Den moderne verden er i stor grad datadrevet. For å oppnå et konkurransefortrinn er det avgjørende for bedrifter å ha tilgang til kraftig sanntidsinnsikt basert på faktiske data. Strømming av data muliggjør kontinuerlig innhenting og bearbeiding av informasjon fra en rekke ulike kilder, noe som understreker viktigheten av effektive plattformer for strømmende data.
Plattformer for datastrømming er konstruert som skalerbare, distribuerte og svært effektive systemer, som sikrer pålitelig behandling av dataflyten. Disse plattformene legger til rette for dataaggregering og analyse, og tilbyr ofte et integrert dashbord for visualisering av data.
Det finnes et bredt spekter av alternativer å velge mellom, fra fullt administrerte systemer som Confluent Cloud og Amazon Kinesis, til åpen kildekode-løsninger som Arroyo og Fluvio.
Typiske bruksområder for datastrømming
Datastrømmingsplattformer er relevante for en rekke bruksområder. La oss se nærmere på noen av dem:
- Oppdagelse av svindel ved kontinuerlig analyse av transaksjoner, brukeratferd og mønstre.
- Innsamling av data fra aksjemarkedet av flere systemer som utfører raske handler med høyt volum basert på markedsanalyse.
- Tilpasset innsikt via sanntids markedsdata som hjelper e-handelsplattformer med å nå riktig målgruppe for sine produkter.
- Milliarder av sensorer i forskjellige systemer leverer data fra den virkelige verden, noe som bidrar til prediktiv informasjon, som for eksempel værmeldinger.
Nedenfor er en oversikt over de ledende dataplattformene for dine behov innen sanntidsanalyse og databehandling.
Confluent Cloud

Confluent Cloud er en komplett skybasert Apache Kafka-tjeneste, som leverer motstandsdyktighet, skalerbarhet og høy ytelse. Den bruker den spesialutviklede Kora-motoren, som gir ti ganger bedre ytelse enn å drive en egen Kafka-klynge. Tjenesten tilbyr følgende funksjoner:
- Serverløse klynger gir deg skalerbarhet og fleksibilitet, slik at du umiddelbart kan møte kravene til datastrømming med automatisk opp- og nedskalering.
- Datalagringsbehovene dine dekkes med ubegrenset datalagring og dataintegritet. Confluent Cloud kan dermed være din primære datakilde uten bekymringer for datatap.
- Confluent Cloud tilbyr en oppetids-SLA på 99,99%, en av de beste i bransjen. Sammen med replikering på tvers av flere soner er du beskyttet mot datakorrupsjon og tap.
Stream Designer gir deg et dra-og-slipp-grensesnitt for å visuelt konstruere din prosessering. I tillegg kan du enkelt koble deg til alle apper eller dataleverandører med de forhåndsbygde Kafka-kontaktene.
Confluent Cloud tilbyr Stream Governance, bransjens eneste fullt administrerte datastyringspakke. Du kan beskytte data og kontrollere tilgangen med skybasert sikkerhet og overholdelse av bedriftsstandarder.
Confluent Cloud tilbyr ulike prisalternativer, samt en rekke ressurser som gir en rask start.
Aiven

Aiven hjelper deg med dine behov for datastrømming med en fullt administrert Apache Kafka-skytjeneste. Aiven støtter alle de store skyleverandørene, inkludert AWS, Google Cloud, Microsoft Azure, Digital Ocean og UpCloud.
Du kan sette opp din egen Kafka-tjeneste på under 10 minutter, enten via webkonsollen eller programmatisk via API og CLI. Du har også muligheten til å kjøre tjenesten i containere.
Aiven tilbyr en fullt administrert skytjeneste, slik at du slipper å bekymre deg for Kafka-administrasjon. Du kan raskt sette opp datapipelines, sammen med et dashboard for overvåkning. Her er noen av fordelene:
- Motta automatiske oppdateringer for klyngen din, og administrer versjonsoppgraderinger og vedlikehold med få klikk.
- Aiven tilbyr 99,99% oppetid og minimal nedetid.
- Du kan øke lagringsplassen, legge til flere Kafka-noder, eller distribuere til forskjellige regioner ved behov.
Aivens månedlige priser starter fra $200 og varierer med plassering og valg av skyleverandør.
Arroyo
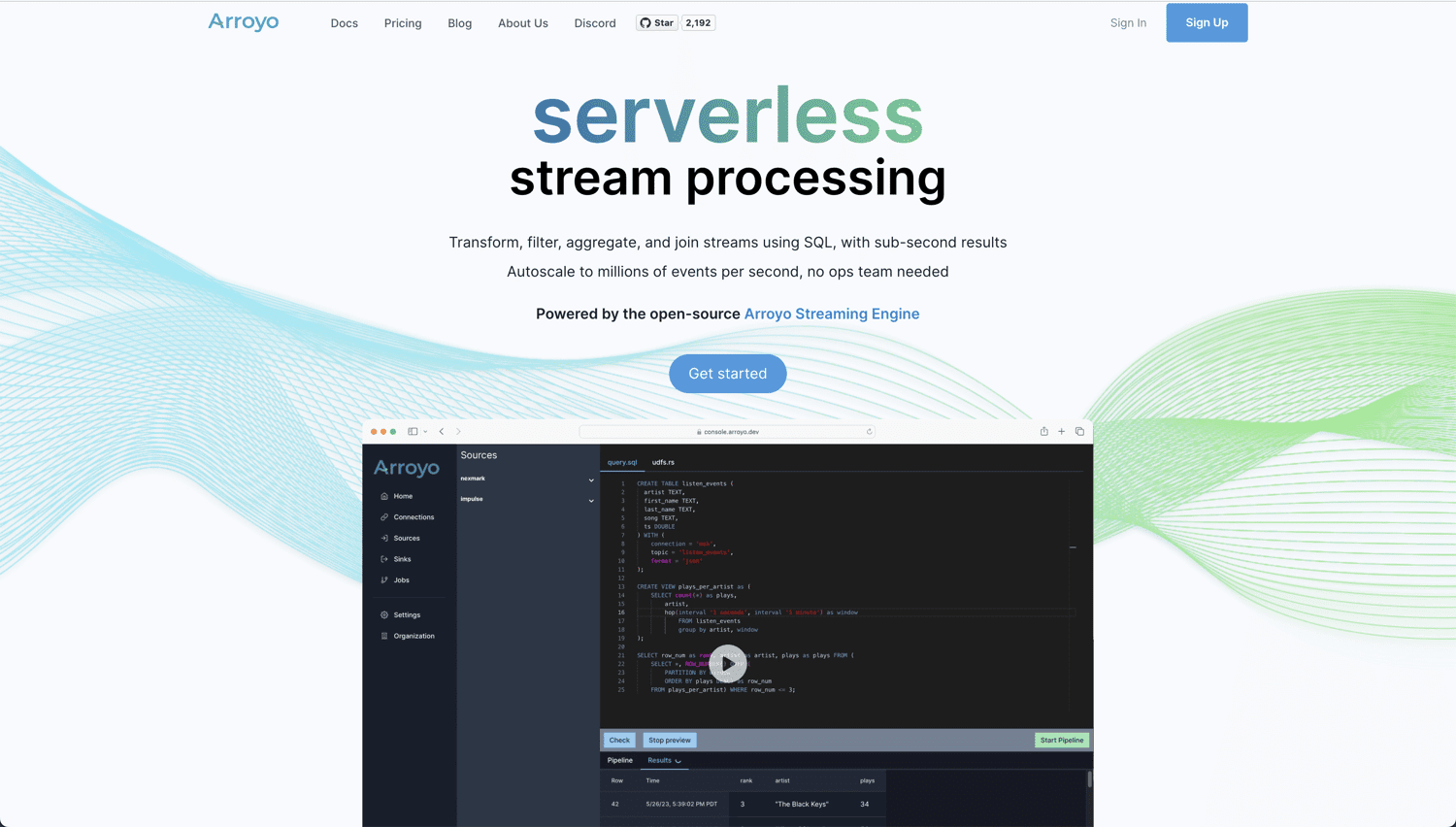
Hvis du leter etter en ekte skybasert og åpen kildekode-løsning for sanntidsanalyse og databehandling, er Arroyo et utmerket verktøy. Det er basert på Arroyo Streaming Engine, en distribuert løsning for strømbehandling, som utmerker seg innen sanntidsoppslag av data med resultater på under et sekund.
Arroyo er designet for å gjøre sanntidsbehandling like enkelt som batchbehandling. Det er svært brukervennlig, og du trenger ikke å være ekspert for å bygge dine egne datapipelines. Dette får du med Arroyo:
- Innebygd støtte for ulike tilkoblinger, inkludert Kafka, Pulsar, Redpanda, WebSockets og Server Sent Events.
- Etter innhenting og bearbeiding kan utgående resultater skrives til forskjellige systemer, som Kafka, Amazon S3 og Postgres.
- En moderne, effektiv og høyytelses kompilator som optimaliserer SQL-spørringene dine for maksimal effektivitet.
- Datastrømmen for dine dataplattformer kan skaleres horisontalt for å støtte millioner av hendelser per sekund.
Du kan velge å kjøre din egen selvhostede forekomst av Arroyo, som er gratis, eller bruke Arroyo Cloud, fra $200 per måned. Arroyo er imidlertid for tiden i en alpha-fase, og noen funksjoner kan være utilgjengelige.
Amazon Kinesis

Amazon Kinesis Data Streams lar deg samle og behandle store datastrømmer for rask og kontinuerlig innhenting. Tjenesten er svært skalerbar, pålitelig og kostnadseffektiv. Her er noen av de beste funksjonene:
- Amazon Kinesis kjører i AWS-skyen i en serverløs modus. Kinesis Data Streams kan enkelt startes fra AWS Management Console.
- Du kan kjøre Kinesis i opptil 3 tilgjengelighetssoner (AZ), og tjenesten tilbyr opptil 365 dagers datalagring.
- Kinesis Data Streams lar deg koble til opptil 20 forbrukere. Hver forbruker har sin egen dedikerte lesekapasitet og kan publisere data innen 70 millisekunder etter inntak.
- Sikkerhetskravene dine ivaretas ved å kryptere data med server-side kryptering.
- Som en del av AWS-økosystemet integreres Kinesis sømløst med andre AWS-tjenester som Cloudwatch, DynamoDB og AWS Lambda.
Med Amazon Kinesis betaler du bare for det du bruker. Med tanke på 1000 poster/sekund på 3 KB hver, vil den daglige kostnaden for en on-demand-modus i utgangspunktet være rundt $30,61. Du kan bruke AWS-kalkulatoren for å beregne din bruksbaserte kostnad.
Databricks

Hvis du er ute etter én samlet dataplattform for både batch- og strømbehandling, er Databricks Lakehouse-plattformen et godt valg. Den tilbyr sanntidsanalyse, maskinlæring og applikasjoner på én plattform.
Databricks Lakehouse-plattformen har sin egen datavisning kalt Delta Live Tables (DLT) med følgende fordeler:
- DLT forenkler defineringen av ende-til-ende datapipelines.
- Automatisert testing av datakvalitet, samtidig som du kan overvåke datakvalitetstrender over tid.
- Forbedret autoskalering som håndterer uforutsigbar arbeidsbelastning.
Plattformen tilbyr den optimale plattformen for å kjøre Apache Spark-arbeidsmengder, med Spark Structured Streaming som kjerneteknologi. Delta Lake, er den eneste åpen kildekode-baserte lagringsplattformen som støtter både strømming og batchdata.
Databricks Lakehouse-plattformen tilbyr en 14 dagers gratis prøveperiode, etterfulgt av et automatisk abonnement på den valgte planen.
Qlik Data Streaming (CDC)

Change Data Capture (CDC) er en teknikk der alle endringer i data varsles til andre systemer. Qlik Data Streaming (CDC) er en enkel og universell løsning som lar deg flytte data fra kilde til destinasjon i sanntid. Alt administreres via et enkelt grafisk grensesnitt.
Qlik Data Streaming (CDC) tilbyr en strømlinjeformet og automatisk konfigurasjon, som gjør det enkelt å sette opp, kontrollere og overvåke datapipelines i sanntid.
Plattformen støtter et bredt spekter av kilder, mål og plattformer. Dette gir muligheten til å ikke bare hente inn et mangfold av data, men også synkronisere lokale, sky- og hybriddatamiljøer.
Qlik Enterprise Manager er ditt sentrale kontrollsenter, som gir deg mulighet til å skalere lett og overvåke dataflyt via varslinger.
Det er fleksible distribusjonsalternativer for hvordan du ønsker å kjøre CDC-pipelinen. Du kan velge mellom følgende:
Du kan starte med en gratis prøveperiode uten å laste ned eller installere noe.
Fluvio

Er du ute etter en åpen kildekode, skybasert strømmeløsning med lav ventetid og høy ytelse? Fluvio er da et godt alternativ. Fluvio lar deg utføre beregninger inne i systemet ved hjelp av SmartModules, noe som utvider funksjonaliteten.
Fluvio tilbyr distribuert strømbehandling med innebygde kontroller for å forhindre datatap og nedetid. I tillegg finnes det API-støtte for populære programmeringsspråk som Rust, Node.js, Python, Java og Go. La oss se nærmere på hva plattformen har å tilby:
- Muligheten til å kombinere beregning med strømming i en felles klynge minimerer forsinkelser.
- Fluvio laster dynamisk inn tilpassede moduler som utvider beregningsmulighetene.
- Høy skalerbarhet som dekker alt fra små IoT-enheter til systemer med flere kjerner.
- Automatisk gjenoppretting med deklarativ administrasjon, avstemming og replikering.
- En kraftig CLI, designet med utviklermiljøet i tankene.
Fluvio kan installeres på alle plattformer, enten det er en bærbar datamaskin, et datasenter eller i den offentlige skyen.
Siden Fluvio er åpen kildekode, er det ingen kostnad for å bruke den.
Cloudera Stream Processing (CSP)

Cloudera Stream Processing (CSP) er drevet av Apache Flink og Apache Kafka, og gir deg analytiske muligheter til å få innsikt i strømmedata. Plattformen har innebygd støtte for standardteknologier som SQL og REST. I tillegg får du en komplett løsning for strømstyring kombinert med tilstandsbehandling, som er designet for bedrifter.
Cloudera Stream Processing leser og analyserer store mengder sanntidsdata for å generere resultater med minimal forsinkelse. Du får støtte for fler-sky og hybrid sky, i tillegg til de nødvendige verktøyene for å bygge avansert dataanalyse. Her er noen verktøy og funksjoner som tilbys:
- Støtte for millioner av meldinger per sekund gir skalerbar strømming.
- Streams Messaging Manager gir et ende-til-ende-perspektiv på hvordan dataene dine beveger seg gjennom datapipelinene.
- Streams Replication Manager tilbyr replikering, tilgjengelighet og katastrofegjenoppretting.
- Schema Registry reduserer skjemafeil og avbrudd, ved å la deg administrere alle skjemaer i et felles depot.
- Cloudera SDX tilbyr enhetlig kontroll og styring på tvers av alle komponenter, med automatisk håndhevet sentralisert sikkerhet.
Med Cloudera Stream Processing kan du starte din strømbehandlingspipeline på den skyplattformen du velger – enten det er AWS, Azure eller Google Cloud Platform – på under 10 minutter.
Striim Cloud
Har din dataplattform og sanntidsanalyse behov for et bredt spekter av dataprodusenter og -forbrukere? Med innebygd støtte for over 100 tilkoblinger, kan Striim Cloud være det rette valget. Integrer enkelt med eksisterende datalagre og strøm data i sanntid, ved hjelp av en fullt administrert SaaS-plattform designet for skyen.
Striim Cloud tilbyr et enkelt dra-og-slipp-grensesnitt, som ikke bare hjelper med å bygge pipelines, men også gir innsikt i dataene dine. Plattformen støtter de mest populære analyseverktøyene, inkludert Google BigQuery, Snowflake, Azure Synapse og Databricks. I tillegg får du følgende:
- Striims skjemaevolusjonsegenskaper håndterer endringer i datastrukturen. Du kan konfigurere den for automatisk oppløsning eller manuelt inngrep.
- Bygget på en distribuert SQL-strømmeplattform som lar deg kjøre kontinuerlige spørringer.
- Striim tilbyr høy skalerbarhet og kapasitet. Du kan skalere pipelinen uten ekstra planlegging eller kostnad.
- «ReadOnlyWriteMany»-metoden gjør det mulig å legge til og fjerne nye mål uten innvirkning på datalagrene.
Du betaler kun for det du bruker. Striim-utviklermiljøet er gratis og lar deg prøve plattformen med opptil 10 millioner hendelser/måned. For en skyløsning i bedriftsskala, starter prisen på $2500/måned.
VK Streaming Data Platform
Vertical Knowledge (VK) hjelper enkeltpersoner og bedrifter med å ta gode beslutninger i stor skala. VK Streaming Data Platform gir deg mulighet til å behandle enorme mengder data gjennom et nettbasert datastrømmemiljø.
Få handlingsrettet innsikt med automatisert dataoppdagelse. Her er noen av de viktigste fordelene med VKs Streaming Data Platform:
- Robust cybersikkerhet takket være VKs stabile infrastruktur, som beskytter mot skadelig innhold. Du kan også laste ned data gjennom et virtuelt miljø.
- Automatiske datastrømmer lar deg enkelt operere på tvers av flere datakilder.
- Rask oppdagelse reduserer manuelle prosesser, som ofte er tidkrevende.
- Generer avanserte datasamlinger ved å kjøre samtidige pipelines fra flere kilder.
- Du kan eksportere datasamlingene dine i rå JSON- eller CSV-format eller bruke API-er for å integrere med tredjepartssystemer.
HSream-plattformen
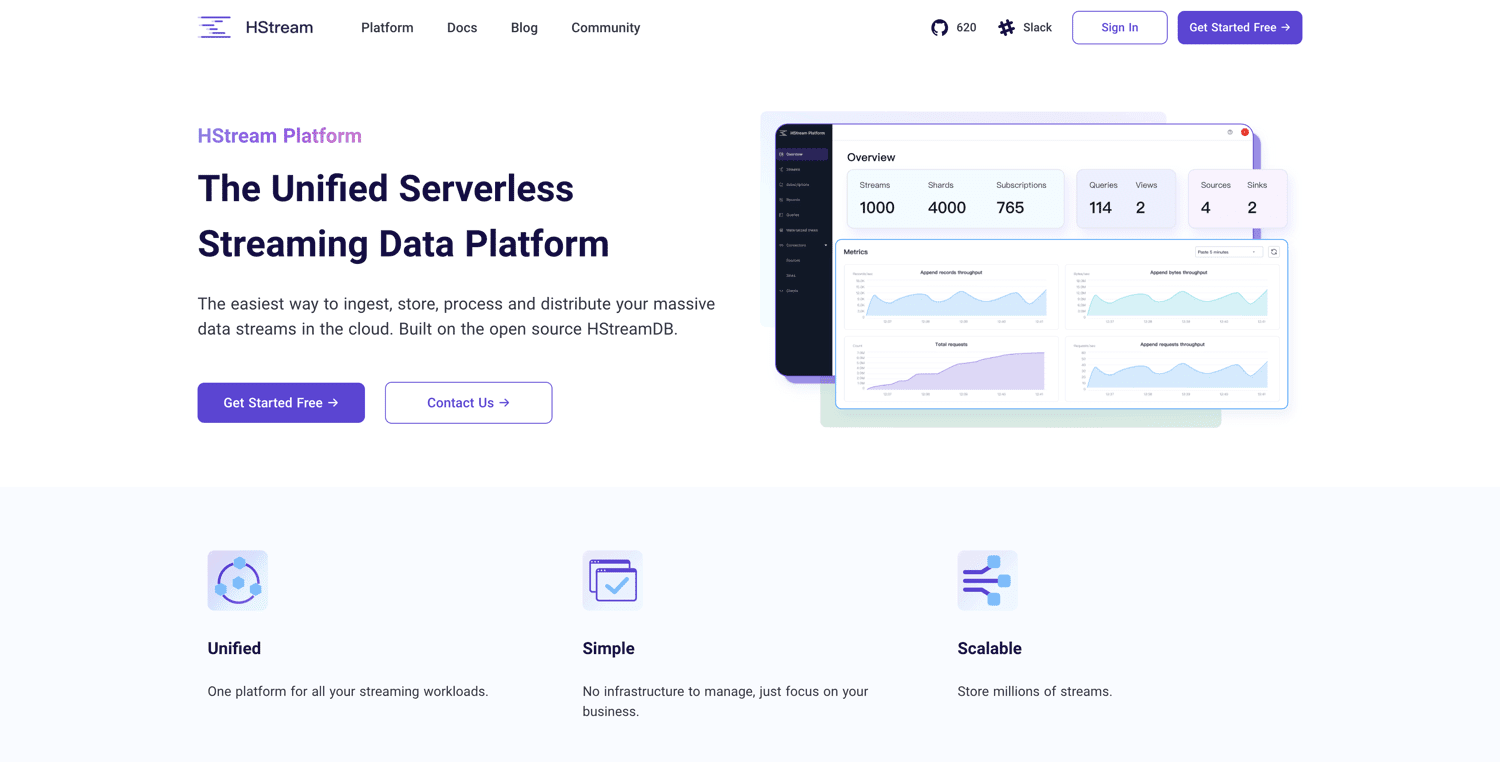
Den HSream-plattformen er bygget på åpen kildekode HStreamDB og tilbyr en serverløs datastrømmingsplattform. Du kan hente inn enorme datamengder og lagre millioner av datastrømmer på en pålitelig måte. HStreamDB er like rask som Kafka. I tillegg kan du spille av historiske data på nytt.
Du kan bruke SQL til å filtrere, transformere, samle og til og med slå sammen flere datavisninger, slik at du får sanntidsinnsikt i dataene dine. HSream-plattformen er designet for å være enkel og slank. Her er de viktigste funksjonene:
- Siden plattformen er serverløs, er den klar til bruk fra start.
- Det er ikke behov for Kafka for å håndtere strømmebehov.
- Du får strømbehandling på stedet ved å bruke standard SQL.
- Forbruk fra og produser til forskjellige systemer, enten det er databaser, datavarehus eller datasjøer, uten behov for flere ETL-verktøy.
- Administrer arbeidsmengden din i én enkelt strømmeplattform.
- Den skybaserte arkitekturen lar deg skalere databehandling og lagringsbehov uavhengig av hverandre.
HSream Platform er for tiden i offentlig beta. Den er gratis å bruke – alt du trenger å gjøre er å melde deg på.
Konklusjon
Valget av en god datastrømmingsplattform avhenger av størrelse, behov for tilkoblinger, oppetid og pålitelighet.
Mens noen plattformer er fullt administrerte tjenester, er andre åpen kildekode og tilbyr ulike tilpasninger. Vurder dine behov og budsjett, og velg det som passer best for deg.
Hvis du lurer på hvordan du best kan utnytte all denne dataen, bør du vurdere å prøve AI-drevne data- og prediksjonsverktøy for bedrifter.