Viktige punkter
- Selvkjørende biler er avhengige av maskinlæringsvisjon for å observere og forstå sine omgivelser. Dette gjør dem i stand til å oppdage objekter, identifisere skilter og navigere på veien.
- Maskinlæringsvisjon i selvkjørende biler består av et kamerasystem, lokal databehandling (edge computing) og kunstig intelligens (AI)-algoritmer. Disse komponentene arbeider sammen for å samle visuell informasjon, behandle den i sanntid og identifisere mønstre og gjenstander.
- Maskinlæringsvisjon er essensielt for å oppnå full autonomi i selvkjørende biler. Det muliggjør objektklassifisering, deteksjon av kjørefelt og signaler, identifisering av skilt og gjenkjenning av trafikk. Fremtidens autonome kjøretøy er avhengig av fremskritt innen AI, lokal databehandling og kamerateknologi.
Selvkjørende biler har lenge vært et spennende tema. Selv om vi ikke har fullt ut autonome biler ennå, finnes det biler med avanserte førerassistentsystemer (ADAS) som kan styre, skifte fil, parkere og tilpasse fart i trafikken automatisk.
En selvkjørende bil bruker en rekke sensorer for sine ADAS-funksjoner. Maskinlæringsvisjon er den viktigste metoden for å oppdage, identifisere og beregne avstanden til objekter og omgivelsene generelt. Uten maskinlæringsvisjon ville selvkjørende biler med cruisekontroll og autopilot være usannsynlige.
Hva er maskinlæringsvisjon?

Maskinlæringsvisjon er en teknologi som gir maskiner evnen til å «se» og gjenkjenne objekter i sine omgivelser. Det er en gren av datasyn som fokuserer på industrielle anvendelser av visjonsbasert objektdeteksjon i autonome maskiner, som roboter og kjøretøy.
Dagens maskinlæringsvisjon benytter AI-baserte dyp læringsalgoritmer, som konvolusjonelle nevrale nettverk (CNN), for å skape robuste og allsidige modeller. Disse modellene kan nøyaktig identifisere objekter under forskjellige forhold. Dette gjør det mulig å implementere maskinlæringsvisjon i en rekke oppgaver som krever høy pålitelighet innen produksjon, landbruk, robotikk og bilindustrien.
Hvordan fungerer maskinlæringsvisjon i selvkjørende biler?
Maskinlæringsvisjon i selvkjørende biler kan typisk deles inn i tre hovedkomponenter: kamerasystemet, databehandling (lokal databehandling) og AI. Denne teknologikombinasjonen gjør det mulig for et autonomt kjøretøy å «se», «tenke» og identifisere tegn og hindringer under kjøring. La oss se nærmere på hver komponent for å forstå hvordan disse teknologiene samarbeider for å danne maskinlæringsvisjon i en selvkjørende bil.
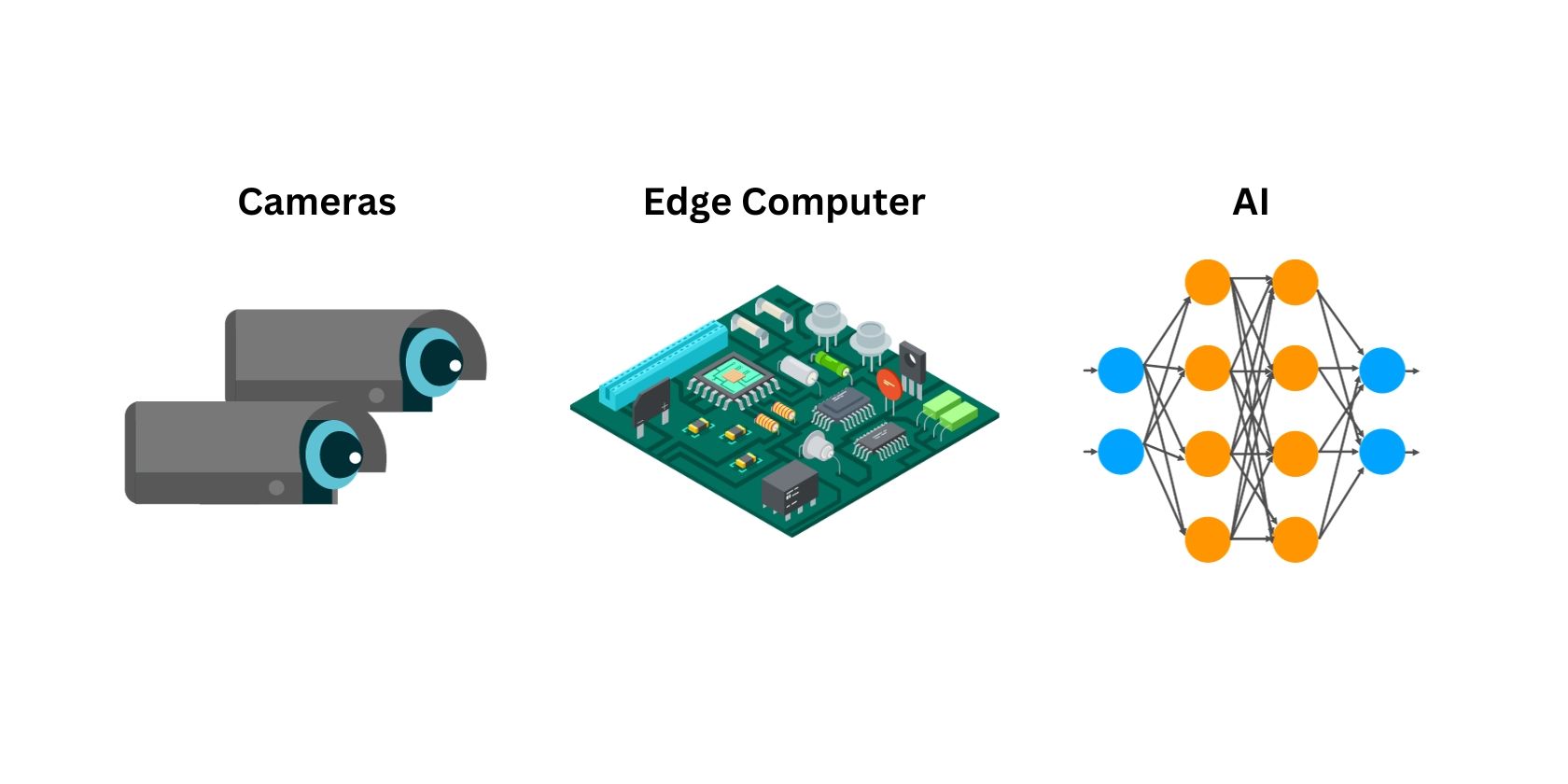
Kamerasystem
Maskinlæringsvisjon er avhengig av kamerasystemer for å samle inn visuell informasjon om omgivelsene. Selvkjørende biler bruker flere kameraer montert rundt bilen for å samle inn så mye visuell informasjon som mulig.
To hovedtyper sensorer brukes i maskinlæringsvisjonskameraer: komplementære metalloksid-halvledere (CMOS) og ladningskoblede enheter (CCD). I selvkjørende biler er CMOS ofte foretrukket på grunn av sin raske avlesningshastighet, kraftige integrerte elektronikk og evne til parallell databehandling. Dette gjør den til en raskere sensor, selv om den kan være mer utsatt for støy eller forstyrrelser. Løsninger som ulike lysmoduser, digitalt nattsyn og filtre kan hjelpe CMOS-sensoren under dårlige lysforhold.
Kameraer i selvkjørende biler er montert i bestemte avstander fra hverandre for å skape stereoskopisk syn. Stereoskopisk syn er evnen til å kombinere to eller flere visuelle inntrykk, og skape en følelse av dybde eller tredimensjonalitet i objekter og omgivelsene. Dette lar bilene triangulere og beregne den omtrentlige avstanden mellom et objekt og bilen.
Mennesker, med sine to øyne, har også nytte av stereoskopisk syn. Du kan teste det selv: lukk det ene øyet og velg en liten gjenstand på et bord. Hold hånden ved siden av objektet og sørg for at objektets spiss er minst fem centimeter unna. Ta en pause i noen sekunder og legg merke til hvor sikker du er på din beregning av avstanden. Åpne så begge øynene, og se hvordan din dybdeoppfatning er betydelig forbedret.
Lokal databehandling (Edge computing)
Mens kamerasystemet på den selvkjørende bilen samler data, behandler en innebygd datamaskin (lokal datamaskin) all informasjonen i sanntid. Dette oppdaterer systemet umiddelbart med statusen for omgivelsene. Selv om typiske maskinlæringsvisjonsoppgaver kan være kostnadseffektive ved bruk av skydatabehandling, er risikoen ved å koble selvkjørende biler til skyen for stor, selv for å outsource prosessen med maskinlæringsvisjon.
Ved å bruke en lokal datamaskin for å behandle inngangsdata, elimineres forsinkelsesproblemer, og man sikrer at data mottas, behandles og kommuniseres i sanntid. Lokale datamaskiner for selvkjørende biler benytter spesialiserte datamaskiner som integrerer AI-grafikkprosessorer, som NVIDIAs Tensor Core og CUDA Cores.
AI-algoritmer
Algoritmer har alltid vært en sentral del av maskinlæringsvisjon. Algoritmen er det som gjør at en datamaskin kan identifisere mønstre, former og farger fra kamerasystemet. Ved å bruke AI fremfor tradisjonelle maskinlæringsvisjonsalgoritmer, forbedres en selvkjørende bils evne til pålitelig å identifisere objekter, trafikkskilt, veimerker og trafikklys. Flere AI-algoritmer brukes til å trene selvkjørende biler. De mest populære inkluderer:
- YOLO (You Only Look Once): En algoritme for objektdeteksjon i sanntid som identifiserer og sporer objekter i bilens synsfelt.
- SIFT (Scale-Invariant Feature Transform): Brukes for å trekke ut karakteristiske trekk, og hjelper bilen å gjenkjenne landemerker og objekter i omgivelsene.
- Histogram of Oriented Gradients (HOG): Brukes for objektgjenkjenning, og fokuserer på å trekke ut lokale mønstre og gradienter fra bilder.
- TextonBoost: En algoritme som hjelper med å gjenkjenne objekter ved å analysere teksturer i miljøet.
- AdaBoost: Brukes til dataklassifisering. AdaBoost kombinerer flere svakere klassifikasjoner for å ta sterke avgjørelser om objekter og hindringer i kjøretøyets vei.
Viktigheten av maskinlæringsvisjon i selvkjørende biler
 Bildekreditt: Automobile Italia/Flickr
Bildekreditt: Automobile Italia/Flickr
Maskinlæringsvisjon er den primære metoden for selvkjørende biler for å oppfatte og forstå omgivelsene. Uten maskinlæringsvisjon vil sannsynligvis selvkjørende biler bli begrenset til nivå 1 på skalaen for kjøretøyautonomi, og kanskje aldri oppnå full autonomi.
Med maskinlæringsvisjon kan selvkjørende biler nå utføre objektklassifisering, deteksjon av kjørefelt og signaler, identifisering av skilt og gjenkjenning av trafikk.
Selv om mange selvkjørende kjøretøy nå bruker ulike sensorer som LIDAR, RADAR og SONAR, er de alle avhengige av maskinlæringsvisjon for å se omgivelsene, identifisere objekter og forstå betydningen av skilt og trafikklys. Alle disse ekstra sensorene er der for å forbedre maskinlæringsvisjon og fremme sikkerheten for mennesker, dyr og eiendom.
Det er også verdt å merke seg at maskinlæringsvisjon kan fungere uavhengig uten hjelp fra andre sensorer for å gi autopilotfunksjoner. Faktisk har Teslas nyeste selvkjørende biler droppet RADAR og er nå utelukkende avhengig av maskinlæringsvisjon for sitt autopilotsystem.
Dette betyr ikke at andre sensorteknologier er verdiløse, men det understreker viktigheten og kraften til maskinlæringsvisjon i selvkjørende biler.
Fremtiden for maskinlæringsvisjon i autonome kjøretøy
Maskinlæringsvisjon er grunnlaget for selvkjørende biler. Gjennom maskinlæringsvisjon kan biler «se» og oppfatte omgivelsene på samme måte som mennesker gjør. Selv om utfordringene fortsatt er til stede, kan ikke fordelene med maskinlæringsvisjon når det gjelder sikkerhet og navigasjon undervurderes. Fremtidens autonome kjøretøy vil dra nytte av ytterligere fremskritt innen AI, lokal databehandling og/eller kamerateknologi, noe som sannsynligvis vil gjøre selvkjørende biler mer dyktige og øke deres automatiseringsnivå.