Grunnleggende om Dataklassifisering
Dataklassifisering er en prosess der virksomheter organiserer og merker data ut fra deres følsomhet, verdi og mulige konsekvenser hvis de skulle bli kompromittert.
Gjennom dataklassifisering kan selskaper etablere passende sikkerhetsmetoder og kontroller for å beskytte informasjonen og sikre samsvar med relevante regler og standarder.
Det er essensielt å ha en god forståelse av de ulike typene data man besitter, samt hvordan de blir brukt. Dette hjelper med å bestemme det nødvendige beskyttelsesnivået.
La oss utforske hva dataklassifisering innebærer og hvorfor det er viktig å klassifisere data.
Hva er Dataklassifisering?
Dataklassifisering er metoden for å organisere informasjon i kategorier eller klasser basert på spesifikke egenskaper eller attributter. De nøyaktige kriteriene som benyttes for klassifiseringen, kan variere avhengig av virksomhetens behov og mål.
Hovedformålet med dataklassifisering er å gjøre informasjonen mer strukturert og brukervennlig, samtidig som den beskyttes mot uautorisert tilgang eller eksponering.
Ved å klassifisere data, er det mulig å identifisere de forskjellige datatypene som er relevante for en organisasjon og tilordne passende merkelapper eller tagger til dem. Dette kan være fordelaktig for datahåndtering, sikkerhet og personvern.
Dataklassifisering kan utføres manuelt eller med hjelp av automatiserte verktøy, avhengig av størrelsen og kompleksiteten til datasettet.
Det finnes flere grunner til hvorfor dataklassifisering er nødvendig:
- Dataorganisering: Dataklassifisering bidrar til å organisere og strukturere data på en meningsfull måte, noe som forenkler forståelse og analyse.
- Forbedret Beslutningstaking: Ved å kategorisere data, er det mulig å få innsikt og ta mer informerte beslutninger basert på dataenes egenskaper.
- Forbedret Sikkerhet: Dataklassifisering kan brukes til å beskytte sensitiv informasjon ved å kategorisere den som konfidensiell, offentlig eller begrenset. Dette hjelper med å sikre at riktig sikkerhetsnivå blir brukt på dataene.
- Økt Effektivitet: Ved å kategorisere data, er det enklere å lokalisere og hente spesifikke opplysninger ved behov. Dette kan øke effektiviteten og redusere tiden og innsatsen som kreves for å finne og bruke data.
- Forbedret Nøyaktighet: Klassifisering av data kan bidra til å forbedre nøyaktigheten til maskinlæringsmodeller ved å sikre at modellen er trent på relevante og passende data.
Hvordan Forbedrer Dataklassifisering Sikkerheten?
Dataklassifisering kan være en effektiv strategi for å styrke datasikkerheten ved å identifisere og beskytte følsomme eller konfidensielle data. Her er noen måter dataklassifisering kan brukes for å forbedre datasikkerheten:
- Identifiser Følsomme Data: Ved å klassifisere data etter sensitivitetsnivå, kan virksomheter identifisere den informasjonen som krever høyeste beskyttelse. Dette hjelper med å prioritere sikkerhetstiltak og tildele ressurser til de mest kritiske områdene.
- Beskytt Konfidensielle Data: Ved å tildele passende klassifikasjonsmerker til konfidensiell informasjon, kan organisasjoner sikre at denne informasjonen kun er tilgjengelig for autoriserte personer. Dette reduserer risikoen for uautorisert tilgang eller deling av sensitiv informasjon.
- Implementer Kontroller: Basert på dataklassifisering kan organisasjoner iverksette passende sikkerhetskontroller for å beskytte dataene. For eksempel kan sensitive data kreve sterkere autentisering eller ekstra kryptering.
- Forbedre Datahåndtering: Ved å etablere klare retningslinjer og prosedyrer for dataklassifisering, kan virksomheter forbedre datahåndteringen og sikre at data blir behandlet konsekvent og sikkert.
- Overvåk og Revider Datatilgang: Ved å overvåke og revidere datatilgang, kan organisasjoner spore hvem som har tilgang til klassifiserte data og forsikre seg om at de har riktig tilgang. Dette bidrar til å oppdage uautorisert tilgang eller misbruk av data.
Typer Dataklassifisering
For å organisere og håndtere data på en korrekt måte, kan data merkes eller klassifiseres basert på ulike egenskaper. Her er fire vanlige metoder som brukes for å sortere rådata før man bestemmer klassifiseringen:

Brukerbasert klassifisering: Innebærer å tildele data til kategorier basert på brukerens rolle eller ansvar i en organisasjon. For eksempel kan en ansattes tilgang til data være begrenset basert på jobbfunksjon eller sikkerhetsklarering.
Innholdsbasert klassifisering: Organiserer data basert på det faktiske innholdet. Dette kan inkludere tema, format eller andre spesifikke egenskaper ved dataene.
Automatisert klassifisering: Benytter programvare eller algoritmer for å analysere og kategorisere data basert på forhåndsbestemte kriterier. Dette kan være basert på innhold i selve dataene, som nøkkelord eller mønstre, eller metadata som filnavn eller plassering.
Kontekstbasert klassifisering: Innebærer å kategorisere data basert på konteksten de brukes i, eller formålet de ble opprettet for.
Dataklassifiserings Sensitivitetsnivåer
Ulike typer data krever vanligvis forskjellige nivåer av klassifisering. Du kan kategorisere dataene dine mer nøyaktig ved å vurdere disse nivåene. Det er hovedsakelig fire sensitivitetsnivåer innen dataklassifisering:
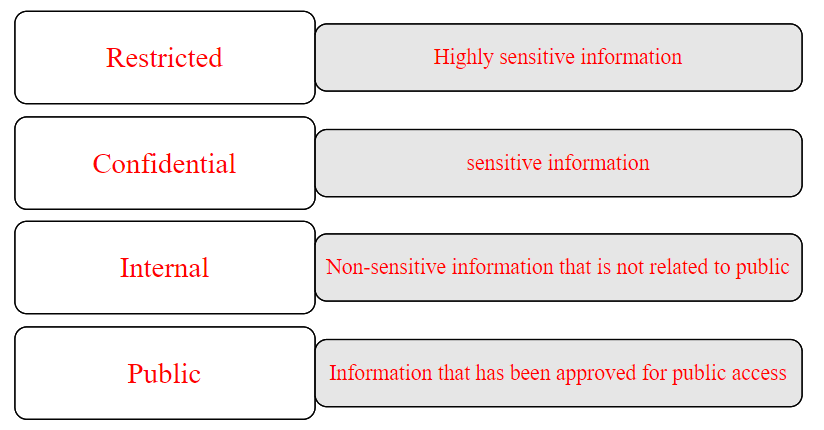
Offentlige: Offentlige data er tilgjengelig for allmennheten og kan brukes av alle. Dette kan inkludere data samlet inn av offentlige etater, ideelle organisasjoner eller private selskaper som er tilgjengelige for offentlig bruk.
Interne: Interne data er data som samles inn og brukes innenfor en organisasjon eller et selskap. Denne typen data deles vanligvis ikke med offentligheten, og brukes til formål som beslutningstaking, planlegging og analyse. Slike data lagres og administreres ofte i organisasjonens interne systemer, og er kun tilgjengelige for autoriserte personer i organisasjonen.
Konfidensielle: Konfidensielle data er informasjon som er ment å holdes hemmelig eller privat innenfor en organisasjon. Denne typen data deles vanligvis ikke med noen utenfor organisasjonen og kan være underlagt spesifikke sikkerhetstiltak for å beskytte konfidensialiteten.
Begrensede: Denne typen data er svært sensitive og krever det høyeste beskyttelsesnivået. Et datainnbrudd på dette nivået kan ha alvorlige konsekvenser for en virksomhet, og kan til og med true nasjonal sikkerhet. Eksempler inkluderer personopplysninger, juridiske dokumenter og forretningshemmeligheter.
Trinn i Dataklassifisering
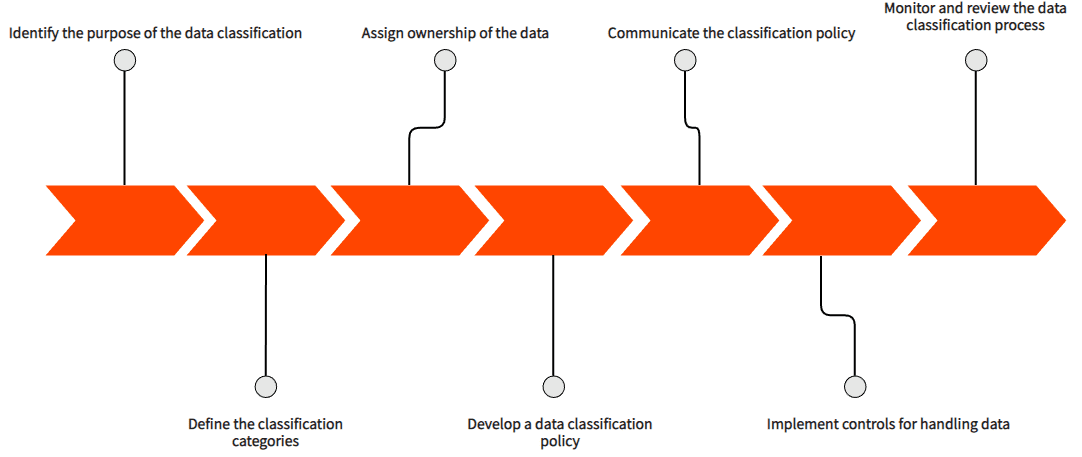
Det er flere trinn involvert i dataklassifiseringsprosessen:
- Identifiser formålet med dataklassifiseringen: Det er viktig å forstå motivasjonen bak klassifiseringen og målene som skal oppnås. Dette kan være for å sikre overholdelse av reguleringer, beskytte sensitiv informasjon eller forbedre datahåndteringsprosesser.
- Definer klassifiseringskategoriene: Bestem kategoriene som data skal klassifiseres i, for eksempel offentlig, konfidensiell eller begrenset. Det er essensielt å tydelig definere egenskapene til hver kategori, og hvilke typer data som skal plasseres i hver kategori.
- Tildel eierskap til dataene: Bestem hvem som er ansvarlig for å administrere og beskytte dataene, samt for å ta beslutninger om klassifiseringen. Dette kan være en spesifikk person eller en avdeling i organisasjonen.
- Utvikle en dataklassifiseringspolicy: Lag en klar og konsis policy som beskriver klassifiseringskategoriene, dataeiernes ansvar og prosedyrene for klassifisering og håndtering av data.
- Kommuniser retningslinjene for dataklassifisering: Sikre at alle relevante parter i organisasjonen er klar over retningslinjene for dataklassifisering og sitt tilhørende ansvar. Dette kan inkludere opplæring eller tilgjengeliggjøring av ressurser for ansatte.
- Implementer kontroller for håndtering av data: Etabler prosedyrer og kontroller for håndtering av data basert på deres klassifiseringsnivå. Dette kan innebære tilgangskontroller, kryptering, samt sikkerhetskopiering og gjenoppretting.
- Overvåk og gjennomgå dataklassifiseringsprosessen: Evaluer regelmessig effektiviteten av dataklassifiseringsprosessen for å sikre at den oppfyller organisasjonens mål, og at data blir behandlet korrekt. Gjør justeringer etter behov for å forbedre prosessen.
Beste Praksis for Dataklassifisering

Her er noen anbefalte fremgangsmåter for dataklassifisering:
- Hold det enkelt: Det er viktig å ha et tydelig og enkelt klassifiseringssystem som er lett for ansatte å forstå og følge. Komplekse systemer kan være vanskelige å administrere og er ikke nødvendigvis effektive for å beskytte sensitiv informasjon.
- Klassifiser data ved opprettelse: Data bør klassifiseres så snart de opprettes, istedenfor å vente til de er nødvendig eller åpnes. Dette sikrer at sensitiv informasjon er forsvarlig beskyttet fra begynnelsen av.
- Bruk klare etiketter: Bruk tydelige og konsise etiketter for å identifisere klassifiseringsnivået til data. Dette hjelper ansatte å forstå sensitiviteten og beskyttelsen som kreves for hver enkelt dataenhet.
- Etabler et standard klassifiseringsskjema: Utvikle et standard klassifiseringsskjema som brukes konsekvent i hele organisasjonen. Dette sikrer at data klassifiseres konsistent og nøyaktig.
- Dokumenter klassifiseringen: Før et register over klassifiseringsprosessen, inkludert kategoriene og kriteriene som brukes. Dette gjør det enkelt å forstå og reprodusere klassifiseringen.
Ved å følge disse beste praksisene, kan du sikre at dataene dine er korrekt og effektivt kategorisert. Dette kan forenkle dataadministrasjon og -evaluering.
Læringsressurser for Dataklassifisering
Alle kan lære å designe klassifiseringsmodeller for effektiv datakontroll, med riktig engasjement og innsats. Det finnes flere ressurser tilgjengelige for å lære dataklassifisering. Her er et utvalg av viktige bøker som kan utvide kunnskapen din:
#1. Dataklassifisering: Algoritmer og Applikasjoner
Denne boken gir en innføring i det grunnleggende om dataklassifisering, med fokus på modellutvikling. Den dekker en rekke emner, inkludert ulike algoritmer og teknikker, bruksområder innen forskjellige felt, og anbefalte metoder for å implementere dataklassifisering i praktiske situasjoner.
Boken diskuterer også viktigheten av dataklassifisering og dens fordeler, som forbedret datakvalitet og bedre beslutningsgrunnlag.
#2. Dataklassifisering: En Komplett Veiledning
Denne boken introduserer leserne for metoder og tilnærminger for å definere, designe, skape og implementere en klassifiseringsprosess for å forbedre sikkerhet og effektiv datahåndtering.
I tillegg gir den veiledning i hvordan man tilpasser den nyeste utviklingen innen dataklassifisering og arbeidsflytdesign, i tråd med de beste klassifiseringsstandardene.
#3. Dataklassifisering: En Klar og Konsis Referanse
Denne boken omhandler hovedsakelig de interne og eksterne relasjonene innen dataklassifisering. Den introduserer også ulike nøkkelindikatorer for klassifisering, samt gir et overordnet rammeverk for dataklassifiseringsdesign.
Forkunnskaper kreves for å forstå prinsippene og emnene i denne boken.
Avsluttende Tanker
Dataklassifisering kan være et kraftig verktøy for bedrifter og organisasjoner av alle størrelser. Ved å strukturere og merke data, kan man oppnå en bedre forståelse av informasjonen, identifisere mønstre og trender, og ta mer informerte beslutninger.
I tillegg kan dataklassifisering forbedre kundeservice ved å gjøre det enklere å finne relevant informasjon. Det kan også hjelpe med datasikkerhet ved å kontrollere tilgang til sensitiv informasjon.
Håper denne artikkelen har vært nyttig for å lære om dataklassifisering. Du kan også være interessert i å lære mer om de beste sikkerhetstjenestene for å overvåke brudd på personopplysninger.