Linux-kommandoen uniq analyserer tekstfilene dine for å identifisere unike eller gjentatte linjer. Denne veiledningen utforsker allsidigheten og funksjonene, og viser hvordan du kan utnytte dette praktiske verktøyet maksimalt.
Oppdagelse av like tekstlinjer i Linux
uniq-kommandoen er effektiv, tilpasningsdyktig og spesialdesignet for oppgaven. Som mange Linux-kommandoer har den visse særegenheter som det er greit å være klar over. Uten denne forkunnskapen kan det fort oppstå forvirring. Vi vil avklare disse særegenhetene underveis.
uniq er ideell for de som foretrekker spesialiserte verktøy som utfører en bestemt oppgave godt. Den egner seg spesielt godt til bruk i kombinasjon med andre kommandoer via pipes. En av dens hyppigste samarbeidspartnere er sort, siden uniq krever sortert input for å fungere korrekt.
La oss sette i gang!
Kjøring av uniq uten tilleggsvalg
Vi har en tekstfil som inneholder teksten til Robert Johnsons sang «I believe I’ll dust my broom». La oss undersøke hva som er unikt ved den.
Vi skriver inn følgende for å sende resultatet til less:
uniq dust-my-broom.txt | less

Vi ser hele sangen, inkludert gjentatte linjer, i less.
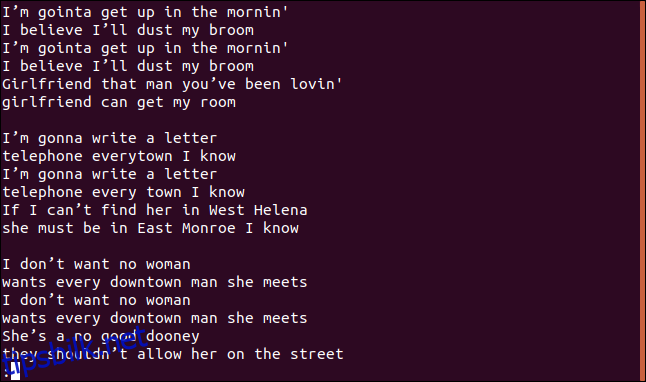
Det ser ikke ut til å være hverken de unike eller de gjentatte linjene.
Det er riktig – dette er den første innledende tilnærmingen. Når du kjører uniq uten tilleggsvalg, oppfører den seg som om du har brukt alternativet -u (unike linjer). Dette instruerer uniq om å skrive ut kun de unike linjene i filen. Grunnen til at du ser gjentatte linjer, er at for at uniq skal anse en linje som en duplikat, må den være ved siden av duplikatet, og det er her sort kommer inn.
Når vi sorterer filen, grupperes de gjentatte linjene, og uniq behandler dem som duplikater. Vi bruker sort på filen, videresender det sorterte resultatet til uniq, og deretter sender vi det endelige resultatet til less.
For å gjøre dette skriver vi følgende:
sort dust-my-broom.txt | uniq | less

En sortert liste over unike linjer vises i less.
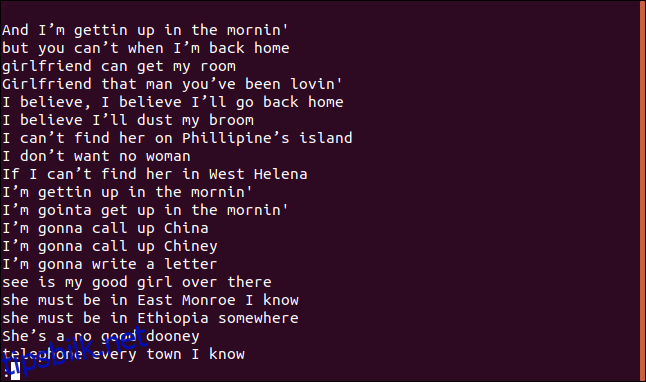
Linjen, «I believe I’ll dust my broom,» forekommer definitivt mer enn én gang i sangen. Faktisk gjentas den to ganger i de første fire linjene.
Så hvorfor vises den i en liste over unike linjer? Fordi første gang en linje vises i filen, er den unik; bare de påfølgende forekomstene er duplikater. Du kan tenke på det som en liste over den første forekomsten av hver unike linje.
La oss bruke sort igjen og sende utdataene til en ny fil. På denne måten trenger vi ikke bruke sortering i hver kommando.
Vi skriver inn følgende kommando:
sort dust-my-broom.txt > sorted.txt

Nå har vi en forhåndssortert fil å jobbe med.
Telle duplikater
Du kan bruke alternativet -c (telling) for å skrive ut hvor mange ganger hver linje vises i en fil.
Skriv inn følgende kommando:
uniq -c sorted.txt | less

Hver linje begynner med antallet ganger den linjen vises i filen. Du vil imidlertid legge merke til at den første linjen er tom. Dette forteller deg at det er fem tomme linjer i filen.
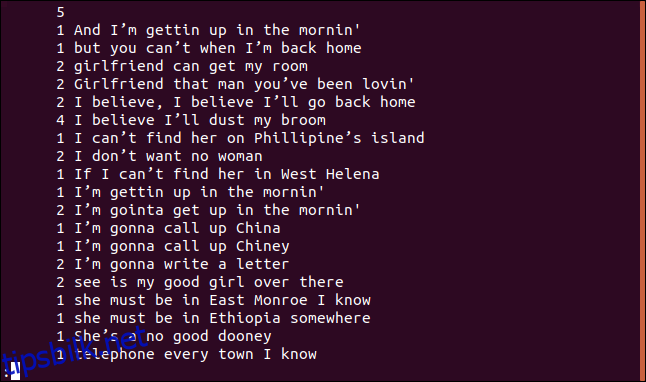
Hvis du vil at utdataene skal sorteres i numerisk rekkefølge, kan du sende utdataene fra uniq til sort. I vårt eksempel bruker vi alternativene -r (omvendt) og -n (numerisk sortering), og sender resultatene til less.
Vi skriver følgende:
uniq -c sorted.txt | sort -rn | less

Listen er sortert i synkende rekkefølge basert på frekvensen av hver linjes forekomst.
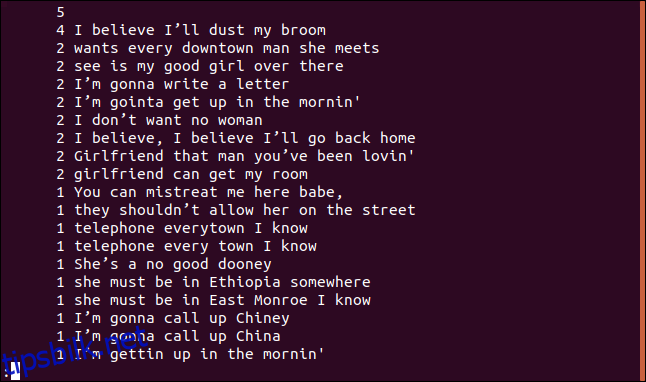
Lister kun dupliserte linjer
Hvis du bare vil se linjene som er gjentatt i en fil, kan du bruke alternativet -d (dupliserte). Uansett hvor mange ganger en linje er duplisert i en fil, vises den bare én gang.
For å bruke dette alternativet skriver vi følgende:
uniq -d sorted.txt

De dupliserte linjene er oppført for oss. Du vil legge merke til den tomme linjen øverst, noe som betyr at filen inneholder dupliserte tomme linjer – det er ikke noe mellomrom igjen av uniq for å forskyve oppføringen visuelt.
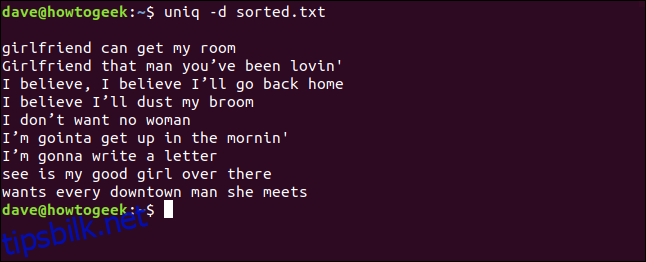
Vi kan også kombinere alternativene -d (dupliserte) og -c (telle) og sende utdataene gjennom sort. Dette gir oss en sortert liste over linjene som vises minst to ganger.
Skriv inn følgende for å bruke dette alternativet:
uniq -d -c sorted.txt | sort -rn
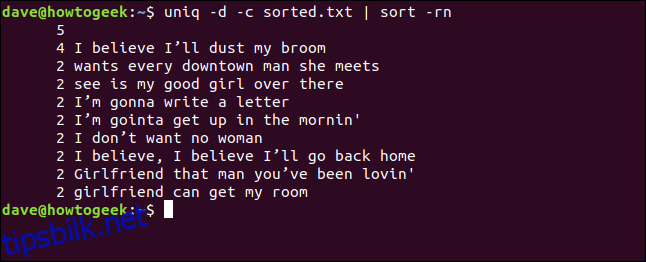
Liste over alle dupliserte linjer
Hvis du vil se en liste over hver dupliserte linje, samt en oppføring for hver gang en linje vises i filen, kan du bruke alternativet -D (alle dupliserte linjer).
For å bruke dette alternativet, skriver du følgende:
uniq -D sorted.txt | less

Oppføringen inneholder en oppføring for hver dupliserte linje.
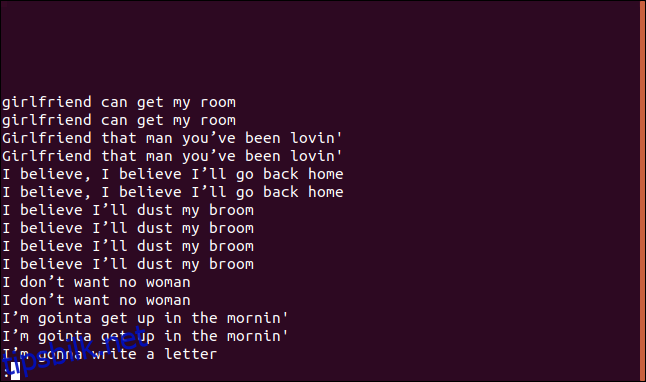
Hvis du bruker --group-alternativet, skrives hver dupliserte linje ut med en tom linje enten før (prepend) eller etter hver gruppe (append), eller både før og etter (both) hver gruppe.
Vi bruker append som modifikator, så vi skriver inn følgende:
uniq --group=append sorted.txt | less

Gruppene er atskilt med tomme linjer for å gjøre dem lettere å lese.
Kontrollere et visst antall tegn
Som standard sjekker uniq hele lengden på hver linje. Hvis du vil begrense sjekkene til et visst antall tegn, kan du imidlertid bruke alternativet -w (sjekk tegn).
I dette eksemplet gjentar vi den siste kommandoen, men begrenser sammenligningene til de tre første tegnene. For å gjøre det skriver vi følgende kommando:
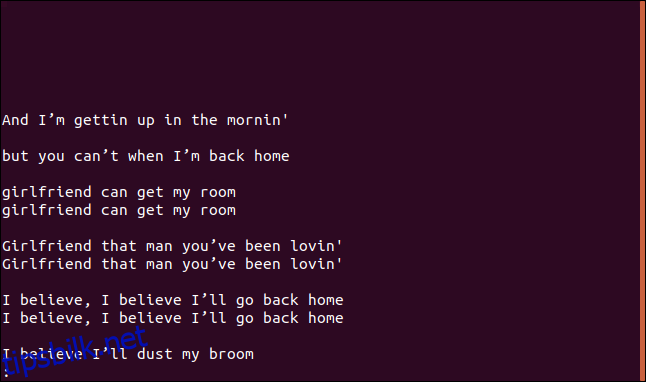
uniq -w 3 --group=append sorted.txt | less

Resultatene og grupperingene vi får er ganske forskjellige.
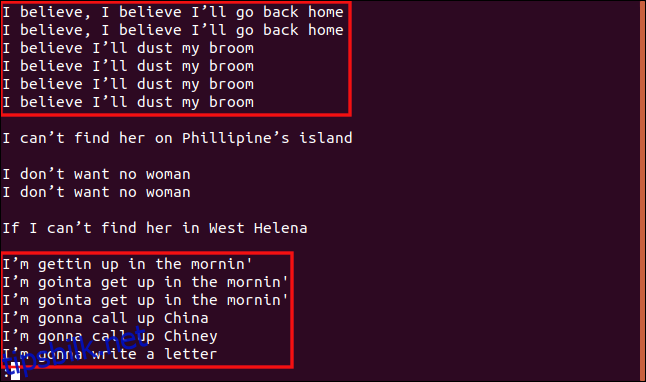
Alle linjer som starter med «I b» er gruppert sammen fordi disse delene av linjene er like, så de anses å være duplikater.
På samme måte behandles alle linjer som starter med «jeg» som duplikater, selv om resten av teksten er forskjellig.
Ignorere et visst antall tegn
Det finnes situasjoner der det kan være fordelaktig å hoppe over et visst antall tegn i starten av hver linje, for eksempel når linjene i en fil er nummerert. Eller si at du trenger uniq for å hoppe over et tidsstempel og begynne å sjekke linjene fra tegn seks i stedet for fra det første tegnet.
Nedenfor ser du en versjon av vår sorterte fil med nummererte linjer.
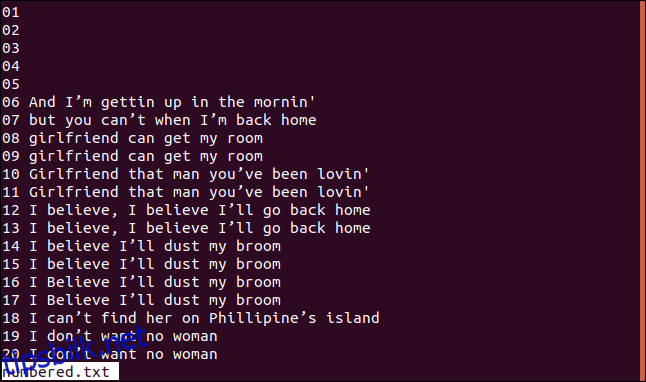
Hvis vi vil at uniq skal starte sine sammenligningssjekker ved tegn tre, kan vi bruke alternativet -s (hopp over tegn) ved å skrive følgende:
uniq -s 3 -d -c numbered.txt
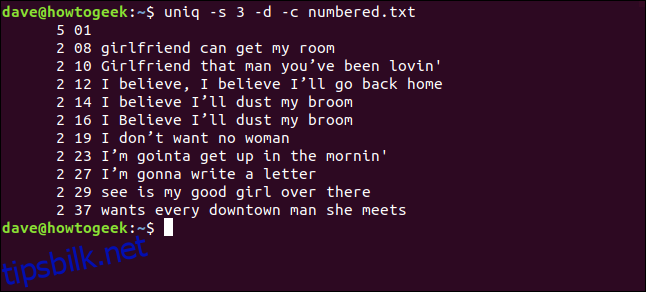
Linjene oppdages som duplikater og telles riktig. Merk at linjenumrene som vises, er for den første forekomsten av hvert duplikat.
Du kan også hoppe over felt (en serie tegn og et mellomrom) i stedet for tegn. Vi bruker alternativet -f (felt) for å fortelle uniq hvilke felt som skal ignoreres.
Vi skriver følgende for å fortelle uniq å ignorere det første feltet:
uniq -f 1 -d -c numbered.txt
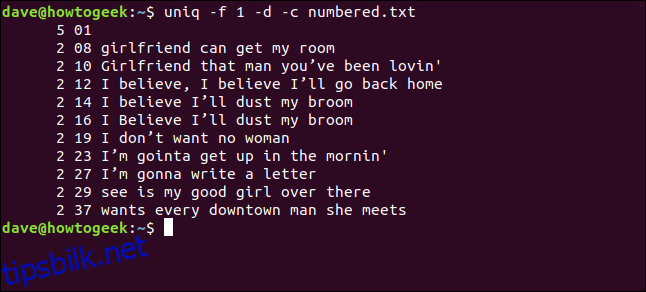
Vi får de samme resultatene som da vi ba uniq hoppe over tre tegn i begynnelsen av hver linje.
Ignorerer forskjeller i store og små bokstaver
Som standard skiller uniq mellom store og små bokstaver. Hvis den samme bokstaven vises med stor og liten bokstav, anser uniq linjene som forskjellige.
Sjekk for eksempel utdataene fra følgende kommando:
uniq -d -c sorted.txt | sort -rn
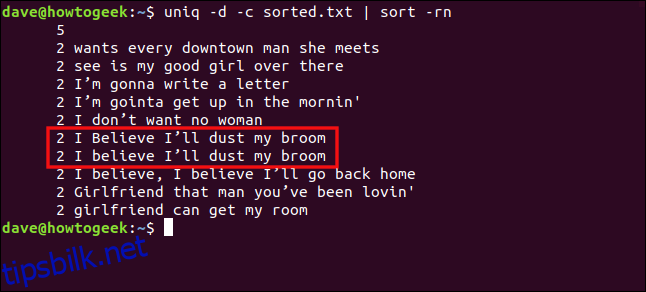
Linjene «I Believe I’ll dust my broom» og «I believe I’ll dust my broom» behandles ikke som duplikater på grunn av forskjellen i stor og liten bokstav i «B» i «believe».
Hvis vi inkluderer alternativet -i (ignorer store og små bokstaver), vil disse linjene imidlertid bli behandlet som duplikater. Vi skriver følgende:
uniq -d -c -i sorted.txt | sort -rn
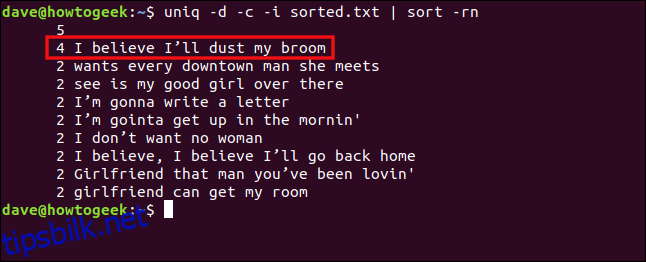
Linjene behandles nå som duplikater og grupperes sammen.
Linux gir deg en rekke spesialverktøy. Som mange av dem, er ikke uniq et verktøy du vil bruke hver dag.
Derfor er en viktig del av det å bli dyktig i Linux å huske hvilket verktøy som vil løse ditt nåværende problem, og hvor du kan finne det igjen. Men hvis du øver, er du på god vei.
Eller du kan alltids bare søke på How-To Geek – vi har sannsynligvis en artikkel om det.