Forstå ETL: En Grunnleggende Oversikt
ETL, forkortelse for Extract, Transform, og Load, refererer til en prosess der data hentes fra forskjellige kilder, bearbeides og deretter lagres i et mål system, som en database, et datavarehus eller til og med en datasjø. ETL-verktøy er avgjørende for å flytte og strukturere data for analyse og rapportering.
Tidligere var kunnskapen om ETL begrenset til en liten gruppe fagfolk, og prosessene ble ofte håndtert av skreddersydde batchjobber på lokale maskiner. Den gang virket ETL som en fjern og komplisert teknologi. Mange prosjekter utførte en form for ETL, selv om de kanskje ikke var klar over det eller brukte begrepet.
I dag har dette bildet endret seg drastisk. Overgangen til skyen har gjort ETL-verktøy til en sentral del av arkitekturen for de fleste moderne prosjekter. Skybasert datalagring og -behandling krever effektive metoder for å overføre og omforme data fra lokale systemer til skybaserte plattformer, og det er her ETL-verktøy kommer inn.
Overordnet sett handler migrering til skyen om å flytte data fra lokale kilder og tilpasse dem for skybaserte databaser, og dette er nøyaktig hva ETL-verktøy er designet for.
ETLs Historiske Utvikling og Dens Relevans i Dagens Miljø
Kilde: aws.amazon.com
De grunnleggende funksjonene til ETL har forblitt konsistente over tid. ETL-verktøy henter data fra en rekke kilder, som kan være databaser, filer, webtjenester eller skybaserte applikasjoner. I tidligere tider innebar dette ofte å håndtere filer i Unix-filsystemer med preprosessering, prosessering og etterbehandling.
Man kan gjenkjenne et standardisert mønster med mappenavn som:
- Inndata
- Produksjon
- Feil
- Arkiv
Disse mappene hadde ofte en hierarkisk struktur basert på datoer. Dette var en vanlig metode for å forberede innkommende data for lagring i en database.
I dag er bruken av Unix-filsystemer redusert, og data hentes ofte gjennom API-er i stedet for filer. Data kan hentes fra cache, filer eller andre formater, men de må være strukturert, ofte i JSON, XML eller CSV-format. Valget om å lagre historikken til inndatafiler er ikke lenger et standardtrinn og er opp til prosjektets spesifikke behov.
Transformasjon
ETL-verktøy transformerer dataene til et format som er egnet for analyse, med datarensing, validering, berikelse og aggregering som viktige elementer. I fortiden var datatransformasjon ofte en kompleks prosess med tilpasset logikk i Pro-C eller PL/SQL, der data ble hentet, omformet og lagret i databasen. Transformasjonsprosessen var ofte en standardisert prosess der innkommende filer ble organisert i undermapper basert på behandlingsfasen.
Selv om dette var en vanlig praksis, var det en svakhet: direkte transformering av data uten permanent lagring førte til tap av rådataenes uforanderlighet. Prosjekter kastet bort verdifull informasjon uten muligheten til å gjenopprette den.
Nå til dags, er praksisen å minimere transformasjon av rådata ved første lagring i systemet. Rådata bør lagres i sin opprinnelige form. Det kan senere være behov for transformasjon av data og modellendring, men selve rådataene bør bevares. Dette er en betydelig endring fra tidligere tider.
Lasting
ETL-verktøy laster de transformerte dataene inn i måldatabasen eller datavarehuset, og dette innebærer å opprette tabeller, definere relasjoner og fylle inn de relevante feltene. Selve lastingstrinnet har i stor grad forblitt det samme, men måldatabasene har endret seg. Mens Oracle tidligere var det vanligste alternativet, er det nå skybaserte løsninger som tilbys av AWS som ofte brukes.
ETL i Dagens Skybaserte Miljø
Hvis du planlegger å flytte data fra lokale systemer til en skyplattform som AWS, er et ETL-verktøy essensielt. Denne delen av skyarkitekturen er ofte ansett som en av de mest kritiske. Hvis ETL-prosessen ikke utføres korrekt, kan det påvirke alle påfølgende trinn i prosjektet. Det finnes mange ETL-verktøy på markedet, men jeg vil fokusere på de tre jeg har mest erfaring med:
- Data Migration Service (DMS) – en integrert tjeneste fra AWS.
- Informatica ETL – en etablert aktør innen kommersiell ETL, som har tilpasset seg fra lokal til skybasert drift.
- Matillion for AWS – en nyere aktør med fokus på skybaserte miljøer.
AWS DMS som ETL-Verktøy
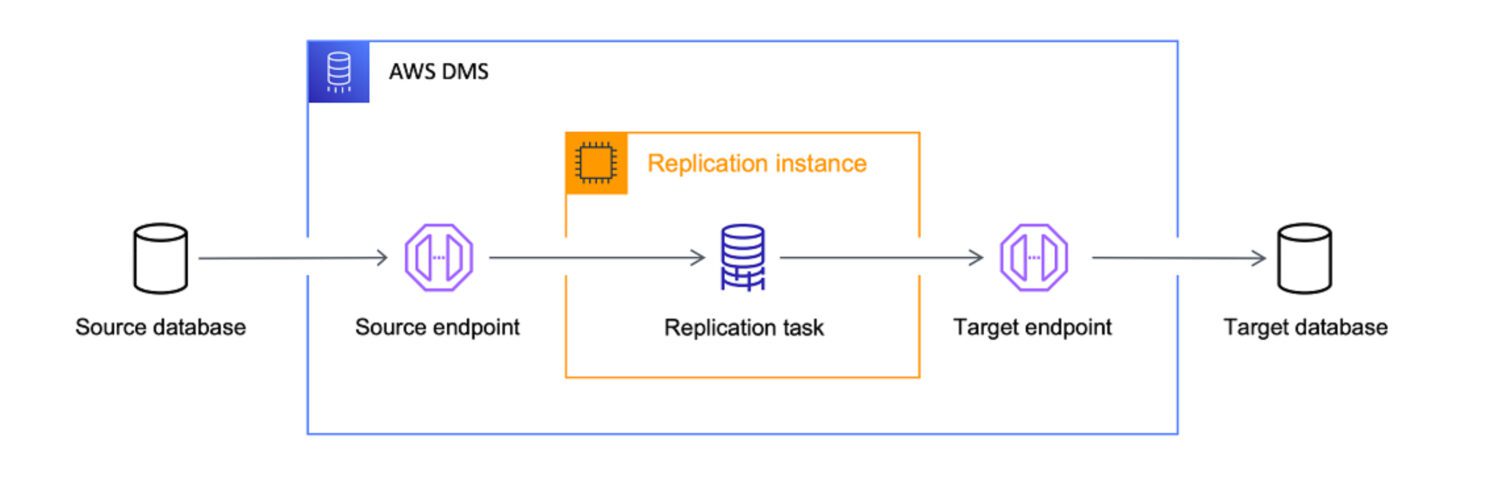
Kilde: aws.amazon.com
AWS Data Migration Services (DMS) er en fullstendig administrert tjeneste for å flytte data mellom ulike kilder og AWS. DMS støtter forskjellige migrasjonsscenarier:
- Homogene migrasjoner (for eksempel Oracle til Amazon RDS for Oracle).
- Heterogene migrasjoner (for eksempel Oracle til Amazon Aurora).
DMS kan flytte data fra forskjellige kilder, som databaser, datavarehus og SaaS-applikasjoner, til ulike mål, inkludert Amazon S3, Amazon Redshift og Amazon RDS.
AWS anser DMS som det beste verktøyet for å flytte data fra enhver databasekilde til skybaserte systemer. Selv om hovedmålet er datakopiering, kan DMS også utføre datatransformasjon. Du kan definere DMS-oppgaver i JSON-format for å automatisere datatransformasjoner under kopieringsprosessen:
- Slå sammen tabeller eller kolonner til en enkelt verdi.
- Dele opp data i flere felt.
- Erstatte data med andre verdier.
- Fjerne uønskede data eller opprette nye.
Dette betyr at DMS kan brukes som et ETL-verktøy, men kanskje ikke så avansert som andre alternativer. Men hvis du definerer målet tydelig, vil DMS gjøre jobben.
Egnethetsfaktor
Selv om DMS har noen ETL-funksjoner, er hovedfokuset datamigrasjon. Det er enkelte scenarier der DMS kan være bedre egnet enn andre ETL-verktøy:
- DMS er ideell for homogene migreringer der kilde- og måldatabasen er av samme type, som Oracle til Oracle.
- DMS tilbyr grunnleggende datatransformasjon, men er ikke like avansert som andre dedikerte verktøy.
- DMS har begrensede funksjoner for datakvalitet og datastyring.
- DMS kan være en mer kostnadseffektiv løsning for organisasjoner med begrenset budsjett.
Matillion ETL
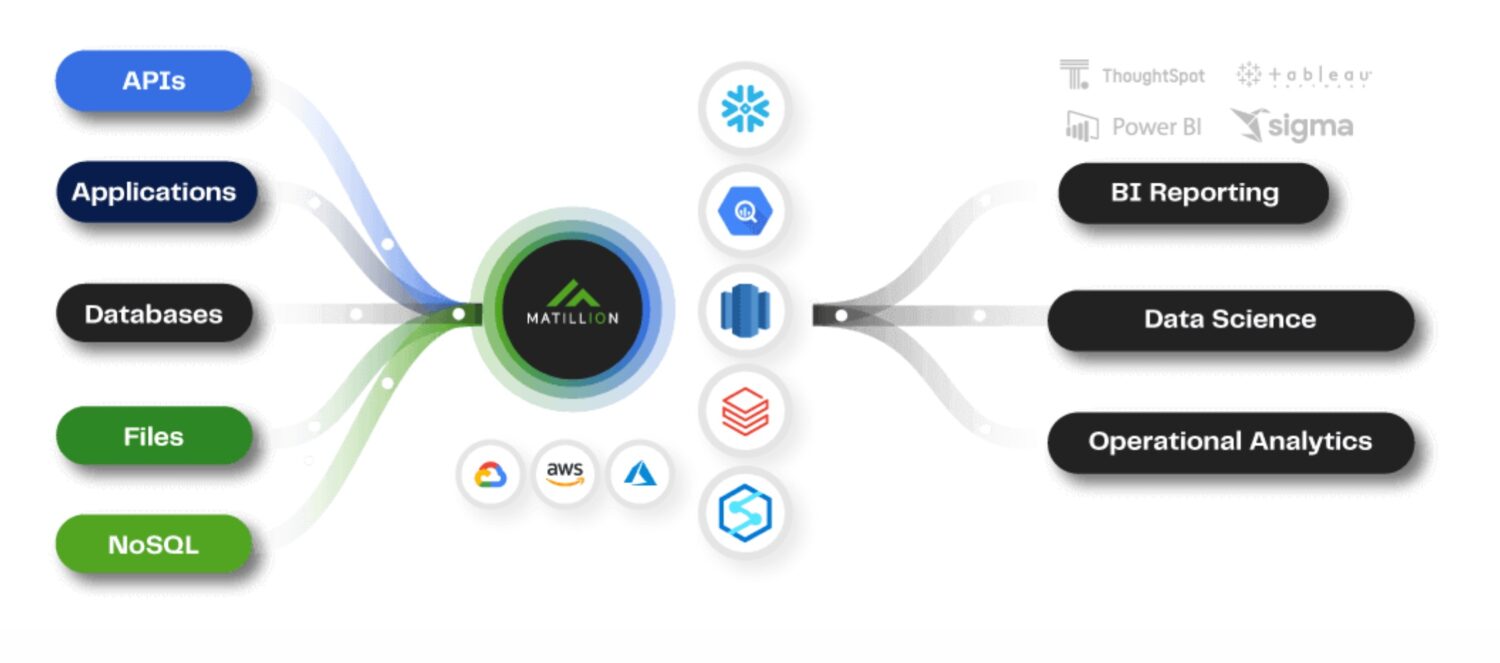
Kilde: matillion.com
Matillion er en skybasert løsning for å integrere data fra ulike kilder, som databaser, SaaS-applikasjoner og filsystemer. Den tilbyr et visuelt grensesnitt for å bygge ETL-rørledninger og integreres med AWS-tjenester som Amazon S3, Amazon Redshift og Amazon RDS.
Matillion er brukervennlig og kan være et godt valg for organisasjoner som er nye til ETL-verktøy eller har mindre komplekse integrasjonsbehov. Likevel må Matillion spesialkonfigureres for å fungere optimalt.
Matillion er ofte beskrevet som et ELT-verktøy, som betyr at lastingen ofte skjer før transformasjonen.
Egnethetsfaktor
Matillion er mer effektiv når datatransformasjon skjer etter at dataene er lagret i databasen. Effektiviteten avhenger i stor grad av den tilpassede koden som kreves. Det er ofte mer effektivt å behandle transformasjoner direkte i måldatabasesystemet og bruke Matillion hovedsakelig for lasting, noe som minimerer risikoen for feil.
Selv om Matillion har mange funksjoner for dataintegrasjon, har det begrensninger når det kommer til datakvalitet og datastyring.
Matillion kan skalere etter behov, men kan ha begrensninger i håndteringen av store datamengder. Informatica er mer avansert og tilbyr bedre funksjonalitet for dette, men for mange organisasjoner vil Matillion være tilstrekkelig.
Informatica ETL
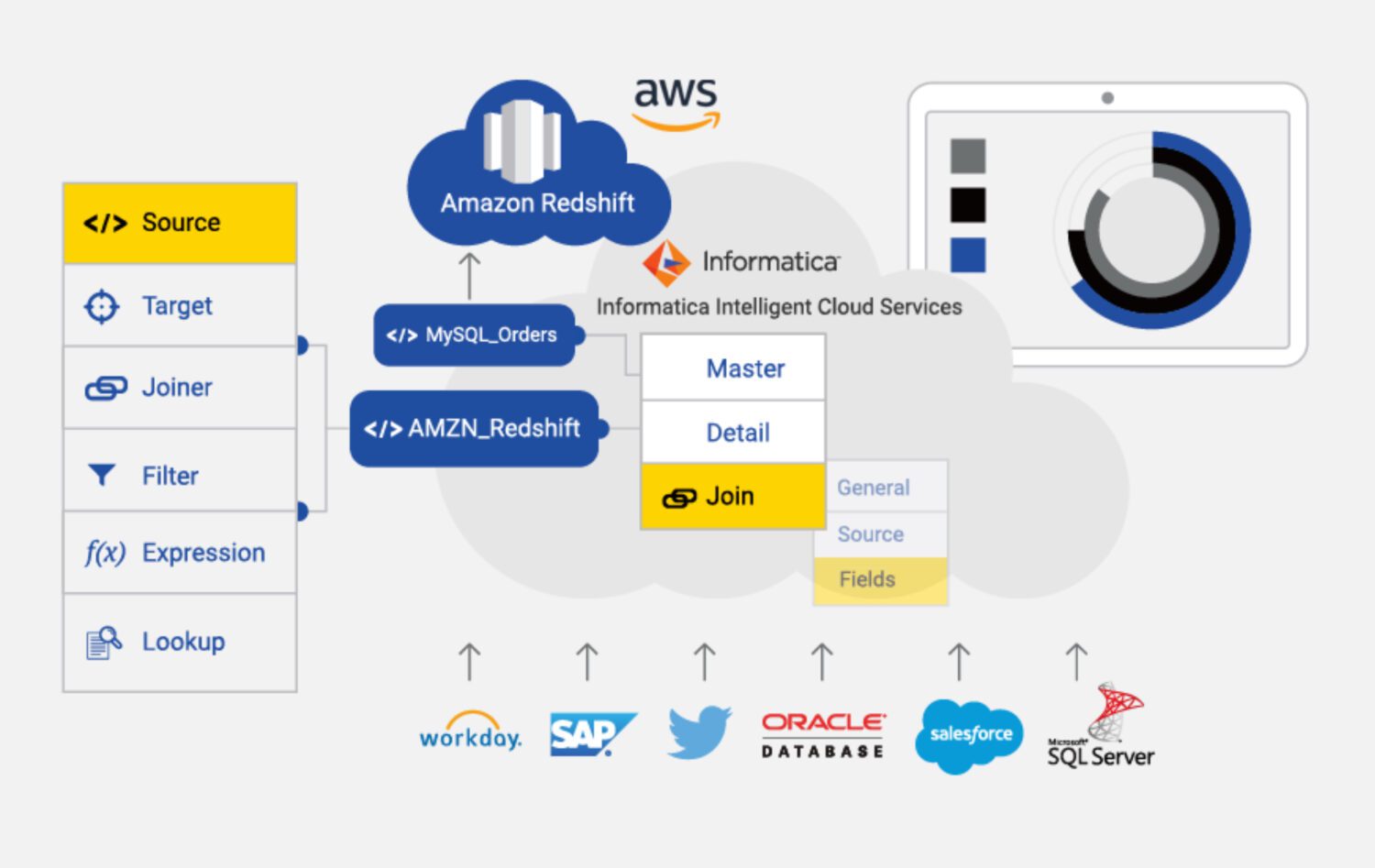
Kilde: informatica.com
Informatica for AWS er et skybasert ETL-verktøy designet for å hjelpe med dataintegrasjon og styring i AWS. Det er en fullt administrert tjeneste med en rekke funksjoner, inkludert dataprofilering, datakvalitet og datastyring.
Noen av hovedkarakteristikkene til Informatica for AWS:
- Informatica er designet for å skalere basert på de faktiske behovene, og kan håndtere store datamengder.
- Informatica har robust sikkerhet, inkludert kryptering, tilgangskontroller og revisjonsspor.
- Informatica tilbyr et visuelt grensesnitt for å bygge ETL-pipelines.
- Informatica integreres med AWS-tjenester som Amazon S3, Amazon Redshift og Amazon RDS.
Egnethetsfaktor
Informatica er det mest funksjonsrike ETL-verktøyet på denne listen, men det kan være dyrere og mer komplisert å bruke enn andre alternativer.
Informatica kan være kostbart, spesielt for små og mellomstore organisasjoner. Prismodellen er basert på bruk, noe som betyr at kostnadene kan øke med økt bruk.
Det kan også være komplekst å konfigurere, spesielt for nybegynnere. Dette kan kreve betydelig investering av tid og ressurser.
Det er også en «kompleks læringskurve», som kan være en ulempe for de som trenger rask integrasjon og har begrensede ressurser.
Informatica er kanskje ikke like effektiv for å integrere data fra ikke-AWS-kilder. I disse tilfellene kan DMS eller Matillion være bedre alternativer.
Til slutt er Informatica et lukket system med begrenset tilpasningsmulighet. Dette kan redusere fleksibiliteten i løsningen.
Konklusjon
Det finnes ingen universal løsning, heller ikke når det gjelder ETL-verktøy i AWS. Valget av verktøy avhenger av spesifikke behov og krav.
Du kan velge Informatica hvis:
- Prosjektet er stort, og du er sikker på at den fremtidige løsningen er kompatibel med Informatica.
- Du har tilgang til et team av dyktige Informatica-utviklere og -konfiguratorer.
- Du er villig til å betale for support og vedlikehold.
Hvis disse kravene ikke er oppfylt, kan Matillion være et bedre valg hvis:
- Prosjektet ikke er for komplekst.
- Du trenger fleksibilitet og tilpasning.
- Du er villig til å utvikle de fleste funksjonene fra bunnen av.
For enklere prosjekter kan DMS være det beste valget, da det er en innfødt AWS-tjeneste.
Etter ETL-prosessen kan det være nyttig å se på datatransformasjon for å bedre administrere dataene.