Bearbeiding av store datamengder er en av de mest utfordrende oppgavene for organisasjoner i dag. Denne prosessen blir enda mer kompleks når man arbeider med store mengder sanntidsdata.
I denne artikkelen skal vi utforske hva stordata-behandling innebærer, hvordan det utføres, og vi vil se nærmere på Apache Kafka og Spark – to av de mest anerkjente verktøyene for databehandling!
Hva er databehandling? Hvordan fungerer det?
Databehandling kan defineres som enhver operasjon eller serie av operasjoner som utføres, enten ved hjelp av en automatisert prosess eller manuelt. Dette omfatter innsamling, organisering og strukturering av informasjon på en logisk og hensiktsmessig måte for analyse og tolkning.

Når en bruker søker i en database og mottar resultater, er det databehandlingen som muliggjør dette. Informasjonen som presenteres som søkeresultat er direkte et produkt av databehandling. Derfor er databehandling kjernen i moderne informasjonsteknologi.
Tradisjonell databehandling ble utført ved hjelp av enkel programvare. Men med fremveksten av store datamengder, også kjent som Big Data, har dette endret seg. Big Data refererer til data som kan overstige hundre terabyte eller petabyte i størrelse.
I tillegg oppdateres denne informasjonen kontinuerlig. Eksempler på dette inkluderer data fra kundesentre, sosiale medier og børsdata. Slike data kalles også datastrømmer – en kontinuerlig, uavbrutt flyt av data. En vesentlig egenskap er at dataene ikke har noen definerte grenser, noe som gjør det vanskelig å fastslå når strømmen begynner eller slutter.
Data bearbeides som de ankommer målet. Noen eksperter refererer til dette som sanntids- eller online-behandling. En annen tilnærming er blokk-, batch- eller offline-behandling, der datablokker bearbeides i intervaller på timer eller dager. Batch-behandling utføres ofte om natten for å konsolidere data fra den foregående dagen. Det finnes også tilfeller der rapporter genereres med intervaller på en uke eller til og med en måned, som da vil være noe utdaterte.
De mest populære plattformene for sanntidsbehandling av Big Data er åpen kildekode-løsninger som Kafka og Spark. Disse plattformene tillater bruk av forskjellige, men komplementære verktøy. Det at de er åpen kildekode, bidrar til raskere utvikling og integrasjon med et bredt spekter av verktøy. På denne måten kan datastrømmer fra forskjellige kilder håndteres med variabel hastighet og uten avbrudd.
La oss nå ta en titt på to av de mest kjente verktøyene for databehandling og sammenligne dem:
Apache Kafka
Apache Kafka er et meldingssystem som brukes til å bygge strømningsapplikasjoner med en kontinuerlig dataflyt. Kafka, som opprinnelig ble utviklet av LinkedIn, er loggbasert. En logg er en grunnleggende form for lagring der ny informasjon legges til på slutten av filen.

Kafka er en av de foretrukne løsningene for big data på grunn av sin høye gjennomstrømningskapasitet. Med Apache Kafka er det til og med mulig å transformere batchbehandling til sanntidsbehandling.
Apache Kafka er et publiser-abonner-meldingssystem der en applikasjon publiserer meldinger, og en annen applikasjon som abonnerer på emnet mottar disse meldingene. Tiden mellom publisering og mottak av meldingen kan være bare noen få millisekunder, noe som betyr at Kafka har lav ventetid.
Slik fungerer Kafka
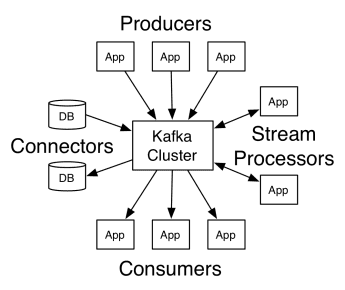
Arkitekturen til Apache Kafka består av produsenter, konsumenter og selve klyngen. En produsent er en applikasjon som publiserer meldinger til klyngen. En konsument er en applikasjon som mottar meldinger fra Kafka. Kafka-klyngen består av en rekke noder som fungerer som en enkelt instans av meldingstjenesten.
 Slik fungerer Kafka
Slik fungerer Kafka
En Kafka-klynge består av flere meglere. En megler er en Kafka-server som mottar meldinger fra produsenter og lagrer dem på disk. Hver megler håndterer en liste over emner, og hvert emne er delt inn i flere partisjoner.
Etter å ha mottatt meldinger, sender megleren dem videre til de registrerte konsumentene for hvert emne.
Apache Kafka-innstillinger administreres av Apache Zookeeper, som lagrer klyngemetadata, inkludert partisjonsplassering, emnelister og tilgjengelige noder. Zookeeper opprettholder synkronisering mellom de forskjellige komponentene i klyngen.
Zookeeper er viktig fordi Kafka er et distribuert system, der skriving og lesing utføres av flere klienter samtidig. Hvis det oppstår en feil, velger Zookeeper en erstatning og gjenoppretter driften.
Bruksområder
Kafka har blitt populært, spesielt som et meldingsverktøy, men allsidigheten strekker seg utover det og kan brukes i en rekke scenarioer, som i eksemplene nedenfor.
Meldinger
Asynkron kommunikasjonsform som kobler fra de kommuniserende partene. I denne modellen sender en part data som en melding til Kafka, og en annen applikasjon bruker dem senere.
Aktivitetssporing
Gjør det mulig å lagre og behandle data som følger en brukers interaksjon med et nettsted, for eksempel sidevisninger, klikk og dataregistrering. Denne typen aktivitet genererer vanligvis store datamengder.
Beregninger
Involverer innsamling av data og statistikk fra flere kilder for å generere en sentralisert rapport.
Loggaggregering
Sentraliserer og lagrer loggfiler fra forskjellige systemer.
Strømbehandling
Behandling av datapipelines i flere trinn, der rådata forbrukes fra emner og aggregeres, berikes eller transformeres til andre emner.
For å støtte disse funksjonene tilbyr plattformen tre hoved-APIer:
- Streams API: Fungerer som en strømprosessor som forbruker data fra et emne, transformerer det og skriver det til et annet.
- Connectors API: Tillater kobling av emner til eksisterende systemer, for eksempel relasjonsdatabaser.
- Produsent- og konsument-APIer: Lar applikasjoner publisere og konsumere data fra Kafka.
Fordeler
Replikkert, partisjonert og ordnet
Meldinger i Kafka replikeres på tvers av partisjoner på klyngenoder i den rekkefølgen de kommer, for å garantere sikkerhet og leveringshastighet.
Datatransformasjon
Med Apache Kafka er det også mulig å transformere batchbehandling til sanntid ved hjelp av batch ETL streams API.
Sekvensiell disktilgang
Apache Kafka lagrer meldinger på disk i stedet for i minnet, da dette skal være raskere. Minnetilgang er generelt sett raskere, spesielt når man vurderer tilgang til data som er lagret på tilfeldige steder i minnet. Kafka benytter seg av sekvensiell tilgang, og i dette tilfellet er disken mer effektiv.
Apache Spark
Apache Spark er et databehandlingsverktøy for store datamengder og et sett med biblioteker for å behandle parallelle data på tvers av klynger. Spark er en videreutvikling av Hadoop og Map-Reduce-programmeringsparadigmet. Det kan være opptil 100 ganger raskere takket være effektiv bruk av minne, som reduserer behovet for å lagre data på disk under behandlingen.
Spark er organisert på tre nivåer:
- Lavnivå-APIer: Dette nivået inneholder den grunnleggende funksjonaliteten for å kjøre jobber og annen funksjonalitet som kreves av de andre komponentene. Andre viktige funksjoner i dette laget er styring av sikkerhet, nettverk, planlegging og logisk tilgang til filsystemer som HDFS, GlusterFS, Amazon S3 og andre.
- Strukturerte APIer: Det strukturerte API-nivået håndterer datamanipulasjon gjennom DataSets eller DataFrames, som kan leses i formater som Hive, Parquet, JSON og andre. Ved hjelp av SparkSQL (et API som lar oss skrive spørringer i SQL) kan vi manipulere dataene som vi ønsker.
- Høyt nivå: På det høyeste nivået finner vi Spark-økosystemet med forskjellige biblioteker, inkludert Spark Streaming, Spark MLlib og Spark GraphX. Disse er ansvarlige for å håndtere strømmeinnmating og relaterte prosesser, som krasjgjenoppretting, utvikling og validering av maskinlæringsmodeller, samt håndtering av grafer og algoritmer.
Slik fungerer Spark
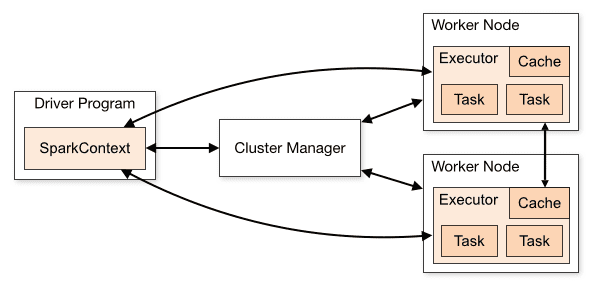
Arkitekturen til en Spark-applikasjon består av tre hoveddeler:
Driverprogram: Er ansvarlig for å orkestrere gjennomføringen av databehandling.
Cluster Manager: Komponenten som er ansvarlig for å administrere de forskjellige maskinene i en klynge. Kun nødvendig hvis Spark kjører i en distribuert setting.
Arbeidernoder: Dette er maskinene som utfører oppgavene til et program. Hvis Spark kjøres lokalt på din maskin, vil den fungere både som et driverprogram og en arbeidernode. Denne måten å kjøre Spark på kalles Standalone.
 Klyngeoversikt
Klyngeoversikt
Spark-kode kan skrives i en rekke forskjellige programmeringsspråk. Spark-konsollen, kalt Spark Shell, er interaktiv og nyttig for læring og utforsking av data.
En såkalt Spark-applikasjon består av en eller flere jobber, som muliggjør støtte for storskala databehandling.
Når det gjelder utførelse, har Spark to modi:
- Klient: Driveren kjører direkte på klienten, uten å gå gjennom Resource Manager.
- Klynge: Driveren kjører på Application Master gjennom Resource Manager. I klyngemodus vil applikasjonen fortsette å kjøre selv om klienten kobles fra.
Det er viktig å bruke Spark på riktig måte, slik at tilknyttede tjenester som Resource Manager kan identifisere behovet for hver utførelse og levere optimal ytelse. Derfor er det utviklerens ansvar å finne den beste måten å kjøre Spark-jobber på, strukturere kallet og konfigurere Spark-utførerne.
Spark-jobber bruker primært minne, så det er vanlig å justere konfigurasjonsverdiene for arbeidsnodenes utførere. Avhengig av arbeidsbelastningen kan det være at en ikke-standard Spark-konfigurasjon gir bedre ytelse. For å finne den optimale konfigurasjonen, kan du utføre sammenligningstester mellom forskjellige tilgjengelige konfigurasjonsalternativer og standard Spark-konfigurasjon.
Bruksområder
Apache Spark hjelper til med å behandle enorme datamengder, enten de er i sanntid eller arkivert, strukturert eller ustrukturert. Her er noen av de mest populære bruksområdene:
Databerikelse
Bedrifter bruker ofte en kombinasjon av historiske kundedata og sanntids data om brukeratferd. Spark kan bidra til å bygge en kontinuerlig ETL-pipeline for å konvertere ustrukturerte hendelsesdata til strukturerte data.
Hendelsesdeteksjon
Spark Streaming muliggjør rask deteksjon og respons på uvanlig eller mistenkelig atferd som kan indikere et potensielt problem eller svindel.
Kompleks sesjonsdataanalyse
Ved hjelp av Spark Streaming kan hendelser relatert til brukerens sesjon, som for eksempel aktivitet etter innlogging i applikasjonen, grupperes og analyseres. Denne informasjonen kan også brukes kontinuerlig til å oppdatere maskinlæringsmodeller.
Fordeler
Iterativ behandling
Hvis oppgaven krever gjentatt databehandling, tillater Sparks resiliens distribuerte datasett (RDD) flere kartoperasjoner i minnet uten å måtte skrive midlertidige resultater til disken.
Grafisk behandling
Sparks beregningsmodell med GraphX API er utmerket for iterative beregninger som er typiske for grafikkbehandling.
Maskinlæring
Spark har MLlib – et innebygd maskinlæringsbibliotek med ferdige algoritmer som også kjører i minnet.
Kafka mot Spark
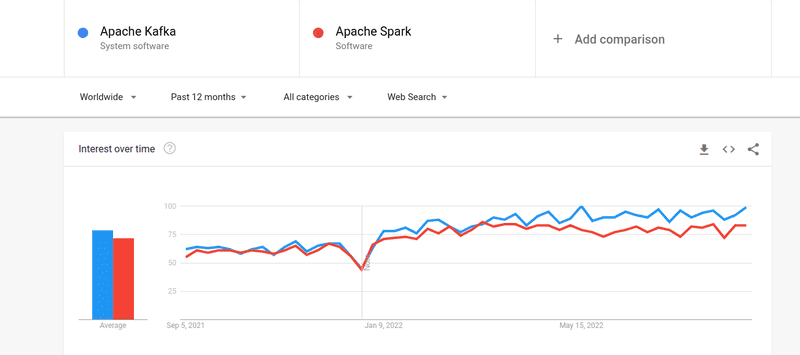
Selv om interessen for både Kafka og Spark er omtrent like stor, finnes det noen viktige forskjeller mellom de to. La oss ta en titt:
#1. Databehandling
Kafka er et sanntids verktøy for datastrømmer og lagring som er ansvarlig for å overføre data mellom applikasjoner, men det er ikke tilstrekkelig for å bygge en komplett løsning. Derfor trengs andre verktøy for oppgaver som Kafka ikke utfører, for eksempel Spark. Spark, derimot, er en plattform for batch-første databehandling, som henter data fra Kafka-emner og transformerer dem til kombinerte skjemaer.
#2. Minnehåndtering
Spark bruker Robust Distributed Dataset (RDD) for minnehåndtering. I stedet for å prøve å behandle store datasett, distribuerer det dem over flere noder i en klynge. Kafka derimot, bruker sekvensiell tilgang, som ligner på HDFS, og lagrer data i et bufferminne.
#3. ETL-transformasjon
Både Spark og Kafka støtter ETL-transformasjonsprosessen, som kopierer poster fra en database til en annen, vanligvis fra en transaksjonsdatabase (OLTP) til en analytisk database (OLAP). Men i motsetning til Spark, som har en innebygd funksjon for ETL-prosessering, er Kafka avhengig av Streams API for å støtte det.
#4. Datapersistens

Sparks bruk av RDD lar deg lagre dataene flere steder for senere bruk, mens du i Kafka må definere datasettobjekter i konfigurasjonen for å lagre data.
#5. Vanskelighetsgrad
Spark er en mer komplett løsning og er enklere å lære på grunn av støtten for forskjellige programmeringsspråk på høyt nivå. Kafka er avhengig av en rekke forskjellige APIer og tredjepartsmoduler, noe som kan gjøre det mer utfordrende å jobbe med.
#6. Gjenoppretting
Både Spark og Kafka tilbyr gjenopprettingsalternativer. Spark bruker RDD, som lar det lagre data kontinuerlig, og hvis det er en klyngefeil, kan det gjenopprettes.

Kafka replikerer kontinuerlig data i klyngen på tvers av meglere, noe som gjør at du kan fortsette operasjonen på en annen megler hvis det oppstår en feil.
Likheter mellom Spark og Kafka
| Apache Spark | Apache Kafka | |
| Åpen kildekode | Ja | Ja |
| Bygging av datastrømningsapplikasjoner | Ja | Ja |
| Støtter tilstandsfølsom behandling | Ja | Ja |
| Støtter SQL | Ja | Ja |
Avsluttende tanker
Kafka og Spark er begge åpen kildekode-verktøy skrevet i Scala og Java, som lar deg bygge sanntids datastrømmeapplikasjoner. De har flere felles trekk, inkludert tilstandsfølsom behandling, støtte for SQL og ETL. Kafka og Spark kan også brukes som komplementære verktøy for å løse kompleksiteten i dataoverføring mellom applikasjoner.