Om du har kjennskap til programmering, har du sannsynligvis støtt på begrepet tekstparsing. Dette er en prosess som forenkler komplekse dataverdier i en fil. Denne artikkelen veileder deg i hvordan du kan analysere tekst ved hjelp av ulike programmeringsspråk. I tillegg gir den informasjon om hvordan du kan løse feil som kan oppstå under tekstparsing, spesielt relatert til feilmeldingen «parse tekst x».

Tekstanalyse: En praktisk guide
Denne artikkelen gir en fullstendig veiledning i hvordan du analyserer tekst på forskjellige måter, inkludert en kort introduksjon til selve konseptet.
Hva innebærer tekstparsing?
Før du dykker ned i de tekniske aspektene ved tekstparsing, er det viktig å forstå de grunnleggende prinsippene for programmering og koding.
Naturlig Språkbehandling (NLP)
Tekstanalyse er ofte avhengig av Naturlig Språkbehandling (NLP), som er et underfelt av kunstig intelligens. Programmeringsspråk som Python, brukes ofte til dette formålet.
NLP-koder gjør det mulig for datamaskiner å forstå og bearbeide menneskelig språk, noe som er nyttig i en rekke applikasjoner. For å bruke maskinlæringsteknikker på språk, må ustrukturerte tekstdata omformes til strukturerte tabelldata. Python er et populært valg for å endre programkoder for å gjennomføre denne analyseprosessen.
Definisjon av tekstparsing
Tekstparsing handler om å konvertere data fra ett format til et annet. Det opprinnelige formatet til en fil analyseres og konverteres til et nytt format for å gjøre det mulig å bruke dataene i forskjellige applikasjoner.
- Med andre ord innebærer prosessen å analysere en tekststreng og transformere den til logiske komponenter ved å endre filformatet.
- Python har spesifikke regler som brukes for å gjennomføre denne vanlige programmeringsoppgaven. Når tekst analyseres, brytes en gitt tekstserie ned i mindre enheter.
Hvorfor er tekstanalyse nødvendig?
Det finnes flere grunner til hvorfor tekstanalyse er nødvendig, og denne kunnskapen er grunnleggende før du lærer å analysere tekst:
- Data i datamaskiner foreligger ikke alltid i samme format, og formatet kan variere mellom ulike applikasjoner.
- Ulike applikasjoner krever forskjellige dataformater, og inkompatibel kode kan føre til feil.
- Det finnes ikke ett universelt dataprogram som kan håndtere alle dataformater.
Metode 1: Bruk av DataFrame-klassen
DataFrame-klassen i Python har alle nødvendige funksjoner for å analysere tekst. Dette innebygde biblioteket inneholder de nødvendige kodene for å konvertere data fra ett format til et annet.
Kort introduksjon til DataFrame-klassen
DataFrame-klassen er en funksjonsrik datastruktur som brukes som et dataanalyseverktøy. Det er et kraftig verktøy som muliggjør dataanalyse med minimal innsats.
- Koden leses inn i pandas DataFrame for å utføre analysen i Python.
- Klassen inneholder mange pakker levert av pandas, som brukes av dataanalytikere i Python.
- Funksjonen til denne klassen er en abstraksjon, hvor den interne funksjonaliteten er skjult for brukeren av NumPy-biblioteket. NumPy er et Python-bibliotek som inneholder kommandoer og funksjoner for å jobbe med matriser.
- DataFrame-klassen kan brukes til å representere en todimensjonal matrise med flere rad- og kolonneindekser. Disse indeksene hjelper med å lagre flerdimensjonale data, og kalles derfor MultiIndex. Disse må endres for å løse parsefeil.
Python-biblioteket pandas hjelper til med å utføre SQL- eller database-operasjoner med stor nøyaktighet for å unngå feil under tekstparsing. Det inneholder også IO-verktøy som hjelper til med å analysere filer i formater som CSV, MS Excel, JSON, HDF5 og andre dataformater.
Slik analyserer du tekst ved hjelp av DataFrame-klassen
For å analysere tekst, kan du følge denne standardprosessen ved bruk av DataFrame-klassen:
- Finn ut dataformatet til inndataene.
- Bestem dataformatet for utdataene, for eksempel CSV (kommaseparerte verdier).
- Skriv koden med en primitiv datatype som en liste eller et dictionary.
Merk: Det kan være kjedelig og komplisert å skrive koden direkte i en tom DataFrame. Pandas tillater å lage data på DataFrame-klassen fra disse datatypene. Dermed kan data i den primitive datatypen enkelt analyseres til det ønskede dataformatet.
- Analyser dataene ved hjelp av dataanalyseverktøyet pandas DataFrame, og vis resultatet.
Alternativ I: Standardformat
Standardmetoden for å formatere en fil med et spesifikt dataformat som CSV, forklares her:
- Lagre filen med dataverdiene lokalt på datamaskinen. Du kan for eksempel kalle filen data.txt.
- Importer filen til pandas med et spesifikt navn, og overfør dataene til en annen variabel. For eksempel, pandas-biblioteket importeres som «pd» i koden.
- Importen må inkludere en komplett kode med detaljene i inndatafilnavnet, funksjonen og inndatafilformatet.
Merk: Her brukes variabelen «res» til å lese dataene i filen «data.txt» ved hjelp av pandas-biblioteket som er importert som «pd». Dataformatet til inndatateksten er spesifisert som CSV.
- Kall den navngitte filtypen, og vis den analyserte teksten. For eksempel vil kommandoen «res» etter kjøring av koden vise den analyserte teksten.
Et kodeeksempel for prosessen forklart ovenfor er gitt nedenfor for å illustrere tekstanalyse:
import pandas as pd res = pd.read_csv(‘data.txt’) res
I dette tilfellet, hvis du skriver inn dataverdiene [1,2,3] i filen «data.txt», vil de bli analysert og vist som 1 2 3.
Alternativ II: Strengmetode
Hvis teksten kun inneholder strenger eller alfanumeriske tegn, kan spesialtegn i strengen (som komma, mellomrom osv.) brukes til å skille og analysere teksten. Prosessen ligner på vanlige strengoperasjoner. For å unngå feil i tekstparsing, må du følge denne prosessen nøye.
- Dataene hentes ut fra strengen, og alle spesialtegn som skiller teksten, noteres.
For eksempel, i koden nedenfor, identifiseres spesialtegnene i strengen «min_streng» som «,» og «:». Denne prosessen må gjøres nøyaktig for å unngå feil.
- Teksten i strengen deles individuelt basert på plasseringen og verdien av spesialtegnene.
For eksempel, blir strengen delt inn i tekstdataverdier basert på spesialtegnene ved hjelp av «split»-kommandoen.
- Dataverdiene i strengen vises alene som den analyserte teksten. Her brukes «print»-setningen for å skrive ut den analyserte dataverdien.
Kodeeksempelet for denne prosessen er gitt nedenfor:
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
I dette tilfellet vil resultatet av den analyserte strengen vises som:
Names: [‘Tech’, ‘computer’]
For å øke forståelsen og vise hvordan man analyserer tekst ved bruk av strengtekst, kan en «for»-løkke brukes, og koden endres som følger:
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
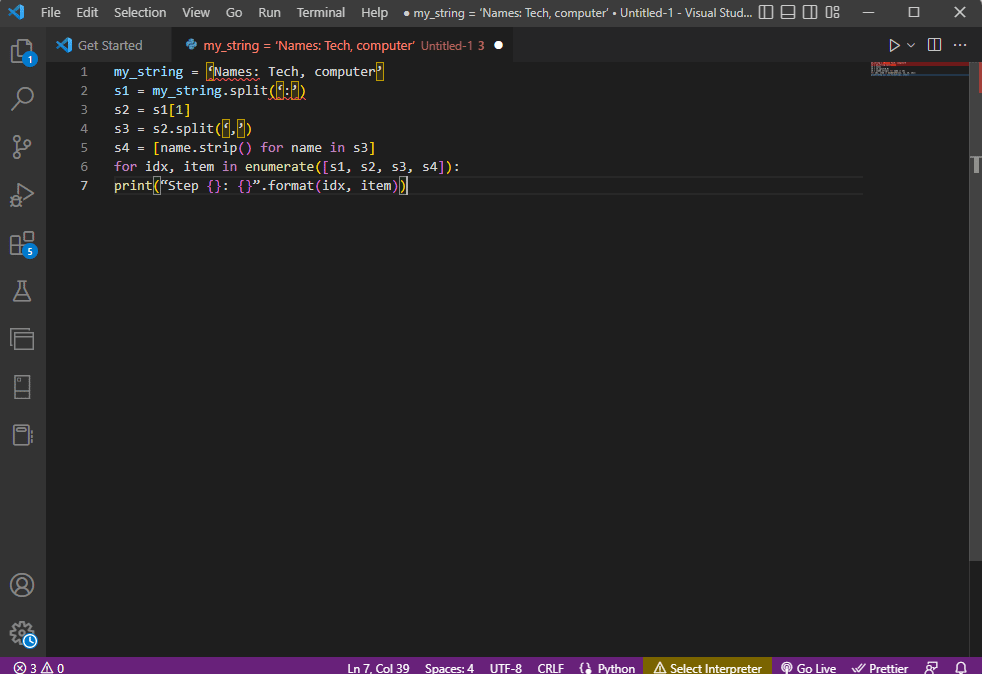
Resultatet av den analyserte teksten for hvert trinn er som følger. Legg merke til at i trinn 0 er strengen separert basert på spesialtegnet «:», og tekstdataverdiene separeres videre basert på dette tegnet i de etterfølgende trinnene:
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Alternativ III: Analyse av kompleks fil
I de fleste tilfeller inneholder dataene som skal analyseres ulike datatyper og -verdier. I slike tilfeller kan det være vanskelig å analysere filen ved hjelp av de tidligere metodene.
Målet med å analysere de komplekse dataene i filen er å vise dataverdiene i et tabellformat:
- Tittelen eller metadataene til verdiene vises øverst i filen.
- Variablene og feltene vises i en tabell.
- Dataverdiene utgjør en sammensatt nøkkel.
Før du lærer hvordan du analyserer tekst i denne metoden, er det nødvendig å forstå noen grunnleggende konsepter. Parsing av dataverdiene gjøres basert på regulære uttrykk eller Regex.
Regex-mønstre
For å unngå feil ved tekstparsing, må regex-mønstrene i uttrykkene være korrekte. Koden for å analysere strengdataverdiene inkluderer vanlige Regex-mønstre som beskrevet nedenfor:
-
“d”: samsvarer med desimaltall i strengen.
-
“s”: samsvarer med mellomrom.
-
“w”: samsvarer med alfanumeriske tegn.
-
“+” eller “*”: utfører en grådig match ved å matche ett eller flere tegn i strengen.
-
“a-z”: samsvarer med små bokstaver.
-
“A-Z” eller “a-z”: samsvarer med grupper av store og små bokstaver.
-
“0-9”: samsvarer med numeriske verdier.
Regulære uttrykk
Regulære uttrykksmoduler er en viktig del av pandas-pakken i Python, og feil i Regex kan føre til feil i tekstparsing. Regex er et lite språk innebygd i Python for å finne strengmønstre. Regulære uttrykk er strenger med en spesiell syntaks som gjør det mulig å matche mønstre i andre strenger basert på verdiene.
Regex opprettes basert på datatypen og kravene til uttrykket i strengen, for eksempel «String = (.*)n». Regex brukes før mønsteret i hvert uttrykk. Symbolene som brukes i regulære uttrykk, er opplistet nedenfor og vil hjelpe deg med å forstå tekstparsing:
-
. : for å hente ut et hvilket som helst tegn fra dataene.
-
* : bruk null eller flere data fra det forrige uttrykket.
-
(.*) : for å gruppere en del av det regulære uttrykket innenfor parentes.
-
n : lag et nytt linjetegn på slutten av linjen i koden.
-
d : lag en kort heltallsverdi i området 0 til 9.
-
+ : bruk en eller flere data fra det forrige uttrykket.
-
| : lag et logisk utsagn, brukt for «eller»-uttrykk.
RegexObjects
RegexObject er returverdien for kompileringfunksjonen, og brukes for å returnere et MatchObject dersom uttrykket samsvarer med de angitte verdiene.
1. MatchObject
Siden den boolske verdien til et MatchObject alltid er True, kan du bruke en «if»-setning for å identifisere de positive samsvarene i objektet. Ved bruk av «if»-setningen brukes gruppen som det refereres til av indeksen for å finne samsvaret i uttrykket.
-
group() returnerer en eller flere undergrupper av samsvar.
-
group(0) returnerer hele samsvaret.
-
group(1) returnerer den første undergruppen innenfor parenteser.
- Når det refereres til flere grupper, må en Python-spesifikk utvidelse brukes. Denne utvidelsen brukes for å spesifisere navnet på gruppen der treffet skal finnes. Den spesifikke utvidelsen er gitt i gruppen i parentes. For eksempel vil uttrykket (?P<gruppe1>regex1) referere til den spesifikke gruppen med navnet «gruppe1», og lete etter samsvar i det regulære uttrykket, «regex1». For å rette feil i tekstparsing, må du sjekke at gruppen peker riktig.
2. Metoder for MatchObject
Når du finner ut hvordan du analyserer tekst, er det viktig å vite at MatchObject har to grunnleggende metoder. Hvis et MatchObject finnes i det spesifiserte uttrykket, returnerer metoden objektet, ellers returneres verdien «None».
- Metoden «match(string)» brukes for å finne strengsamsvar i begynnelsen av det regulære uttrykket.
- Metoden «search(string)» brukes til å skanne gjennom strengen for å finne et samsvar i det regulære uttrykket.
Regulære uttrykksfunksjoner
Regex-funksjoner er kodelinjer som brukes til å utføre en bestemt funksjon angitt av brukeren, fra settet med dataverdier som er hentet ut.
Merk: For å skrive funksjoner brukes råstrenger for regulære uttrykk for å unngå feil i tekstparsing. Dette gjøres ved å legge til bokstaven «r» før hvert mønster i uttrykket.
De vanlige funksjonene i uttrykkene er forklart nedenfor:
1. re.findall()
Denne funksjonen returnerer alle mønstrene i strengen dersom et samsvar er funnet. Hvis det ikke finnes noe samsvar, returneres en tom liste. For eksempel vil funksjonen string = re.findall(«[aeiou]», regex_filename) brukes til å finne vokalforekomster i filnavnet.
2. re.split()
Denne funksjonen brukes til å dele strengen dersom det oppdages et samsvar med et tegn, for eksempel et mellomrom. Hvis det ikke finnes noe samsvar, returnerer den en tom streng.
3. re.sub()
Funksjonen erstatter den matchede teksten med innholdet i den gitte erstatningsvariabelen. I motsetning til andre funksjoner returneres den opprinnelige strengen dersom det ikke finnes noe mønster.
4. re.search()
En av de grunnleggende funksjonene som hjelper deg med å lære tekstanalyse, er søkefunksjonen. Den søker etter mønsteret i strengen og returnerer matchobjektet. Hvis søket mislykkes i å identifisere et samsvar, returneres verdien «None».
5. re.compile(pattern)
Denne funksjonen brukes til å kompilere regulære uttrykksmønstre til et RegexObject, som beskrevet tidligere.
Andre krav
De følgende kravene er en tilleggsfunksjon som brukes av avanserte programmerere for dataanalyse:
- «regexper» brukes for å visualisere regulære uttrykk.
- «regex101» brukes for å teste regulære uttrykk.
Prosess for tekstparsing
Metoden for å analysere tekst i dette komplekse alternativet beskrives som følger:
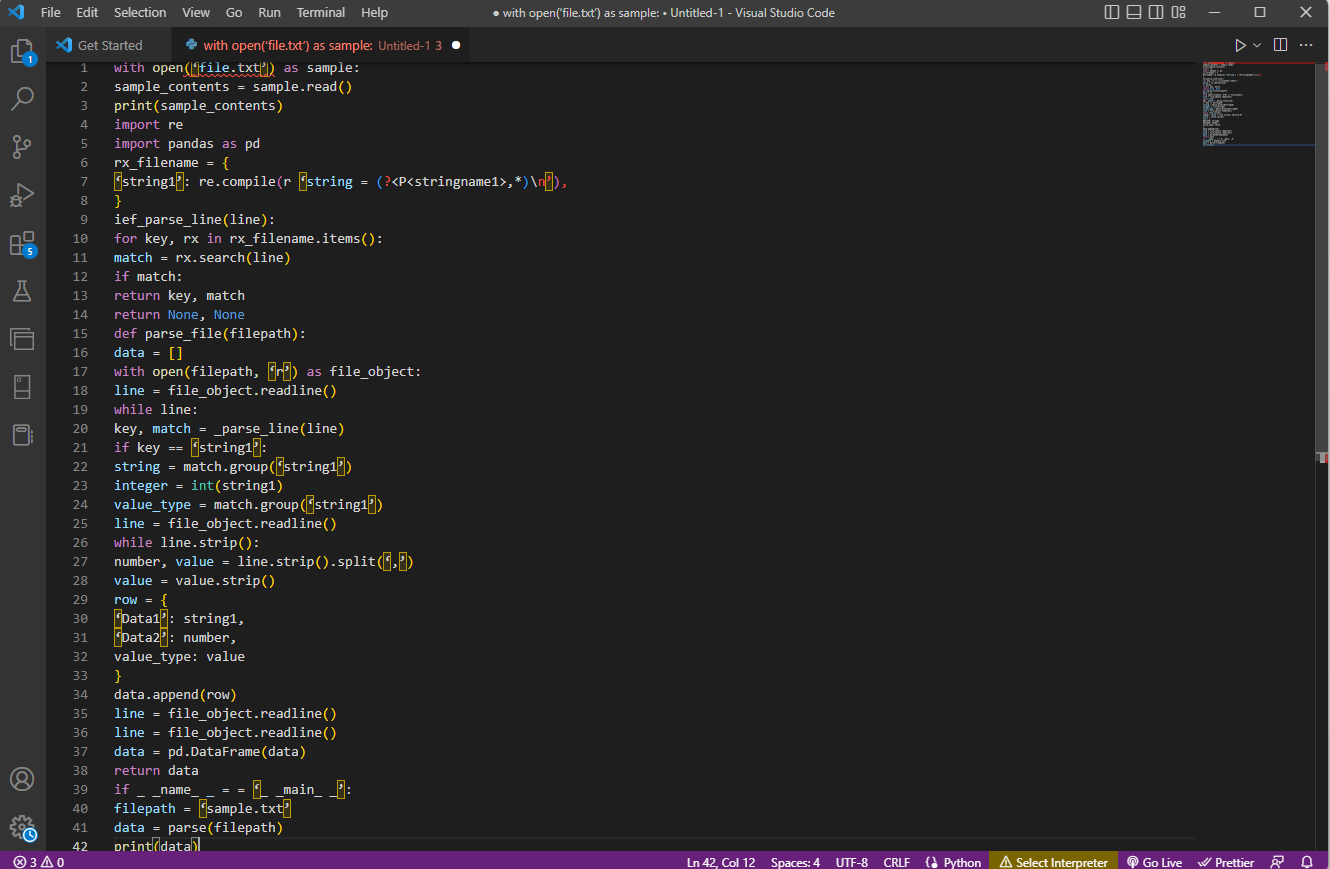
- Det første trinnet er å forstå inndataformatet ved å lese innholdet i filen. Funksjonene «with open» og «read()» brukes for å åpne og lese innholdet i en fil, for eksempel «sample.txt». For å unngå feil i tekstanalyse, må filen leses fullstendig.
- Innholdet i filen skrives ut for å analysere dataene manuelt og for å finne metadataene til verdiene. «print()»-funksjonen brukes for å vise innholdet i filen.
- De nødvendige datapakkene for å analysere teksten importeres til koden, og et navn gis til klassen for videre koding. Her importeres regulære uttrykk og pandas.
- De regulære uttrykkene som kreves for koden, defineres i filen ved å inkludere regex-mønsteret og -funksjonen. Dette gjør at tekstobjektet kan bruke koden for dataanalyse.
- For å analysere tekst, kan du referere til kodeeksemplet. «Compile()»-funksjonen brukes for å kompilere strengen fra gruppen «stringname1» til filnavnet. Funksjonen for å lete etter treff i regex brukes av kommandoen «ief_parse_line(line)».
- En linjeparser for koden skrives ved å bruke «def_parse_file(filepath)», der den definerte funksjonen sjekker alle regex-treffene. Her leter «regex search()»-metoden etter nøkkelen «rx» i filnavnet, og returnerer nøkkelen og treffet fra den første samsvarende regex. Eventuelle problemer i dette trinnet kan føre til feil i tekstparsing.
- Neste trinn er å skrive en filparser ved bruk av filparser-funksjonen, som er «def_parse_file(filbane)». En tom liste opprettes for å samle inn data, «data = []». Samsvaret sjekkes på hver linje med «match = _parse_line(line)», og de faktiske dataverdiene returneres basert på datatypen.
- For å hente ut tall og verdier i tabellen, brukes kommandoen «line.strip().split(«,»)». Kommandoen «row{}» brukes for å lage en dictionary med datalinjen. Kommandoen «data.append(row)» brukes for å forstå dataene og analysere dem til et tabellformat.
Kommandoen «data = pd.DataFrame(data)» brukes for å lage en pandas DataFrame fra dictionary-verdiene. Alternativt kan du bruke følgende kommandoer for de respektive formålene som vist nedenfor:
-
data.sett_indeks([«string», «integer»]inplace=True) for å angi indeksen til tabellen.
-
data = data.groupby(level=data.index.names).first() for å konsolidere og fjerne NaN-verdier.
-
data = data.apply(pd.to_numeric, errors=’ignore») for å konvertere score fra flyttall til heltall.
Siste trinn for å lære hvordan man analyserer tekst, er å teste parseren ved hjelp av en «if»-setning. Tilordne verdiene til en variabel «data», og vis dem med kommandoen «print(data)».
Et eksempel på koden for denne forklaringen er gitt her:
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ == ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Metode 2: Bruk av Word Tokenization
Prosessen med å konvertere en tekst eller et korpus til mindre deler (tokens) basert på visse regler, kalles tokenisering. For å kunne unngå feil i tekstparsing, er det viktig å analysere tokeniseringskommandoene i koden. På samme måte som med regex, kan egne regler opprettes i denne metoden. Tokenisering hjelper til med tekstforbehandling, for eksempel for å kartlegge ordklasser. Aktiviteter som å finne og matche vanlige ord, rense tekst og forberede dataene for avansert tekstanalyseteknikk som sentimentanalyse, utføres med denne metoden. Hvis tokeniseringen er feil, kan det oppstå feil i tekstanalyse.
Ntlk-bibliotek
Denne prosessen bruker biblioteket Natural Language Toolkit (nltk) som har et rikt utvalg av funksjoner for NLP-oppgaver. Disse kan lastes ned gjennom Pip-installasjon. For å lære tekstanalyse, kan du bruke basissversjonen av Anaconda-distribusjonen som inkluderer biblioteket som standard.
Typer tokenisering
Vanlige typer tokenisering er ordtokenisering og setningstokenisering. Ordtokenisering tar utgangspunkt i symboler på ordnivå, der hvert ord vises én gang. Setningstokenisering tar for seg setninger i stedet for enkeltord.
Prosessen for å analysere tekst
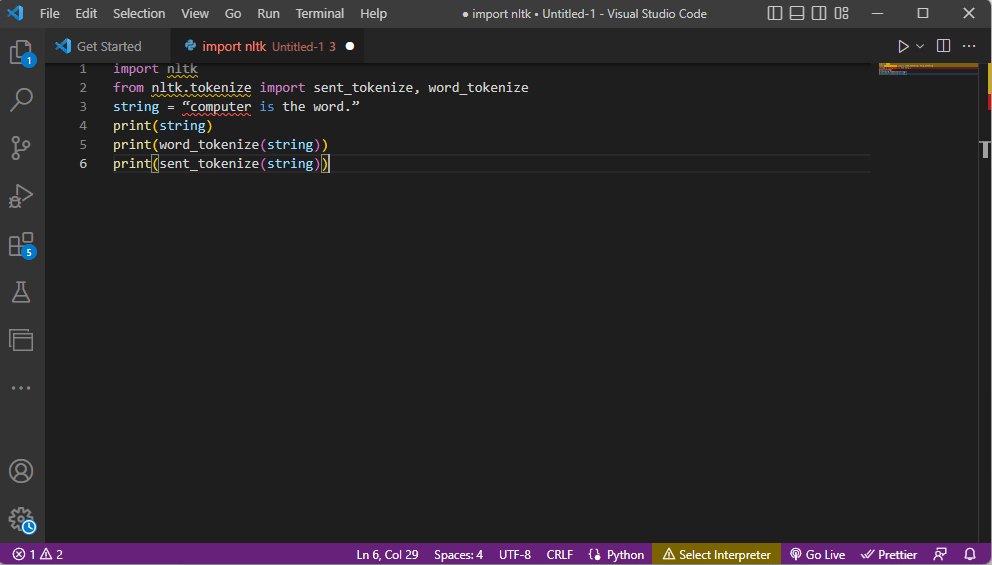
- Nltk-biblioteket importeres, og tokeniseringsskjemaene importeres fra biblioteket.
- En streng blir definert, og kommandoene for tokenisering utføres.
- Når strengen skrives ut, vil resultatet være «computer is the word».
- Når det gjelder ordtokenisering eller «word_tokenize()», skrives hvert ord i setningen ut individuelt i anførselstegn, og er atskilt med komma. Resultatet av kommandoen vil være «’computer’», «’is’», «’the’», «’word’», «’.’».
- Ved setningstokenisering eller «sent_tokenize()», plasseres de individuelle setningene innenfor anførselstegn, og repetisjon av ord er tillatt. Resultatet vil være «’computer is the word.’».
Koden som forklarer trinnene ovenfor er gitt her:
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Metode 3: Bruk av DocParser-klassen
I likhet med DataFrame-klassen, kan DocParser-klassen brukes til å analysere tekst i koden. Denne klassen lar deg kalle parse-funksjonen med en filbane.
Prosessen for tekstparsing
Følg disse instruksjonene for å analysere tekst ved hjelp av DocParser-klassen:
- Funksjonen «get_format(filename)» brukes for å hente ut filtypen, sende den til en variabel for funksjonen, og sende den videre til neste funksjon. For eksempel vil «p1 = get_format(filename)» hente ut filtypen, sette den til variabelen «p1» og sende den videre.
- En logisk struktur med andre funksjoner er konstruert ved hjelp av «if-elif-else»-setninger.
- Hvis filtypen er gyldig og strukturen er logisk, brukes «get_parser»-funksjonen for å analysere data i filbanen og returnere strengobjektet til brukeren.
Merk: Denne funksjonen må implementeres riktig for å unngå feil i tekstparsing.
- Parsing av dataverdiene gjøres basert på filtypen. Den konkrete implementeringen av klassen, som for eksempel «parse_txt» eller «parse_docx», brukes for å generere strengobjekter fra deler av den gitte filtypen.
- Parsing kan også gjøres for filer med andre lesbare filendelser som «parse_pdf», «parse_html» og «parse_pptx».
- Dataverdiene og grensesnittet kan importeres til andre applikasjoner ved hjelp av importsetninger og instansiere et DocParser-objekt. Dette kan gjøres ved å analysere filer i Python, for eksempel parse_file.py. Denne operasjonen må utføres nøye for å unngå feil i tekstparsing.
Metode 4: Bruk av verktøyet Parse Text Tool
Tekstverktøyet Parse brukes for å hente ut spesifikke data fra variabler og tilordne dem til andre variabler. Verktøyet er uavhengig av andre verktøy i en oppgave, og BPA-plattformverktøyet brukes for å bruke og generere variabler. Følg denne lenken for å få tilgang til Parse Text Tool online og bruk informasjonen om hvordan du analyserer tekst som er gitt tidligere i artikkelen.
Metode 5: Bruk av TextFieldParser (Visual Basic)
TextFieldParser-objekter brukes for å analysere og behandle store filer som er strukturert og avgrenset. Metoden kan brukes for bredde- og kolonneorientert tekst, for eksempel loggfiler eller eldre databaseinformasjon. Analysen ligner på å iterere kode over en tekstfil, og brukes hovedsakelig for å hente ut tekstfelter som ligner på strengmanipuleringsmetoder. Dette gjøres for å tokenisere avgrensede strenger og felt av ulike bredder ved bruk av et definert skilletegn som komma eller tabulator.
Funksjoner for tekstparsing
Følgende funksjoner kan brukes for å analysere tekst i denne metoden:
- «SetDelimiters» brukes for å definere et skilletegn. For eksempel vil kommandoen «testReader.SetDelimiters (vbTab)» angi en tabulator som skilletegn.
- For å angi en fast feltbredde til en positiv heltallsverdi for tekstfiler, kan du bruke kommandoen «testReader.SetFieldWidths (integer)».
- For å teste felttypen, kan du bruke følgende kommando: «testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth».
Metoder for å finne MatchObject
Det finnes to grunnleggende metoder for å finne MatchObject i koden eller den analyserte teksten:
- Den første metoden er å definere formatet og gå gjennom filen ved hjelp av «ReadFields»-metoden. Denne metoden vil hjelpe til med å behandle hver linje i koden.
- «PeekChars»-metoden brukes for å sjekke hvert felt individuelt før lesing, definere flere formater og reagere.
I begge tilfeller, dersom et felt ikke samsvarer med det spesifiserte formatet mens du utfører parsing, returneres unntaket «MalformedLineException».
Ekspert-tips: Hvordan analysere tekst i MS Excel
Som en enkel metode for å analysere tekst, kan du bruke MS Excel for å lage tabulator- eller kommaseparerte filer. Dette kan hjelpe deg med å kryssjekke resultatet og unngå feil i tekstparsing.
1. Velg dataverdiene i kildefilen, og trykk Ctrl + C for å kopiere filen.
2. Åpne Excel ved å bruke søkefeltet i Windows.
<img class=»alignnone wp-image-136836″ width=»600″ height=»48