Webskraping gir deg muligheten til å samle store mengder data fra internett raskt og effektivt. Det er spesielt nyttig når nettsider ikke presenterer dataene sine på en strukturert måte via Application Programming Interfaces (API).
La oss si du utvikler en applikasjon som sammenligner priser på varer fra forskjellige nettbutikker. Hvordan ville du gå frem? En mulighet er å manuelt sjekke prisene på alle varer på alle nettstedene og notere deg funnene. Dette er imidlertid ikke særlig effektivt, da det finnes tusenvis av produkter på e-handelsplattformer, og det ville ta svært lang tid å samle inn den relevante dataen.
En bedre metode er å bruke webskraping. Webskraping er en prosess der programvare automatisk henter data fra nettsider og nettsteder.
Programvareskripter, kjent som webskrapere, brukes til å aksessere nettsider og hente ut data. Dataen som hentes, ofte i en ustrukturert form, kan deretter analyseres og lagres på en strukturert måte som er meningsfull for brukerne.
Webskraping er svært verdifullt for datautvinning, da det gir tilgang til store mengder data og muliggjør automatisering. Du kan for eksempel planlegge at skriptet skal kjøre på bestemte tidspunkter eller som respons på spesifikke hendelser. Webskraping muliggjør også sanntidsoppdateringer og forenkler markedsundersøkelser.

Mange virksomheter og selskaper benytter seg av webskraping for å hente data til analyse. Bedrifter innenfor HR, e-handel, finans, eiendom, reise, sosiale medier og forskning bruker webskraping for å hente ut relevant informasjon fra nettsider.
Google bruker også webskraping for å indeksere nettsider på internett og presentere relevante søkeresultater til brukerne.
Det er imidlertid viktig å være forsiktig ved webskraping. Selv om det ikke er ulovlig å skrape offentlig tilgjengelig data, tillater ikke alle nettsteder skraping. Dette kan skyldes sensitiv brukerinformasjon, at deres brukervilkår eksplisitt forbyr webskraping eller at de beskytter åndsverk.
Noen nettsteder tillater ikke webskraping fordi det kan overbelaste deres servere og føre til økte båndbreddekostnader, spesielt ved stor skala skraping.
For å sjekke om et nettsted tillater skraping, kan du legge til /robots.txt til nettstedets URL. Filen robots.txt brukes for å informere roboter om hvilke deler av nettstedet som kan skrapes. For eksempel, for å sjekke om du kan skrape Google, går du til google.com/robots.txt
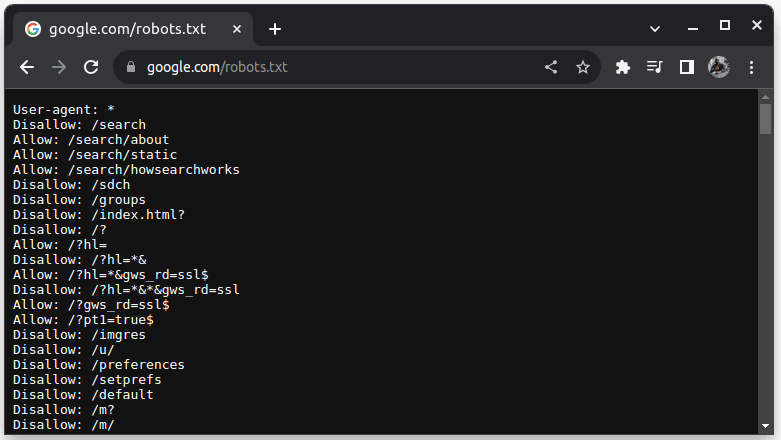
«User-agent: *» refererer til alle roboter eller programvareskript og crawlere. «Disallow» brukes for å informere roboter om at de ikke har tilgang til noen URL-er under en bestemt katalog, for eksempel /search. «Allow» angir kataloger hvor de kan få tilgang til URL-er fra.
Et eksempel på et nettsted som ikke tillater skraping, er LinkedIn. For å sjekke om du kan skrape LinkedIn, gå til linkedin.com/robots.txt.
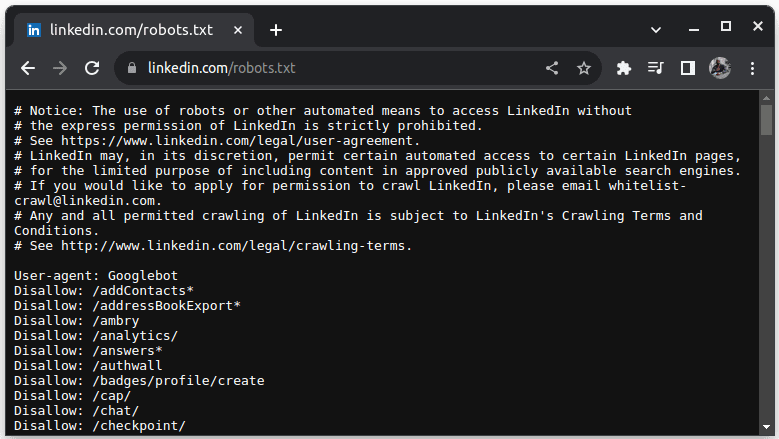
Som du ser, er det ikke tillatt å skrape LinkedIn uten tillatelse. Du bør alltid sjekke om et nettsted tillater skraping for å unngå juridiske problemer.
Hvorfor Java er et passende språk for webskraping
Selv om du kan lage en webskraper i mange programmeringsspråk, er Java spesielt godt egnet for oppgaven av flere grunner. For det første har Java et stort og rikt økosystem med et omfattende fellesskap, og det tilbyr en rekke biblioteker for webskraping, som JSoup, WebMagic og HTMLUnit. Disse bibliotekene forenkler utviklingen av webskrapere.

Det finnes også HTML-parsing-biblioteker som forenkler prosessen med å trekke ut data fra HTML-dokumenter, og nettverksbiblioteker som HttpURLConnection for å sende forespørsler til ulike nettadresser.
Javas sterke støtte for samtidighet og multithreading er også fordelaktig ved webskraping, da det gir mulighet for parallell behandling av webskrapingsjobber med flere forespørsler. Dette betyr at du kan skrape flere sider samtidig. Skalerbarhet er en sentral styrke ved Java, noe som gjør det mulig å skrape nettsteder i stor skala med en webskraper skrevet i Java.
Javas plattformuavhengighet er også en fordel. Det lar deg skrive en webskraper og kjøre den på et hvilket som helst system som har en kompatibel Java Virtual Machine (JVM). Dette betyr at du kan skrive en webskraper i ett operativsystem og kjøre den i et annet uten å gjøre endringer i koden.
Java kan også brukes sammen med hodeløse nettlesere som Headless Chrome, HTML Unit, Headless Firefox og PhantomJs. En hodeløs nettleser er en nettleser uten et grafisk brukergrensesnitt. Hodeløse nettlesere kan simulere brukerinteraksjoner, noe som er veldig nyttig når du skraper nettsider som krever brukerinteraksjon.
I tillegg er Java et svært populært og mye brukt språk som er enkelt å integrere med en rekke verktøy som databaser og databehandlingsrammeverk. Dette er en fordel, da det sikrer at verktøyene du trenger for å skrape, behandle og lagre data, sannsynligvis støtter Java.
La oss se på hvordan vi kan bruke Java til webskraping.
Java for webskraping: Forutsetninger
For å bruke Java i webskraping må følgende forutsetninger være oppfylt:
1. Java – Du bør ha Java installert, helst den nyeste versjonen med langvarig støtte. Hvis du ikke har Java installert, finner du informasjon om hvordan du installerer Java på maskinen din ved å søke etter «installer Java» på internett.
2. Integrert utviklingsmiljø (IDE) – Du bør ha en IDE installert på maskinen din. I denne opplæringen bruker vi IntelliJ IDEA, men du kan bruke en hvilken som helst IDE du er komfortabel med.
3. Maven – Dette vil bli brukt til avhengighetshåndtering og for å installere et bibliotek for webskraping.
Hvis du ikke har Maven installert, kan du installere det ved å åpne terminalen og kjøre:
sudo apt install maven
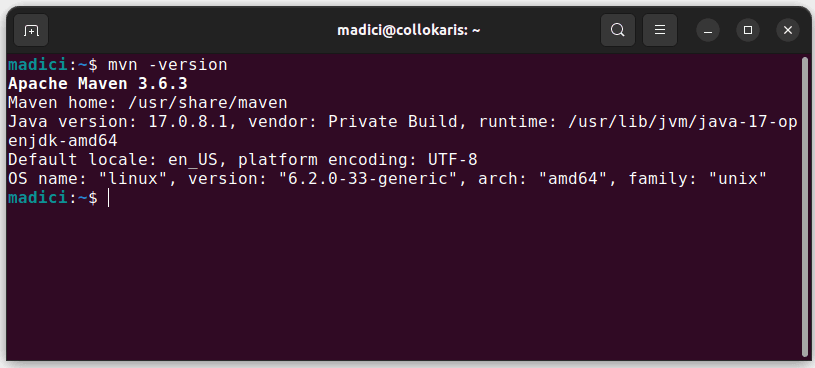
Dette installerer Maven fra det offisielle depotet. Du kan bekrefte at Maven ble installert ved å kjøre:
mvn -version
Hvis installasjonen var vellykket, bør du få en utskrift som dette:
Sette opp miljøet
Slik setter du opp miljøet ditt:
1. Åpne IntelliJ IDEA. Klikk på «Prosjekter» i venstre menylinje, og velg «Nytt prosjekt».
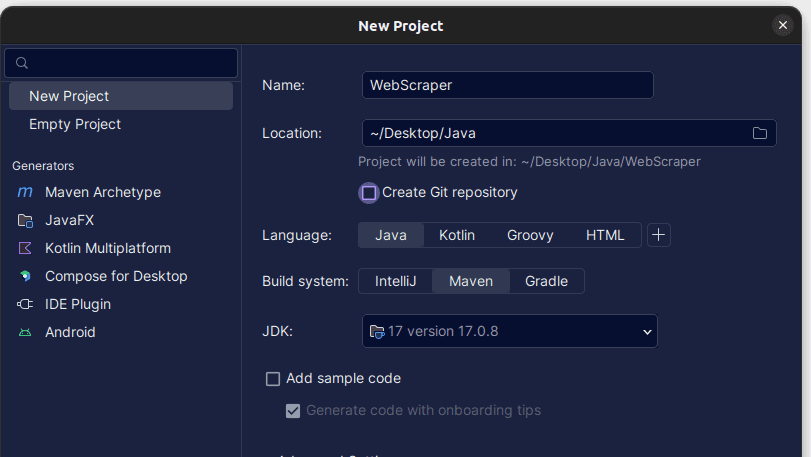
2. I vinduet «Nytt prosjekt» som åpnes, fyll ut informasjonen som vist nedenfor. Sørg for at «Språk» er satt til Java, og at «Byggesystem» er satt til Maven. Du kan gi prosjektet et valgfritt navn og bruke «Plassering» for å spesifisere mappen der du vil at prosjektet skal opprettes. Når du er ferdig, klikker du på «Opprett».
3. Når prosjektet er opprettet, skal du ha en pom.xml-fil i prosjektet som vist nedenfor.
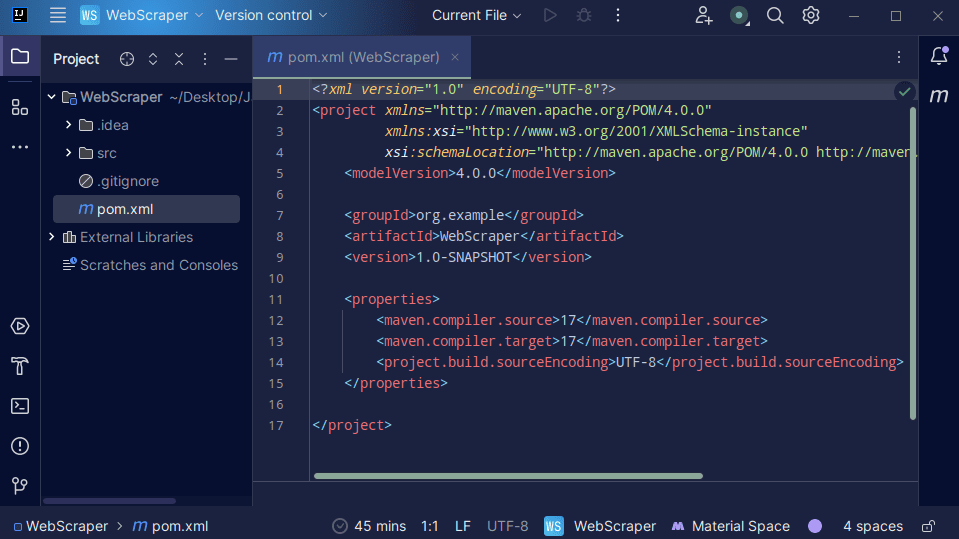
Pom.xml-filen opprettes av Maven og inneholder informasjon om prosjektet, samt konfigurasjonsdetaljer som Maven bruker for å bygge prosjektet. Det er også denne filen vi bruker for å angi at vi vil bruke eksterne biblioteker.
Når vi skal utvikle en webskraper, vil vi bruke jsoup-biblioteket. Vi må derfor legge det til som en avhengighet i pom.xml-filen slik at Maven kan gjøre det tilgjengelig i prosjektet vårt.
4. Legg til jsoup-avhengigheten i pom.xml-filen ved å kopiere koden nedenfor og lime den inn i din pom.xml-fil:
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Resultatet skal se ut som vist nedenfor:
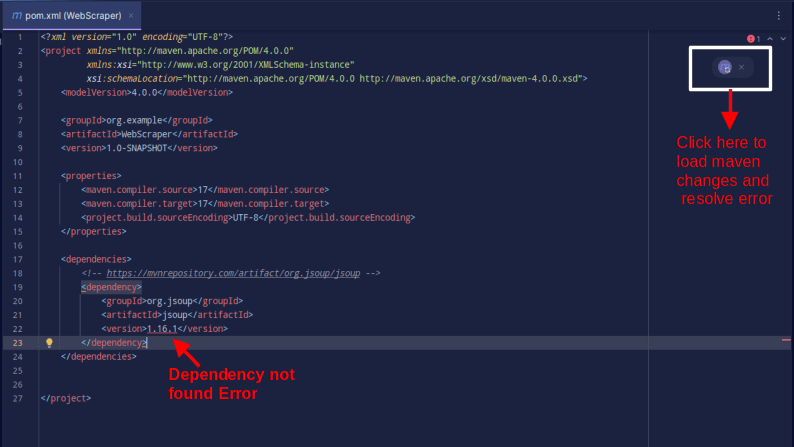
Hvis du får en feilmelding om at avhengigheten ikke ble funnet, klikker du på Maven-ikonet for å laste inn de nylige endringene, laste inn avhengigheten og fjerne feilen.
Nå er miljøet ditt klart.
Webskraping med Java
For å praktisere webskraping, skal vi skrape data fra ScrapeThisSite. Dette nettstedet tilbyr en sandkasse der utviklere kan øve på webskraping uten å bekymre seg for juridiske spørsmål.
For å skrape et nettsted med Java, gjør du følgende:
1. I venstre menylinje i IntelliJ åpner du src-katalogen, deretter main-katalogen, som er inne i src-katalogen. main-katalogen inneholder en katalog som heter java. Høyreklikk på den og velg «Ny», deretter «Java Class».
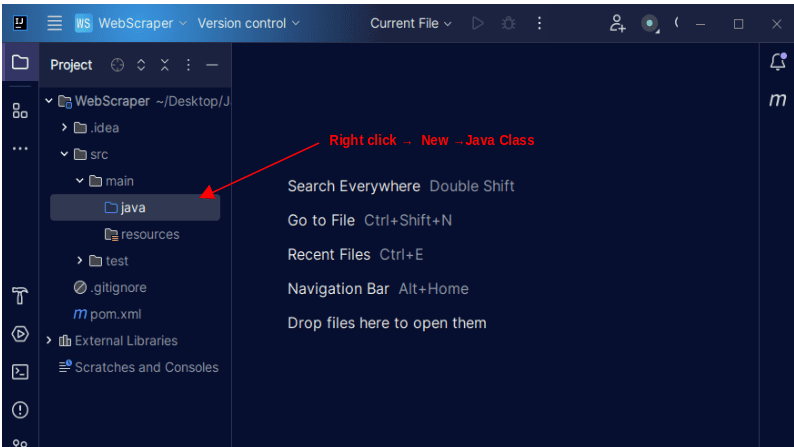
Gi klassen et valgfritt navn, for eksempel WebScraper, og trykk deretter Enter for å opprette en ny Java-klasse.
Åpne den nyopprettede filen som inneholder Java-klassen du nettopp opprettet.
2. Webskraping innebærer å hente data fra nettsteder. Derfor må vi spesifisere URL-en vi ønsker å skrape data fra. Når vi har spesifisert URL-en, må vi koble til URL-en og lage en GET-forespørsel for å hente HTML-innholdet på siden.
Koden som gjør dette, er vist nedenfor:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("En IOException oppsto. Vennligst prøv igjen.");
}
}
}
Utskrift:
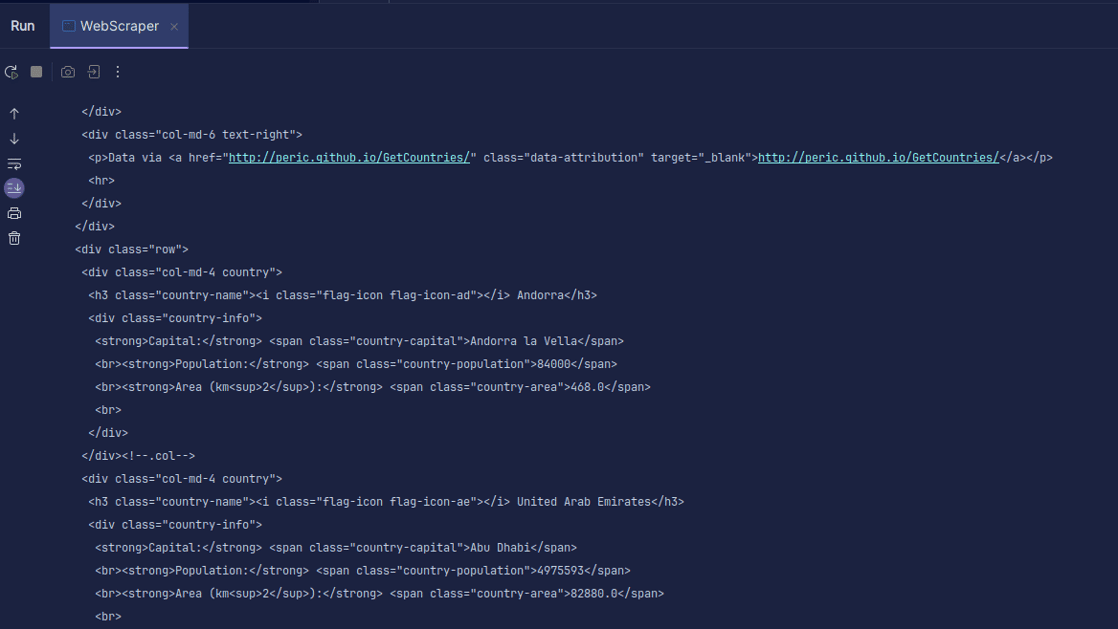
Som du ser, returneres HTML-en til siden, og det er det vi skriver ut. Når du skraper, kan URL-en du oppgir ha en feil, eller ressursen du prøver å skrape, finnes ikke. Derfor er det viktig å pakke koden vår inn i en try-catch-blokk.
Linjen:
Document doc = Jsoup.connect(url).get();
brukes for å koble til URL-en du ønsker å skrape. Metoden get() brukes for å lage en GET-forespørsel og hente HTML-en på siden. Resultatet som returneres, lagres deretter i et JSOUP Document-objekt, kalt doc. Ved å lagre resultatet i et JSOUP-dokument kan du bruke JSOUP API for å manipulere den returnerte HTML-en.
3. Gå til ScrapeThisSite og inspiser siden. I HTML-en skal du se strukturen vist nedenfor:
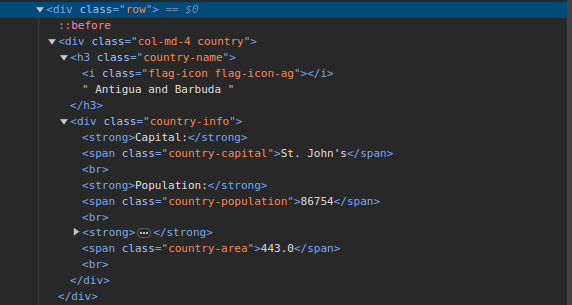
Legg merke til at alle landene på siden er lagret under en lignende struktur. Det er en div med en klasse kalt «land» som inneholder et h3-element med en klasse med «country-name», som inneholder navnet på hvert land på siden.
Inne i hoveddiven er det en annen div med klassen «country-info», som inneholder informasjon som hovedstad, befolkning og landareal. Vi kan bruke disse klassenavnene til å velge HTML-elementene og trekke ut informasjon fra dem.
4. Trekk ut spesifikt innhold fra HTML-en på siden ved å bruke følgende linjer:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Befolkning - " + population);
}
Vi bruker metoden select() for å velge elementer fra HTML-en på siden som samsvarer med den spesifikke CSS-velgeren vi sender inn. I dette tilfellet sender vi inn klassenavnene. Ved å inspisere siden ser vi at all landinformasjon er lagret i en div med klassen «land».
Hvert land har sin egen div med klassen «land», og denne diven inneholder informasjon som landets navn, hovedstad og befolkning.
Derfor velger vi først alle landene på siden ved å bruke klassen «.country». Vi lagrer dette i en variabel som kalles countries, som er av typen Elements, og fungerer som en liste. Vi bruker deretter en for-løkke for å gå gjennom landene og trekke ut landets navn, hovedstad og befolkning og skrive ut funnene.
Hele kodebasen vår er vist nedenfor:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Befolkning - " + population);
}
} catch (IOException e) {
System.out.println("En IOException oppsto. Vennligst prøv igjen.");
}
}
}
Utskrift:
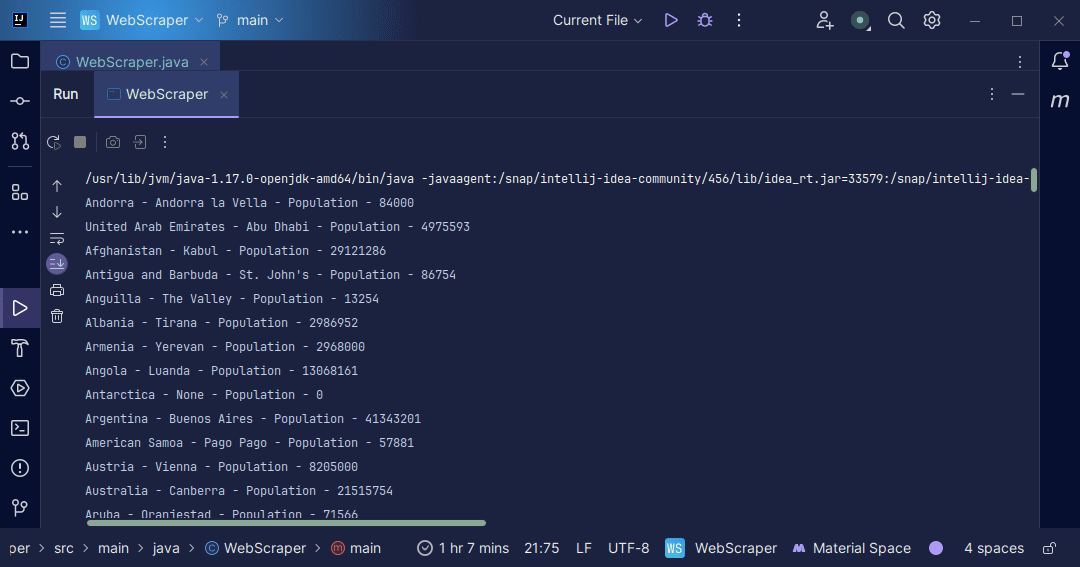
Med informasjonen vi får fra siden, kan vi gjøre en rekke ting, for eksempel å skrive den ut som vi gjorde eller lagre den i en fil dersom vi ønsker å utføre videre databehandling.
Konklusjon
Webskraping er en utmerket måte å hente ustrukturert data fra nettsteder, lagre dataen på en strukturert måte og behandle dataene for å trekke ut meningsfull informasjon. Det er likevel viktig å være forsiktig ved webskraping, da ikke alle nettsteder tillater det.
For å være på den sikre siden, bruk nettsteder som tilbyr sandkasser for å øve på skraping. Du bør alltid undersøke robots.txt for hvert nettsted du vil skrape for å finne ut om nettstedet tillater skraping.
Java er et utmerket språk for å skrive webskrapere, da det gir biblioteker som gjør webskraping enklere og mer effektiv. Som Java-utvikler vil utviklingen av en webskraper bidra til å forbedre dine programmeringsferdigheter. Så prøv å skrive din egen webskraper, eller modifiser den som er brukt i denne artikkelen for å hente ut andre typer informasjon. Lykke til med kodingen!
Du kan også utforske noen populære skybaserte løsninger for webskraping.