Reddit tilbyr JSON-data for alle sine subreddits. Dette gir oss muligheten til å lage et Bash-skript som henter og analyserer en oversikt over innlegg fra en valgfri subreddit. Denne funksjonen representerer bare en liten del av hva som er mulig med Reddits JSON-data.
Installasjon av Curl og JQ
Vi vil bruke curl til å laste ned JSON-data fra Reddit, og jq for å analysere JSON-dataene og plukke ut de spesifikke feltene vi trenger fra resultatet. Du kan installere disse to verktøyene ved hjelp av apt-get på Ubuntu og andre Linux-distribusjoner basert på Debian. For andre Linux-distribusjoner kan du bruke den respektive pakkebehandleren.
sudo apt-get install curl jq
Laste ned JSON-data fra Reddit
La oss ta en titt på hvordan dataflyten ser ut. Vi benytter curl for å hente de nyeste innleggene fra Mildt interessant subreddit:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json
Merk deg alternativene som ble brukt før URL-en: -s kommanderer curl til å kjøre i lydløs modus, slik at vi kun ser dataene fra Reddits servere, uten unødvendig output. Det påfølgende alternativet og parameteren, -A “reddit scraper example”, setter en egendefinert brukeragentstreng som hjelper Reddit med å identifisere tjenesten som henter dataene. Reddit API-servere bruker hastighetsbegrensninger basert på brukeragentstrengen. Ved å definere en unik verdi kan Reddit differensiere vår takstbegrensning fra andre brukere, noe som reduserer risikoen for å få en HTTP 429 Rate Limit Exceeded-feil.
Resultatet vil fylle terminalvinduet og se omtrent slik ut:
Resultatet inneholder mange felt, men vi er primært interessert i Tittel, Permalink og URL. En fullstendig oversikt over typer og deres felter finnes på Reddits API-dokumentasjonsside: https://github.com/reddit-archive/reddit/wiki/JSON
Hente ut Data fra JSON-Output
Vi ønsker å hente ut Tittel, Permalink og URL fra output og lagre disse i en fil med tabulatorseparerte verdier. Selv om vi kunne bruke verktøy som sed og grep, har vi et annet verktøy tilgjengelig som er laget for å håndtere JSON-strukturer, nemlig jq. La oss i første omgang bruke det til å printe ut output med fargekoding. Vi bruker samme kall som tidligere, men sender output gjennom jq, som instrueres til å analysere og skrive ut JSON-data.
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq .
Merk deg punktumet etter kommandoen. Dette uttrykket analyserer input og skriver den ut nøyaktig slik den er. Output vil se pent formatert og fargekodet ut:
La oss undersøke strukturen til JSON-dataene vi får tilbake fra Reddit. Rotresultatet er et objekt med to egenskaper: type og data. Sistnevnte har en egenskap som kalles children, som inneholder en samling av innlegg til denne subredditen.
Hvert element i samlingen er et objekt som også har to felter kalt type og data. Egenskapene vi ønsker å hente ut, ligger i data-objektet. jq forventer et uttrykk som kan brukes på inputdataene for å generere den ønskede outputen. Dette uttrykket må beskrive hierarkiet og medlemskapet i en samling, samt hvordan dataene skal transformeres. La oss kjøre hele kommandoen igjen med det korrekte uttrykket:
curl -s -A “reddit scraper example” https://www.reddit.com/r/MildlyInteresting.json | jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
Output viser nå Tittel, URL og Permalink, hver på sin egen linje:
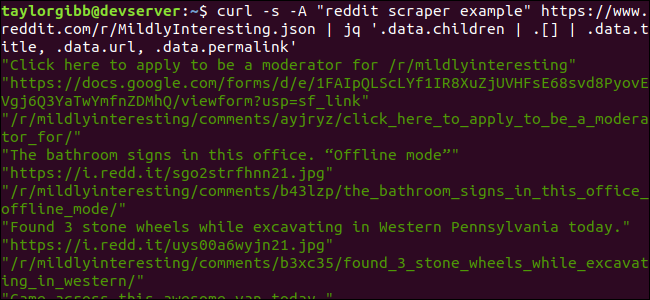
La oss se nærmere på jq-kommandoen vi kjørte:
jq ‘.data.children | .[] | .data.title, .data.url, .data.permalink’
Denne kommandoen inneholder tre uttrykk separert av to rør-symboler. Resultatene av hvert uttrykk overføres til det neste for videre evaluering. Det første uttrykket filtrerer bort alt unntatt samlingen av Reddit-innlegg. Denne outputen sendes til det andre uttrykket og omformes til en samling. Det tredje uttrykket opererer på hvert element i samlingen og henter ut tre egenskaper. Du finner mer informasjon om jq og dets uttrykkssyntaks i jqs offisielle manual.
Sammenkoble Alt i et Skript
La oss sette sammen API-kallet og JSON-behandlingen til et skript som produserer en fil med de ønskede innleggene. Vi skal legge til støtte for å hente innlegg fra en hvilken som helst subreddit, ikke bare /r/MildlyInteresting.
Åpne en teksteditor og kopier innholdet av følgende kodebit til en fil kalt scrape-reddit.sh.
#!/bin/bash
if [ -z "$1" ]
then
echo "Vennligst spesifiser en subreddit"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "bash-scrape-topics" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}t${URL}t${PERMALINK}" | tr --delete '"' >> ${OUTPUT_FILE}
done
Dette skriptet vil først sjekke om brukeren har spesifisert et subreddit-navn. Hvis ikke, avsluttes det med en feilmelding og en returkode som ikke er null.
Deretter lagres det første argumentet som subreddit-navnet, og det genereres et datostemplet filnavn der output lagres.
Handlingen starter når curl kalles med en egendefinert overskrift og URL-en til subredditen som skal hentes. Utdata sendes til jq der det analyseres og reduseres til tre felter: Tittel, URL og Permalink. Disse linjene leses én etter én og lagres i variabler ved hjelp av read-kommandoen, alt inne i en while-løkke, som fortsetter til det ikke er flere linjer å lese. Den siste linjen i den indre while-blokken formatterer de tre feltene med en tabulator som skilletegn og sender det gjennom tr-kommandoen for å fjerne doble anførselstegn. Deretter legges utdataene til filen.
Før vi kan kjøre skriptet, må vi gi det utførelsesrettigheter. Bruk chmod-kommandoen for å tildele disse tillatelsene til filen:
chmod u+x scrape-reddit.sh
Til slutt, kjør skriptet med et subreddit-navn:
./scrape-reddit.sh MildlyInteresting
En output-fil genereres i samme katalog, og innholdet vil se omtrent slik ut:
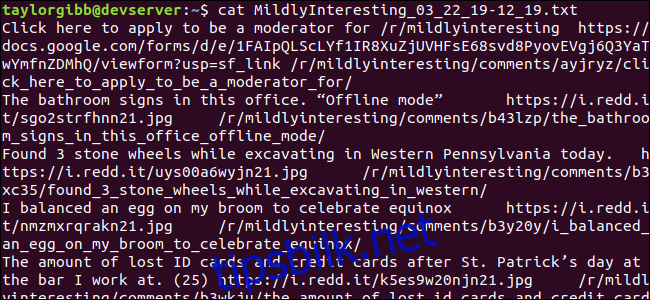
Hver linje inneholder de tre feltene vi er ute etter, adskilt av en tabulator.
Videre Utvikling
Reddit er en kilde til interessant innhold og media, og alt er enkelt tilgjengelig via JSON API. Nå som du har en måte å få tilgang til disse dataene og behandle dem, kan du gjøre ting som:
- Hente de nyeste overskriftene fra
/r/WorldNewsog sende dem til skrivebordet ditt ved hjelp av notify-send. - Integrere de beste vitsene fra
/r/DadJokesi systemets Message-Of-The-Day. - Hente dagens beste bilde fra
/r/awwog bruke det som skrivebordsbakgrunn.
Alt dette er mulig med de tilgjengelige dataene og verktøyene på systemet ditt. Lykke til med eksperimenteringen!