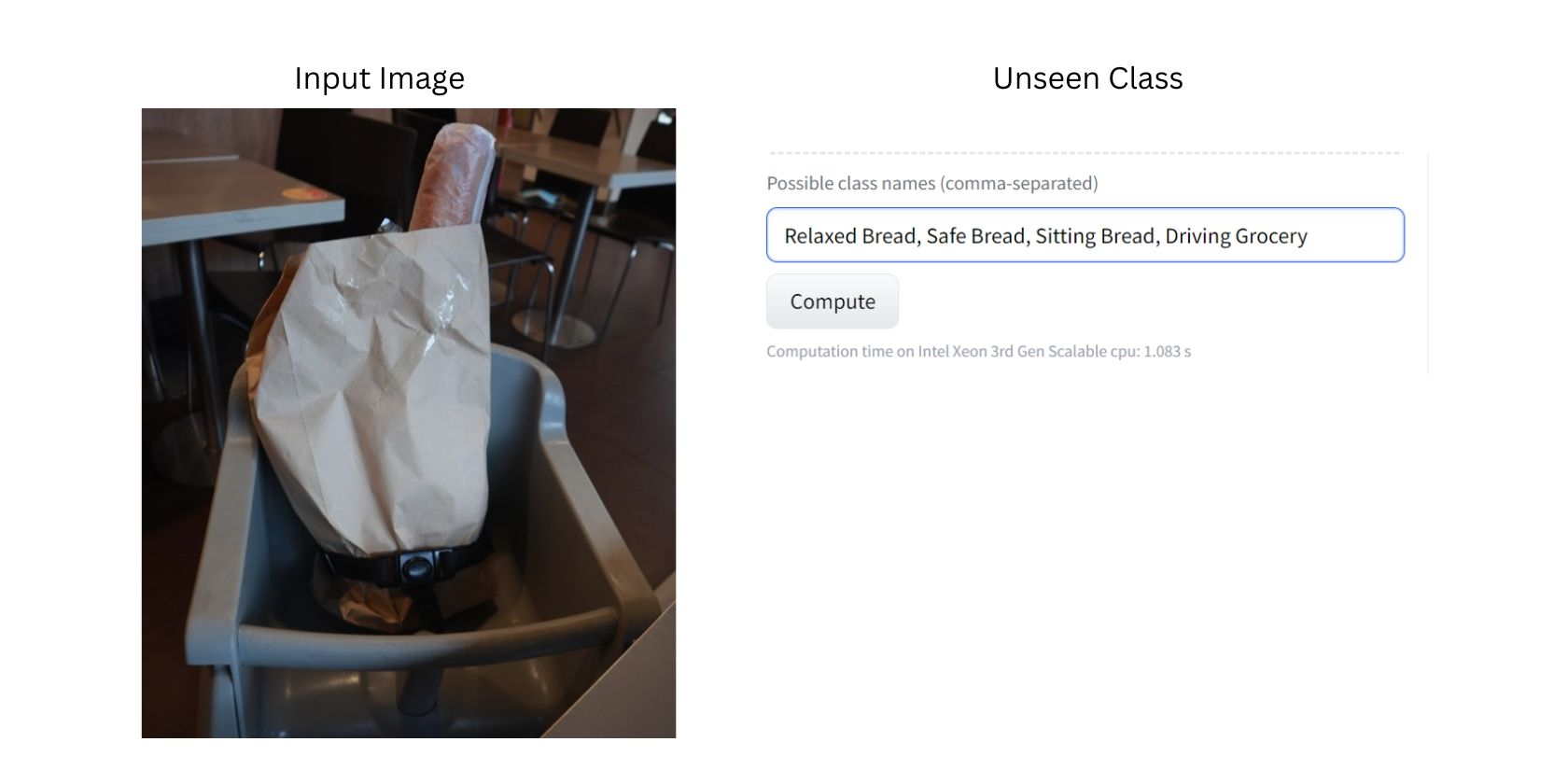
Dette bildet viser brød i en handlepose, plassert på en barnestol. Siden modellen er trent på et stort bilde-datasett, er den sannsynligvis i stand til å identifisere alle elementene på bildet, som brød, handleposer, stoler og sikkerhetsbelter.
Nå skal vi få modellen til å klassifisere bildet ved å bruke tidligere usette klasser. I dette tilfellet er de nye eller usette klassene «Avslappet brød», «Sikkert brød», «Sittende brød», «Kjørende matvarer» og «Trygge matvarer».
Vær oppmerksom på at vi med hensikt har brukt uvanlige usette klasser og bilder for å vise effektiviteten til zero-shot klassifisering.
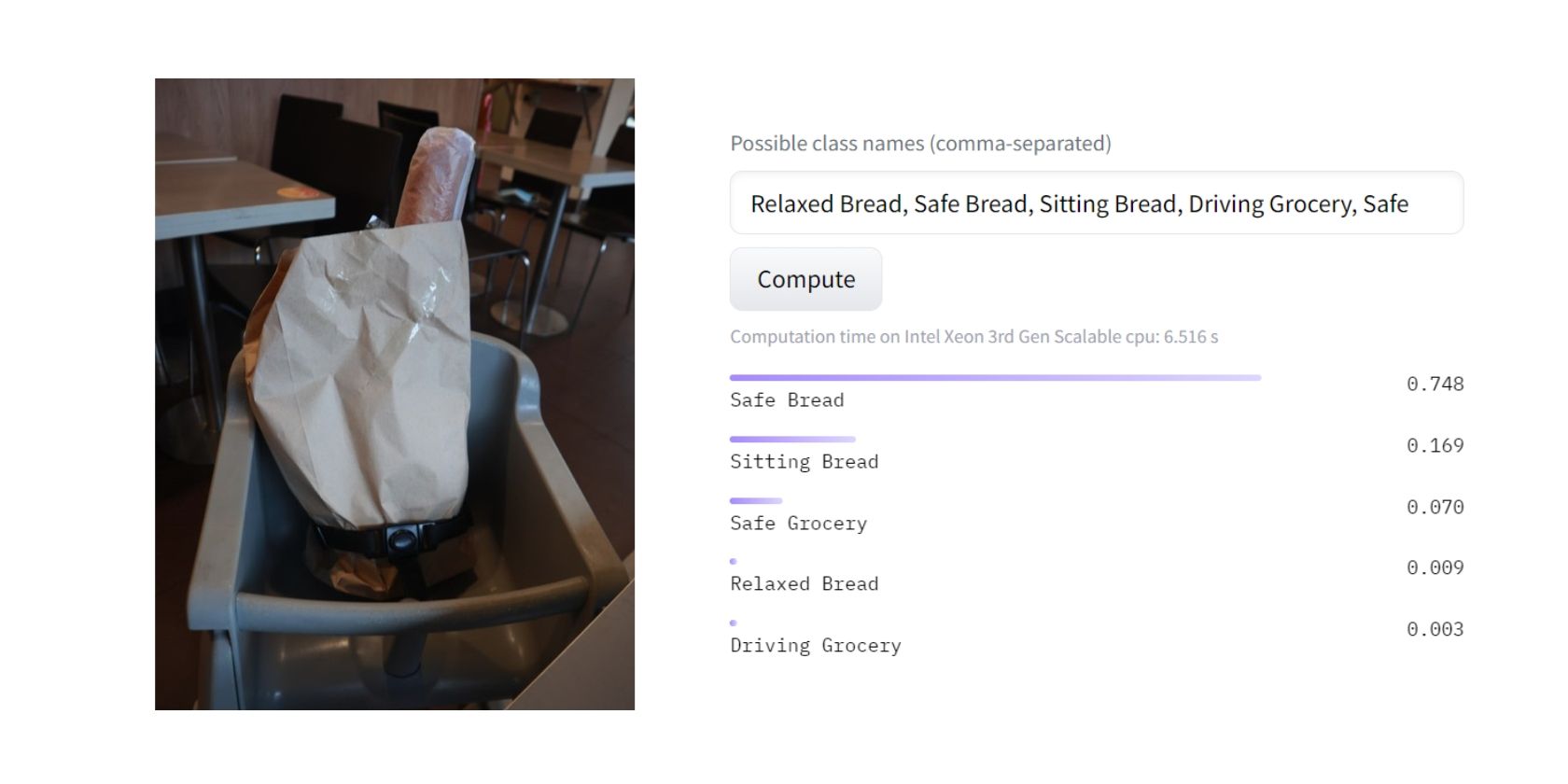
Etter at modellen ble bedt om å gjøre en klassifisering, identifiserte den med ca. 80 % sikkerhet at den mest passende kategorien for bildet var «Trygt brød». Dette skyldes sannsynligvis at modellen antar at en barnestol primært handler om sikkerhet og ikke så mye om det å sitte, slappe av eller kjøre.
Utrolig! Jeg er personlig enig i modellens konklusjon. Men hvordan kom modellen frem til et slikt resultat? Her følger en generell oversikt over hvordan zero-shot læring fungerer.
Hvordan fungerer Zero-Shot Læring?
Zero-shot læring kan hjelpe en forhåndstrent modell med å identifisere nye klasser uten å tilføre merkede data. I sin enkleste form består zero-shot læring av tre trinn:
1. Forberedelse
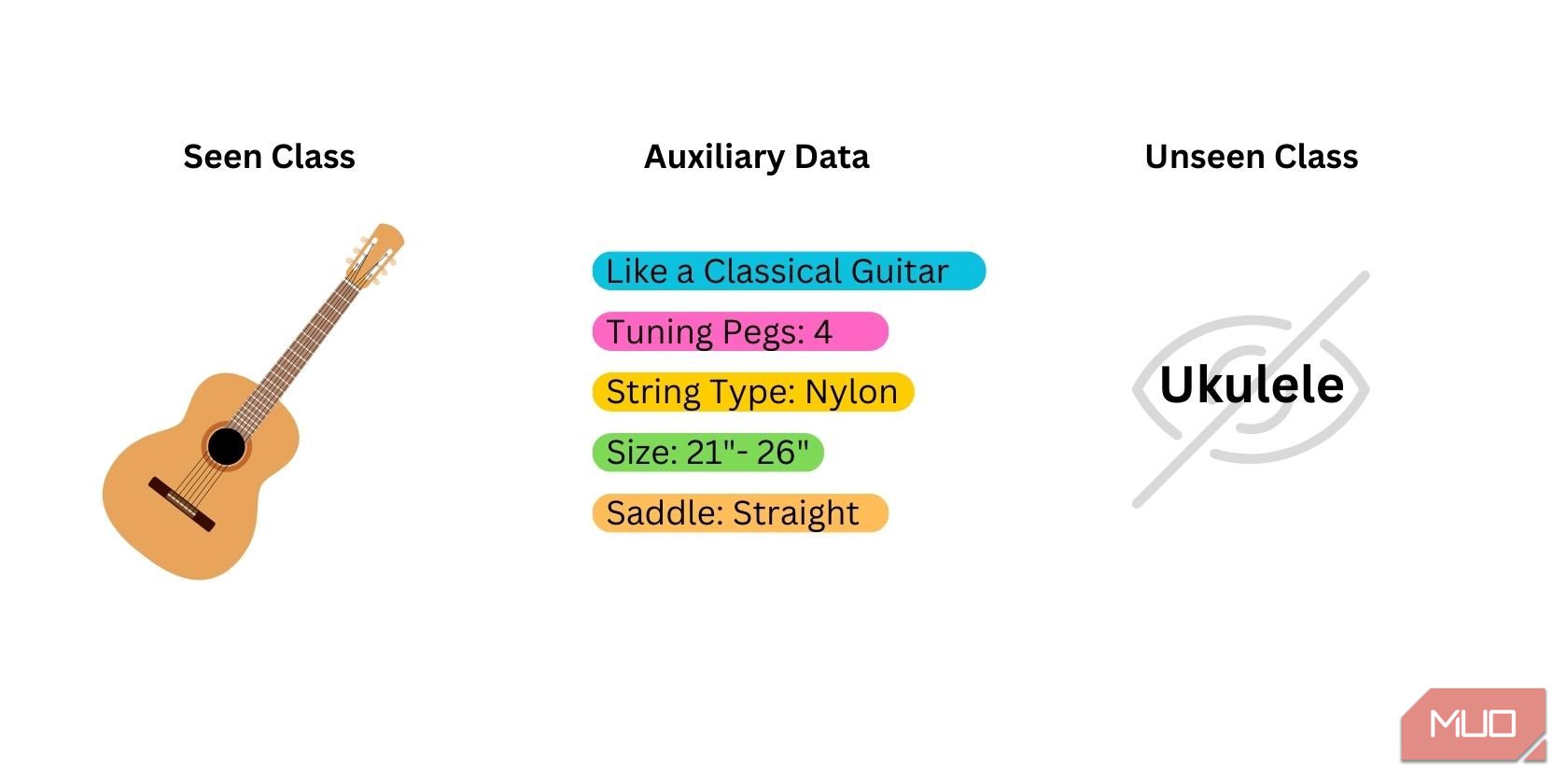
Zero-shot læring begynner med å forberede tre typer data:
- Sett klasser: Data som ble brukt til å trene den forhåndstrente modellen. Modellen har allerede kjennskap til disse klassene. De beste modellene for zero-shot læring er modeller som er trent på klasser som er nært relatert til den nye klassen du vil at modellen skal identifisere.
- Usett/Ny klasse: Data som aldri ble brukt til å trene modellen. Disse dataene må du samle selv, da de ikke er tilgjengelige fra modellen.
- Semantiske/hjelpedata: Ekstra databiter som kan hjelpe modellen med å identifisere den nye klassen. Dette kan være i form av ord, fraser, ordinnbygginger eller klassenavn.
2. Semantisk kartlegging
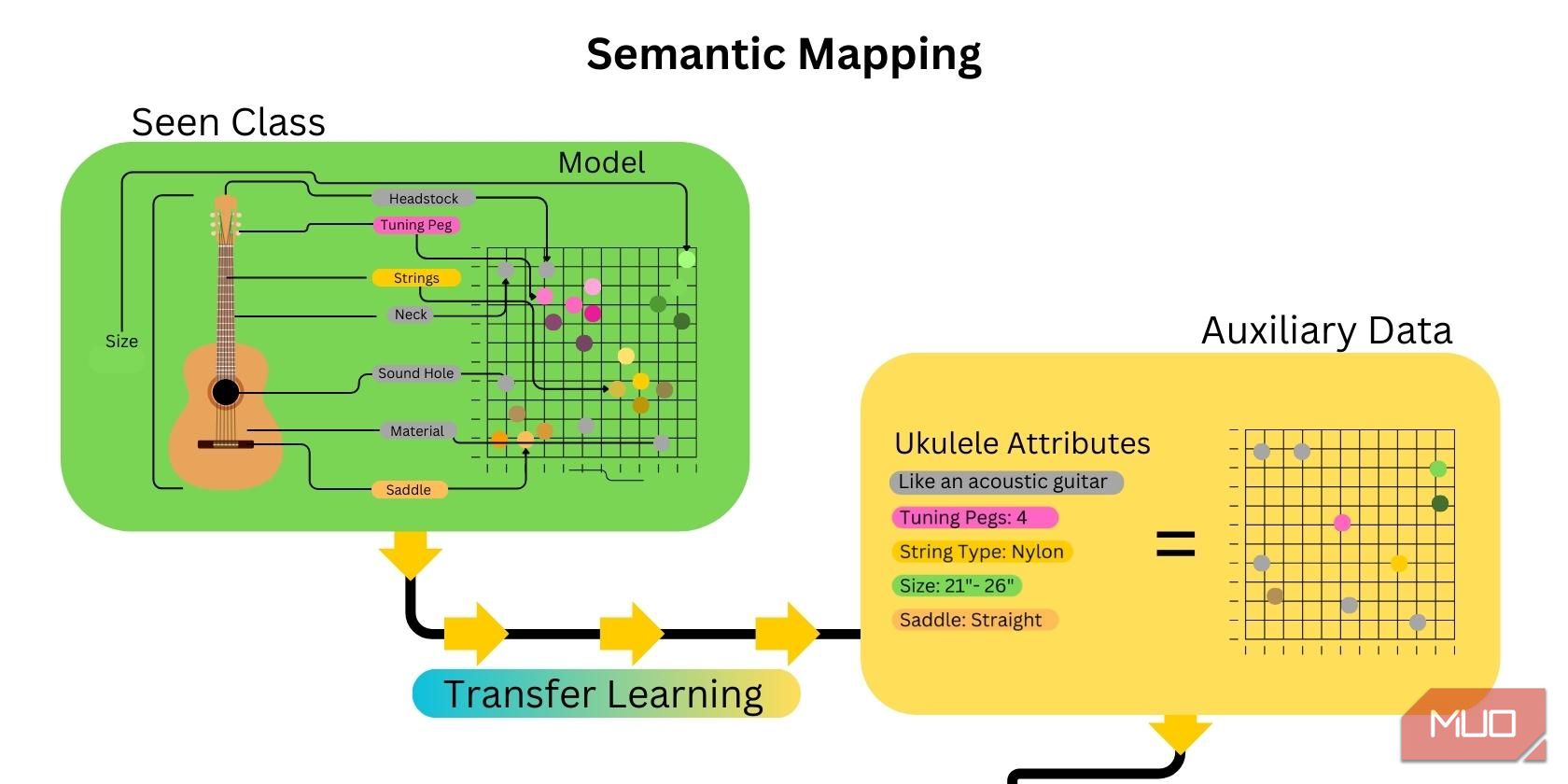
Det neste trinnet innebærer å kartlegge funksjonene til den usette klassen. Dette gjøres ved å lage ordinnbygginger og generere et semantisk kart som kobler attributtene eller egenskapene til den usette klassen til hjelpedataene som er gitt. Overføringslæring innen kunstig intelligens gjør prosessen mye raskere, siden mange attributter som er relatert til den usette klassen allerede er kartlagt.
3. Inferens
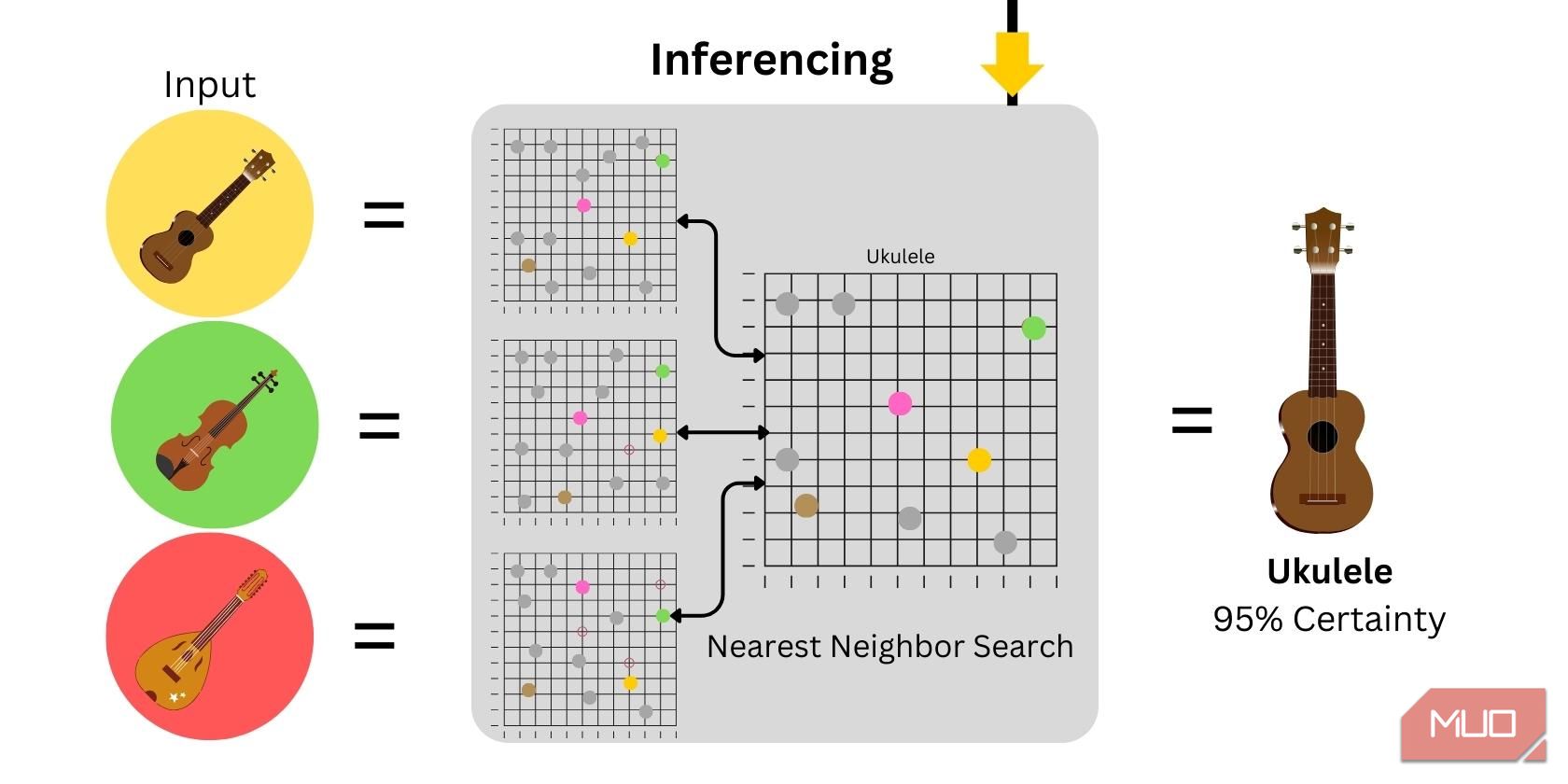
Inferens er bruken av modellen til å generere forutsigelser eller resultater. I zero-shot bildeklassifisering genereres ordinnbygginger fra bildeinndata, som deretter plottes og sammenlignes med hjelpedataene. Sikkerhetsnivået vil avhenge av likheten mellom inndataene og de gitte hjelpedataene.
Hvordan Zero-Shot Læring Forbedrer Kunstig Intelligens
Zero-shot læring forbedrer AI-modeller ved å møte flere utfordringer innen maskinlæring, inkludert:
- Forbedret generalisering: Ved å redusere avhengigheten av merkede data kan modellene trenes på større datasett, noe som forbedrer generalisering og gjør modellene mer robuste og pålitelige. Etter hvert som modellene blir mer erfarne og generaliserte, kan det til og med bli mulig for dem å utvikle sunn fornuft i stedet for bare å analysere informasjon på tradisjonelt vis.
- Skalerbarhet: Modeller kan kontinuerlig trenes og tilegne seg mer kunnskap gjennom overføringslæring. Bedrifter og uavhengige forskere kan kontinuerlig forbedre modellene sine, slik at de blir mer effektive i fremtiden.
- Redusert fare for overtilpasning: Overtilpasning kan oppstå som følge av at en modell trenes på et begrenset datasett som ikke inneholder nok variasjon til å representere alle mulige inndata. Å trene modellen gjennom zero-shot læring reduserer risikoen for overtilpasning ved å trene modellen til å utvikle en bedre kontekstuell forståelse av emner.
- Kostnadseffektivt: Det kan kreve mye tid og ressurser å samle inn store mengder merkede data. Ved å benytte seg av zero-shot overføringslæring, kan en robust modell utvikles med mindre tid og behov for merkede data.
I takt med utviklingen av kunstig intelligens vil teknikker som zero-shot læring bli enda viktigere.
Fremtiden for Zero-Shot Læring
Zero-shot læring har blitt en viktig del av maskinlæring. Det gjør det mulig for modeller å gjenkjenne og klassifisere nye klasser uten eksplisitt trening. Med kontinuerlig utvikling innen modellarkitekturer, attributtbaserte tilnærminger og multimodal integrasjon, kan zero-shot læring i betydelig grad bidra til at modeller blir mer tilpasningsdyktige når det gjelder å håndtere komplekse utfordringer innen robotikk, helsevesen og datasyn.