Meta lanserte Llama 2 sommeren 2023. Denne nye versjonen av Llama er forbedret med 40 % flere tokens sammenlignet med den opprinnelige Llama-modellen. Den har også dobbelt så lang kontekstlengde, noe som gjør at den overgår mange andre tilgjengelige modeller med åpen kildekode. Den raskeste måten å benytte seg av Llama 2 er gjennom et API via en nettbasert plattform. Men for den optimale brukeropplevelsen er det anbefalt å installere og kjøre Llama 2 direkte på din egen datamaskin.
Med dette i tankene har vi utviklet en detaljert veiledning som forklarer hvordan du bruker Text-Generation-WebUI for å laste en kvantisert Llama 2 LLM lokalt på datamaskinen din.
Hvorfor installere Llama 2 lokalt?
Det er flere grunner til at mange velger å kjøre Llama 2 direkte på sin egen maskin. Noen gjør det av hensyn til personvern, andre for tilpasning og fleksibilitet, og atter andre ønsker offline-tilgang. Om du skal undersøke, finjustere eller integrere Llama 2 i dine egne prosjekter, kan det hende at det ikke er hensiktsmessig å bruke API-tilgang. Å kjøre en LLM lokalt på din PC reduserer avhengigheten av tredjeparts AI-verktøy. Du kan dermed bruke AI når som helst, hvor som helst, uten bekymring for å avsløre potensielt sensitiv informasjon til eksterne selskaper eller organisasjoner.
Med det sagt, la oss gå i gang med trinn-for-trinn-guiden for å installere Llama 2 lokalt.
For å forenkle prosessen, vil vi bruke et ett-klikks installasjonsprogram for Text-Generation-WebUI (programmet som brukes til å laste Llama 2 med et grafisk brukergrensesnitt). Før vi kan bruke dette installasjonsprogrammet må vi laste ned og installere Visual Studio 2019 Build Tool, sammen med nødvendige ressurser.
Nedlasting: Visual Studio 2019 (Gratis)
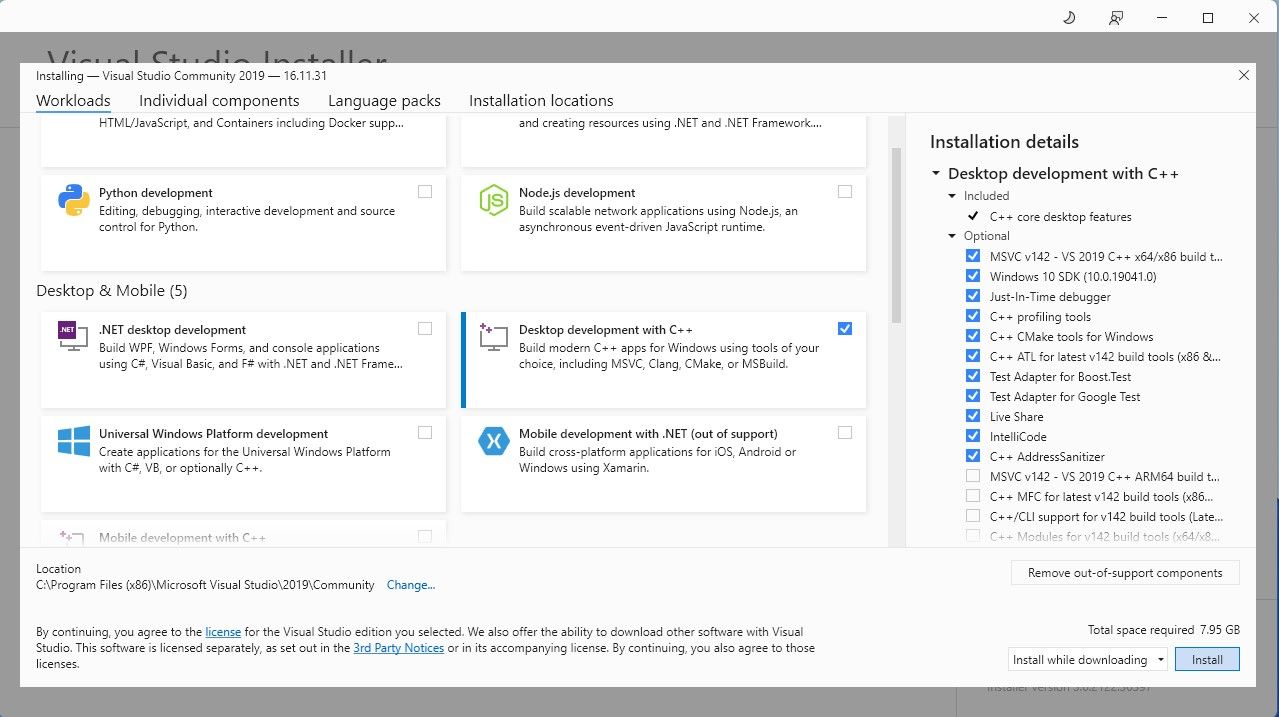
Nå som du har installert «Desktop development with C++», er det tid for å laste ned Text-Generation-WebUI sitt ett-klikks installasjonsprogram.
Trinn 2: Installer Text-Generation-WebUI
Text-Generation-WebUI ett-klikks installasjonsprogram er et skript som automatisk oppretter de nødvendige mappene, setter opp et Conda-miljø, og installerer alle nødvendige avhengigheter for å kjøre en AI-modell.
For å installere skriptet, last ned installasjonsprogrammet ved å trykke på «Code» > «Download ZIP».
Nedlasting: Text-Generation-WebUI Installer (Gratis)
- For Windows: Velg «start_windows» batchfil.
- For MacOS: Velg «start_macos» shell script.
- For Linux: «start_linux» shell script.
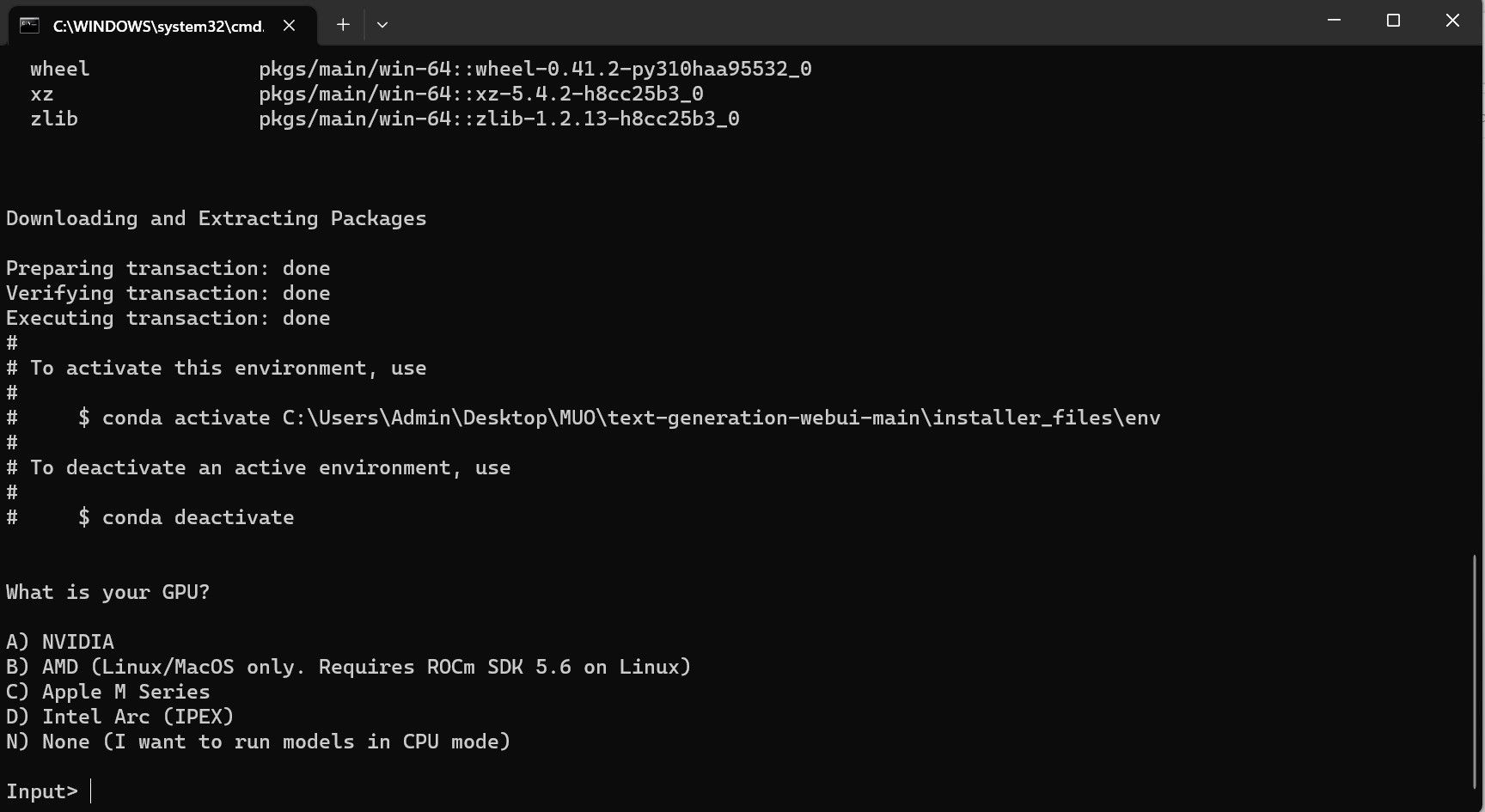
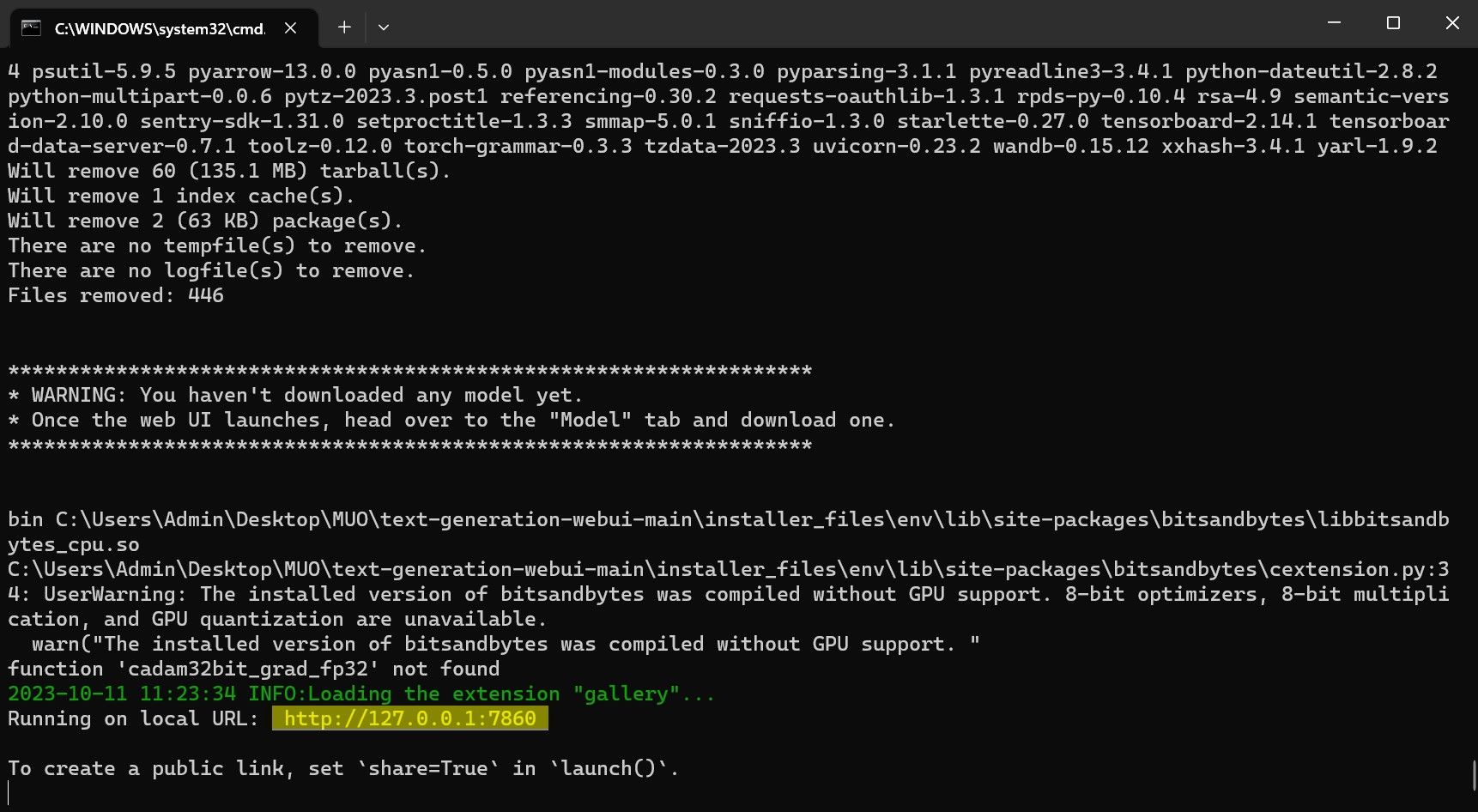
Programmet er imidlertid kun en modell-laster. La oss laste ned Llama 2 for å starte modell-lasteren.
Trinn 3: Last ned Llama 2-modellen
Det er flere faktorer som spiller inn når du skal velge hvilken versjon av Llama 2 du trenger. Disse inkluderer parametere, kvantisering, maskinvareoptimalisering, størrelse og bruksområde. All denne informasjonen finner du vanligvis i modellens navn.
- Parametere: Antall parametere som brukes til å trene modellen. Større parameter-antall gir mer avanserte modeller, men går på bekostning av ytelse.
- Bruk: Kan være standard eller chat. En chat-modell er optimalisert for å brukes som en chatbot, mens standard er standard-modellen.
- Maskinvareoptimalisering: Indikerer hvilken maskinvare som er best egnet for å kjøre modellen. GPTQ betyr at modellen er optimalisert for dedikert GPU, mens GGML er optimalisert for CPU.
- Kvantisering: Angir presisjonen til vekter og aktiveringer i modellen. For inferens er en presisjon på q4 optimal.
- Størrelse: Refererer til den spesifikke modellens størrelse.
Vær oppmerksom på at noen modeller kan være navngitt annerledes, og kanskje ikke inneholder alle de nevnte informasjonsdelene. Likevel er denne typen navnekonvensjon relativt vanlig i HuggingFace Model-biblioteket, så det er verdt å forstå.

I dette eksemplet ser vi at modellen er en mellomstor Llama 2 modell som er trent med 13 milliarder parametere, og optimalisert for chat-inferens ved hjelp av dedikert CPU.
For de som bruker dedikert GPU, velg en GPTQ modell, mens de som bruker CPU velger en GGML modell. Hvis du vil chatte med modellen på samme måte som du gjør med ChatGPT, velg chat. Hvis du derimot ønsker å eksperimentere med modellens fulle muligheter, bør du bruke standardmodellen. Når det gjelder antall parametere, må du vite at bruk av større modeller vil gi bedre resultater, men på bekostning av ytelsen. Vi anbefaler å starte med en 7B-modell. Når det gjelder kvantisering, velg q4, da dette er optimalt for inferens.
Nedlasting: GGML (Gratis)
Nedlasting: GPTQ (Gratis)
Nå som du har oversikt over hvilken versjon av Llama 2 du trenger, kan du laste ned den modellen du ønsker.
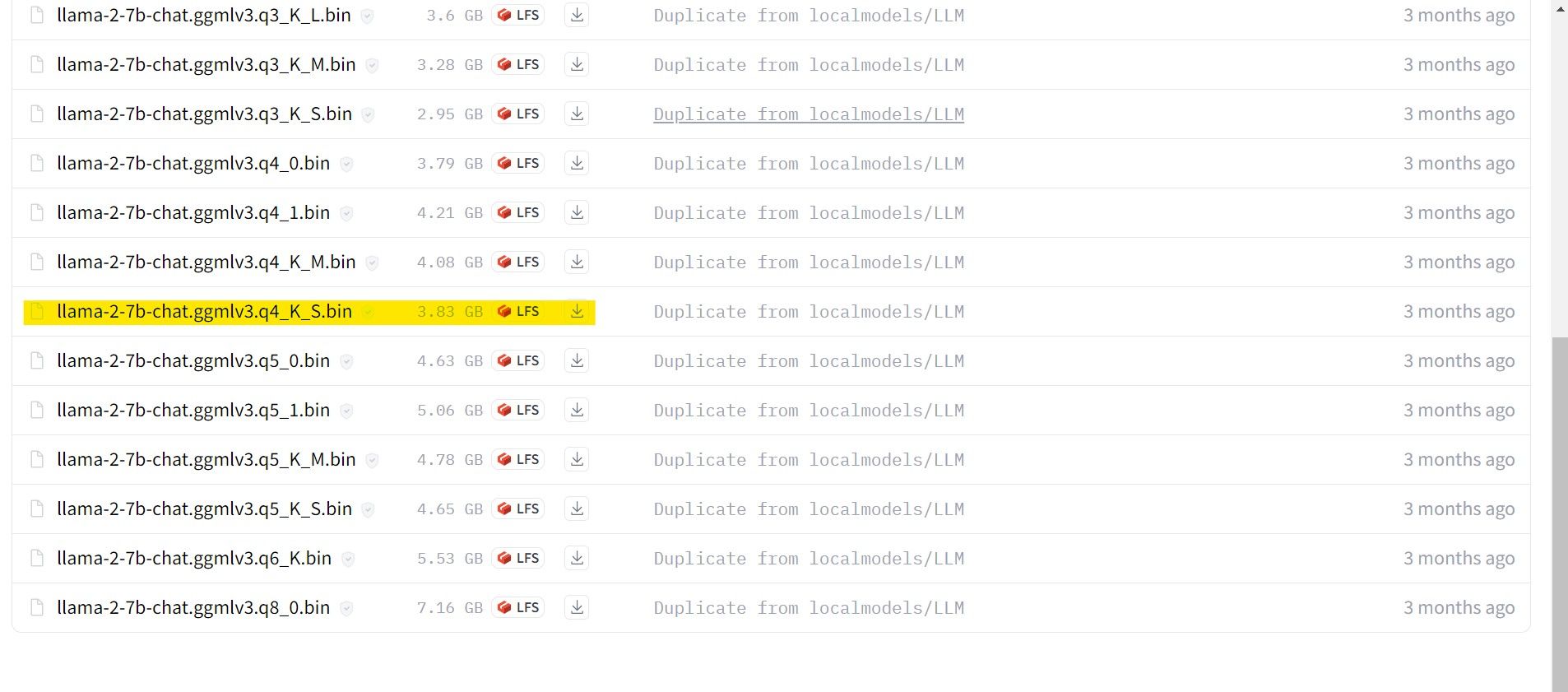
I mitt tilfelle, siden jeg kjører dette på en ultrabook, vil jeg bruke en GGML-modell som er finjustert for chat: «llama-2-7b-chat-ggmlv3.q4_K_S.bin».
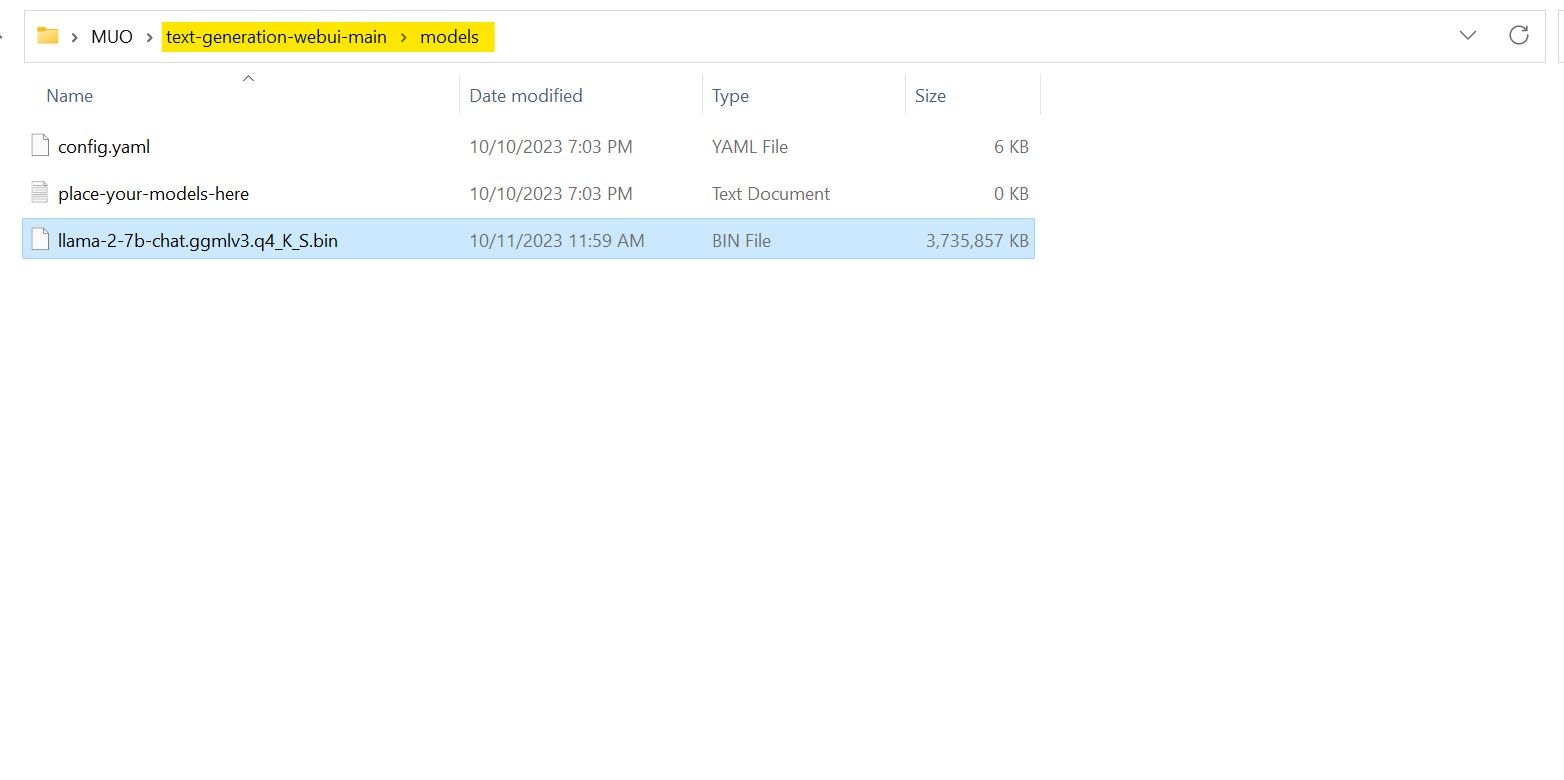
Etter nedlastingen er fullført, flytter du modellen til «text-generation-webui-main» > «models».
Nå som du har lastet ned modellen og lagt den i modellmappen, er det på tide å konfigurere modell-lasteren.
Trinn 4: Konfigurer Text-Generation-WebUI
La oss begynne med konfigurasjonsfasen.
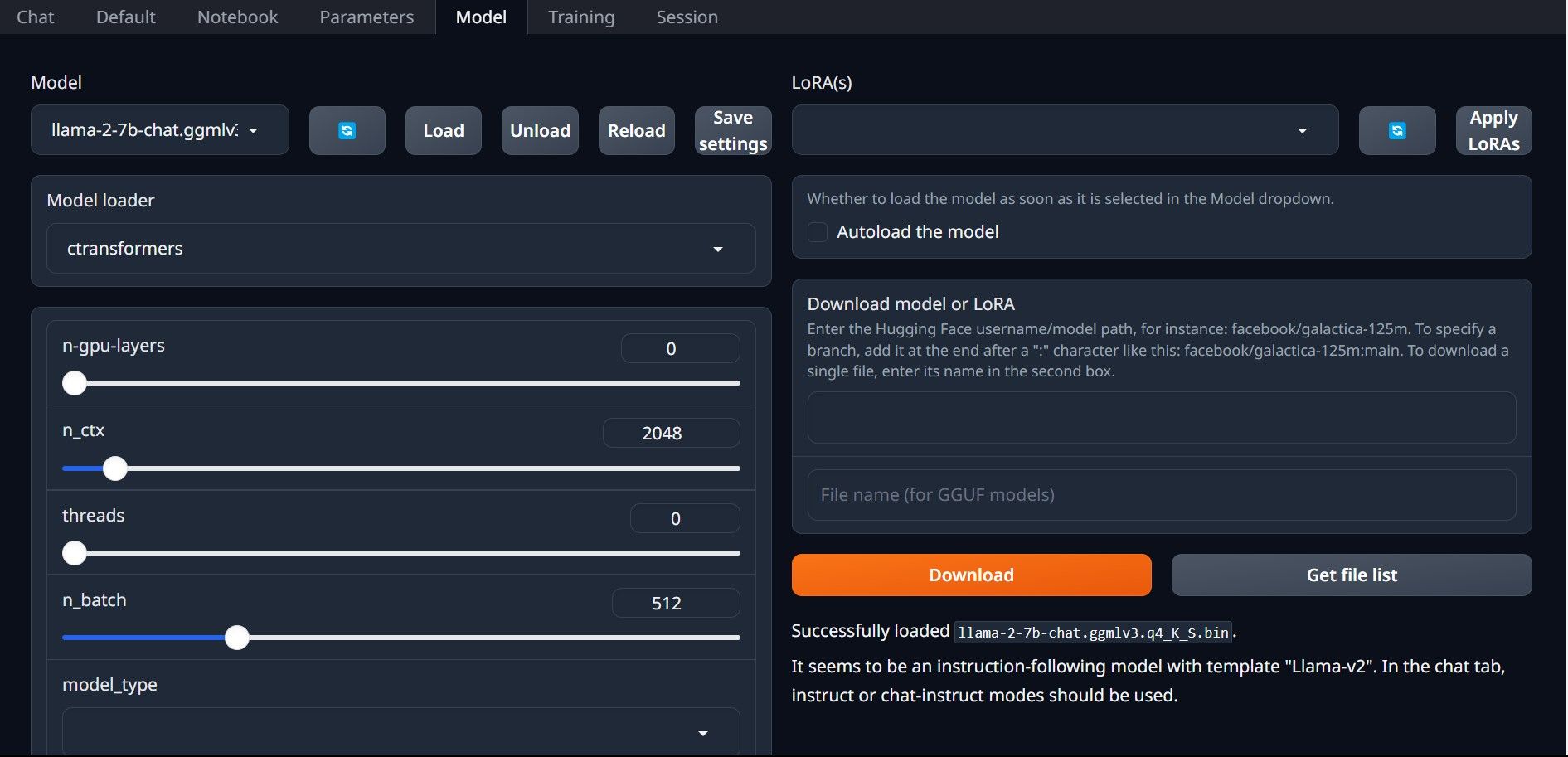
Gratulerer, du har nå lastet Llama 2 lokalt på din datamaskin!
Prøv andre LLM-er
Nå som du vet hvordan du kjører Llama 2 direkte på datamaskinen din ved hjelp av Text-Generation-WebUI, kan du også kjøre andre LLM-er i tillegg til Llama. Husk å ta hensyn til modellens navnekonvensjoner, og at det som regel kun er kvantiserte modeller (vanligvis q4 presisjon) som kan lastes inn på vanlige PC-er. Du finner et bredt utvalg kvantiserte LLM-er tilgjengelig på HuggingFace. Hvis du vil utforske flere modeller, søk etter «TheBloke» i HuggingFace sitt modellbibliotek. Der finner du et stort utvalg av tilgjengelige modeller.