Når man observerer utviklingen innen bedriftsprogramvare gjennom to tiår, fremstår den tydelige trenden de siste årene: overgangen av databaser til skyen.
Jeg har deltatt i flere migreringsprosjekter, der målet var å flytte eksisterende lokale databaser til Amazon Web Services (AWS) skybaserte databaser. Selv om AWS-dokumentasjonen beskriver prosessen som enkel, er min erfaring at gjennomføringen kan være utfordrende og i noen tilfeller mislykkes.
I dette innlegget vil jeg dele mine erfaringer fra følgende scenario:
- Kilden: Selv om kilden i teorien ikke spiller noen rolle (samme tilnærming kan brukes for de fleste populære databaser), har Oracle vært det foretrukne databasesystemet i store selskaper i mange år, og det er mitt fokus her.
- Målet: Målet er ikke spesifikt. Du kan velge hvilken som helst måldatabase i AWS, og tilnærmingen vil være relevant.
- Metoden: Oppdateringen kan være fullstendig eller inkrementell. Dataoverføringen kan være i batch (kilde og mål er ikke synkronisert) eller (nær) sanntids. Jeg vil dekke begge tilfeller.
- Hyppighet: Du kan ønske en engangsmigrering med full overgang til skyen, eller en overgangsperiode med data oppdatert på begge sider samtidig. Dette innebærer daglig synkronisering mellom lokale systemer og AWS. Den første metoden er enklere og mer logisk, men den andre er oftere forespurt og har flere risikomomenter. Jeg vil beskrive begge.
Problembeskrivelse
Kravet er ofte enkelt:
Vi vil utvikle tjenester i AWS, så vennligst kopier alle dataene våre til «ABC»-databasen. Raskt og enkelt. Vi trenger dataene i AWS nå. Senere skal vi vurdere hvilke deler av databasedesignet som skal endres for å matche behovene våre.
Før vi går videre, er det viktig å vurdere følgende:
- Ikke la deg for raskt friste av ideen om «bare kopier det vi har og ta det senere». Dette er den enkleste og raskeste løsningen, men det kan føre til et fundamentalt arkitektonisk problem som vil være vanskelig å fikse senere uten omfattende refaktorering av den nye skyplattformen. Skyøkosystemet er svært forskjellig fra det lokale. Nye tjenester vil bli introdusert over tid, og bruken vil naturlig endres. Det er sjelden en god idé å replikere den lokale tilstanden i skyen 1:1. Det kan være nødvendig i noen tilfeller, men dobbeltsjekk dette.
- Still kritiske spørsmål ved kravet, som:
- Hvem er den typiske brukeren av den nye plattformen? Mens det lokalt kan være en transaksjonell forretningsbruker, kan det i skyen være en dataforsker, analytiker eller en tjeneste (f.eks. Databricks, Glue, maskinlæringsmodeller osv.).
- Vil de vanlige daglige oppgavene forbli de samme etter overgangen til skyen? Hvis ikke, hvordan vil de endre seg?
- Forventer du en betydelig økning i data over tid? Mest sannsynlig er svaret ja, da dette ofte er hovedårsaken til å migrere til skyen. En ny datamodell må være forberedt på det.
- Prøv å forstå de vanlige forespørslene den nye databasen vil motta. Dette vil definere hvor mye den eksisterende datamodellen må endres for å opprettholde ytelsen.
Forberede migreringen
Når måldatabasen er valgt og datamodellen er diskutert, er neste steg å sette seg inn i AWS Schema Conversion Tool. Dette verktøyet kan hjelpe med:
- Analyse og uttrekk av kildedatamodellen. SCT leser den eksisterende lokale databasen og genererer en kildedatamodell.
- Forslag til en måldatamodellstruktur basert på måldatabasen.
- Generering av distribusjonsskript for måldatabasen. Disse skriptene installerer måldatamodellen (basert på informasjonen hentet fra kildedatabasen). Etter kjøring er databasen i skyen klar for dataimport fra den lokale databasen.
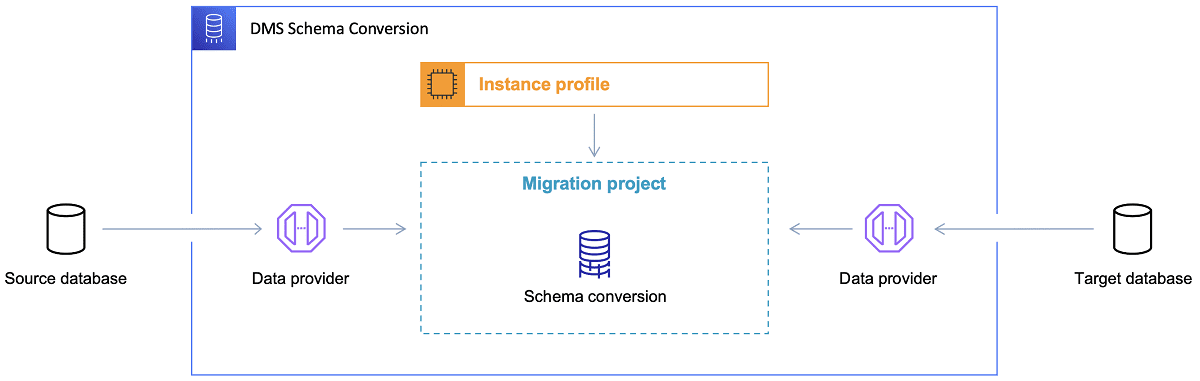
Her er noen tips for bruk av Schema Conversion Tool.
For det første, bør man sjelden bruke resultatene direkte. Betrakt dem heller som referanse, og gjør nødvendige justeringer basert på din forståelse av dataene og hvordan de skal brukes i skyen.
For det andre, tabellene ble tidligere valgt av brukere som forventet raske resultater om en bestemt dataenhet. Nå kan dataene bli valgt for analytiske formål. For eksempel kan databaseindekser som tidligere fungerte bra lokalt, nå være ubrukelige og ikke forbedre ytelsen. Det kan være nødvendig å partisjonere dataene annerledes i målsystemet enn i kildesystemet.
Det kan også være lurt å utføre datatransformasjoner under migreringsprosessen, som betyr å endre måldatamodellen for noen tabeller (slik at de ikke lenger er 1:1-kopier). Transformasjonsreglene må implementeres i migreringsverktøyet senere.
Hvis kilde- og måldatabasene er av samme type (f.eks. Oracle on-premise vs. Oracle i AWS, PostgreSQL vs. Aurora Postgresql, etc.), er det best å bruke et dedikert migreringsverktøy som databasen støtter (f.eks. eksport og import av datapumper, Oracle Goldengate, etc.).
I de fleste tilfeller vil kilde- og måldatabasen ikke være kompatible, og da vil AWS Database Migration Service være et godt valg.
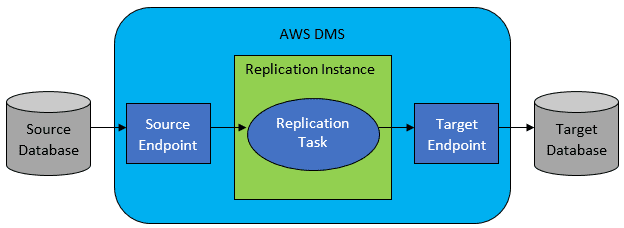
AWS DMS lar deg konfigurere en liste med oppgaver på tabellnivå, som definerer:
- Hvilken kildedatabase og tabell skal brukes.
- Spesifikasjoner for å hente data fra kildetabellen.
- Transformasjonsverktøy (hvis nødvendig), som definerer hvordan kildedataene skal mappes til måltabelldata (hvis ikke 1:1).
- Hvilken måldatabase og tabell dataene skal lastes inn i.
DMS-oppgavene konfigureres ved hjelp av JSON.
I det enkleste scenarioet er alt du trenger å gjøre å kjøre distribusjonsskriptene i måldatabasen og starte DMS-oppgaven. Men det er mer komplisert enn som så.
Engangs full datamigrering

Det enkleste tilfellet er når du skal flytte hele databasen én gang til skyen. Da vil prosessen se slik ut:
- Definer DMS-oppgave for hver kildetabell.
- Konfigurer DMS-jobbene riktig. Dette inkluderer parallellitet, cache-variabler, DMS-serverkonfigurasjon, dimensjonering av DMS-klyngen osv. Dette er den mest tidkrevende fasen, da det krever omfattende testing og optimalisering.
- Sørg for at hver måltabell er opprettet (tom) i måldatabasen med riktig tabellstruktur.
- Planlegg et tidsvindu for datamigreringen. Utfør ytelsestester for å sikre at tidsvinduet er tilstrekkelig. Kildedatabasen kan være begrenset under migreringen. Kildedatabasen skal ikke endres under migreringen, ellers kan de migrerte dataene være forskjellig fra dataene i kildedatabasen.
Hvis DMS er riktig konfigurert, skal alt gå bra i dette scenariet. Hver kildetabell blir kopiert til AWS-måldatabasen. De eneste bekymringene er ytelsen og tilstrekkelig lagringsplass.
Inkrementell daglig synkronisering

Dette er når det begynner å bli komplisert. I en ideell verden ville alt fungert perfekt, men verden er sjelden ideell.
DMS kan konfigureres til å fungere i to moduser:
- Full last – standardmodus som beskrevet ovenfor. DMS-oppgavene startes enten manuelt eller planlagt. Når ferdig, er oppgavene fullført.
- Endre datafangst (CDC) – i denne modusen kjører DMS-oppgaven kontinuerlig. DMS overvåker kildedatabasen for endringer på tabellnivå. Hvis endring oppstår, replikeres endringen til måldatabasen basert på konfigurasjonen.
Når du velger CDC, må du ta et valg om hvordan CDC henter endringer fra kilde-DB.
#1. Oracle Redo Loggleser
Et alternativ er å bruke Oracle’s databasers redo-loggleser, som CDC kan bruke for å hente de endrede dataene og replikere dem i måldatabasen.
Selv om dette kan virke som det opplagte valget for Oracle, er det en hake: Oracle redo-loggleser bruker kilde-Oracle-klyngen og påvirker de andre aktivitetene i databasen, da den oppretter aktive økter.
Jo flere DMS-oppgaver du har konfigurert (eller jo flere DMS-klynger parallelt), jo mer sannsynlig må du oppgradere Oracle-klyngen. Dette vil øke kostnadene, spesielt hvis daglig synkronisering skal pågå over lang tid.
#2. AWS DMS Logg Miner
Dette er en innebygd AWS-løsning på samme problem. DMS påvirker ikke kilden for Oracle DB. I stedet kopieres Oracle redo-loggene til DMS-klyngen for behandling. Dette sparer Oracle-ressurser, men er en tregere løsning, da det krever flere operasjoner. Den tilpassede leseren for Oracle redo-logger er trolig tregere enn den opprinnelige leseren fra Oracle.
Avhengig av størrelsen på kildedatabasen og antall daglige endringer, kan du i beste fall oppnå sanntids inkrementell synkronisering av dataene fra den lokale Oracle-databasen til AWS-skydatabasen.
I andre tilfeller vil det ikke være sanntid, men du kan prøve å redusere forsinkelsen mellom kilde og mål ved å optimalisere kilde- og målklyngenes ytelse, parallellitet, DMS-oppgaver og fordeling mellom CDC-instanser.
Det er også viktig å vite hvilke endringer i kildetabellen som støttes av CDC (f.eks. tillegg av en kolonne), da ikke alle endringer støttes. I noen tilfeller må måltabellen endres manuelt, og CDC-oppgaven må startes på nytt (med tap av eksisterende data i måldatabasen).
Når ting går galt, uansett hva

Jeg har lært på den harde måten at det er et spesifikt scenario med DMS der daglig replikering er vanskelig å oppnå.
DMS behandler redo-loggene med en definert hastighet. Det spiller ingen rolle om flere DMS-instanser utfører oppgavene, da hver DMS-instans leser redo-loggene med en definert hastighet, og hver instans må lese alle loggene. Dette gjelder både Oracle redo-logger og AWS log miner.
Hvis kildedatabasen har mange endringer i løpet av dagen, og Oracle redo-loggene blir veldig store (500 GB+), vil ikke CDC fungere. Replikeringen vil ikke bli ferdig før dagen er over. Dette vil føre til at ubehandlede data fortsetter til neste dag, hvor et nytt sett med endringer venter. Mengden ubehandlede data vil bare øke dag for dag.
I dette tilfellet var ikke CDC et alternativ. Den eneste måten å sikre at alle endringer ble replikert samme dag var å:
- Skille store tabeller som ikke brukes så ofte, og replikere dem bare én gang i uken.
- Dele replikering av store tabeller mellom flere DMS-oppgaver. En tabell ble migrert av 10 eller flere DMS-oppgaver parallelt, med tilpasset kode for å sikre distinkt datadeling.
- Legge til flere (opptil 4) DMS-instanser og fordele DMS-oppgavene jevnt mellom dem. Dette betyr fordeling ikke bare etter antall tabeller, men også etter størrelse.
Vi brukte full load-modusen til DMS for å replikere daglige data, da det var den eneste måten å fullføre datareplikeringen samme dag.
Det er ikke en perfekt løsning, men den fungerer fortsatt, selv etter mange år. Kanskje ikke så verst likevel. 😃