Se for deg en omfattende infrastruktur bestående av forskjellige typer enheter som krever jevnlig vedlikehold og tilsyn for å sikre at de ikke utgjør en fare for omgivelsene.
En vanlig tilnærming er å sende personell til hvert enkelt sted for å utføre inspeksjoner. Denne metoden er gjennomførbar, men kan være kostbar både i form av tid og ressurser. I tilfeller med store infrastrukturer kan det til og med være vanskelig å rekke over alle lokasjoner innenfor et kalenderår.
En alternativ løsning er å automatisere denne prosessen og overføre verifiseringen til skybaserte tjenester. For å realisere dette, må følgende trinn gjennomføres:
👉 Etabler en effektiv metode for å anskaffe bilder av enhetene. Dette kan fortsatt utføres av personell, da fotografering er betydelig raskere enn å gjennomføre en fullstendig enhetsverifisering. Alternativt kan bilder samles inn fra kjøretøy eller droner, noe som fører til en raskere og mer automatisert prosess for bildeinnsamling.
👉 Overfør alle innsamlede bilder til en dedikert plassering i skyen.
👉 Implementer en automatisert oppgave i skyen som henter bildene og prosesserer dem ved hjelp av maskinlæringsmodeller. Disse modellene må være trent for å identifisere enhetsskader eller uregelmessigheter.
👉 Til slutt må resultatene være tilgjengelige for relevante brukere, slik at reparasjonsarbeid kan planlegges for enheter med identifiserte problemer.
La oss undersøke hvordan vi kan oppnå deteksjon av anomalier fra bilder ved hjelp av AWS-skyen. Amazon tilbyr en rekke forhåndsutviklede maskinlæringsmodeller som kan anvendes til dette formålet.
Hvordan utvikle en modell for visuell anomali deteksjon
For å skape en effektiv modell for å oppdage visuelle anomalier, må flere trinn følges:
Trinn 1: Definer klart og tydelig problemstillingen du ønsker å løse, samt hvilke typer anomalier du vil identifisere. Dette vil hjelpe deg med å finne de rette testdatasettene som er nødvendige for å trene modellen.
Trinn 2: Samle et omfattende datasett med bilder som representerer både normale og unormale tilstander. Merk bildene for å indikere hvilke som er normale, og hvilke som inneholder anomalier.
Trinn 3: Velg en passende modellarkitektur for oppgaven. Dette kan innebære å bruke en forhåndstrent modell og finjustere den for ditt spesifikke bruksområde, eller å utvikle en tilpasset modell fra grunnen av.
Trinn 4: Tren modellen ved å bruke det forberedte datasettet og den valgte algoritmen. Dette kan inkludere å benytte overføringslæring for å utnytte eksisterende modeller, eller å trene modellen fra bunnen av ved hjelp av metoder som konvolusjonelle nevrale nettverk (CNN).
Slik trener du en maskinlæringsmodell
Kilde: aws.amazon.com
Prosessen med å trene maskinlæringsmodeller i AWS for visuell anomali deteksjon omfatter vanligvis flere viktige etapper.
#1. Innhent data
Først og fremst må du samle og merke et stort datasett med bilder som gjenspeiler både vanlige og avvikende forhold. Jo større datasettet er, desto bedre og mer nøyaktig kan modellen trenes. Dette fører imidlertid også til at mer tid må brukes til trening av modellen.
Som en tommelfingerregel er et testsett med omtrent 1000 bilder et godt utgangspunkt.
#2. Forbered dataene
Bildedataene må forbehandles for at maskinlæringsmodellene skal kunne analysere dem. Forbehandling kan omfatte ulike operasjoner, som for eksempel:
- Organisering av inngangsbilder i separate undermapper, samt korrigering av metadata.
- Endre bildestørrelsen slik at den tilfredsstiller oppløsningskravene til modellen.
- Deler opp bildene i mindre enheter for å muliggjøre mer effektiv og parallell prosessering.
#3. Velg modell
Deretter skal du velge en modell som er passende for den aktuelle oppgaven. Du kan enten benytte en forhåndstrent modell, eller du kan utvikle en skreddersydd modell som er optimalisert for den visuelle anomali deteksjonen.
#4. Evaluer resultatene
Etter at modellen har behandlet datasettet, må du vurdere ytelsen. Det er viktig å kontrollere om resultatene oppfyller kravene. For eksempel kan det være ønskelig at resultatene er korrekte i mer enn 99 % av tilfellene.
#5. Implementer modellen
Dersom du er tilfreds med resultatene og ytelsen, kan du implementere modellen med en spesifikk versjon i AWS-miljøet, slik at prosesser og tjenester kan begynne å benytte den.
#6. Overvåk og forbedre
La modellen gjennomgå ulike tester og bilde datasett, og evaluer kontinuerlig om de nødvendige parameterne for deteksjonsnøyaktighet fortsatt er tilstede.
Dersom ikke, trenes modellen på nytt ved å inkludere nye datasett der modellen gav feil resultater.
AWS maskinlæringsmodeller
La oss nå se nærmere på noen konkrete modeller som kan utnyttes i Amazon-skyen.
AWS Rekognition
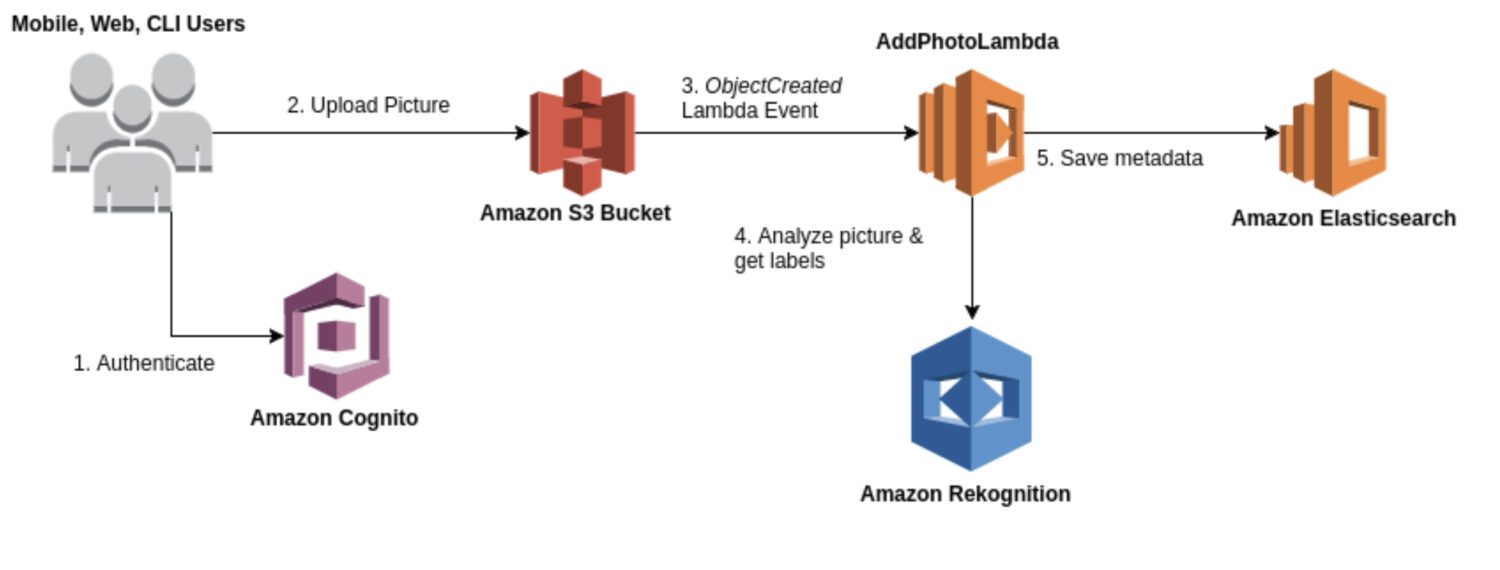
Kilde: aws.amazon.com
Rekognition er en generell tjeneste for bilde- og videoanalyse som kan brukes i ulike sammenhenger, som for eksempel ansiktsgjenkjenning, objektgjenkjenning og tekstgjenkjenning. Rekognition-modellen benyttes ofte for å danne et innledende datagrunnlag av identifiserte anomalier.
Den tilbyr en rekke forhåndsutviklede modeller som kan tas i bruk uten trening. Rekognition leverer også sanntidsanalyse av bilder og videoer med høy nøyaktighet og lav forsinkelse.
Her er noen typiske situasjoner der Rekognition er et godt valg for deteksjon av avvik:
- Generell bruk for deteksjon av uregelmessigheter, for eksempel i bilder eller videoer.
- Sanntids deteksjon av anomalier.
- Integrering av anomali deteksjonsmodellen med AWS-tjenester som Amazon S3, Amazon Kinesis eller AWS Lambda.
Her er noen eksempler på uregelmessigheter som kan oppdages ved hjelp av Rekognition:
- Anomalier i ansikter, for eksempel å oppdage ansiktsuttrykk eller følelser utenfor normalområdet.
- Manglende eller feilplasserte objekter i en scene.
- Feilstavede ord eller uvanlige tekstmønstre.
- Uvanlige lysforhold eller uventede gjenstander i en scene.
- Upassende eller støtende innhold i bilder eller videoer.
- Plutselige endringer i bevegelse eller uventede bevegelsesmønstre.
AWS Lookout for Vision
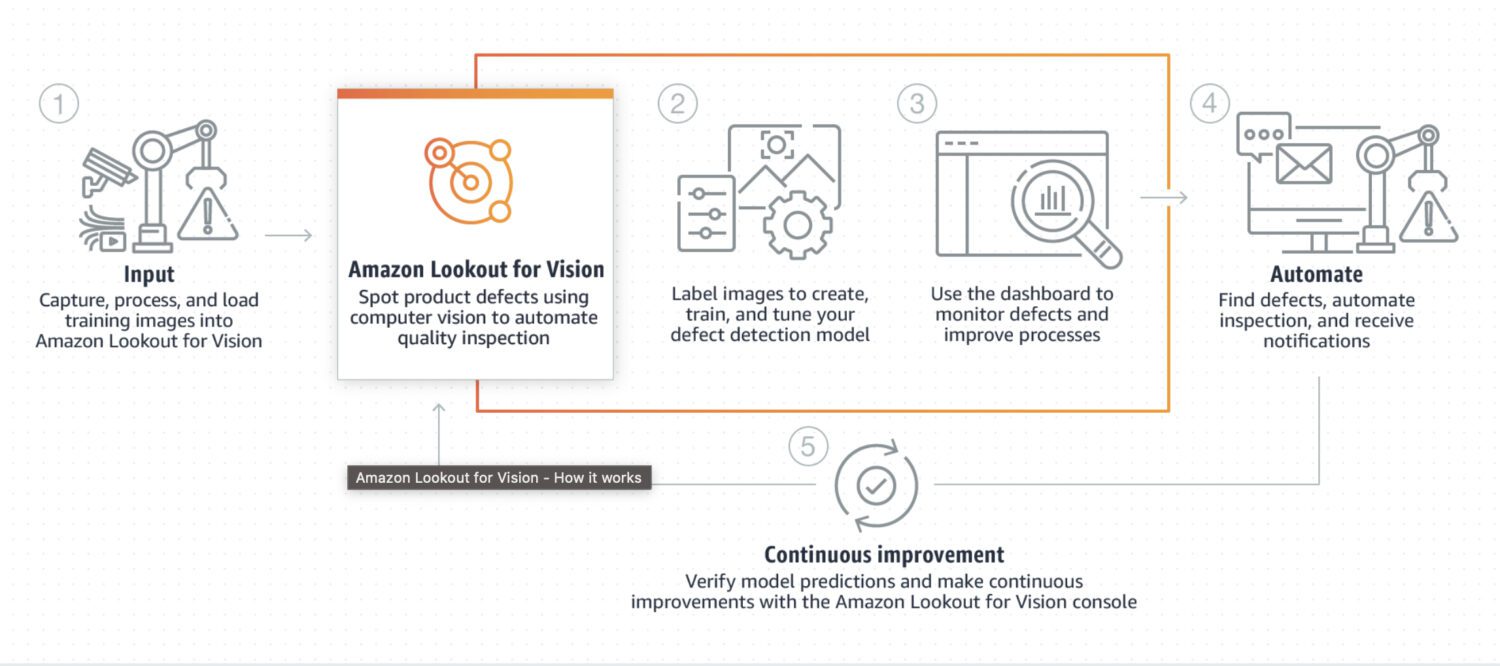
Kilde: aws.amazon.com
Lookout for Vision er en modell som er spesielt utviklet for å identifisere avvik i industrielle prosesser, slik som produksjons- og samlebånd. Det krever vanligvis en del tilpasset kode for forbehandling og etterbehandling av et bilde eller et spesifikt utsnitt av bildet, ofte ved hjelp av programmeringsspråket Python. Den spesialiserer seg hovedsakelig på spesifikke problemstillinger i et bilde.
Den krever tilpasset trening med et datasett av normale og unormale bilder for å utvikle en spesialtilpasset modell for deteksjon av avvik. Den er ikke like rettet mot sanntidsanalyse, men er designet for batch prosessering av bilder, med fokus på nøyaktighet og presisjon.
Her er noen typiske bruksområder der Lookout for Vision er et godt valg dersom du trenger å identifisere:
- Defekter i ferdigvarer eller identifisering av utstyrsfeil i en produksjonslinje.
- Et omfattende datasett med bilder eller annen informasjon.
- Sanntidsanomali i en industriell prosess.
- Anomali integrert med andre AWS-tjenester, som Amazon S3 eller AWS IoT.
Og her er noen konkrete eksempler på uregelmessigheter som du kan oppdage ved bruk av Lookout for Vision:
- Defekter i produserte produkter, som riper, bulker eller andre feil som kan påvirke produktkvaliteten.
- Utstyrsfeil i en produksjonslinje, som for eksempel å oppdage ødelagte eller feilfungerende maskiner som kan forårsake forsinkelser eller sikkerhetsfarer.
- Kvalitetskontrollproblemer i en produksjonslinje, som omfatter å identifisere produkter som ikke oppfyller de nødvendige spesifikasjonene eller toleransene.
- Sikkerhetsfarer i en produksjonslinje, herunder identifisering av gjenstander eller materialer som kan utgjøre en risiko for arbeidere eller utstyr.
- Anomalier i en produksjonsprosess, som for eksempel å identifisere uventede endringer i material- eller produktflyten gjennom produksjonslinjen.
AWS Sagemaker
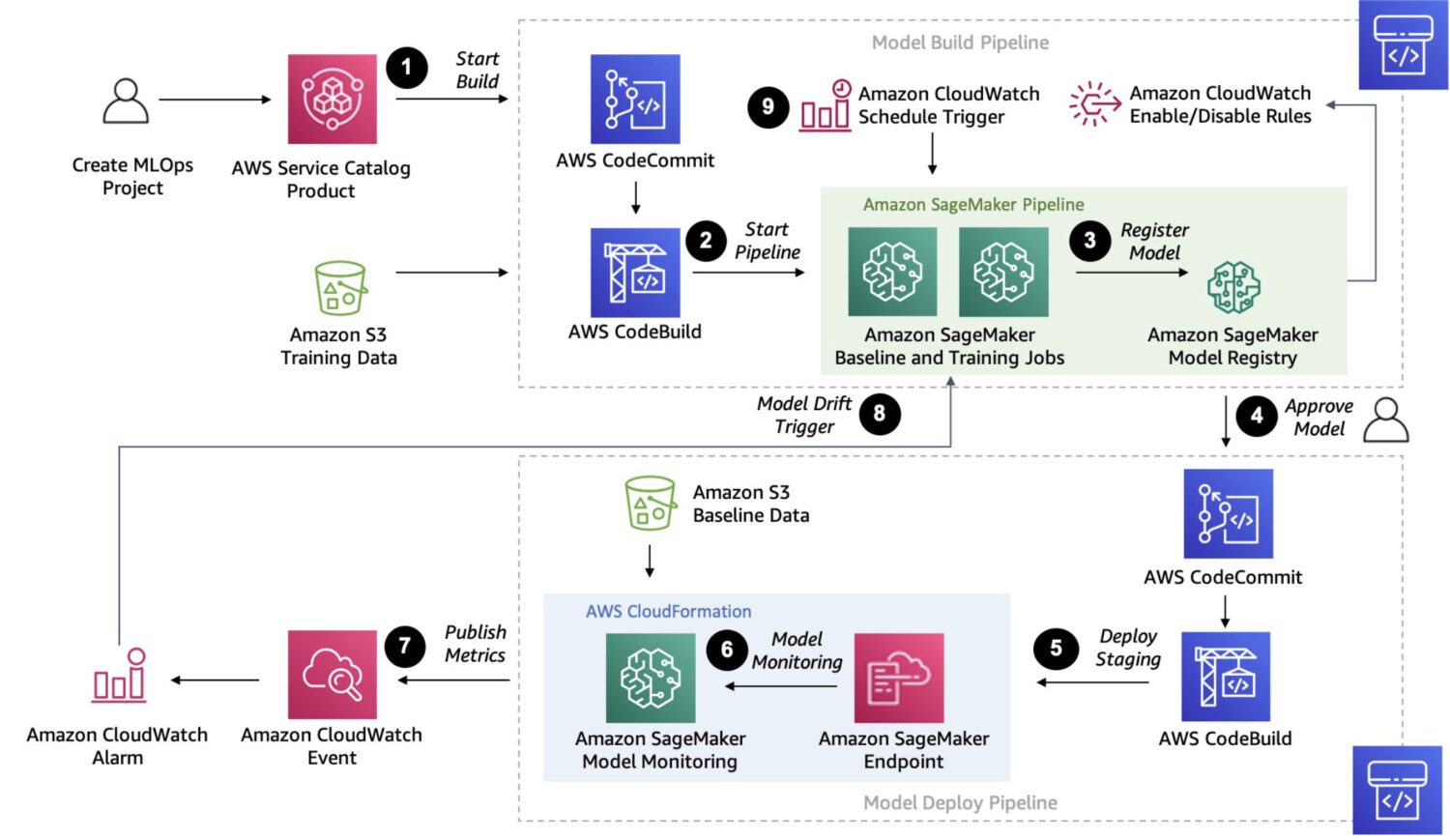
Kilde: aws.amazon.com
Sagemaker er en fullt administrert plattform for utvikling, trening og implementering av tilpassede maskinlæringsmodeller.
Det er en langt mer robust løsning. Den muliggjør sammensetting og gjennomføring av komplekse flertrinnsprosesser i en sammenhengende kjede, på samme måte som AWS Step Functions.
Siden Sagemaker benytter ad-hoc EC2-instanser for prosessering, er det ikke 15-minutters tidsbegrensning for enkeltjobber som i tilfellet med AWS Lambda-funksjoner i AWS Step Functions.
Sagemaker muliggjør også automatisk modelljustering, som er en særegen funksjon. I tillegg kan Sagemaker enkelt implementere modeller i et produksjonsmiljø.
Her er noen typiske bruksområder hvor Sagemaker er et godt valg for å oppdage anomalier:
- Spesifikke bruksområder som ikke dekkes av forhåndsutviklede modeller eller APIer, og hvor du trenger en tilpasset modell for dine unike behov.
- Dersom du har et stort datasett med bilder eller annen informasjon. Forhåndsutviklede modeller krever en del forbehandling i slike tilfeller, men Sagemaker kan håndtere dette uten.
- Dersom du trenger sanntidsanomali deteksjon.
- Dersom du trenger å integrere modellen din med andre AWS-tjenester, som Amazon S3, Amazon Kinesis eller AWS Lambda.
Her er noen typiske anomalideteksjoner som Sagemaker kan utføre:
- Oppdage svindel i finansielle transaksjoner, som uvanlige forbruksmønstre eller transaksjoner utenfor normalområdet.
- Cybersikkerhet i nettverkstrafikk, som uvanlige mønstre for dataoverføring eller uventede tilkoblinger til eksterne servere.
- Medisinsk diagnose i medisinske bilder, som for eksempel påvisning av svulster.
- Uregelmessigheter i utstyrsytelsen, som å oppdage endringer i vibrasjoner eller temperatur.
- Kvalitetskontroll i produksjonsprosesser, for eksempel å oppdage feil i produkter eller identifisere avvik fra forventede kvalitetsstandarder.
- Uvanlige mønstre i energiforbruk.
Hvordan integrere modellene i en serverløs arkitektur
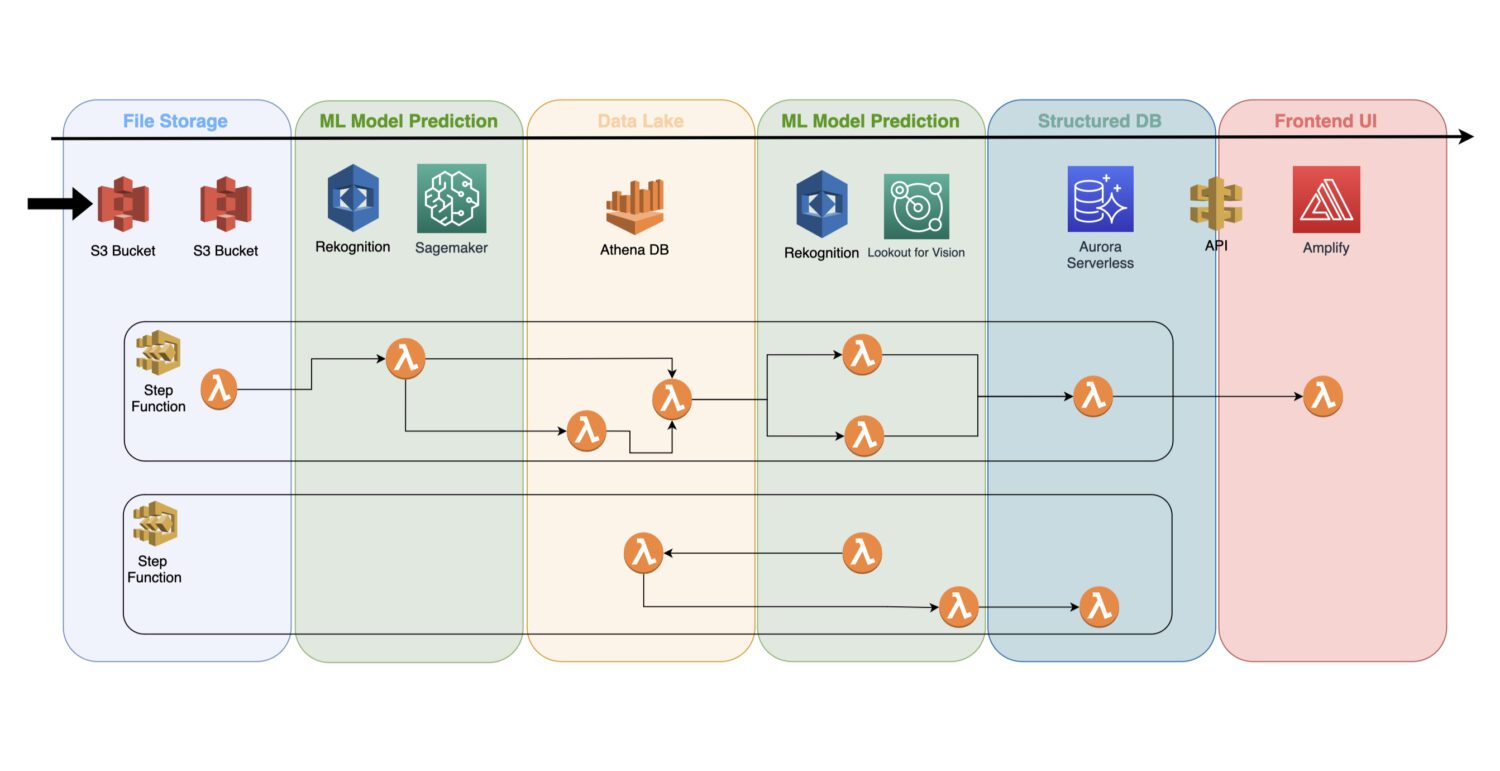
En trent maskinlæringsmodell er en skytjeneste som ikke benytter noen serverklynger i bakgrunnen, og derfor kan den enkelt inkluderes i en eksisterende serverløs arkitektur.
Automatiseringen skjer ved hjelp av AWS Lambda-funksjoner, som er koblet til en flertrinnsjobb i en AWS Step Functions-tjeneste.
Vanligvis kreves innledende gjenkjenning rett etter at bildene er innsamlet og forbehandlet i S3-bøtten. Det er her du vil generere deteksjon av de grunnleggende avvikene i inngangsbildene og lagre resultatene i en datainnsjø, som for eksempel representert ved Athena-databasen.
I noen tilfeller er ikke denne første deteksjonen tilstrekkelig for ditt spesifikke bruksområde. Det kan være behov for en annen, mer detaljert deteksjon. For eksempel kan den innledende modellen (f.eks. Rekognition) oppdage et problem med en enhet, men den identifiserer ikke nødvendigvis hva slags problem det er.
For dette formålet kan du trenge en annen modell med andre funksjoner. I slike tilfeller kan den andre modellen (f.eks. Lookout for Vision) kjøres på det undersettet av bilder der den opprinnelige modellen oppdaget problemet.
Dette er også en god måte å redusere kostnadene på, ettersom du ikke trenger å kjøre den andre modellen på alle bildene, men kun på det relevante undersettet.
AWS Lambda-funksjoner vil håndtere all slik prosessering med Python- eller Javascript-kode. Det er avhengig av prosessens natur og antall AWS Lambda-funksjoner som må inkluderes i arbeidsflyten. Grensen på 15 minutter for maksimal varighet av et AWS Lambda-anrop vil avgjøre hvor mange trinn en slik prosess må inneholde.
Siste kommentarer
Arbeid med skybaserte maskinlæringsmodeller er en interessant oppgave. Hvis vi ser på det fra et ferdighets- og teknologiperspektiv, vil vi se at det kreves et team med et bredt spekter av kunnskap.
Teamet må forstå hvordan man trener en modell, enten det er en forhåndsutviklet modell eller en som er laget fra bunnen av. Dette innebærer en del matematikk eller algebra for å balansere påliteligheten og ytelsen til resultatene.
Det kreves også avanserte programmeringsferdigheter i Python eller Javascript, samt database- og SQL-ferdigheter. Etter at utviklingsarbeidet er utført, trenger du DevOps-kompetanse for å knytte det til en pipeline som vil automatisere jobben for implementering og utførelse.
Å definere anomalien og trene modellen er en ting, men det er en utfordring å integrere alt dette i et funksjonelt team som kan behandle resultatene fra modellene og lagre dataene på en effektiv og automatisert måte for å betjene sluttbrukerne.
Du kan lese mer om ansiktsgjenkjenning for bedrifter her.