Linux-kommandoen curl er langt mer allsidig enn bare et verktøy for nedlasting av filer. La oss utforske de mange bruksområdene til curl, og se når det kan være et bedre alternativ enn wget.
curl vs. wget: Hva er de grunnleggende forskjellene?
Det er vanlig at brukere lurer på hva som skiller wget og curl. Begge kommandoene har overlappende funksjoner, spesielt når det gjelder å hente filer fra eksterne servere. Men der stopper også likheten.
Wget er et utmerket verktøy for å laste ned innhold og filer. Det kan laste ned alt fra enkelte filer til hele nettsider og mapper. Wget har avanserte funksjoner for å følge lenker på nettsider og laste ned innhold rekursivt fra et helt nettsted. Dermed er det den ubestridte mesteren når det gjelder kommandolinjebasert nedlasting.
Curl har et helt annet fokus. Riktignok kan curl hente filer, men det mangler funksjonen for rekursiv navigering på nettsteder. Curl spesialiserer seg i interaksjon med eksterne systemer. Den sender forespørsler og mottar svar. Disse svarene kan inkludere nettsideinnhold og filer, men også data fra en nettjeneste eller et API, avhengig av hva som etterspørres.
I tillegg er ikke curl begrenset til kun nettsider. Den støtter over 20 protokoller, som HTTP, HTTPS, SCP, SFTP og FTP. Curl er også kjent for sin gode integrasjon med Linux-rør, noe som gjør det enkelt å kombinere curl med andre kommandoer og skript.
Skaperen av curl har en nettside som forklarer forskjellene mellom curl og wget fra hans perspektiv.
Installasjon av curl
Under testingen av denne artikkelen var curl forhåndsinstallert på Fedora 31 og Manjaro 18.1.0. På Ubuntu 18.04 LTS måtte curl installeres manuelt. For å installere curl på Ubuntu, bruk følgende kommando:
sudo apt-get install curl

Curl-versjonen
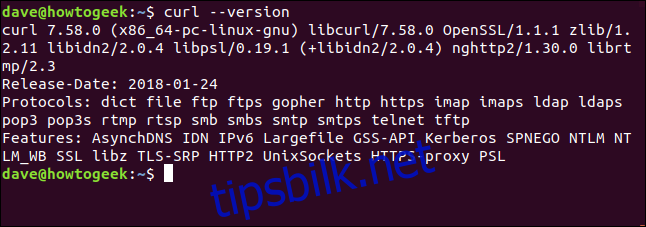
Alternativet --version gir informasjon om curl-versjonen og hvilke protokoller som støttes:
curl --version
Henting av en nettside
For å hente en nettside, oppgir du bare URL-en som parameter til curl:
curl https://www.bbc.com

Som standard vil curl dumpe kildekoden til nettsiden i terminalvinduet.
Vær oppmerksom på at dersom du ikke spesifiserer at du vil lagre innholdet som en fil, vil curl alltid sende det til terminalen. Hvis filen som hentes er binær, kan resultatet være uforutsigbart. Skallet kan prøve å tolke enkelte byteverdier som kontrolltegn eller escape-sekvenser.
Lagring av data til en fil
For å lagre utdataene i en fil, bruker vi omdirigering:
curl https://www.bbc.com > bbc.html

Denne gangen vises ikke det hentede innholdet i terminalvinduet. Isteden lagres det direkte i filen. Siden det ikke er noe terminalvindu å vise fremdrift i, genererer curl en fremdriftsrapport.
Dette skjedde ikke i det forrige eksempelet. Da ville fremdriftsrapporten blandes med kildekoden, så curl undertrykte den automatisk.
I dette eksempelet ser curl at utdataene blir omdirigert til en fil, og viser derfor fremdriftsinformasjon.

Informasjonen som vises er:
| % Total: | Total mengde data som skal hentes. |
| % Mottatt: | Prosentandel og faktisk mengde data som er hentet hittil. |
| % Xferd: | Prosent og faktisk mengde data som er sendt, hvis data lastes opp. |
| Gjennomsnittlig nedlastingshastighet: | Gjennomsnittlig nedlastingshastighet. |
| Gjennomsnittlig opplastingshastighet: | Gjennomsnittlig opplastingshastighet. |
| Time Total: | Estimat på total varighet for overføringen. |
| Tid brukt: | Tiden som har gått hittil for denne overføringen. |
| Tid igjen: | Beregnet tid som gjenstår før overføringen er fullført. |
| Current Speed: | Gjeldende overføringshastighet for denne overføringen. |
Fordi vi omdirigerte utdataene fra curl til en fil, har vi nå en fil som heter «bbc.html.»

Ved å dobbeltklikke på filen åpnes den i standardnettleseren, slik at du kan se den hentede nettsiden.

Merk at adressen i nettleserens adresselinje viser til en lokal fil på denne datamaskinen, og ikke et eksternt nettsted.
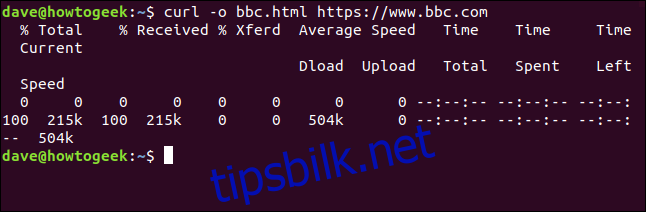
Vi trenger ikke å omdirigere utdataene for å lage en fil. Vi kan bruke alternativet -o (output) for å spesifisere filnavnet. I dette tilfellet vil vi lage en fil som heter «bbc.html»:
curl -o bbc.html https://www.bbc.com
Bruk av fremdriftslinje for nedlastinger
For å erstatte den tekstbaserte fremdriftsinformasjonen med en enkel fremdriftslinje, bruk alternativet -# (progress bar):
curl -# -o bbc.html https://www.bbc.com

Gjenoppta avbrutt nedlasting
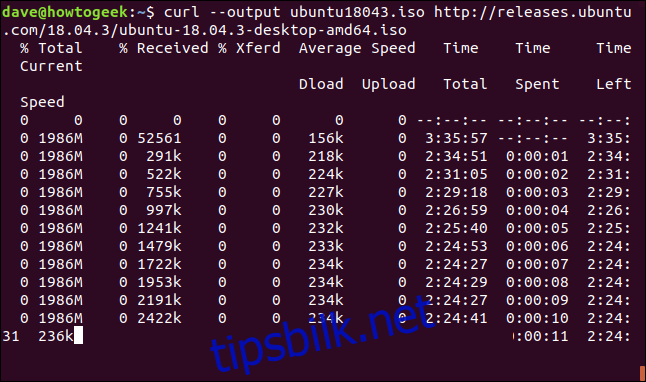
Det er enkelt å gjenoppta en nedlasting som har blitt avbrutt. La oss starte nedlastingen av en stor fil. Vi bruker den nyeste versjonen av Ubuntu 18.04 med langvarig støtte. Vi bruker alternativet --output for å spesifisere filnavnet vi ønsker å lagre filen i: «ubuntu180403.iso.»
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Nedlastingen starter og fortsetter mot fullføring.
Hvis vi avbryter nedlastingen med Ctrl+C, går vi tilbake til ledeteksten og nedlastingen avbrytes.
For å gjenoppta nedlastingen, bruk alternativet -C (continue on). Dette forteller curl å gjenoppta nedlastingen fra et spesifikt punkt. Hvis du oppgir en bindestrek som forskyvning, vil curl selv sjekke den allerede nedlastede delen av filen og finne den korrekte forskyvningen som skal brukes.
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Nedlastingen starter på nytt. Curl rapporterer forskyvningen der den starter på nytt.

Henting av HTTP-hoder
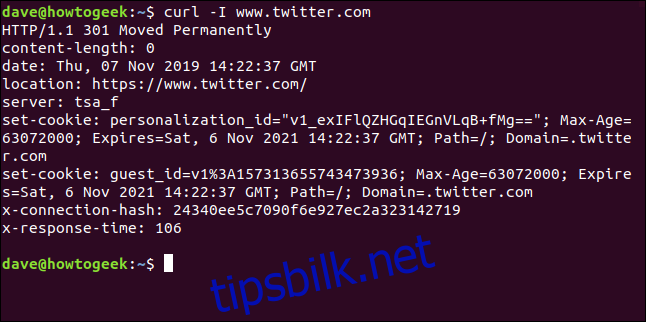
Med alternativet -I (head) kan du hente kun HTTP-hodene. Dette er det samme som å sende en HTTP HEAD-kommando til en webserver.
curl -I www.twitter.com

Denne kommandoen henter kun informasjon; den laster ikke ned noen nettsider eller filer.
Nedlasting av flere URL-er
Ved hjelp av xargs kan vi laste ned flere URL-er samtidig. La oss anta at vi ønsker å laste ned en serie nettsider som utgjør en enkelt artikkel eller veiledning.
Kopier disse nettadressene inn i et tekstredigeringsprogram og lagre dem i en fil som heter «urls-to-download.txt.» Vi kan bruke xargs til å behandle innholdet i hver linje i tekstfilen som en parameter som sendes til curl.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Dette er kommandoen vi må bruke for at xargs skal sende disse nettadressene til curl en etter en:
xargs -n 1 curl -O
Merk at denne kommandoen bruker -O (ekstern fil) for å lagre filen med samme navn som på den eksterne serveren.
Alternativet -n 1 forteller xargs å behandle hver linje i tekstfilen som en enkelt parameter.
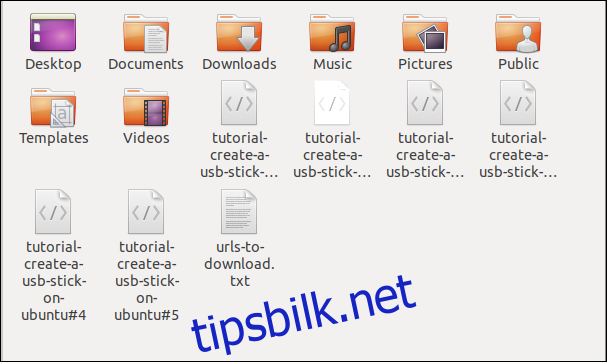
Når du kjører kommandoen, vil du se at flere nedlastinger starter og fullføres, en etter en.

En kikk i filbehandleren viser at flere filer er lastet ned. Hver enkelt fil har samme navn som på den eksterne serveren.
Nedlasting av filer fra en FTP-server
Det er enkelt å bruke curl med en File Transfer Protocol (FTP)-server, selv om du må autentisere deg med brukernavn og passord. For å oppgi brukernavn og passord med curl, bruk alternativet -u (user), og skriv inn brukernavnet, et kolon «:», og passordet. Ikke sett inn mellomrom før eller etter kolon.
Dette er en gratis FTP-server for testing, hostet av Rebex. Test FTP-siden har brukernavnet «demo» og passordet «password.» Unngå å bruke så svake brukernavn og passord på en produksjons- eller «ekte» FTP-server.
curl -u demo:password ftp://test.rebex.net

curl finner ut at vi peker den mot en FTP-server, og returnerer en liste over filene som er tilgjengelige på serveren.

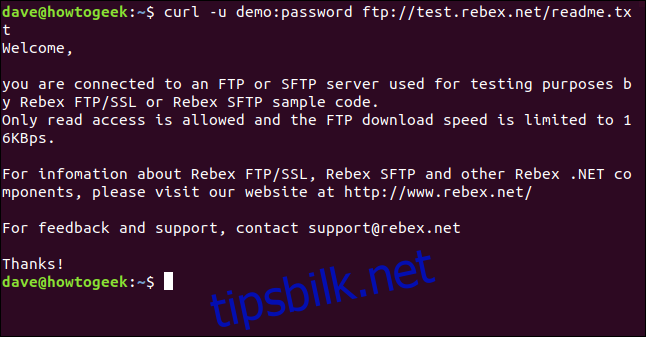
Den eneste filen på denne serveren er en «readme.txt»-fil som er 403 byte. La oss hente den. Bruk samme kommando som forrige gang, men legg til filnavnet:
curl -u demo:password ftp://test.rebex.net/readme.txt

Filen lastes ned, og curl viser innholdet i terminalvinduet.
I nesten alle tilfeller vil det være mer praktisk å lagre den nedlastede filen på disk, i stedet for å vise den i terminalvinduet. Nok en gang kan vi bruke -O (ekstern fil) for å lagre filen på disk, med samme filnavn som på den eksterne serveren.
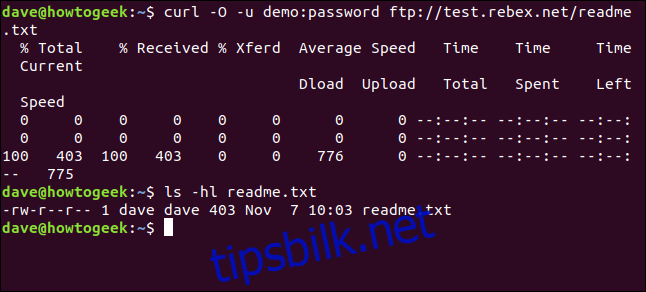
curl -O -u demo:password ftp://test.rebex.net/readme.txt

Filen lastes ned og lagres på disk. Vi kan bruke ls for å sjekke filinformasjonen. Filen har samme navn som på FTP-serveren, og den har samme lengde, 403 byte.
ls -hl readme.txt
Sende parametere til eksterne servere
Noen eksterne servere godtar parametere i forespørslene som sendes til dem. Parametrene kan brukes til å formatere de returnerte dataene, eller de kan brukes til å velge de spesifikke dataene som brukeren ønsker å hente. Det er ofte mulig å kommunisere med web API-er ved hjelp av curl.
Som et enkelt eksempel har ipify et API som kan spørres for å finne din eksterne IP-adresse.
curl https://api.ipify.org
Ved å legge til parameteren format med verdien json kan vi be om vår eksterne IP-adresse, men denne gangen vil de returnerte dataene være kodet i JSON-format.
curl https://api.ipify.org?format=json

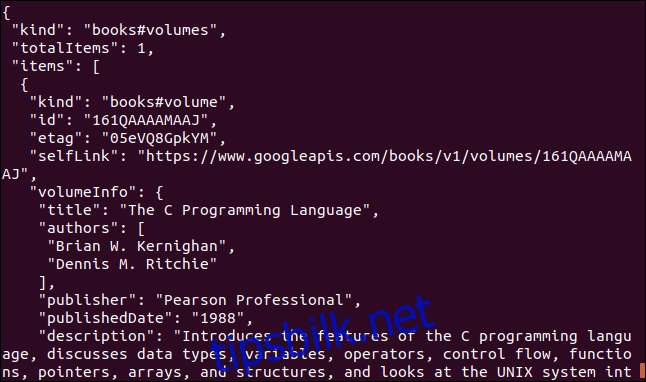
Her er et annet eksempel som bruker et Google API. Det returnerer et JSON-objekt som beskriver en bok. Parameteren du må oppgi er International Standard Book Number (ISBN)-nummeret til en bok. Du finner disse på baksiden av de fleste bøker, vanligvis under en strekkode. Parameteren vi skal bruke her er «0131103628.»
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

De returnerte dataene er omfattende:
Noen ganger curl, noen ganger wget
Hvis jeg ønsket å laste ned innhold fra et nettsted og samtidig rekursivt traversere trestrukturen til nettstedet for å finne innholdet, ville jeg valgt wget.
Hvis jeg ønsket å kommunisere med en ekstern server eller et API, og muligens laste ned noen filer eller nettsider, ville jeg brukt curl. Spesielt hvis protokollen var en av de mange som ikke støttes av wget.