Håndtering av PDF-filer med Python: Utpakking av tekst, lenker og bilder
Python er et utrolig fleksibelt programmeringsspråk, og som Python-utvikler vil du ofte støte på behovet for å bearbeide informasjon lagret i ulike filer. Et populært format du garantert vil jobbe med er Portable Document Format, eller PDF.
PDF-filer er ofte komplekse, og kan inneholde en blanding av tekst, bilder og hyperlenker. Når du arbeider med data i Python, kan det være nødvendig å hente ut denne informasjonen. I motsetning til enkle datastrukturer som tupler, lister og ordbøker, kan uthenting av data fra et PDF-dokument fremstå som utfordrende.
Heldigvis finnes det flere biblioteker som forenkler arbeidet med PDF-filer og utpakking av data. La oss undersøke hvordan du kan trekke ut tekst, lenker og bilder ved hjelp av disse verktøyene. For å følge med, last ned en PDF-fil og plasser den i samme mappe som Python-skriptet ditt.
Utpakking av tekst fra PDF-filer med PyPDF2
Vi vil starte med å bruke PyPDF2 for å hente ut tekst fra PDF-filer. PyPDF2 er et gratis og åpen kildekode bibliotek for Python som kan brukes til å manipulere PDF-filer, inkludert å slå sammen, beskjære og transformere sider. Det tillater også tilføying av tilpasset data, visningsalternativer og passordbeskyttelse. Mest relevant for oss, PyPDF2 kan også hente ut tekst fra PDF-dokumenter.
Før du kan bruke PyPDF2, må du installere det ved hjelp av pip, en pakkehåndterer for Python. Pip gjør det enkelt å installere ulike Python-pakker på systemet ditt.
Først, sjekk om pip allerede er installert ved å kjøre følgende kommando i terminalen:
pip --version
Hvis du ikke får et versjonsnummer tilbake, betyr det at pip ikke er installert.
For å installere pip, gå til denne lenken for å laste ned installasjonsskriptet.
Lenken vil åpne en side med skriptet for å installere pip:
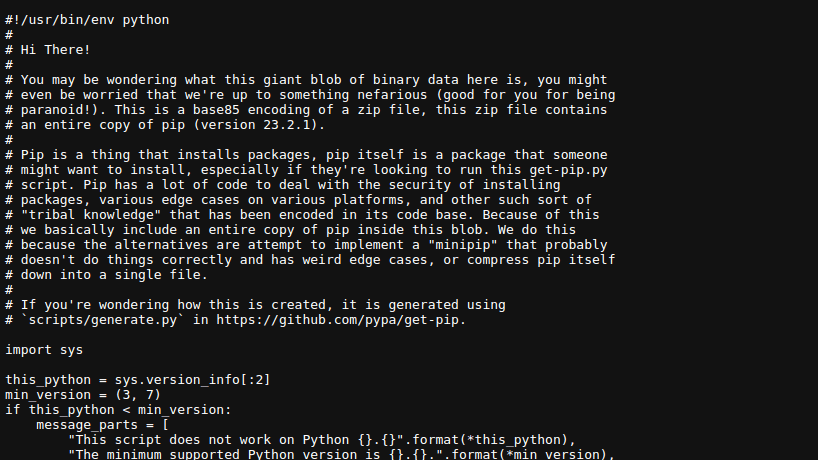
Høyreklikk på siden og velg «Lagre som» for å lagre filen, som standard er filnavnet `get-pip.py`.
Åpne terminalen, naviger til mappen der du lagret `get-pip.py`, og kjør følgende kommando:
sudo python3 get-pip.py
Dette vil installere pip:
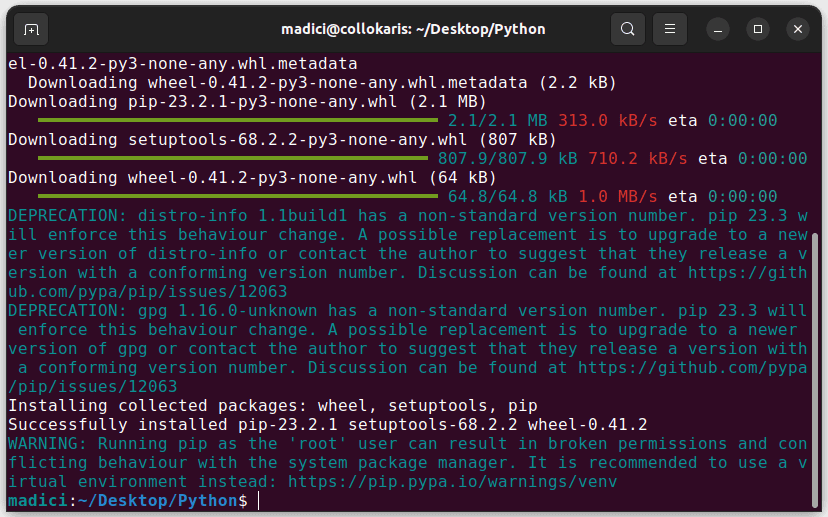
For å bekrefte at pip er installert, kjør:
pip --version
Et vellykket resultat vil vise et versjonsnummer:

Med pip installert kan vi nå begynne å bruke PyPDF2.
Installer PyPDF2 med kommandoen:
pip install PyPDF2
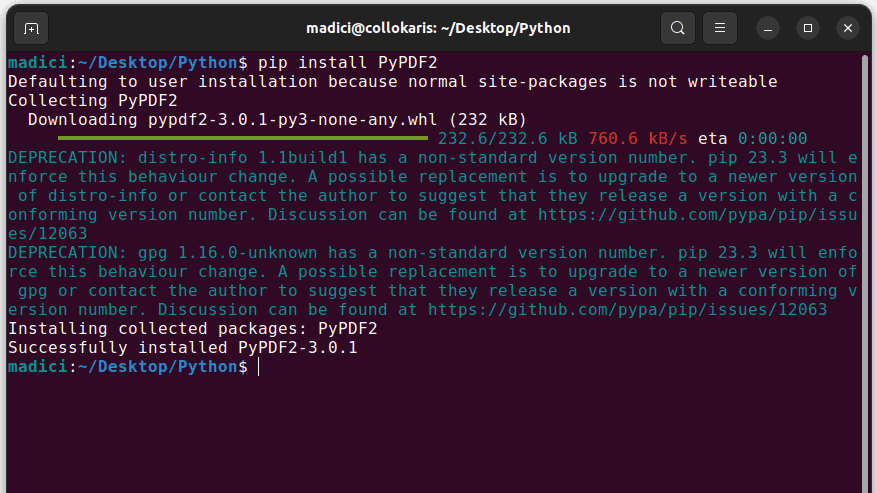
Deretter, opprett en Python-fil og importer `PdfReader` fra PyPDF2:
from PyPDF2 import PdfReader
PyPDF2-biblioteket tilbyr ulike klasser for arbeid med PDF-filer. En av disse er `PdfReader`, som kan brukes til å åpne PDF-filer, lese innhold og hente ut tekst.
For å starte, må du først åpne PDF-filen. Opprett en forekomst av `PdfReader` og spesifiser PDF-filen du vil bruke:
reader = PdfReader('games.pdf')
Denne koden initialiserer `PdfReader` og forbereder den for å lese innholdet i den angitte PDF-filen. Instansen lagres i variabelen `reader`, som gir tilgang til metoder og egenskaper fra `PdfReader` klassen.
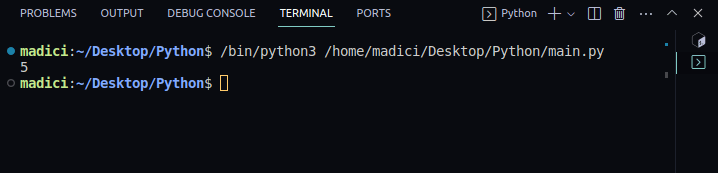
For å sjekke at alt fungerer, kan du skrive ut antall sider i PDF-filen:
print(len(reader.pages))
Utdata:
5
Siden PDF-filen har 5 sider, kan vi nå aksessere hver side. Husk at indekseringen begynner på 0, slik som i Python. Dermed vil den første siden være på indeks 0. Hent den første siden slik:
page1 = reader.pages[0]
Denne linjen henter den første siden og lagrer den i variabelen `page1`.
For å hente ut teksten fra den første siden, bruk:
textPage1 = page1.extract_text()
Dette trekker ut teksten fra den første siden og lagrer den i `textPage1`. Du har nå tilgang til teksten fra den første siden gjennom denne variabelen.
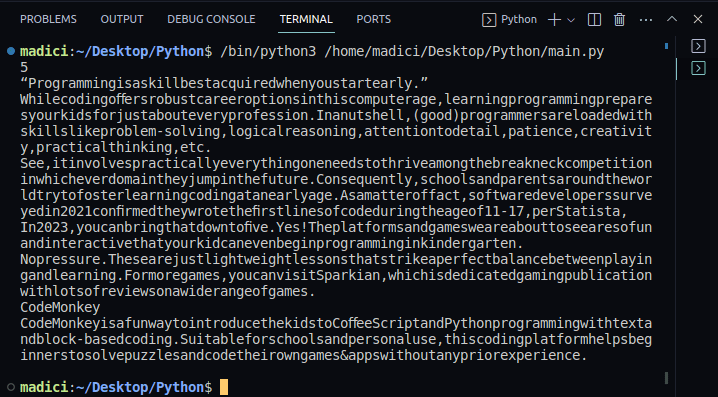
For å bekrefte, skriv ut innholdet av `textPage1`. Her er hele koden:
# importer PdfReader fra PyPDF2
from PyPDF2 import PdfReader
# lag en forekomst av PdfReader
reader = PdfReader('games.pdf')
# hent antall sider
print(len(reader.pages))
# hent første side
page1 = reader.pages[0]
# hent tekst fra side 1
textPage1 = page1.extract_text()
# skriv ut teksten
print(textPage1)
Utdata:
Utpakking av lenker fra PDF-filer med PyMuPDF
For å trekke ut lenker, vil vi bruke PyMuPDF, et Python-bibliotek for å jobbe med dokumenter som PDF-filer. Du trenger Python 3.8 eller nyere for å bruke PyMuPDF. Start med å installere biblioteket:
pip install PyMuPDF
Importer PyMuPDF i Python-filen din:
import fitz
Åpne PDF-filen du ønsker å jobbe med:
doc = fitz.open("games.pdf")
Skriv ut antall sider:
print(doc.page_count)
Utdata:
5
For å trekke ut lenker fra en spesifikk side, last inn siden du vil bruke. Husk at indekseringen begynner på null:
page = doc.load_page(0)
Hent ut lenkene fra siden:
links = page.get_links()
Alle lenkene på den valgte siden vil nå være lagret i variabelen `links`.
Skriv ut innholdet av `links`:
print(links)
Utdata:
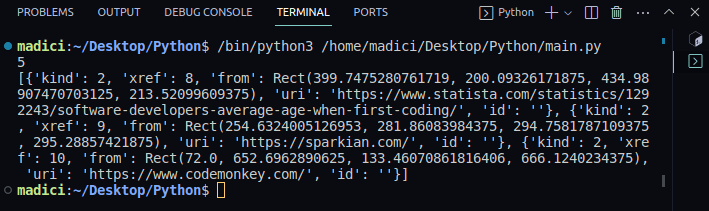
Variabelen `links` inneholder en liste med ordbøker, hvor hver ordbok representerer en lenke på siden. Den faktiske lenken er lagret under nøkkelen «uri».
For å hente ut de spesifikke lenkene, iterer gjennom listen og skriv ut «uri»-nøkkelen for hver lenke. Her er hele koden:
import fitz
# Åpne PDF-filen
doc = fitz.open("games.pdf")
# Skriv ut antall sider
print(doc.page_count)
# Last inn den første siden
page = doc.load_page(0)
# Hent ut alle lenker fra siden
links = page.get_links()
# Skriv ut lenkeobjektet
# print(links)
# Skriv ut de faktiske lenkene som er lagret under "uri"
for obj in links:
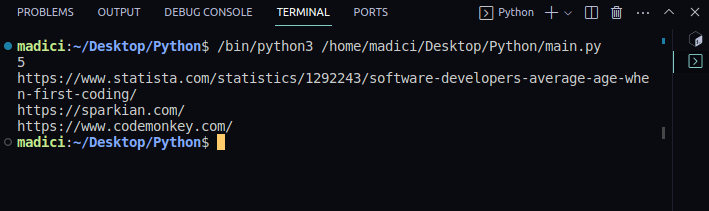
print(obj["uri"])
Utdata:
5 https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/
For å gjøre koden mer fleksibel, kan vi definere funksjoner for å trekke ut alle lenker fra en PDF og for å skrive ut disse. Dette gjør koden mer gjenbrukbar. Her er et eksempel:
import fitz
# Hent ut alle lenker fra en PDF
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# Skriv ut alle lenker
def print_all_links(links):
for link in links:
print(link["uri"])
# Kall funksjonen for å hente ut lenker fra en pdf
all_links = extract_link("games.pdf")
# Kall funksjonen for å skrive ut alle lenker
print_all_links(all_links)
Utdata:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
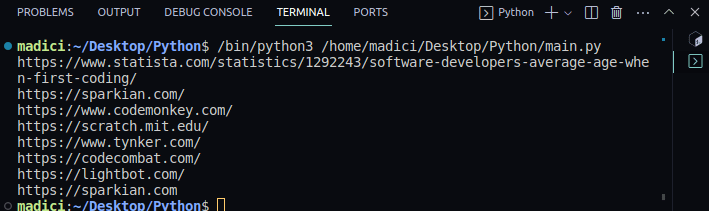
Funksjonen `extract_link()` tar inn en PDF-fil, går gjennom hver side, henter ut alle lenker og returnerer dem. Funksjonen `print_all_links()` tar inn resultatet fra `extract_link()`, og skriver ut hver lenke.
Utpakking av bilder fra PDF-filer
For å trekke ut bilder, vil vi fortsette å bruke PyMuPDF, sammen med `io` og PIL (Python Imaging Library). `io` gir verktøy for å håndtere binær data, mens PIL gir funksjoner for å arbeide med bilder.
Start med å importere de nødvendige bibliotekene:
import fitz from io import BytesIO from PIL import Image
Åpne PDF-filen:
doc = fitz.open("games.pdf")
Last inn siden du vil trekke ut bilder fra:
page = doc.load_page(0)
PyMuPDF identifiserer bilder ved hjelp av en kryssreferanse (xref) som er et unikt heltall. For å hente ut et bilde, må du først finne xref-nummeret. Bruk `get_images()` for å finne xref-nummeret for bildene på siden:
image_xref = page.get_images() print(image_xref)
Utdata:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
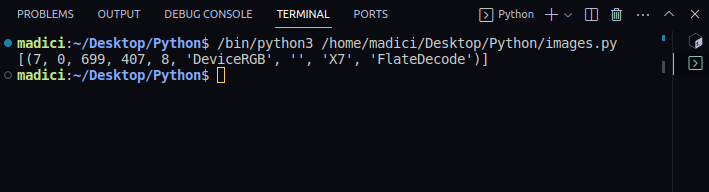
`get_images()` returnerer en liste med tupler med informasjon om bildene. Det første elementet i tuppelen representerer xref-verdien. I dette eksemplet er xref-verdien 7.
For å trekke ut xref-verdien fra listen av tupler:
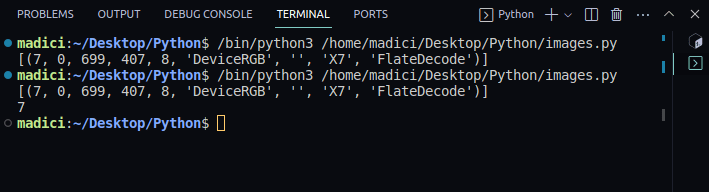
# hent xref-verdien xref_value = image_xref[0][0] print(xref_value)
Utdata:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
Nå som du har xref-verdien, kan du trekke ut bildet med `extract_image()`:
img_dictionary = doc.extract_image(xref_value)
Dette returnerer en ordbok med binærdata for bildet og metadata.
Sjekk filtypen til bildet som er lagret under nøkkelen «ext»:
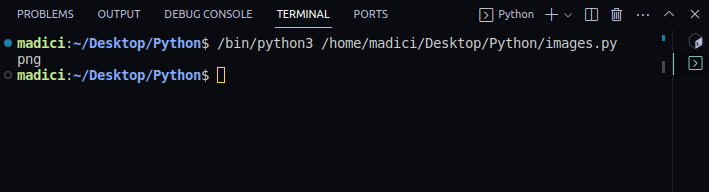
# hent filtype img_extension = img_dictionary["ext"] print(img_extension)
Utdata:
png
Hent ut de binære bildedataene fra ordboken, lagret under nøkkelen «image»:
# hent binære bildedata img_binary = img_dictionary["image"]
Lag et `BytesIO`-objekt med de binære bildedataene. Dette skaper en fillignende struktur som kan brukes av PIL:
# lag et BytesIO-objekt image_io = BytesIO(img_binary)
Åpne og analyser bildedataene i `BytesIO`-objektet med PIL. Dette gjør at PIL kan håndtere bildet og lagre det:
# åpne bildet med PIL image = Image.open(image_io)
Spesifiser lagringsplassering for bildet:
output_path = "image_1.png"
Lagre bildet og lukk `BytesIO`-objektet:
# lagre bildet image.save(output_path) # lukk BytesIO image_io.close()
Her er hele koden for utpakking av et bilde fra PDF:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# hent xref-verdien
image_xref = page.get_images()
# hent xref fra tuppelen
xref_value = image_xref[0][0]
# hent ut bildet
img_dictionary = doc.extract_image(xref_value)
# hent filtype
img_extension = img_dictionary["ext"]
# hent binære data
img_binary = img_dictionary["image"]
# skap BytesIO-objekt
image_io = BytesIO(img_binary)
# åpne bildet med PIL
image = Image.open(image_io)
# spesifiser lagringsplassering
output_path = "image_1.png"
# lagre bildet
image.save(output_path)
# lukk BytesIO
image_io.close()
Kjør koden, og du vil finne det utpakkede bildet med navnet `image_1.png` i samme mappe som Python-filen:
Konklusjon
For å øve mer på utpakking av lenker, bilder og tekst, prøv å refaktorere koden for å gjøre den mer gjenbrukbar, slik som eksemplet med lenker. Dette gjør det enklere å behandle ulike PDF-filer og hente ut dataene du trenger. Lykke til med kodingen!
Du kan også utforske noen av de beste PDF API-ene for dine forretningsbehov.