Python er et svært populært programmeringsspråk, spesielt innenfor databehandling og analyse. En av de store fordelene med Python er dets evne til å håndtere data i en rekke formater, slik som JSON, CSV og Excel-regneark.
I denne artikkelen vil vi se nærmere på noen av de mest nyttige Python-bibliotekene for datahåndtering, med spesielt fokus på Excel-regneark.
Hvorfor er Python egnet for databehandling?
- Python er kjent for sin lettfattelige syntaks, noe som gjør det til et tilgjengelig språk å lære. Dette har bidratt til dets store popularitet blant utviklere.
- Python er et allsidig språk som kan brukes i en rekke sammenhenger, fra kunstig intelligens og webutvikling til dataanalyse og utvikling av skrivebordsprogrammer.
- Det finnes et stort og aktivt fellesskap rundt Python, som bidrar med ressurser og støtte. Dette fører til at feil blir raskt identifisert og løst, og at utviklingen går raskt fremover.
- Python har et omfattende utvalg av biblioteker som er spesielt utviklet for databehandling, inkludert NumPy og Pandas, som vi skal se nærmere på i denne artikkelen.
La oss nå utforske de ulike bibliotekene som Python tilbyr for databehandling.
OpenPyXL
OpenPyXL er et Python-bibliotek som gjør det mulig å lese filer fra Microsoft Excel 2010 og nyere. Det støtter filformatene .xlsx, .xlsm, .xltm og .xltx. Dette biblioteket er en av de mest populære løsningene for å administrere Excel-data med Python.
Med OpenPyXL kan du åpne filer, opprette nye ark, redigere metadata, samt lese og skrive data. Dette gir deg fleksibilitet til å håndtere dine Excel-data direkte fra Python.
Pandas

Pandas er et svært populært bibliotek for databehandling, analyse og manipulering i Python. Det er et gratis og åpent kildekode bibliotek som tilbyr høy grad av fleksibilitet, brukervennlighet og hastighet.
Pandas kan lese data fra ulike kilder, inkludert Excel-filer. Biblioteket er kraftig og regnes som et av de viktigste verktøyene for enhver dataforsker.
Les også: Her er grunnen til at Pandas er det mest brukte Python-biblioteket for dataanalyse
xlrd

xlrd er et Python-bibliotek som er utviklet for å lese og formatere Excel-arbeidsbøker. Som de andre bibliotekene på denne listen er også xlrd gratis og åpen kildekode. Det er verdt å merke seg at xlrd kun støtter det eldre .xls-filformatet. Til tross for dette er det fortsatt et populært valg for mange.
pyexcel
pyexcel har som mål å tilby et enkelt grensesnitt for å arbeide med en rekke Excel- og regnearkformater, inkludert csv, ods, xls, xlsx og flere.
Med pyexcel er det enkelt å importere data fra disse filformatene, konvertere dem til arrays og dictionaries i minnet, og motsatt. Også dette biblioteket er gratis og åpen kildekode.
PyExcelerate
PyExcelerate er et bibliotek som er spesielt utviklet for rask og effektiv skriving av regneark. PyExcelerate er optimalisert for hastighet, men støtter kun skriving av regneark. En fordel med PyExcelerate er at det også støtter formatering av stil, i motsetning til mange andre biblioteker i denne listen. Dette biblioteket er spesielt nyttig hvis du ofte trenger å generere mange regneark raskt.
xlwings
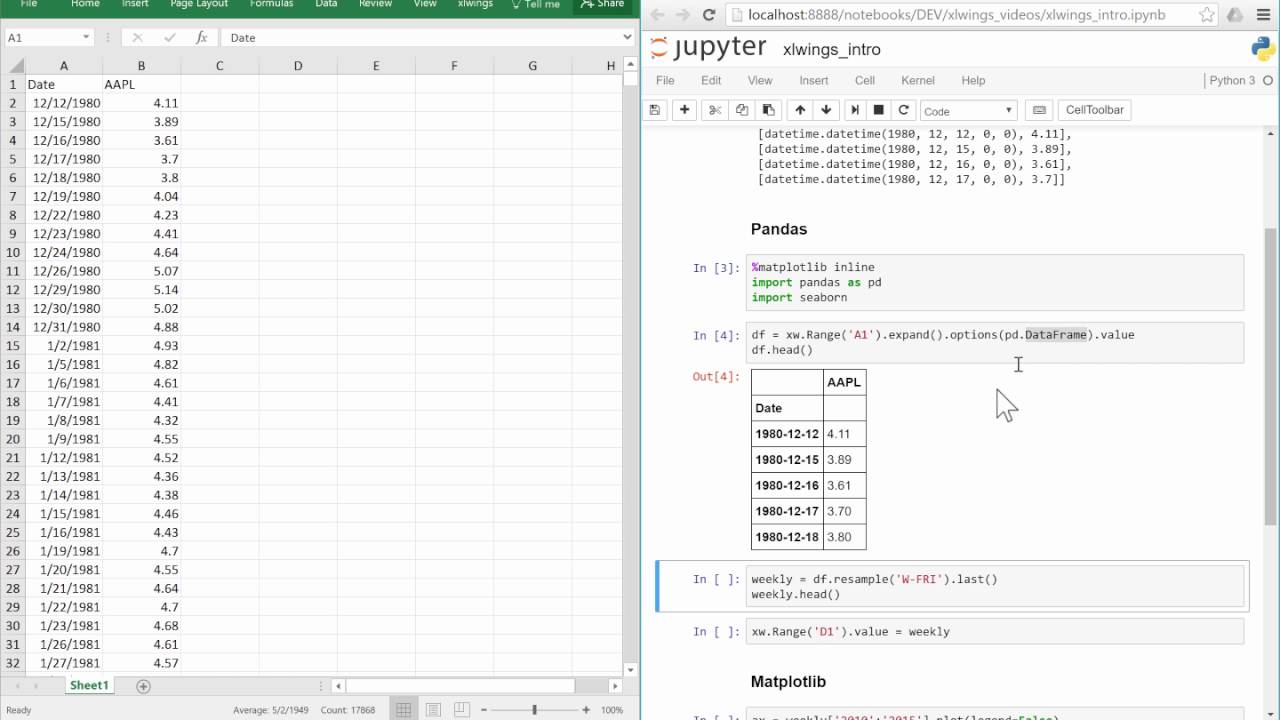
xlwings er en pakke med åpen kjerne som fungerer med Microsoft Excel og Google Sheets. Det er en automatiseringsløsning for regneark som kan erstatte VBA-makroer og Power Query.
Kjerneversjonen av xlwings er gratis og åpen kildekode, men det finnes også en betalt pro-versjon med tilleggsfunksjoner og support. Blant brukerne av xlwings finner vi store selskaper som Accenture, Nokia, Shell og EU-kommisjonen.
xlSlank

Med xlSlim kan du arbeide med regneark som om de var Jupyter-notatbøker. Det betyr at du kan skrive kode i interaktive celler i regnearket ditt. Denne koden kan kommunisere med data i arbeidsboken og utføre beregninger.
xlSlim har også en innebygd editor for Python-koden din. Du kan kalle opp VBA-funksjoner fra Python og bruke funksjoner definert i regnearket som om de var vanlige Excel-funksjoner.
NumPy

NumPy er et numerisk beregningsbibliotek i Python som er kjent for sin høye hastighet og evne til å behandle data effektivt.
Med NumPy kan du importere data fra CSV-filer til NumPy-matriser. Deretter kan du utføre en rekke databehandlingsoperasjoner fra ditt Python-program. Det er også mulig å skrive data tilbake til CSV-filer.
Pycel
Pycel kompilerer Excel-arbeidsbøkene dine til en Python-graf som kan kjøres uavhengig av Excel. Dette gjør Pycel nyttig for å utføre komplekse beregninger utenfor Excel, for eksempel i Python på en Linux-server.
Den genererte beregningsgrafen inneholder noder for alle cellene i arbeidsboken og deres relasjoner. Disse relasjonene og avhengighetene kan dynamisk beregne alle verdier når verdien til én celle endres.
Formler
Formler er en annen tolk for Excel-arbeidsbøkene dine. Denne Python-pakken med åpen kildekode leser Excel-arbeidsbøkene dine, analyserer formlene og kompilerer dem til Python. Denne Python-koden kan gjøre raskere beregninger på ulike datamaskiner uten behov for en installert Excel COM-server.
PyXLL

PyXLL gir et grensesnitt for å bruke Python i Excel. Med denne pakken kan du skrive Python-kode som kommuniserer med dataene i regnearkene dine, og du kan definere egne funksjoner som kan brukes i regnearkcellene dine.
I hovedsak fungerer PyXLL som en erstatning for VBA. Fordelen med PyXLL er at du kan utnytte hele Python-økosystemet og de forskjellige bibliotekene det tilbyr i Microsoft Excel.
Avsluttende tanker
Denne artikkelen har presentert ulike Python-biblioteker som kan brukes til databehandling i Excel-regneark. Disse bibliotekene gir deg muligheten til å lese inn og bruke data i et av de mest vanlige formatene for datarepresentasjon, nemlig Excel-regneark.
Med disse bibliotekene kan du utføre mer komplekse oppgaver og dra nytte av Pythons rike økosystem for å håndtere dine data.
Nå kan du gjerne utforske hvordan du kan lage en Pandas DataFrame.