Dataframes representerer en fundamental datastruktur innenfor R, og tilfører den nødvendige strukturen, fleksibiliteten og verktøyene for dataanalyse og manipulasjon. Deres betydning er vidtrekkende, og strekker seg over ulike fagområder, inkludert statistikk, datavitenskap og datadrevet beslutningstaking i et mangfold av bransjer.
Dataframes sørger for organiseringen og strukturen som kreves for å avdekke innsikt og legge til rette for datadrevne beslutninger på en systematisk og effektiv måte.
I R er dataframes organisert som tabeller, bestående av rader og kolonner. Hver enkelt rad representerer en observasjon, mens hver kolonne representerer en variabel. Denne strukturen forenkler organisering og arbeid med data. Dataframes er kapable til å inneholde et mangfold av datatyper, som tall, tekst og datoer, noe som understreker deres allsidighet.
I denne artikkelen vil vi belyse viktigheten av dataframes og undersøke hvordan de opprettes ved hjelp av funksjonen data.frame().
Videre skal vi utforske metoder for datamanipulering, inkludert hvordan man importerer data fra CSV- og Excel-filer, konverterer andre datastrukturer til dataframes, og benytter seg av tibble-biblioteket.
Her er noen sentrale årsaker til at dataframes er uunnværlige i R:
Viktigheten av Dataframes

- Strukturert datalagring: Dataframes gir en strukturert og tabellbasert måte å lagre data på, lignende et regneark. Dette formatet forenkler databehandling og organisering.
- Blandede datatyper: En dataframes kan håndtere diverse datatyper innenfor samme struktur. Du kan ha kolonner som inneholder numeriske verdier, tekststrenger, faktorer, datoer, og mer. Denne fleksibiliteten er avgjørende i håndtering av virkelige data.
- Dataorganisasjon: Hver kolonne i en dataframe representerer en variabel, mens hver rad representerer en observasjon eller hendelse. Denne strukturen gir klarhet i dataorganiseringen og forbedrer forståelsen av datasettet.
- Dataimport og -eksport: Dataframes støtter enkel import og eksport av data fra ulike formater som CSV, Excel og databaser. Denne funksjonen effektiviserer prosessen med å jobbe med eksterne datakilder.
- Interoperabilitet: Dataframes er bredt støttet av R-pakker og funksjoner, noe som garanterer kompatibilitet med andre statistikk- og dataanalyseverktøy og biblioteker. Denne interoperabiliteten muliggjør en problemfri integrasjon i R-økosystemet.
- Datamanipulering: R tilbyr et rikt økosystem av pakker, med
dplyrsom et fremtredende eksempel. Disse pakkene legger til rette for enkel filtrering, transformering og oppsummering av data ved hjelp av dataframes. Denne kapasiteten er uunnværlig for datarensing og forberedelse. - Statistisk analyse: Dataframes er standardformatet for mange statistiske og dataanalysefunksjoner i R. Du kan utføre regresjon, hypotesetesting og en rekke andre statistiske analyser effektivt ved hjelp av dataframes.
- Visualisering: Rs datavisualiseringspakker, som
ggplot2, fungerer sømløst med dataframes. Dette forenkler opprettelsen av informative diagrammer og grafer for datautforskning og formidling. - Datautforskning: Dataframes legger til rette for utforskning av data gjennom sammendragsstatistikk, visualisering og andre analytiske tilnærminger. Dette hjelper analytikere og dataforskere med å forstå datakarakteristika og oppdage mønstre eller avvik.
Hvordan lage en DataFrame i R
Det finnes flere metoder for å konstruere en dataframe i R. Her er noen av de vanligste metodene:
#1. Bruke data.frame()-funksjonen
# Laster nødvendig bibliotek om det ikke allerede er lastet inn
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
# Alternativ installasjon og innlasting av dplyr
# install.packages("dplyr")
library(dplyr)
# Setter et frø for repeterbarhet
set.seed(42)
# Oppretter en eksempel salgsdataframe med faktiske produktnavn
salgs_data <- data.frame(
OrderID = 1001:1010,
Produkt = c("Laptop", "Smarttelefon", "Nettbrett", "Hodetelefoner", "Kamera", "TV", "Skriver", "Vaskemaskin", "Kjøleskap", "Mikrobølgeovn"),
Antall = sample(1:10, 10, replace = TRUE),
Pris = round(runif(10, 100, 2000), 2),
Rabatt = round(runif(10, 0, 0.3), 2),
Dato = sample(seq(as.Date('2023-01-01'), as.Date('2023-01-10'), by="days"), 10)
)
# Viser salgsdataframen
print(salgs_data)
La oss se hva koden gjør:
- Først sjekker den om
dplyr-biblioteket er tilgjengelig i R-miljøet. - Hvis
dplyrikke finnes, installerer og laster den inn biblioteket. - Deretter settes et tilfeldig frø for å sikre at koden produserer de samme resultatene hver gang den kjøres.
- Etter det lages en eksempel dataframe for salg med de angitte dataene.
- Til slutt vises salgsdataframen i konsollen.
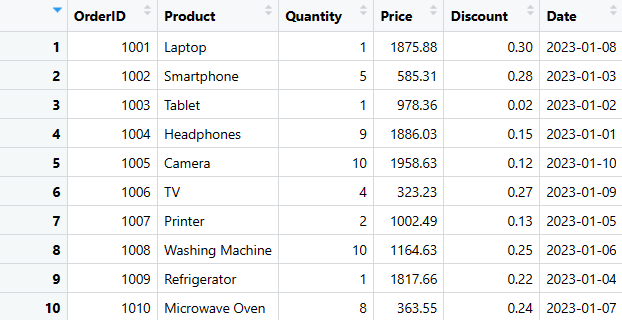
Dette er en av de enkleste måtene å generere en dataframe i R. Vi skal også se på hvordan man trekker ut, legger til, sletter og velger spesifikke kolonner eller rader, og hvordan man oppsummerer data.
Trekk ut kolonner
Det finnes to metoder for å trekke ut de ønskede kolonnene fra dataframen:
- Man kan hente ut de tre siste kolonnene fra en dataframe i R ved å bruke indeksering.
- Man kan også trekke ut kolonner ved å bruke
$-operatoren når man ønsker å få tilgang til individuelle kolonner ved hjelp av navn.
Vi skal se på begge metodene for å spare tid:
# Trekker ut de tre siste kolonnene (Rabatt, Pris og Dato) fra salgs_data-dataframen
siste_tre_kolonner <- salgs_data[, c("Rabatt", "Pris", "Dato")]
# Viser de uttrekkede kolonnene
print(siste_tre_kolonner)
############################################# ELLER #########################################################
# Trekker ut de tre siste kolonnene (Rabatt, Pris og Dato) ved å bruke $-operatoren
rabatt_kolonne <- salgs_data$Rabatt
pris_kolonne <- salgs_data$Pris
dato_kolonne <- salgs_data$Dato
# Lager en ny dataframe med de uttrekkede kolonnene
siste_tre_kolonner <- data.frame(Rabatt = rabatt_kolonne, Pris = pris_kolonne, Dato = dato_kolonne)
# Viser de uttrekkede kolonnene
print(siste_tre_kolonner)
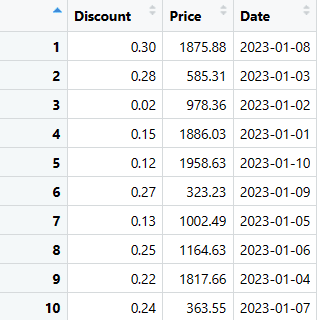
Du kan trekke ut de kolonnene du trenger ved å bruke en av disse kodene.
Du kan trekke ut rader fra en dataframe i R ved hjelp av ulike metoder. Her er en enkel måte å gjøre det på:
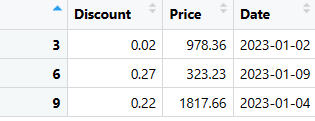
# Trekker ut spesifikke rader (rad 3, 6 og 9) fra siste_tre_kolonner-dataframen valgte_rader <- siste_tre_kolonner[c(3, 6, 9), ] # Viser de valgte radene print(valgte_rader)
Du kan også bruke spesifiserte betingelser:
# Trekker ut og sorterer rader som oppfyller de angitte betingelsene valgte_rader <- salgs_data %>% filter(Rabatt < 0.3, Pris > 100, format(Dato, "%Y-%m") == "2023-01") %>% arrange(OrderID) %>% select(Rabatt, Pris, Dato) # Viser de valgte radene print(valgte_rader)
Legg til ny rad
For å legge til en ny rad i en eksisterende dataframe i R kan du bruke funksjonen rbind():
# Oppretter en ny rad som en dataframe
ny_rad <- data.frame(
OrderID = 1011,
Produkt = "Kaffetrakter",
Antall = 2,
Pris = 75.99,
Rabatt = 0.1,
Dato = as.Date("2023-01-12")
)
# Bruker rbind() for å legge den nye raden til dataframen
salgs_data <- rbind(salgs_data, ny_rad)
# Viser den oppdaterte dataframen
print(salgs_data)
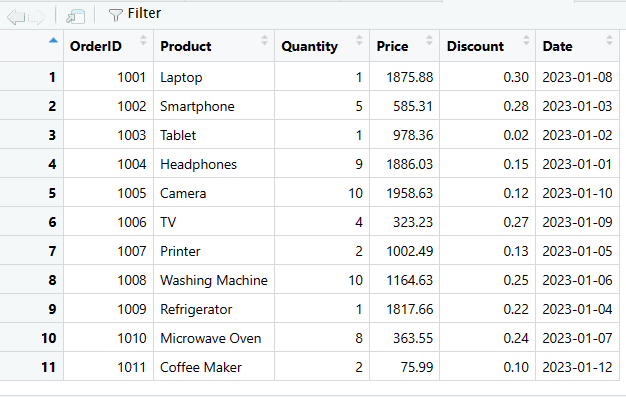
Legg til ny kolonne
Du kan legge til kolonner i en dataframe med enkel kode. Her skal jeg legge til kolonnen Betalingsmetode i mine data.
# Oppretter en ny kolonne "Betalingsmetode" med verdier for hver rad
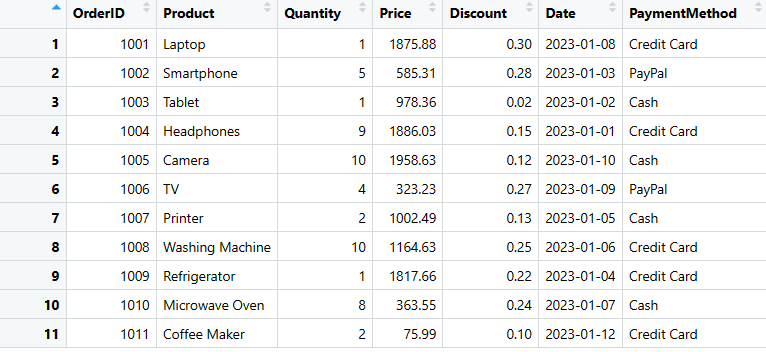
salgs_data$Betalingsmetode <- c("Kredittkort", "PayPal", "Kontant", "Kredittkort", "Kontant", "PayPal", "Kontant", "Kredittkort", "Kredittkort", "Kontant", "Kredittkort")
# Viser den oppdaterte dataframen
print(salgs_data)
Slett rader
Dersom du ønsker å slette unødvendige rader, kan denne metoden være nyttig:
# Identifiserer raden som skal slettes basert på dens OrderID rad_som_skal_slettes <- salgs_data$OrderID == 1010 # Bruker den identifiserte raden for å ekskludere den og lage en ny dataframe salgs_data <- salgs_data[!rad_som_skal_slettes, ] # Viser den oppdaterte dataframen uten den slettede raden print(salgs_data)
Slett kolonner
Du kan slette en kolonne fra en dataframe i R ved å bruke dplyr-pakken.
# install.packages("dplyr")
library(dplyr)
# Fjerner "Rabatt"-kolonnen ved hjelp av funksjonen select()
salgs_data <- salgs_data %>% select(-Rabatt)
# Viser den oppdaterte dataframen uten "Rabatt"-kolonnen
print(salgs_data)
Få sammendrag
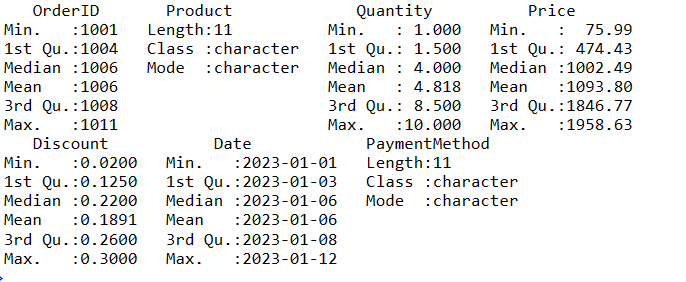
For å få et sammendrag av dine data i R, kan du bruke funksjonen summary(). Denne funksjonen gir en rask oversikt over de sentrale tendensene og fordelingen av numeriske variabler i dine data.
# Henter ut et sammendrag av dataene data_sammendrag <- summary(salgs_data) # Viser sammendraget print(data_sammendrag)
Dette er flere trinn du kan følge for å manipulere dataene dine i en dataframe.
La oss gå videre til den andre metoden for å lage en dataframe.
#2. Lag en R DataFrame fra CSV-fil
For å opprette en R dataframe fra en CSV-fil, kan du bruke read.csv()-funksjonen.
# Leser CSV-filen inn i en dataframe
df <- read.csv("min_data.csv")
# Viser de første radene av dataframen
head(df)
Denne funksjonen leser dataene fra en CSV-fil og konverterer den. Deretter kan du arbeide med dataene i R etter behov.
# Installerer og laster inn readr-pakken om den ikke allerede er installert
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# Leser CSV-filen inn i en dataframe
df <- read_csv("data.csv")
# Viser de første radene av dataframen
head(df)
Du kan bruke readr-pakken til å lese en CSV-fil i R. Funksjonen read_csv() fra readr-pakken benyttes ofte til dette formålet. Den er raskere enn den vanlige metoden.
#3. Bruker funksjonen as.data.frame()
Du kan opprette en dataframe i R ved å bruke funksjonen as.data.frame(). Denne funksjonen lar deg konvertere andre datastrukturer, som matriser eller lister, til en dataframe.
Slik bruker du den:
# Oppretter en nestet liste for å representere dataene
data_liste <- list(
OrderID = 1001:1011,
Produkt = c("Laptop", "Smarttelefon", "Nettbrett", "Hodetelefoner", "Kamera", "TV", "Skriver", "Vaskemaskin", "Kjøleskap", "Mikrobølgeovn", "Kaffetrakter"),
Antall = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Pris = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Rabatt = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Dato = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
Betalingsmetode = c("Kredittkort", "PayPal", "Kontant", "Kredittkort", "Kontant", "PayPal", "Kontant", "Kredittkort", "Kredittkort", "Kontant", "Kredittkort")
)
# Konverterer den nestede listen til en dataframe
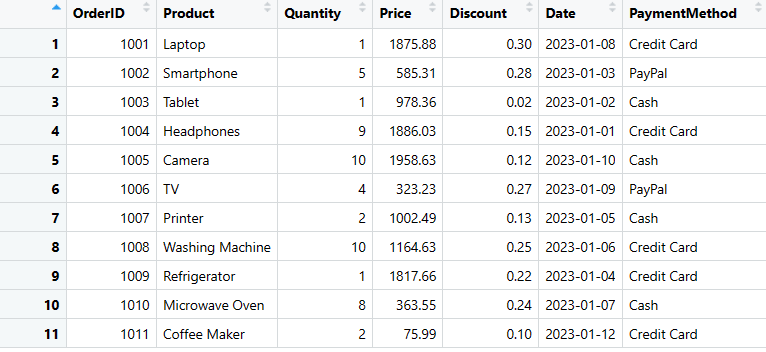
salgs_data <- as.data.frame(data_liste)
# Viser dataframen
print(salgs_data)
Denne metoden lar deg opprette en dataframe uten å spesifisere hver kolonne en etter en, og er spesielt nyttig når du har en stor datamengde.
#4. Fra eksisterende dataramme
For å opprette en ny dataframe ved å velge spesifikke kolonner eller rader fra en eksisterende dataframe i R, kan du bruke firkantede parenteser [] for indeksering. Slik fungerer det:
# Velger rader og kolonner
salgs_delsett <- salgs_data[c(1, 3, 4), c("Produkt", "Antall")]
# Viser det valgte delsettet
print(salgs_delsett)
I denne koden lager vi en ny dataframe kalt salgs_delsett, som inneholder spesifikke rader (1, 3 og 4) og spesifikke kolonner («Produkt» og «Antall») fra salgs_data.
Du kan justere rad- og kolonneindeksene og navnene for å velge de dataene du trenger.

#5. Fra Vektor
En vektor er en endimensjonal datastruktur i R som består av elementer av samme datatype, inkludert logisk, heltall, dobbel, tegn, kompleks eller rå.
En R-dataframe er derimot en todimensjonal struktur designet for å lagre data i et tabellformat med rader og kolonner. Det finnes ulike metoder for å lage en R-dataframe fra en vektor, og et slikt eksempel er gitt nedenfor.
# Oppretter vektorer for hver kolonne
OrderID <- 1001:1011
Produkt <- c("Laptop", "Smarttelefon", "Nettbrett", "Hodetelefoner", "Kamera", "TV", "Skriver", "Vaskemaskin", "Kjøleskap", "Mikrobølgeovn", "Kaffetrakter")
Antall <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Pris <- c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99)
Rabatt <- c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1)
Dato <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
Betalingsmetode <- c("Kredittkort", "PayPal", "Kontant", "Kredittkort", "Kontant", "PayPal", "Kontant", "Kredittkort", "Kredittkort", "Kontant", "Kredittkort")
# Oppretter dataframe ved å bruke data.frame()
salgs_data <- data.frame(
OrderID = OrderID,
Produkt = Produkt,
Antall = Antall,
Pris = Pris,
Rabatt = Rabatt,
Dato = Dato,
Betalingsmetode = Betalingsmetode
)
# Viser dataframen
print(salgs_data)
I denne koden lager vi separate vektorer for hver kolonne, og deretter bruker vi funksjonen data.frame() for å kombinere disse vektorene til en dataframe kalt salgs_data.
Dette lar deg lage en strukturert tabellbasert dataframe fra individuelle vektorer i R.
#6. Fra Excel-fil
For å lage en dataframe ved å importere en Excel-fil i R, kan du bruke tredjepartspakker som readxl, da basis R ikke har innebygd støtte for lesing av CSV-filer. En slik funksjon for å lese Excel-filer er read_excel().
# Laster inn readxl-biblioteket library(readxl) # Definerer filbanen til Excel-filen excel_filbane <- "din_fil.xlsx" # Erstatt med den faktiske filbanen # Leser Excel-filen og oppretter en dataframe dataframe_fra_excel <- read_excel(excel_filbane) # Viser dataframen print(dataframe_fra_excel)
Denne koden vil lese Excel-filen og lagre dataene i en R-dataframe, slik at du kan arbeide med dataene i R-miljøet ditt.
#7. Fra tekstfil
Du kan bruke funksjonen read.table() i R for å importere en tekstfil til en dataframe. Denne funksjonen krever to viktige parametere: filnavnet du ønsker å lese og skilletegnet som spesifiserer hvordan feltene i filen er separert.
# Definerer filnavnet og skilletegnet filnavn <- "din_tekstfil.txt" # Erstatt med det faktiske filnavnet skilletegn <- "\t" # Erstatt med det faktiske skilletegnet (f.eks. "\t" for tab-separert, "," for CSV) # Bruker read.table() for å opprette en dataframe dataframe_fra_tekst <- read.table(filnavn, header = TRUE, sep = skilletegn) # Viser dataframen print(dataframe_fra_tekst)
Denne koden vil lese tekstfilen og opprette den i R, noe som gjør den tilgjengelig for dataanalyse i R-miljøet ditt.
#8. Bruker Tibble
For å lage det ved hjelp av de medfølgende vektorene og tidyverse-biblioteket, kan du følge disse trinnene:
# Laster inn tidyverse-biblioteket
library(tidyverse)
# Oppretter en tibble ved hjelp av de angitte vektorene
salgs_data <- tibble(
OrderID = 1001:1011,
Produkt = c("Laptop", "Smarttelefon", "Nettbrett", "Hodetelefoner", "Kamera", "TV", "Skriver", "Vaskemaskin", "Kjøleskap", "Mikrobølgeovn", "Kaffetrakter"),
Antall = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Pris = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Rabatt = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Dato = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
Betalingsmetode = c("Kredittkort", "PayPal", "Kontant", "Kredittkort", "Kontant", "PayPal", "Kontant", "Kredittkort", "Kredittkort", "Kontant", "Kredittkort")
)
# Viser den opprettede salgs-tibblen
print(salgs_data)
Denne koden bruker funksjonen tibble() fra tidyverse-biblioteket for å lage en tibble-dataframe kalt salgs_data. Tibble-formatet gir mer informativ utskrift sammenlignet med standard R-dataframes, som du nevnte.
Hvordan bruke datarammer effektivt i R
Å bruke dataframes effektivt i R er avgjørende for datamanipulering og -analyse. Dataframes er en fundamental datastruktur i R og blir vanligvis opprettet og manipulert ved å bruke data.frame-funksjonen. Her er noen tips for å arbeide effektivt:
- Før du oppretter, må du sørge for at dataene dine er ryddige og godt strukturert. Fjern unødvendige rader eller kolonner, håndter manglende verdier, og sørg for at datatypene er passende.
- Angi passende datatyper for kolonnene dine (f.eks. numerisk, tegn, faktor, dato). Dette kan forbedre minnebruken og beregningshastigheten.
- Bruk indeksering og delmengder for å arbeide med mindre deler av dataene dine. Funksjonene
subset()og[]-operatoren er nyttige til dette formålet. - Selv om
attach()ogdetach()kan være praktiske, kan de også føre til tvetydighet og uventet oppførsel. - R er sterkt optimalisert for vektoriserte operasjoner. Når det er mulig, bruk vektoriserte funksjoner i stedet for løkker for datamanipulering.
- Nestede løkker kan være langsomme i R. I stedet for nestede løkker, prøv å bruke vektoriserte operasjoner eller bruk funksjoner som
lapplyellersapply. - Store dataframes kan bruke mye minne. Vurder å bruke
data.tableellerdtplyr-pakkene, som er mer minneeffektive for større datasett. - R har et bredt utvalg av pakker for datamanipulering. Bruk pakker som
dplyr,tidyrogdata.tablefor effektive datatransformasjoner. - Minimer bruken av globale variabler, spesielt når du arbeider med flere dataframes. Bruk funksjoner og send dataframes som argumenter.
- Når du arbeider med aggregerte data, bruk
group_by()ogsummarize()-funksjonene idplyrfor å utføre beregninger effektivt. - For store datasett bør du vurdere å bruke parallell prosessering med pakker som
parallelellerforeachfor å fremskynde operasjoner. - Når du leser data inn i R, bruk funksjoner som
readrellerdata.table::freadi stedet for basis R-funksjoner somread.csvfor raskere dataimport. - For svært store datasett bør du vurdere å bruke databasesystemer eller spesialiserte lagringsformater som Feather, Arrow eller Parquet.
Ved å følge disse beste praksisene kan du effektivt arbeide med dataframes i R, noe som gjør datamanipulerings- og analyseoppgavene dine mer håndterbare og raskere.
Siste tanker
Det er enkelt å lage datarammer i R, og det finnes en rekke metoder tilgjengelige. Jeg har belyst viktigheten av datarammer og diskutert opprettelsen av dem ved å bruke funksjonen data.frame().
I tillegg har vi utforsket metoder for å manipulere data og dekket hvordan du oppretter dataframes fra CSV- og Excel-filer, konverterer andre datastrukturer til datarammer og bruker tibble-biblioteket.
Du er kanskje interessert i de beste IDE-ene for R-programmering.