«`html
MapReduce gir en effektiv, raskere og mer kostnadsbevisst metode for å utvikle applikasjoner.
Denne modellen utnytter avanserte prinsipper som parallellprosessering og datalokalisering, noe som gir betydelige fordeler for både programmerere og organisasjoner.
Likevel, med det store utvalget av programmeringsmodeller og rammeverk som finnes, kan det være en utfordring å ta det rette valget.
Spesielt når det gjelder stordata, er det viktig å velge teknologier som effektivt kan håndtere store mengder informasjon.
MapReduce er en fremragende løsning for dette.
I denne artikkelen skal vi utforske MapReduce og hvordan det kan være fordelaktig.
La oss starte!
Hva er MapReduce?
MapReduce er en programmeringsmodell eller et programvare rammeverk som er en del av Apache Hadoop-økosystemet. Den benyttes til å utvikle applikasjoner som kan prosessere store mengder data parallelt på tusenvis av noder (også kjent som klynger eller nettverk) med feiltoleranse og pålitelighet.
Denne databehandlingen foregår i en database eller et filsystem der dataene er lagret. MapReduce kan samhandle med et Hadoop-filsystem (HDFS) for å få tilgang til og administrere store datamengder.
Dette rammeverket ble introdusert av Google i 2004 og er en sentral del av Apache Hadoop. Det fungerer som et behandlingslag i Hadoop, der MapReduce-programmer skrevet i språk som Java, C++, Python og Ruby kjøres.
MapReduce-programmene opererer parallelt i skybaserte miljøer, noe som gjør dem velegnet for storskala dataanalyse.
MapReduce deler en oppgave i mindre, håndterbare deloppgaver ved å bruke funksjonene «map» og «reduce». Hver oppgave kartlegges og reduseres deretter til mindre, ekvivalente oppgaver, noe som gir lavere prosessorkraft og mindre overhead i klyngenettverket.
Tenk deg at du skal lage et måltid for mange gjester. Hvis du skulle tilberede alle rettene alene, ville det bli en krevende og tidkrevende oppgave.
Men forestill deg at du involverer venner eller kollegaer for å hjelpe deg med matlagingen ved å fordele de ulike prosessene. Dette ville tillate dere å tilberede måltidet raskere og mer effektivt, mens gjestene fortsatt venter.
MapReduce opererer på en lignende måte, med distribuerte oppgaver og parallell prosessering, for å fullføre oppgaver raskere og mer effektivt.
Apache Hadoop lar programmerere bruke MapReduce for å utføre avansert maskinlæring og statistiske teknikker på store distribuerte datasett, slik at de kan identifisere mønstre, lage prediksjoner, oppdage korrelasjoner og mer.
Funksjoner i MapReduce
Noen av de viktigste funksjonene i MapReduce inkluderer:
- Brukergrensesnitt: Et brukervennlig grensesnitt gir detaljert informasjon om alle aspekter av rammeverket. Dette forenkler konfigurasjon, bruk og justering av oppgaver.

- Nyttelast: Applikasjoner benytter Mapper- og Reducer-grensesnitt for å aktivere kart- og reduseringsfunksjoner. Mapper konverterer inngangsverdier til mellomliggende nøkkel-verdi-par. Reducer reduserer mellomliggende nøkkel-verdi-par som deler en nøkkel til færre verdier. Denne prosessen omfatter sortering, blanding og redusering.
- Partisjonering: Denne funksjonen styrer fordelingen av mellomliggende data fra kartleggingsprosessen.
- Rapportering: MapReduce har en funksjon for å rapportere fremdrift, oppdatere tellere og angi statusmeldinger.
- Tellere: Globale tellere defineres av en MapReduce-applikasjon.
- OutputCollector: Denne funksjonen samler utdata fra Mapper eller Reducer, i stedet for mellomliggende data.
- RecordWriter: Denne funksjonen skriver utdata eller nøkkel-verdi-par til en utdatafil.
- DistributedCache: Denne funksjonen distribuerer skrivebeskyttede filer som er spesifikke for applikasjonen, effektivt.
- Datakomprimering: Applikasjonen kan komprimere både endelige utdata og mellomliggende data fra kartleggingsprosessen.
- Hopp over dårlige poster: Det er mulig å hoppe over dårlige poster under behandlingen av inndata. Denne funksjonen styres av klassen – SkipBadRecords.
- Feilsøking: Det er mulig å kjøre egendefinerte skript og aktivere feilsøking. Hvis en MapReduce-oppgave mislykkes, kan et feilsøkingsskript kjøres for å identifisere problemene.
MapReduce Arkitektur
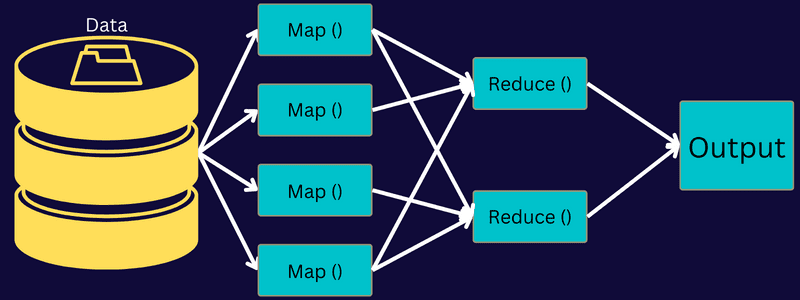
La oss utforske arkitekturen til MapReduce ved å se nærmere på de ulike komponentene:
- Jobb: En jobb i MapReduce er den oppgaven MapReduce-klienten ønsker å utføre. Den består av flere mindre deloppgaver som kombineres for å danne den endelige oppgaven.
- Job History Server: Denne demonprosessen lagrer og vedlikeholder all historisk data om en applikasjon eller oppgave, som logger generert før og etter en jobb.
- Klient: En klient (program eller API) sender en jobb til MapReduce for utførelse eller behandling. En eller flere klienter kan kontinuerlig sende jobber til MapReduce Manager for behandling.
- MapReduce Master: MapReduce Master deler en jobb opp i mindre deler og sikrer at alle oppgaver skrider frem samtidig.
- Jobbdeler: Underjobber eller deljobber oppstår når hovedjobben deles opp. De behandles individuelt og kombineres til slutt for å danne den endelige oppgaven.
- Inndata: Dette er datasettet som sendes til MapReduce for oppgavebehandling.
- Utdata: Dette er det endelige resultatet som oppnås etter at oppgaven er ferdigbehandlet.
I denne arkitekturen sender klienten en jobb til MapReduce Master, som deretter deler den i mindre, like deler. Dette muliggjør raskere behandling, siden mindre oppgaver tar kortere tid å behandle enn større oppgaver.
Det er viktig å unngå å dele oppgavene i for små deler. Dette kan føre til økt overhead og betydelig bortkastet tid på administrasjon av splittene.
De ulike jobbdeler gjøres deretter tilgjengelige for Kart- og Reduser-oppgavene. Kart- og Reduser-oppgavene har programmer som er tilpasset det spesifikke bruksområdet teamet jobber med. Programmereren utvikler logikkbasert kode for å oppfylle kravene.
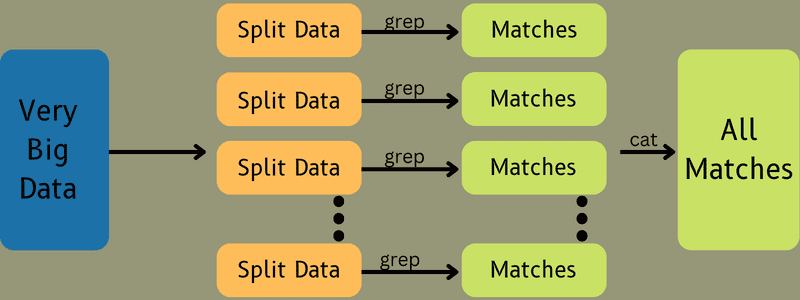
Inndataene sendes til kartoppgaven, som raskt genererer utdata i form av nøkkel-verdi-par. I stedet for å lagre disse dataene i HDFS, brukes en lokal disk for å unngå replikering.
Når oppgaven er fullført, kan utdataene forkastes, da replikering ikke er nødvendig. Utdata fra hver kartoppgave overføres til reduksjonsoppgaven, og kartutdata sendes til maskinen som utfører reduksjonsoppgaven.
Deretter slås utdataene sammen og sendes til den brukerdefinerte reduseringsfunksjonen. Til slutt lagres de reduserte utdataene i HDFS.
Prosessen kan omfatte flere kart- og reduksjonsoppgaver avhengig av sluttmålet. Kart- og reduksjonsalgoritmene er optimalisert for å minimere tids- og romkompleksitet.
Ettersom MapReduce hovedsakelig involverer Map- og Reduce-oppgaver, er det viktig å forstå disse mer detaljert. La oss se nærmere på fasene i MapReduce for å få en god forståelse av disse temaene.
Faser i MapReduce
Kart
I denne fasen blir inndata kartlagt til utdata- eller nøkkel-verdi-par. Nøkkelen kan være en adresse-ID, og verdien kan være den faktiske adressen.
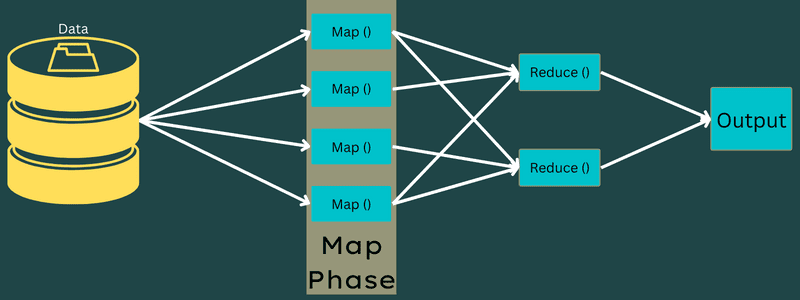
Denne fasen omfatter to deloppgaver: oppdeling og kartlegging. Oppdeling betyr å dele hovedjobben i mindre deler, også kjent som inndataoppdelinger. En inndataoppdeling er en inndatadel som bearbeides av en kartleggingsprosess.
Deretter finner selve kartleggingsoppgaven sted. Dette er den første fasen i et kartreduseringsprogram. Data i hver inndataoppdeling sendes til en kartfunksjon for behandling og utdatagenerering.
Funksjonen Map() kjøres i minnet på inndata-nøkkel-verdi-parene og genererer et mellomliggende nøkkel-verdi-par. Dette nye paret fungerer som inndata for Reduce()- eller Reducer-funksjonen.
Reduser
De mellomliggende nøkkel-verdi-parene fra kartleggingsfasen fungerer som inndata for Reduser-funksjonen. Denne fasen omfatter også to deloppgaver: blanding og redusering.
Nøkkel-verdi-parene sorteres og blandes før de sendes til reduseringsenheten. Deretter grupperer eller aggregerer Reducer dataene i henhold til nøkkel-verdi-paret basert på reduseringsalgoritmen som utvikleren har skrevet.
Her kombineres verdiene fra blandingsfasen for å generere en utdataverdi. Denne fasen oppsummerer hele datasettet.
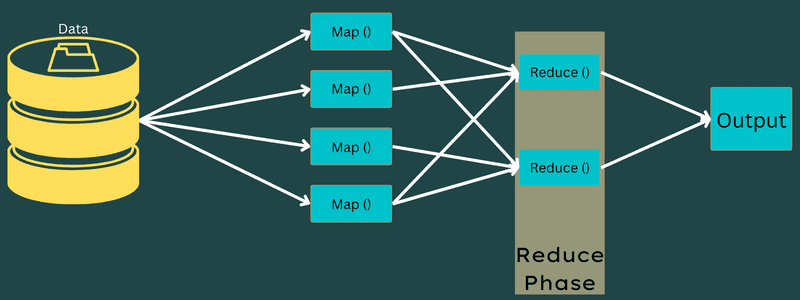
Hele prosessen med å utføre kart- og reduksjonsoppgaver styres av flere enheter:
- Jobbsporing: En jobbsporing fungerer som en hovedkomponent som er ansvarlig for å utføre en innsendt jobb. Den administrerer alle jobber og ressurser i en klynge. I tillegg planlegger jobbsporingen alle kartoppgaver som legges til oppgavesporerne som kjører på bestemte datanoder.
- Flere oppgavesporere: Oppgavesporere fungerer som hjelpekomponenter som utfører oppgavene i henhold til instruksjonene fra jobbsporingen. En oppgavesporer er distribuert på hver node i klyngen og utfører kart- og reduksjonsoppgaver.
Dette fungerer fordi en jobb deles opp i flere oppgaver som kjøres på forskjellige datanoder i en klynge. Jobbsporingen koordinerer arbeidet ved å planlegge oppgaver og kjøre dem på forskjellige datanoder. Oppgavesporerne på hver datanode utfører deler av jobben og overvåker hver oppgave.
Oppgavesporerne sender statusrapporter til jobbsporingen og sender også jevnlig «hjertebank»-signaler for å informere om systemstatusen. Ved feil kan jobbsporingen omplanlegge jobben på en annen oppgavesporer.
Utdatafase: I denne fasen mottar du de endelige nøkkel-verdi-parene fra Reducer. Du kan bruke en utdataformatering for å oversette disse parene og skrive dem til en fil ved hjelp av en plateskriver.
Hvorfor bruke MapReduce?
Her er noen fordeler med MapReduce som begrunner bruken i stordataprosjekter:
Parallell behandling
Med MapReduce kan en jobb deles opp i ulike deler som behandles samtidig på forskjellige noder. Dette reduserer kompleksiteten i store oppgaver. Ettersom oppgaver kjøres parallelt på forskjellige maskiner, istedenfor på en enkelt maskin, reduseres behandlingstiden betydelig.
Datalokalitet
I MapReduce flyttes prosessorenheten til dataene, istedenfor omvendt.
Tradisjonelt ble dataene flyttet til prosessorenheten for behandling. Med den raske økningen av datamengder har denne prosessen begynt å by på utfordringer som høye kostnader, økt tidsbruk, belastning av hovednoden, hyppige feil og redusert nettverksytelse.
MapReduce løser disse problemene ved å flytte prosessorenheten til dataene. Dataene distribueres mellom ulike noder, der hver node behandler en del av de lagrede dataene.
Dette fører til kostnadseffektivitet og redusert behandlingstid siden hver node fungerer parallelt med sin tilsvarende datadel. I tillegg unngår man overbelastning, da hver node behandler en liten del av dataene.
Sikkerhet

MapReduce-modellen tilbyr høy sikkerhet og beskytter applikasjonen mot uautorisert tilgang samtidig som klyngesikkerheten forbedres.
Skalerbarhet og fleksibilitet
MapReduce er et svært skalerbart rammeverk. Det muliggjør kjøring av applikasjoner på flere maskiner med data i terabyte-størrelse. Det er fleksibelt og kan behandle data i strukturerte, semistrukturerte og ustrukturerte formater, med alle formater og størrelser.
Enkelhet
MapReduce-programmer kan skrives i en rekke programmeringsspråk, som Java, R, Perl, Python og andre. Dette gjør det enkelt for alle å lære og skrive programmer som dekker databehandlingsbehov.
Bruksområder for MapReduce
- Fulltekstindeksering: MapReduce brukes til fulltekstindeksering. Mapper-funksjonen kartlegger hvert ord i et dokument, mens Reducer skriver alle kartlagte elementer til en indeks.
- Beregning av PageRank: Google bruker MapReduce til å beregne PageRank.
- Logganalyse: MapReduce kan brukes til å analysere loggfiler. Store loggfiler deles opp, og kartleggeren søker etter tilgjengelige nettsider.
Nøkkel-verdi-par sendes til reduseringsfunksjonen når en nettside identifiseres i loggen. Nettsiden er nøkkelen, og indeksen «1» er verdien. Etter å ha matet nøkkel-verdi-par til Reducer, samles ulike nettsider. Det endelige resultatet er det totale antall treff for hver nettside.

- Omvendt Web-Link Graph: Rammeverket brukes også i Reverse Web-Link Graph. Map()-funksjonen mottar URL-målet og kilden, og tar innspill fra kilden eller nettsiden.
Reduce()-funksjonen samler listen over kilde-URL-er som er knyttet til mål-URL-en, og produserer kilder og mål.
- Ordtelling: MapReduce brukes til å telle hvor mange ganger et ord forekommer i et dokument.
- Global oppvarming: MapReduce kan brukes av organisasjoner, myndigheter og selskaper for å håndtere problemstillinger rundt global oppvarming.
Dette kan for eksempel inkludere å analysere temperaturendringer i havet. Her samles store mengder data som høy temperatur, lav temperatur, breddegrad, lengdegrad, dato og klokkeslett. Dette krever flere kart- og reduseringsprosesser for å beregne utdataene ved hjelp av MapReduce.
- Legemiddelforskning: Tradisjonelt har dataforskere og matematikere samarbeidet om å utvikle nye medisiner. Med MapReduce kan IT-avdelinger i organisasjoner håndtere problemer som tidligere kun ble behandlet av superdatamaskiner og forskere med doktorgrad. Effektiviteten av et legemiddel på en gruppe pasienter kan for eksempel analyseres.
- Andre applikasjoner: MapReduce kan behandle store datamengder som ikke passer inn i en relasjonsdatabase. Det brukes også i datavitenskapelige verktøy for å analysere distribuerte datasett, som tidligere kun var mulig på en enkelt datamaskin.
På grunn av MapReduces robusthet og enkelhet, har det et bredt spekter av applikasjoner innen militæret, næringslivet, vitenskapen og andre områder.
Konklusjon
MapReduce har vist seg å være et banebrytende konsept innen teknologi. Det er ikke bare en raskere og enklere prosess, men også kostnadseffektiv og mindre tidkrevende. Gitt fordelene og økende bruken, er det sannsynlig at MapReduce vil spille en stadig viktigere rolle på tvers av ulike bransjer og organisasjoner.
Du kan også utforske ressurser for å lære mer om stordata og Hadoop.
«`