Nettskraping er en kraftig teknikk for å trekke ut informasjon fra nettsteder og analysere dem automatisk. Selv om du kan gjøre dette manuelt, kan det være en kjedelig og tidkrevende oppgave. Verktøy for nettskraping gjør prosessen raskere og mer effektiv, samtidig som det koster mindre.
Interessant nok har Google Sheets potensialet til å være ditt one-stop web-scrapping-verktøy, takket være IMPORTXML-funksjonen. Med IMPORTXML kan du enkelt skrape data fra nettsider og bruke dem til analyser, rapportering eller andre datadrevne oppgaver.
IMPORTXML-funksjonen i Google Sheets
Google Sheets har en innebygd funksjon kalt IMPORTXML, som lar deg importere data fra nettformater som XML, HTML, RSS og CSV. Denne funksjonen kan være en game-changer hvis du ønsker å samle inn data fra nettsteder uten å ty til kompleks koding.
Her er den grunnleggende syntaksen til IMPORTXML:
=IMPORTXML(url, xpath_query)
- url: URL-en til nettsiden du vil skrape data fra.
- xpath_query: XPath-spørringen som definerer dataene du vil trekke ut.
XPath (XML Path Language) er et språk som brukes til å navigere i XML-dokumenter, inkludert HTML – slik at du kan spesifisere plasseringen av data i en HTML-struktur. Det er viktig å forstå XPath-spørringer for å bruke IMPORTXML riktig.
Forstå XPath
XPath tilbyr ulike funksjoner og uttrykk for å navigere og filtrere data i et HTML-dokument. En omfattende XML- og XPath-veiledning er utenfor denne artikkelens omfang, så vi nøyer oss med noen viktige XPath-konsepter:
- Elementvalg: Du kan velge elementer ved å bruke / og // for å angi stier. For eksempel, /html/body/div velger alle div-elementer i brødteksten i et dokument.
- Attributtvalg: For å velge attributter kan du bruke @. For eksempel velger //@href alle href-attributter på siden.
- Predikatfiltre: Du kan filtrere elementer ved å bruke predikater omsluttet av firkantede parenteser ([ ]). For eksempel, /div[@class=”container”] velger alle div-elementer med klassebeholderen.
- Funksjoner: XPath tilbyr forskjellige funksjoner som contains(), starters-with() og text() for å utføre spesifikke handlinger som å se etter tekstinnhold eller attributtverdier.
Så langt kjenner du IMPORTXML-syntaksen, du kjenner nettsidens URL, og du vet hvilket element du vil trekke ut. Men hvordan får du elementets XPath?
Du trenger ikke å kunne et nettsteds struktur utenat for å trekke ut dataene med IMPORTXML. Faktisk har hver nettleser et pent verktøy som lar deg umiddelbart kopiere et hvilket som helst elements XPath.
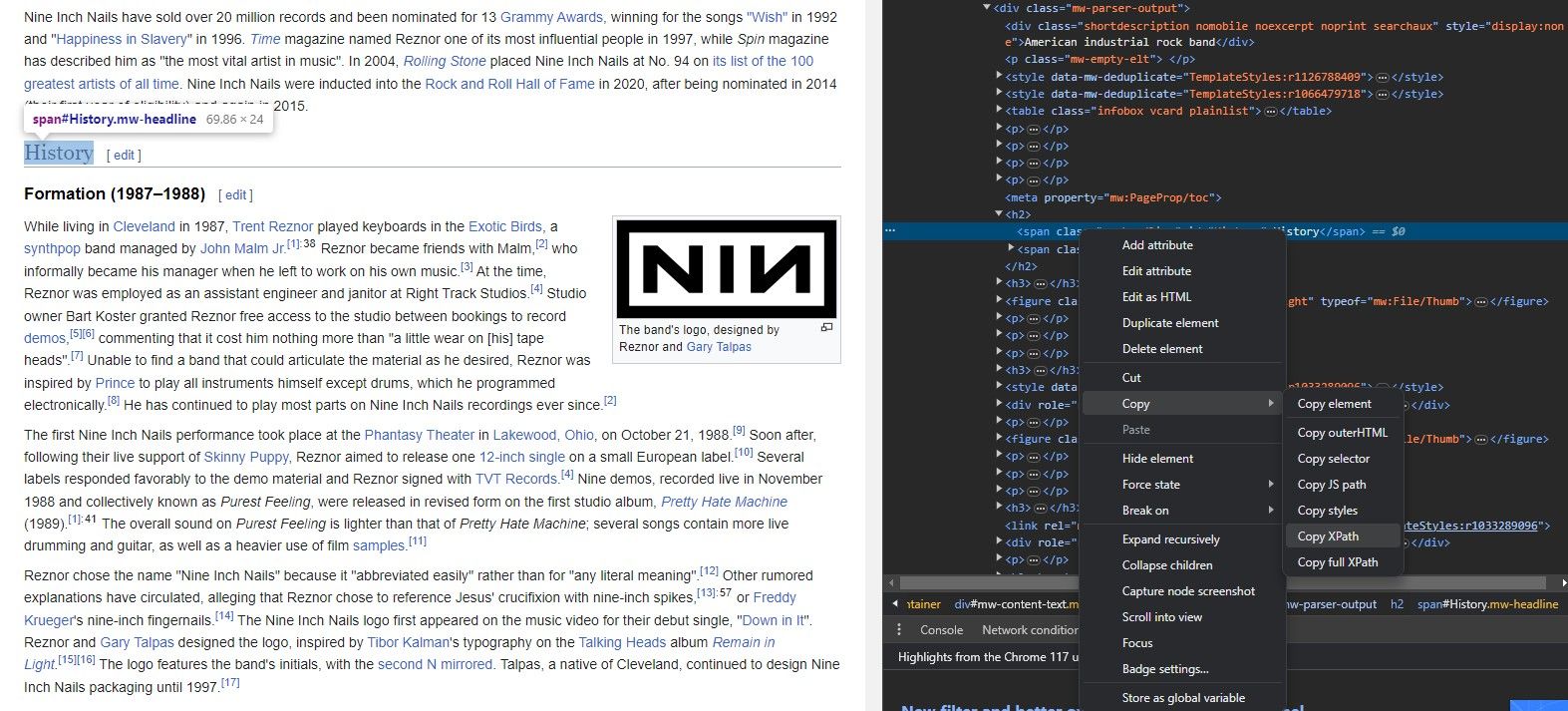
Inspiser element-verktøyet lar deg trekke ut XPath fra nettstedelementer. Dette er hvordan:
Nå som du har alt du trenger, er det på tide å se IMPORTXML i aksjon og skrape noen lenker.
Hvordan skrape lenker fra et nettsted med IMPORTXML
Du kan bruke IMPORTXML til å skrape alle slags data fra nettsteder. Dette inkluderer lenker, videoer, bilder og nesten alle elementer på nettstedet. Lenker er et av de mest fremtredende elementene i nettanalyse, og du kan lære mye om en nettside bare ved å analysere sidene den lenker til.
IMPORTXML lar deg raskt skrape lenker i Google Sheets og deretter analysere dem videre ved hjelp av de ulike funksjonene Google Sheets tilbyr.
1. Skrape alle koblinger
For å skrape alle koblinger fra en nettside, kan du bruke følgende formel:
=IMPORTXML(url, "//a/@href")
Denne XPath-spørringen velger alle href-attributter til et element, og trekker effektivt ut alle koblingene på siden.
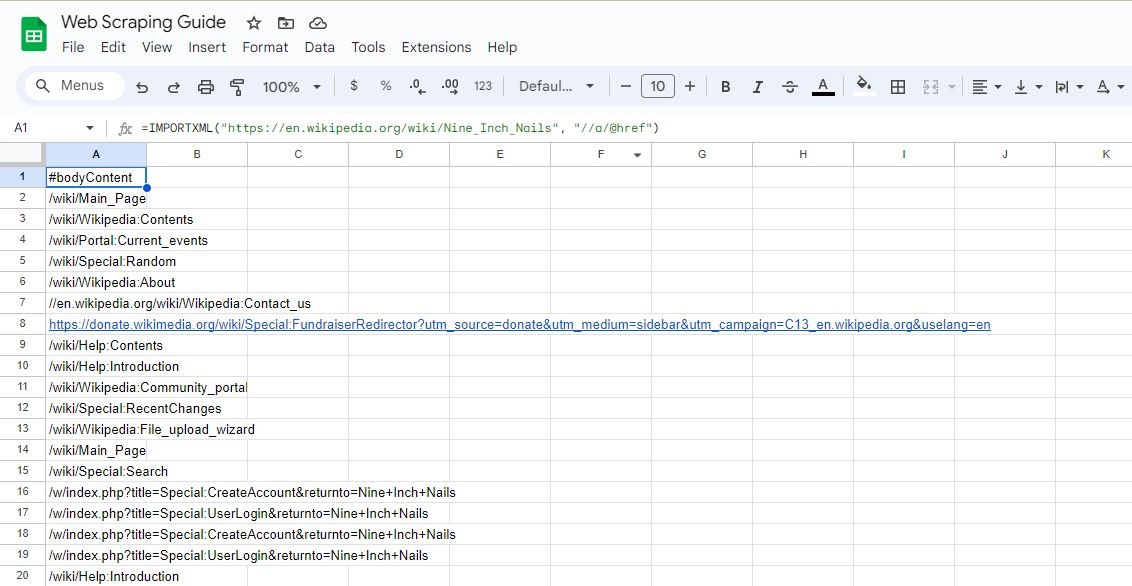
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
Formelen ovenfor skraper alle lenker i en Wikipedia-artikkel.
Det er en god idé å legge inn nettsidens URL i en egen celle og deretter referere til den cellen. Dette vil forhindre at formelen din blir for lang og uhåndterlig. Du kan gjøre det samme med XPath-spørringen.
2. Skrape alle lenketekster
For å trekke ut teksten til koblingene sammen med URL-ene deres, kan du bruke:
=IMPORTXML(url, "//a")
Denne spørringen velger alle elementer, og du kan trekke ut lenketeksten og URL-ene fra resultatene.
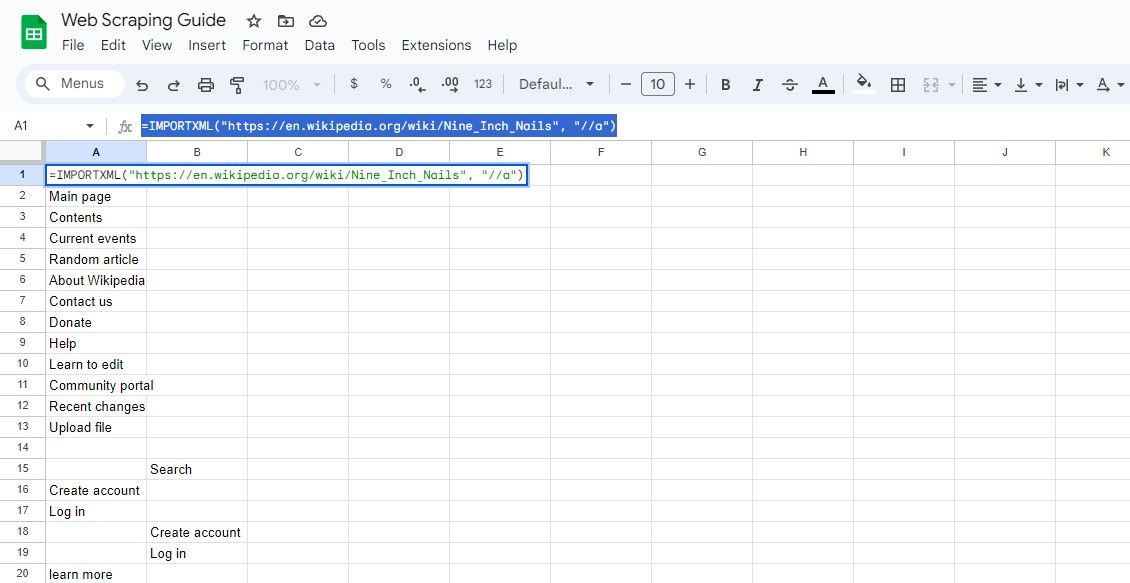
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
Formelen ovenfor får lenketekstene i samme Wikipedia-artikkel.
Hvordan skrape spesifikke lenker fra et nettsted med IMPORTXML
Noen ganger kan det hende du må skrape spesifikke lenker basert på kriterier. Du kan for eksempel være interessert i å trekke ut lenker som inneholder et bestemt søkeord eller lenker som er plassert i en bestemt del av siden.
Med riktig kunnskap om XPath kan du finne et hvilket som helst element du leter etter.
1. Skrape lenker som inneholder et nøkkelord
For å skrape lenker som inneholder et spesifikt nøkkelord, kan du bruke contains() XPath-funksjonen:
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
Denne spørringen velger href-attributter for elementer der href inneholder det angitte søkeordet.
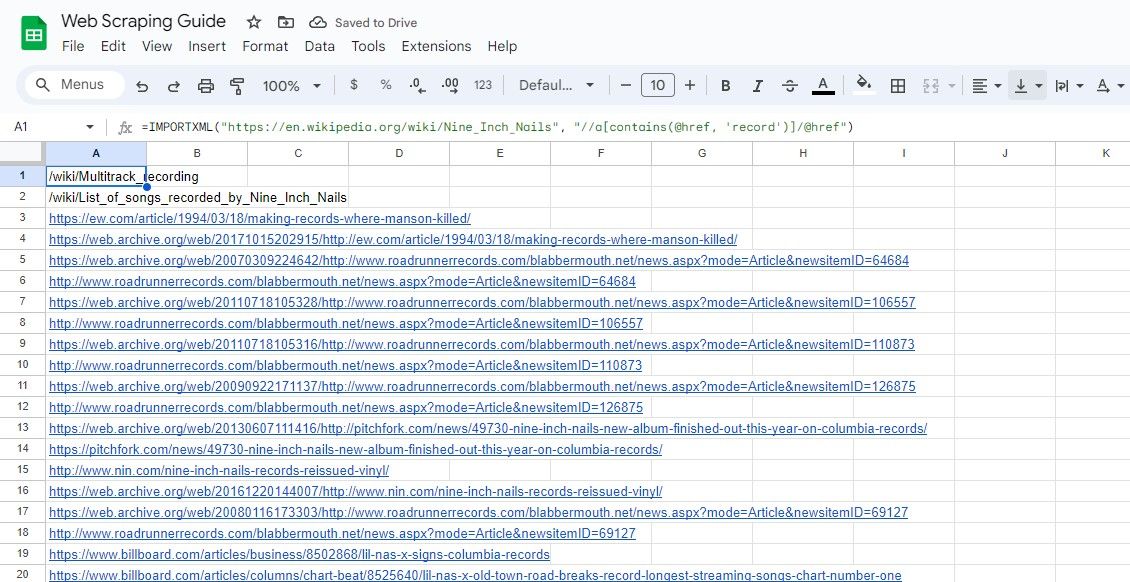
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
Formelen ovenfor skraper alle lenker som inneholder ordet post i teksten i en eksempel Wikipedia-artikkel.
2. Skrape lenker i en seksjon
For å skrape lenker fra en bestemt del av en side, kan du spesifisere delens XPath. For eksempel:
=IMPORTXML(url, "//div[@class="section"]//a/@href")
Denne spørringen velger href-attributter til elementer i div-elementer med klassen «seksjon».
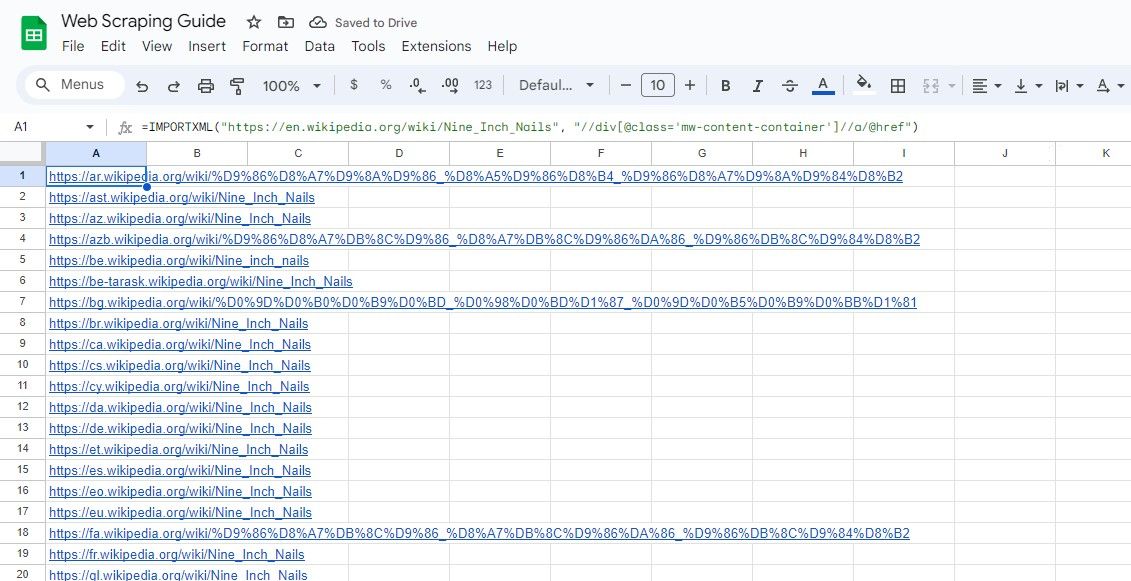
På samme måte velger formelen nedenfor alle lenker i div-klassen som har mw-content-container-klassen:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
Det er verdt å merke seg at du kan bruke IMPORTXML til mer enn nettskraping. Du kan bruke IMPORT-familien av funksjoner til å importere datatabeller fra nettsteder til Google Sheets.
Selv om Google Sheets og Excel deler de fleste funksjonene sine, er IMPORT-familien av funksjoner unik for Google Sheets. Du må vurdere andre metoder for å importere data fra nettsteder til Excel.
Forenkle nettskraping med Google Sheets
Nettskraping med Google Sheets og IMPORTXML-funksjonen er en allsidig og tilgjengelig måte å samle inn data fra nettsteder på.
Ved å mestre XPath og forstå hvordan du lager effektive spørringer, kan du frigjøre det fulle potensialet til IMPORTXML og få verdifull innsikt fra nettressursene. Så begynn å skrape og ta nettanalysen din til neste nivå!