Tidligere innebar konstruksjon av automatiserte programvaresystemer oppsett av flere servere med dedikert prosessorkraft, minne, lagring og andre ressurser. Deretter ble det etablert team av administratorer for å håndtere disse systemene. Utviklingsteamet overtok deretter infrastrukturen og begynte å utvikle prosesser for å koble sammen serverne.
Denne prosessen kan være kompleks, ettersom den involverer mange ulike grupper som jobber mot et felles mål. Disse interessekonfliktene kan da skape utfordringer.
Det kan også være ganske kostbart. Dette krever at man har administratorer på lønningslisten. Serverne, som kjører kontinuerlig, bruker ressurser selv når de ikke er i bruk.
For å opprettholde optimal ytelse over tid, er det nødvendig med en automatisk skaleringsløsning som justerer serverressursene etter behov.
Skyplattformen har en fordel: den tillater opprettelse av en helhetlig arkitektur uten behov for serverklyngeoppsett. Fra et administrativt synspunkt er det ingenting som trenger vedlikehold.
Dette er et kostnadseffektivt alternativ for oppstartsbedrifter og i den første fasen av prosjekter (MVP). Det er et godt utgangspunkt dersom det er vanskelig å forutse fremtidig produksjonsbelastning og brukeraktivitet. Det er i slike tilfeller det kan være vanskelig å bestemme konfigurasjonen av serverklynger.
Automatisering av prosesser gjennom serverløse skytjenester er det som gjør at serverløs arkitektur skiller seg ut. Den kobler sammen tjenester og gir resultater som ligner de man får fra tradisjonelle serverklynger.
Her følger et eksempel på hvordan en slik arkitektur kan bygges ved hjelp av kun native AWS-tjenester.
Serverløs tjenesteflyt
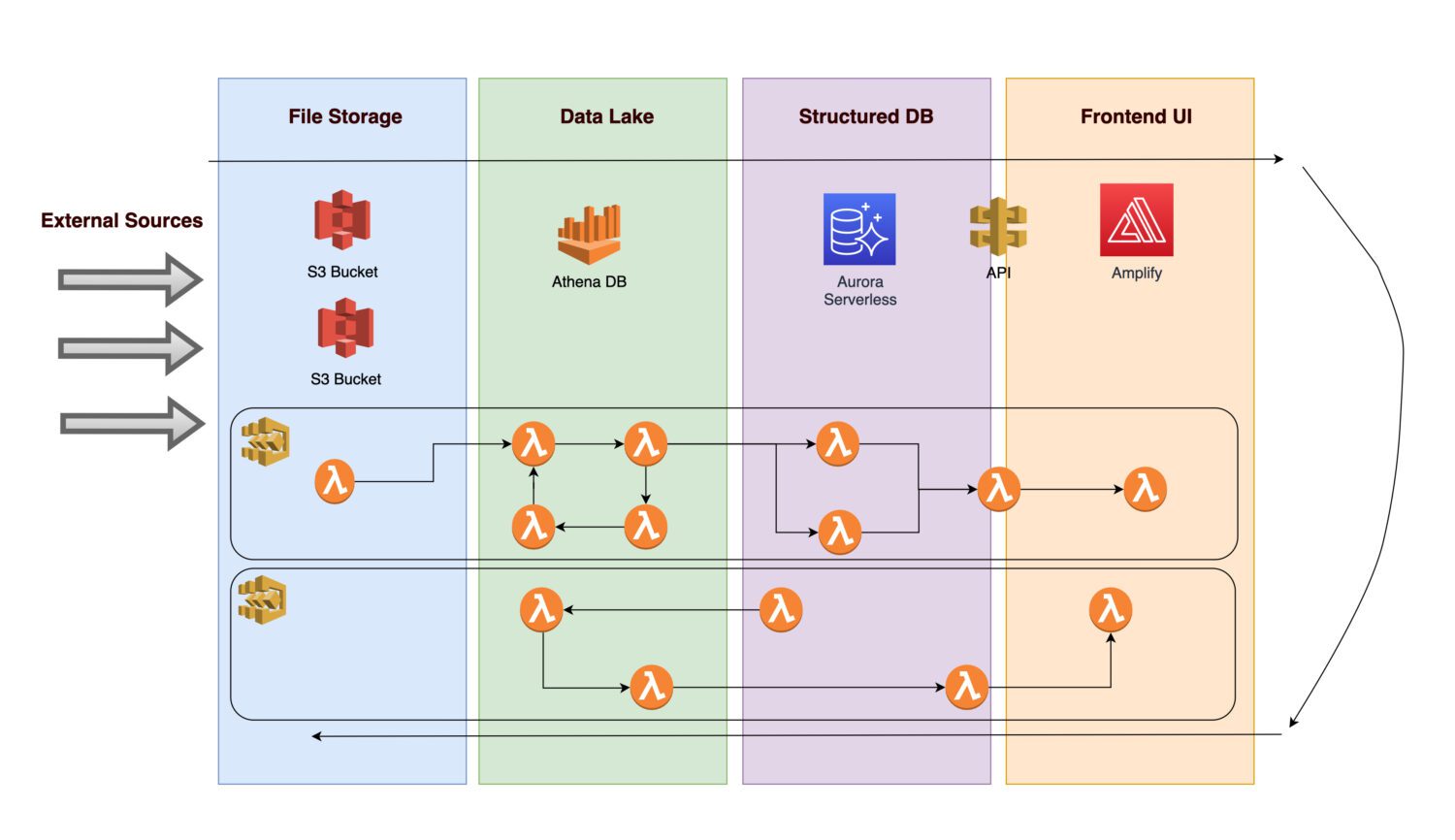
Tenk deg at du ønsker å lage en plattform for å samle ulike data og bilder (eller andre typer visuelt materiale) av spesifikke infrastrukturelementer (dette kan være en hvilken som helst produksjons- eller bruksressurs).
- For å muliggjøre fremtidig analyse, må innkommende data først samles inn.
- Etter å ha anvendt forretningsregler, lagrer en back-end-prosedyre de beregnede resultatene som normalisert informasjon i en relasjonsdatabase.
- Et applikasjonsgrensesnitt som viser de normaliserte og bearbeidede dataene, gjør det mulig for brukerne å se resultatene.
La oss se nærmere på hvilke komponenter en slik arkitektur kan inkludere.
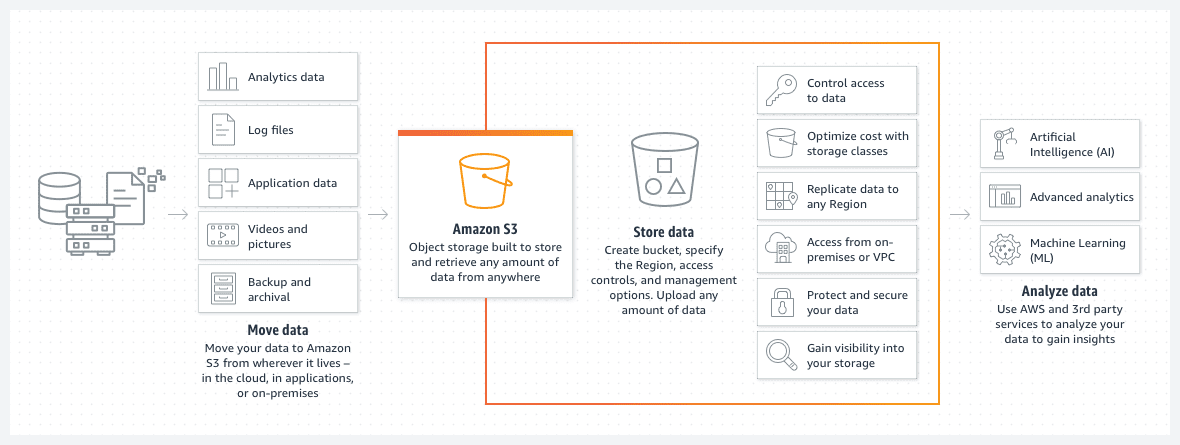
AWS S3-bøtter
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Amazon S3-bøtter er en effektiv måte å lagre filer eller bilder i AWS-skyen. Prisen for lagring i S3-bøtter er bemerkelsesverdig lav. Innføring av en livssykluspolicy for S3-bøtter kan redusere denne prisen ytterligere.
En slik policy vil automatisk flytte eldre filer til ulike klasser av S3-bøtter, for eksempel et arkiv eller dyp arkivtilgang. Disse klassene varierer også i tilgangstid, men for eldre data vil dette være mindre kritisk. Dette er primært for å få tilgang til arkiverte data i nødstilfeller, snarere enn for standard driftsbehov.
- Du kan organisere dataene dine i undermapper.
- Du bør angi passende tillatelsesbegrensninger.
- Legg til tagger i bøttene for å gjøre dem enkle å identifisere og for mulig bruk innenfor dynamiske S3-bøttepolicyer.
- Bøtten er serverløs per definisjon. Den er rett og slett et lagringssted for dataene dine.
En S3-bøtte er serverløs i sin natur. Den er rett og slett en plass for å lagre dine data.
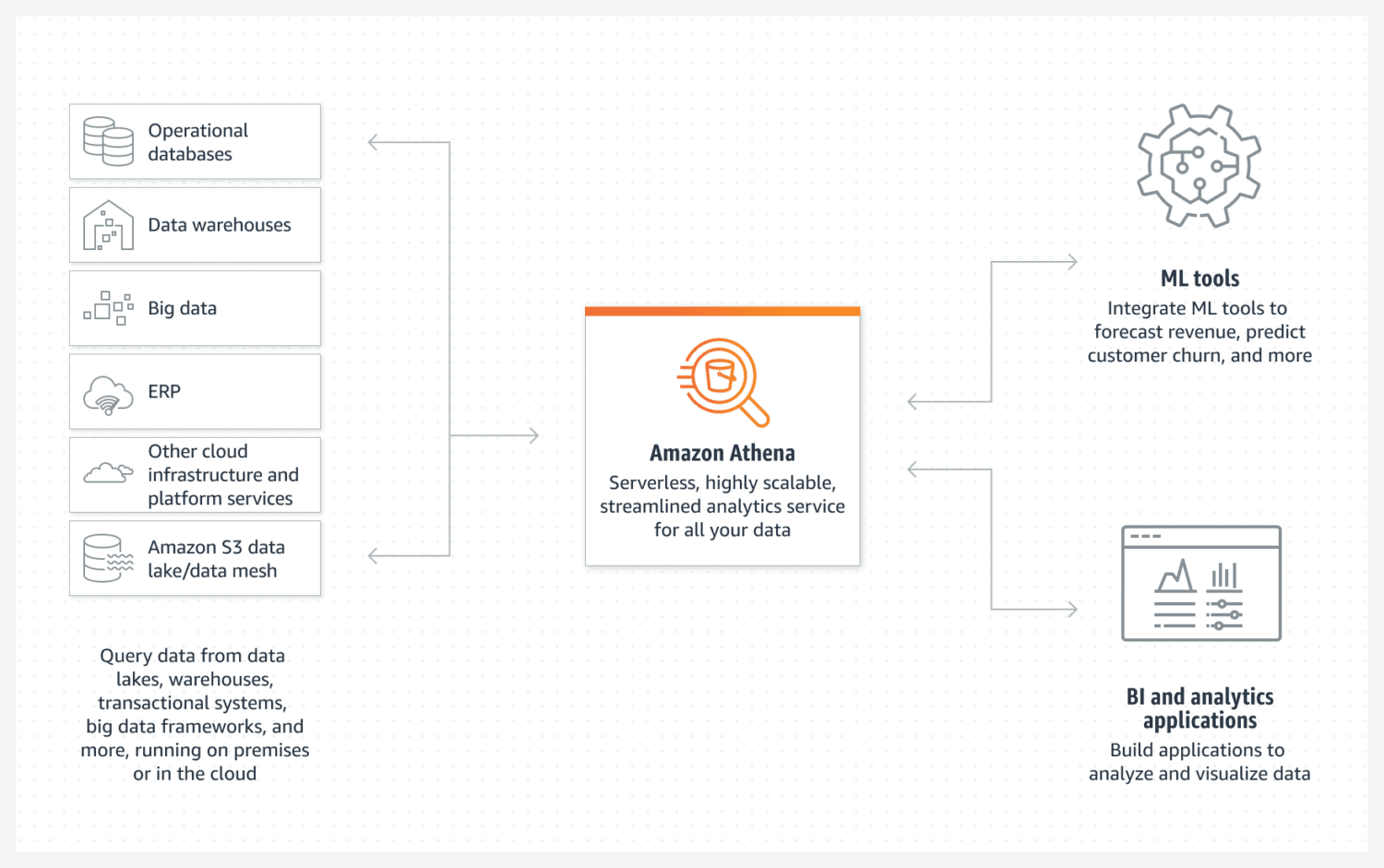
AWS Athena-database
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Athena gjør det enkelt å opprette en AWS-basert datainnsjø. Det er en serverløs database som bruker en S3-bøtte til å lagre dataene. Dataorganisering opprettholdes gjennom strukturerte filformater som Parquet eller CSV (comma-separated value). S3-bøtten inneholder filene, og Athena refererer til dem hver gang prosesser henter data fra databasen.
Vær oppmerksom på at Athena ikke støtter ulike funksjoner som ellers anses som standard, for eksempel oppdateringskommandoer. Derfor bør Athena betraktes som et svært enkelt alternativ.
Imidlertid støtter den indeksering og partisjonering. Den kan også skaleres horisontalt på en enkel måte, da det er like enkelt som å legge til nye bøtter i infrastrukturen. For enkel, men funksjonell opprettelse av datainnsjøer kan dette være tilstrekkelig i de fleste tilfeller.
For å oppnå god ytelse er det avgjørende å velge det beste datadesignet med tanke på fremtidig bruk. Det er viktig å ha et klart bilde av hvordan du ønsker å hente ut data. Det kan være vanskelig å gjenopprette tabeller senere når de allerede er opprettet og fylt med store mengder data.
Athena DB er et godt valg dersom du ønsker å opprette et enkelt, uforanderlig og lett skalerbart datalager.
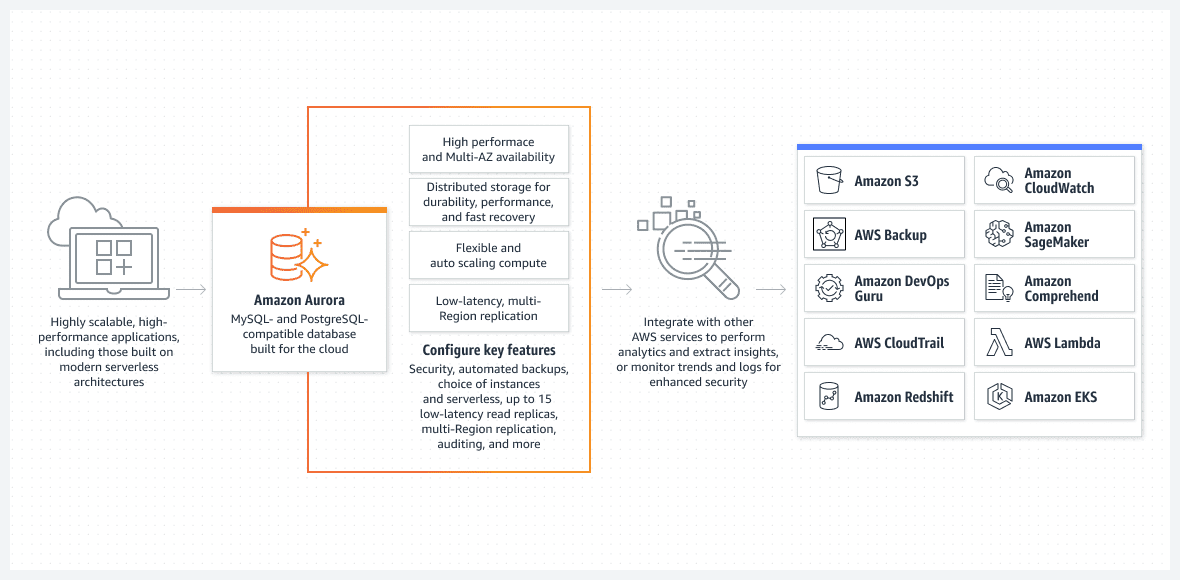
AWS Aurora-database
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Athena DB er utmerket for lagring av rådata. Dette er måten du ønsker å lagre originalt innhold på, for å maksimere fremtidig gjenbruk. Det er imidlertid tregt å hente utvalgte resultater til en frontend-applikasjon.
Et av de beste alternativene, særlig med tanke på hvor enkelt oppsettet er, er Aurora-databasen som kjører i serverløs modus.
Aurora er langt fra en grunnleggende database. Det er en av de mest avanserte, native relasjonsdatabaseløsningene i AWS. Det er også en svært kompleks relasjonsdatabaseløsning som stadig forbedres.
Aurora er unik fordi den kan kjøre i serverløs modus, noe som skiller den fra andre relasjonstjenester. Slik fungerer denne modusen:
- For å konfigurere Aurora-klyngen, bruker du AWS-konsollen. Du må spesifisere standard CPU- og RAM-nivåer, samt et maksimalt intervall for automatisk skaleringsfunksjonalitet. Dette vil påvirke ytelsen som Aurora-klyngen dynamisk kan legge til eller fjerne. Basert på gjeldende bruk av databasen, bestemmer AWS om databasen skal skaleres opp eller ned.
- Aurora-klyngen starter ikke med mindre brukeren eller prosessen starter en reell forespørsel. Dette kan være når planlagt batchbehandling starter, eller når applikasjonen utfører et back-end API-kall for å hente data fra en database. Databasen åpnes automatisk og forblir aktiv i en forhåndsdefinert periode etter at forespørselsprosessen er fullført.
- Aurora-klyngen slås automatisk av dersom det ikke er mer arbeid for databasen.
For å gjenta: serverløs Aurora DB kjører kun når det er behov for å utføre reelt arbeid. Den automatisk oppstartede klyngen slås av igjen hvis den ikke behandler noe arbeid. Det er det faktiske arbeidet du betaler for, ikke periodene den står tom.
Den serverløse Aurora er fullstendig administrert av AWS og krever ingen administrator.
AWS Amplify
Amplify tilbyr en serverløs plattform for rask utrulling av frontend-applikasjoner bygget med JavaScript og React-biblioteker. Det er ikke nødvendig å sette opp klyngeservere. Du kan bruke AWS-konsollen til å distribuere koden direkte, eller bruke en automatisert DevOps-pipeline.
Du kan kalle back-end API-er for å få tilgang til data lagret i databasene. Disse samtalene gir deg tilgang til de faktiske dataene i frontend-applikasjonen. Den viktigste ytelsesoptimaliseringen på back-end bør gjøres av utviklingsteamet. Du kan ytterligere redusere muligheten for trege responser i brukergrensesnittet ved å designe effektive datahentingskommandoer direkte i API-kallene.
AWS Step Functions
 Kilde: aws.amazon.com
Kilde: aws.amazon.com
Selv om alle hovedkomponentene i systemet er serverløse, garanterer ikke dette en fullstendig serverløs arkitektur. Dette er kun mulig dersom alle batchprosesser mellom komponentene også er serverløse.
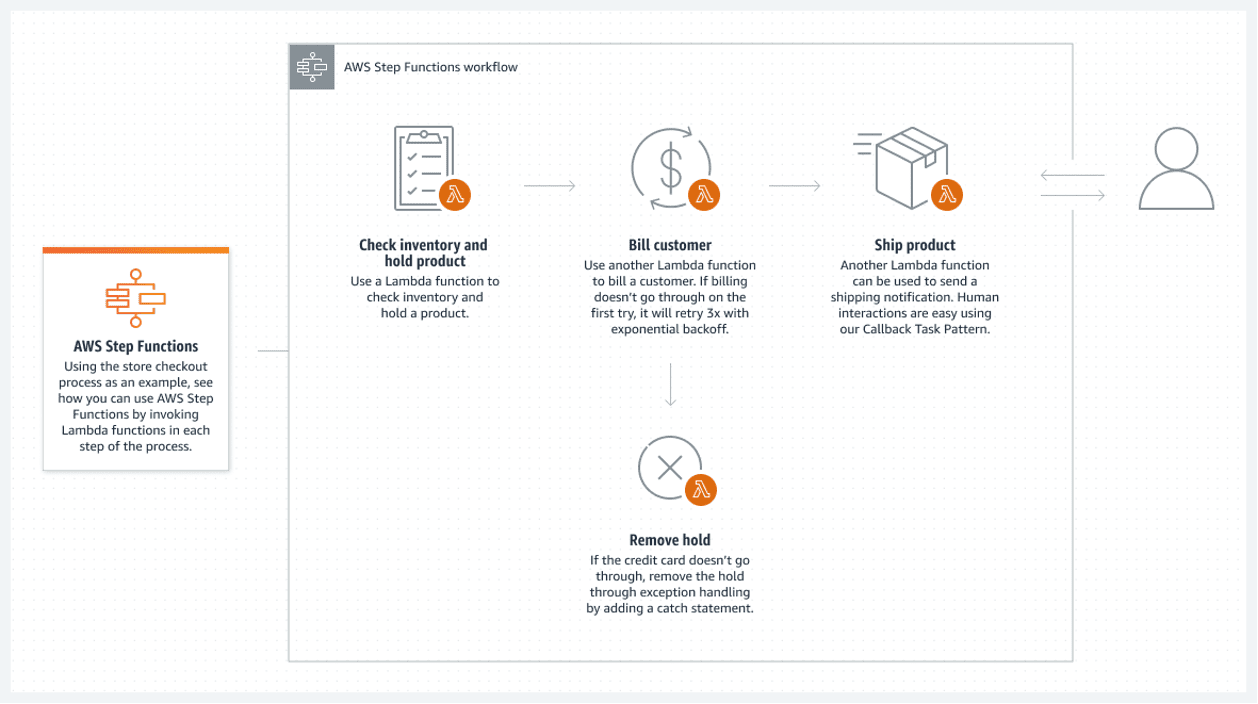
AWS Step Functions tilbyr den beste løsningen i AWS-skyen. En tilkoblet liste over AWS Lambda-funksjoner utgjør en trinnfunksjon. Disse funksjonene danner et flytskjema med klare start- og sluttilstander. En Lambda-funksjon, vanligvis skrevet i Python eller Node.js, er en kjørbar kodebit som behandler det som er nødvendig.
Her er et eksempel på hvordan en trinnfunksjon kan fungere:
Denne serverløse flyten har en stor ulempe: hver lambda-funksjon kan maksimalt kjøre i 15 minutter. Å dele opp strømmen i mindre lambda-funksjoner kan derfor redusere problemene dette skaper.
Det er mulig å kalle flere lambda-funksjoner samtidig i ett trinn, noe som i praksis betyr at man parallelliserer et trinn med flere lambda-funksjoner som utføres samtidig. Man venter deretter til all parallell lambda-behandling er ferdig før man går videre. Fortsett deretter til neste lambda-behandling.
Avsluttende ord
Serverløs arkitektur gir en unik mulighet til å lage en skyplattform som dekker hele systemlandskapet. Denne plattformen er horisontalt skalerbar og har lave driftskostnader, samtidig som den er effektiv.
Det er en perfekt løsning for prosjekter med begrenset budsjett. Det er et utmerket alternativ for utforskning, særlig når man ikke kjenner de reelle produksjonsbelastningene. Dette er spesielt viktig etter at du har lykkes med alle brukere. Prosjektteamene kan fortsatt ha et samlet overblikk over hvordan systemet fungerer. Du kan nyte alle disse fordelene uten å måtte inngå kompromisser.
Denne tilnærmingen vil ikke passe i alle tilfeller, særlig de som krever høy prosessorkraft. AWS-skyen er imidlertid i stadig utvikling når det gjelder serverløse bruksområder. Det er som regel en god idé å foreta grundige undersøkelser før du bestemmer deg for en serverløs løsning for ditt neste AWS-skyprosjekt.
Du kan deretter se nærmere på de beste serverløse databasene for moderne applikasjoner.