Er du klar til å fordype deg i kunsten med funksjonsteknikk for maskinlæring og dataanalyse? Da har du kommet til rett sted!
Funksjonsteknikk er en avgjørende ferdighet for å utvinne verdifull innsikt fra rådata. I denne hurtigguiden vil vi dele opp prosessen i lettfordøyelige deler. La oss starte reisen mot å mestre kunsten med funksjonsekstraksjon!
Hva er egentlig funksjonsteknikk?

Når man utvikler en maskinlæringsmodell for et forretningsproblem eller et eksperiment, presenteres læringsdataene i form av kolonner og rader. Innen datavitenskap og maskinlæringsutvikling refererer vi til kolonner som attributter eller variabler.
De individuelle dataene eller radene under hver kolonne kalles observasjoner eller forekomster. Kolonnene, eller attributtene, utgjør funksjonene i et rådatasett.
Disse råfunksjonene er ofte ikke tilstrekkelige eller optimale for å trene en maskinlæringsmodell. For å redusere støy fra de innhentede dataene og maksimere de unike signalene fra funksjonene, er det nødvendig å transformere eller konvertere metadata-kolonner til mer funksjonelle funksjoner ved hjelp av funksjonsteknikk.
Eksempel 1: Finansiell modellering
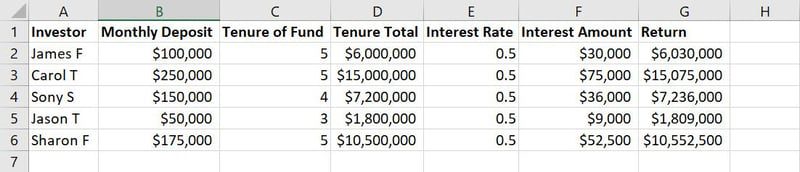 Rådata for opplæring i en ML-modell
Rådata for opplæring i en ML-modell
For eksempel, i dataeksemplet vist ovenfor, representerer kolonnene fra A til G ulike funksjoner. Verdiene eller tekststrengene i hver kolonne, som navn, innskuddsbeløp, innskuddsår, renter osv., er observasjonene.
Ved modellering med maskinlæring er det ofte nødvendig å slette, legge til, kombinere eller transformere data for å generere meningsfulle funksjoner og redusere omfanget av det totale datasettet for modellopplæring. Dette er kjernen i funksjonsteknikk.
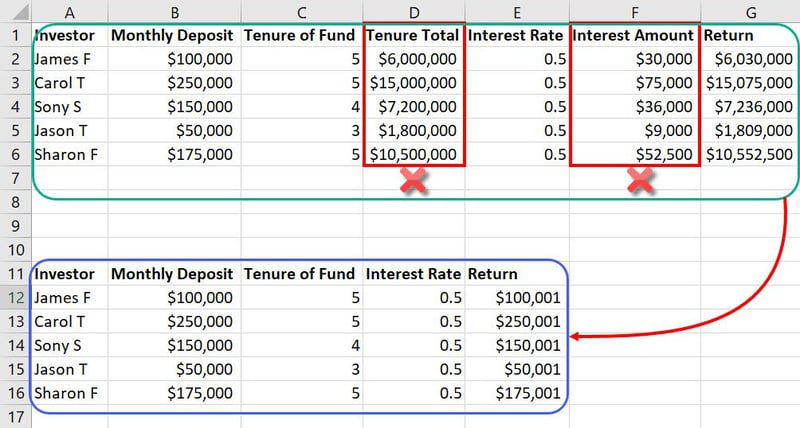 Eksempel på funksjonsteknikk
Eksempel på funksjonsteknikk
I det samme datasettet som nevnt, kan funksjoner som total utlånstid og rentebeløp betraktes som unødvendige inndata. Disse vil kun oppta mer plass og forvirre maskinlæringsmodellen. Dermed kan vi redusere to funksjoner fra totalt syv.
Ettersom databasene som brukes i maskinlæringsmodeller ofte inneholder tusenvis av kolonner og millioner av rader, vil selv en liten reduksjon av funksjoner ha betydelig innvirkning på prosjektet.
Eksempel 2: AI-basert musikkspillelistegenerator
Iblant kan det være fordelaktig å skape helt nye funksjoner basert på eksisterende. La oss si at du utvikler en AI-modell som automatisk genererer musikkspillelister basert på hendelse, preferanser, humør osv.
Du har da samlet inn musikkdata fra ulike kilder og etablert følgende database:
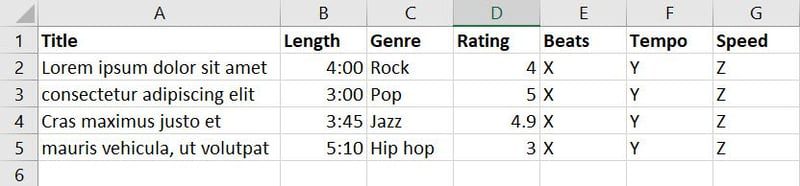
Databasen ovenfor inneholder syv funksjoner. Men siden målet ditt er å trene maskinlæringsmodellen til å avgjøre hvilken sang eller musikk som passer best for en gitt anledning, kan du slå sammen funksjoner som sjanger, vurdering, beats, tempo og hastighet til en ny funksjon som vi kan kalle «egnethet».
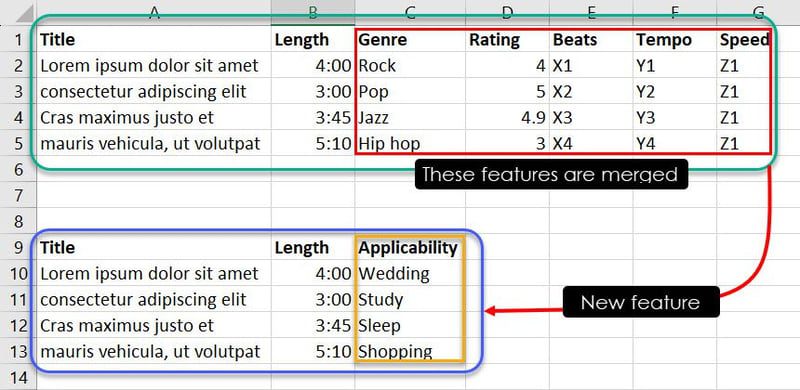
Gjennom ekspertise eller mønstergjenkjenning kan du nå kombinere visse forekomster av funksjoner for å finne ut hvilken sang som passer best for hvilken hendelse. For eksempel vil observasjoner som Jazz, 4.9, X3, Y3 og Z1 fortelle maskinlæringsmodellen at sangen «Cras maximus justo et» passer godt i en spilleliste for søvn.
Typer funksjoner i maskinlæring
Kategoriske funksjoner
Dette er dataattributter som representerer distinkte kategorier eller etiketter. Disse brukes gjerne til å merke kvalitative datasett.
#1. Ordinale kategoriske trekk
Ordinale trekk har kategorier med en meningsfull rangordning. For eksempel har utdanningsnivåer som videregående skole, bachelor, master osv. klare forskjeller i standarder, men uten kvantitative forskjeller.
#2. Nominelle kategoriske trekk
Nominelle funksjoner er kategorier uten en iboende rangordning. Eksempler på dette kan være farger, land eller typer dyr. Her er det kun kvalitative forskjeller.
Array-funksjoner
Denne funksjonstypen representerer data organisert i matriser eller lister. Datavitere og maskinlæringsutviklere benytter ofte array-funksjoner for å håndtere sekvenser eller for å legge inn kategoriske data.
#1. Innebyggingsarray-funksjoner
Innebygde arrayer konverterer kategoriske data til tette vektorer. Dette brukes ofte innen naturlig språkbehandling og anbefalingssystemer.
#2. Liste-array-funksjoner
Liste-arrayer lagrer sekvenser av data, som for eksempel lister over elementer i en ordre eller en handlingshistorikk.
Numeriske funksjoner
Disse funksjonene brukes i forbindelse med matematisk behandling, siden de representerer kvantitative data.
#1. Intervallnumeriske funksjoner
Intervallfunksjoner har konsistente intervaller mellom verdiene, men ikke et ekte nullpunkt – et eksempel er temperaturovervåkningsdata. Null representerer her frysepunktet, men attributtet eksisterer likevel.
#2. Forholdsbaserte numeriske funksjoner
Forholdsfunksjoner har konsistente intervaller mellom verdiene samt et ekte nullpunkt. Eksempler kan være alder, høyde og inntekt.
Viktigheten av funksjonsteknikk i maskinlæring og datavitenskap
- Effektiv funksjonsutvinning gir bedre modellnøyaktighet, noe som fører til mer pålitelige og verdifulle prediksjoner for beslutningstaking.
- Nøye utvalgte funksjoner eliminerer irrelevante eller overflødige attributter, noe som forenkler modeller og sparer beregningsressurser.
- Godt konstruerte funksjoner avslører datamønstre, og hjelper datavitere å forstå komplekse sammenhenger i datasettet.
- Ved å tilpasse funksjoner til spesifikke algoritmer kan man optimalisere modellens ytelse for ulike maskinlæringsmetoder.
- Godt konstruerte funksjoner fører til raskere modellopplæring og reduserte beregningskostnader, noe som effektiviserer arbeidsflyten.
Nå skal vi se nærmere på en trinnvis prosess for funksjonsteknikk.
Funksjonsteknikk trinn-for-trinn

- Datainnsamling: Det første trinnet er å samle inn rådata fra ulike kilder, som databaser, filer eller API-er.
- Datarensing: Når dataene er samlet inn, må de renses ved å identifisere og korrigere eventuelle feil, inkonsekvenser eller avvik.
- Håndtering av manglende verdier: Manglende verdier kan påvirke funksjonslageret til maskinlæringsmodellen. Hvis man ignorerer dem, kan modellen bli partisk. Det er viktig å undersøke disse verdiene og fylle inn manglende verdier eller utelate dem forsiktig, uten å påvirke modellen.
- Koding av kategoriske variabler: Du må konvertere kategoriske variabler til et numerisk format for å kunne brukes i maskinlæringsalgoritmer.
- Skalering og normalisering: Skalering sikrer at numeriske funksjoner er på en konsistent skala. Dette forhindrer at funksjoner med store verdier dominerer maskinlæringsmodellen.
- Funksjonsvalg: Dette trinnet hjelper deg med å identifisere og beholde de mest relevante funksjonene, redusere dimensjonalitet og forbedre modellens effektivitet.
- Oppretting av funksjoner: Noen ganger kan nye funksjoner konstrueres fra eksisterende funksjoner for å fange opp verdifull informasjon.
- Funksjonstransformasjon: Transformasjonsteknikker som logaritmer eller potensfunksjoner kan gjøre dataene mer egnet for modellering.
Nå går vi over til å diskutere de forskjellige funksjonsteknikkmetodene.
Funksjonsteknikkmetoder
#1. Hovedkomponentanalyse (PCA)
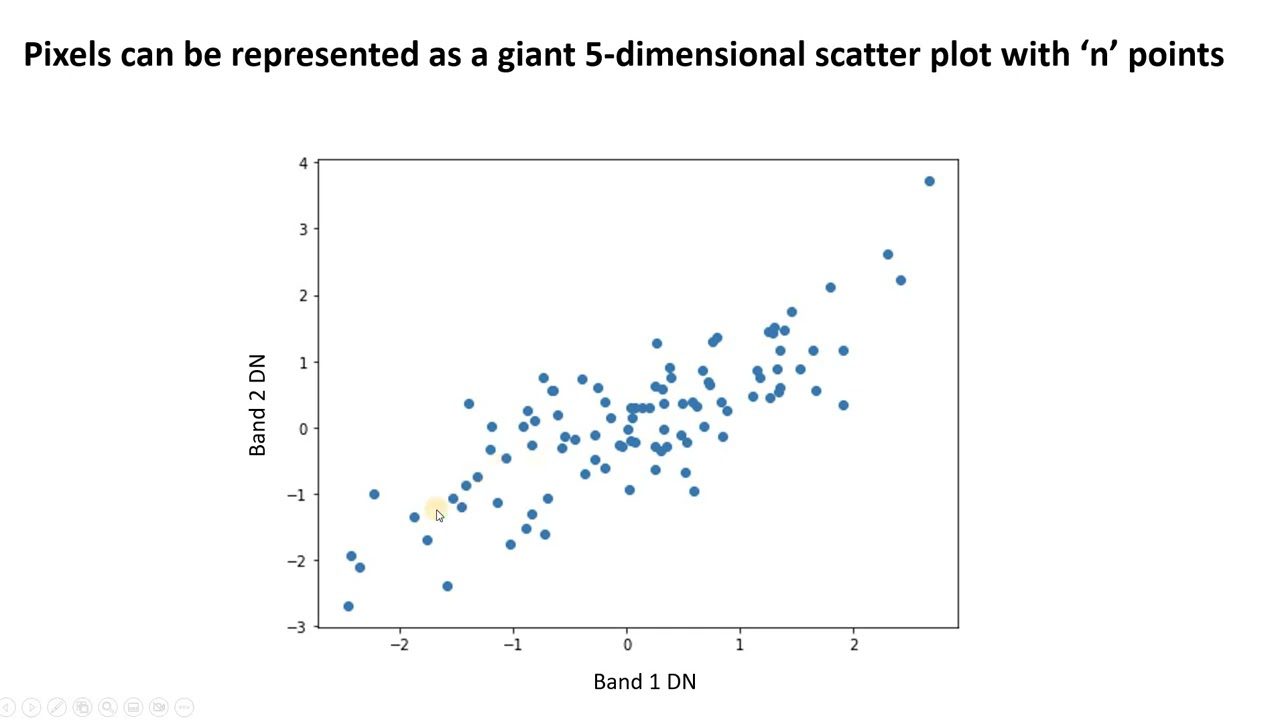
PCA forenkler komplekse data ved å identifisere nye, ikke-korrelerte funksjoner, som kalles hovedkomponenter. Den kan brukes for å redusere dimensjonalitet og forbedre modellens ytelse.
#2. Polynomfunksjoner
Å generere polynomfunksjoner innebærer å legge til potensledd til eksisterende funksjoner, for å fange opp komplekse relasjoner i data. Dette bidrar til at modellen kan tolke ikke-lineære mønstre.
#3. Håndtering av uteliggere
Uteliggere er uvanlige datapunkter som kan påvirke ytelsen til modeller. Det er viktig å identifisere og håndtere uteliggere for å unngå at resultatene blir skjeve.
#4. Logaritmisk transformasjon
Logaritmisk transformasjon kan brukes for å normalisere data som er skjevt fordelt. Den reduserer virkningen av ekstreme verdier, slik at dataene blir bedre egnet for modellering.
#5. T-distribuert stokastisk nabobasert innbygging (t-SNE)
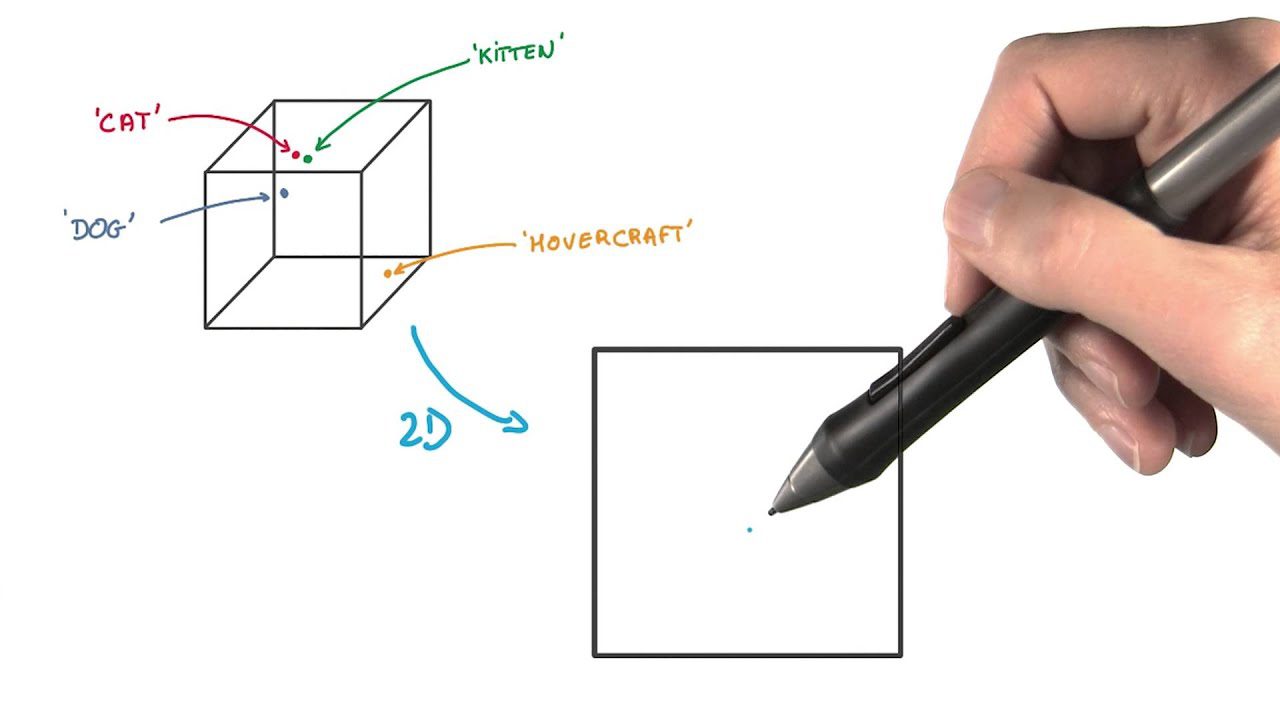
T-SNE er nyttig for å visualisere høydimensjonale data. Det reduserer dimensjonaliteten og gjør klynger mer synlige, samtidig som datastrukturen bevares.
I denne funksjonsekstraksjonsmetoden representeres datapunktene som prikker i et lavere dimensjonalt rom. Deretter plasseres de like datapunktene fra det opprinnelige høydimensjonale rommet nært hverandre i den lavere dimensjonale representasjonen.
Den skiller seg fra andre dimensjonsreduksjonsmetoder ved å bevare strukturen og avstandene mellom datapunktene.
#6. One-hot-koding
One-hot-koding transformerer kategoriske variabler til et binært format (0 eller 1). Dette skaper nye binære kolonner for hver kategori. One-hot-koding gjør kategoriske data egnet for bruk i maskinlæringsalgoritmer.
#7. Antallskoding
Antallskoding erstatter kategoriske verdier med antall ganger de forekommer i datasettet. Dette kan fange opp verdifull informasjon fra kategoriske variabler.
I denne funksjonsutviklingsmetoden benyttes frekvensen eller antallet for hver kategori som en ny numerisk funksjon, i stedet for de originale kategorietikettene.
#8. Funksjonsstandardisering

Funksjoner med store verdier kan ofte dominere funksjoner med små verdier. Dette kan føre til at maskinlæringsmodellen blir partisk. Standardisering forhindrer denne typen skjevheter.
Standardiseringsprosessen omfatter vanligvis følgende to teknikker:
- Z-Score-standardisering: Denne metoden transformerer hver funksjon slik at den får et gjennomsnitt på 0 og et standardavvik på 1. Her trekker man gjennomsnittet av funksjonen fra hvert datapunkt, og deler resultatet på standardavviket.
- Min-maks-skalering: Min-maks-skalering transformerer dataene til et bestemt område, vanligvis mellom 0 og 1. Dette oppnås ved å trekke fra minimumsverdien av funksjonen fra hvert datapunkt, og dele resultatet på området.
#9. Normalisering
Normalisering innebærer å skalere numeriske funksjoner til et felles område, vanligvis mellom 0 og 1. Dette opprettholder de relative forskjellene mellom verdier og sikrer at alle funksjoner er på lik linje.

#1. Funksjonsverktøy
Funksjonsverktøy er et åpen kildekode Python-rammeverk som automatisk genererer funksjoner fra tidsbaserte og relasjonelle datasett. Det kan brukes sammen med verktøy du allerede bruker for å utvikle maskinlæringspipeliner.
Løsningen benytter Deep Feature Synthesis for å automatisere funksjonsutviklingen. Det finnes også et bibliotek med lavnivåfunksjoner for funksjonsoppretting. Featuretools har også et API som er ideelt for presis håndtering av tid.
#2. CatBoost
Hvis du er på jakt etter et åpen kildekode-bibliotek som kombinerer flere beslutningstrær for å skape en kraftig prediktiv modell, bør du vurdere CatBoost. Denne løsningen gir nøyaktige resultater med standardparametere, slik at du slipper å bruke mye tid på å finjustere parametrene.
CatBoost lar deg også bruke ikke-numeriske faktorer for å forbedre treningsresultatene. I tillegg kan du forvente mer nøyaktige resultater og raske prediksjoner.
#3. Funksjonsmotor
Funksjonsmotor er et Python-bibliotek med mange transformatorer og utvalgte funksjoner som kan brukes i maskinlæringsmodeller. Transformatorene kan brukes til variabeltransformasjon, variabeloppretting, datofunksjoner, forbehandling, kategorisk koding, avgrensning eller fjerning og imputering av manglende data. Biblioteket gjenkjenner numeriske, kategoriske og tidsbaserte variabler automatisk.
Læringsressurser for funksjonsteknikk
Nettkurs og virtuelle klasser

#1. Funksjonsteknikk for maskinlæring i Python: Datacamp
Dette Datacamp- kurset om funksjonsteknikk for maskinlæring i Python gir deg muligheten til å skape nye funksjoner som forbedrer ytelsen til maskinlæringsmodellene. Du lærer om funksjonsutvikling og datamunging for å utvikle avanserte maskinlæringsapplikasjoner.
#2. Funksjonsteknikk for maskinlæring: Udemy
Fra dette funksjonsteknikkkurset for maskinlæring lærer du blant annet om imputering, variabelkoding, funksjonsekstraksjon, diskretisering, tidsfunksjonalitet, uteliggere osv. Deltakerne vil også lære å jobbe med skjeve variabler og å håndtere sjeldne, usynlige og sjeldne kategorier.
#3. Funksjonsteknikk: Pluralsight
Denne læringsstien hos Pluralsight inneholder totalt seks emner. Kursene vil hjelpe deg med å lære viktigheten av funksjonsteknikk i maskinlæringsarbeidsflyt, hvordan du kan bruke teknikkene og funksjonsutvinning fra tekst og bilder.
#4. Funksjonsvalg for maskinlæring: Udemy
Gjennom dette kurset på Udemy kan deltakerne lære om funksjonsutvelgelse, filtrering, innpaknings- og innebygde metoder, rekursiv funksjonseliminering og grundig søk. Det diskuteres også funksjonsvalgteknikker, inkludert de som benytter Python, Lasso og beslutningstrær. Kurset omfatter 5,5 timer med on-demand video og 22 artikler.
#5. Funksjonsteknikk for maskinlæring: Great Learning
Dette kurset fra Great Learning introduserer deg for funksjonsteknikk og oversampling og undersampling. Du får også muligheten til å gjennomføre praktiske øvelser for modellinnstilling.
#6. Funksjonsteknikk: Coursera
Bli med på Coursera-kurset for å lære å bruke BigQuery ML, Keras og TensorFlow til funksjonsutvikling. Dette kurset på mellomnivå dekker også avansert funksjonsteknikk.
Digitale bøker og innbundne bøker

#1. Funksjonsteknikk for maskinlæring
Denne boken lærer deg hvordan du transformerer funksjoner til formater som kan brukes i maskinlæringsmodeller.
Du lærer om prinsipper for funksjonsteknikk og praktisk anvendelse gjennom trening.
#2. Funksjonsteknikk og -utvalg
Ved å lese denne boken vil du lære metodene for å utvikle prediktive modeller i ulike faser.
Du lærer teknikker for å finne de beste representasjonene for modellering.
#3. Funksjonsteknikk gjort enkelt
Boken er en guide for å forbedre forutsigbarheten til maskinlæringsalgoritmer.
Den lærer deg å designe og skape effektive funksjoner for maskinlæringsbaserte applikasjoner, med dyptgående datainnsikt.
#4. Funksjonsteknikk Bookcamp
Denne boken går gjennom praktiske eksempler for å lære funksjonsteknikker for bedre maskinlæringsresultater og oppgraderte datahåndteringsteknikker.
Ved å lese denne boken vil du kunne oppnå bedre resultater uten å bruke mye tid på å finjustere maskinlæringsparametere.
#5. The Art of Feature Engineering
Denne ressursen er viktig for enhver datavitenskapsmann eller maskinlæringsingeniør.
Boken tar i bruk en tverrfaglig tilnærming for å diskutere grafer, tekster, tidsserier, bilder og casestudier.
Konklusjon
Dette er en oversikt over hvordan du kan utføre funksjonsutvikling. Nå som du kjenner definisjonen, trinnvise prosesser, metoder og læringsressurser, kan du begynne å implementere dem i dine egne maskinlæringsprosjekter og se hvor vellykket det kan være!
Som et neste steg kan du lese artikkelen om forsterkende læring.