
Scikit-LLM er en Python-pakke som hjelper med å integrere store språkmodeller (LLM) i scikit-learn-rammeverket. Det hjelper med å utføre tekstanalyseoppgaver. Hvis du er kjent med scikit-learn, vil det være lettere for deg å jobbe med Scikit-LLM.
Det er viktig å merke seg at Scikit-LLM ikke erstatter scikit-learn. scikit-learn er et maskinlæringsbibliotek for generell bruk, men Scikit-LLM er spesielt utviklet for tekstanalyseoppgaver.
Innholdsfortegnelse
Komme i gang med Scikit-LLM
Til å komme i gang med Scikit-LLM, må du installere biblioteket og konfigurere API-nøkkelen din. For å installere biblioteket, åpne IDE-en og lag et nytt virtuelt miljø. Dette vil bidra til å forhindre potensielle konflikter med bibliotekversjon. Kjør deretter følgende kommando i terminalen.
pip install scikit-llm
Denne kommandoen vil installere Scikit-LLM og dens nødvendige avhengigheter.
For å konfigurere API-nøkkelen din, må du anskaffe en fra din LLM-leverandør. Følg disse trinnene for å få tak i OpenAI API-nøkkelen:
Fortsett til OpenAI API-side. Klikk deretter på profilen din i øvre høyre hjørne av vinduet. Velg Vis API-nøkler. Dette tar deg til API-nøkler-siden.
På API-nøkler-siden klikker du på knappen Opprett ny hemmelig nøkkel.
Gi API-nøkkelen et navn og klikk på knappen Opprett hemmelig nøkkel for å generere nøkkelen. Etter generering må du kopiere nøkkelen og lagre den på et trygt sted da OpenAI ikke vil vise nøkkelen igjen. Hvis du mister den, må du generere en ny.
Nå som du har API-nøkkelen din, åpne IDE-en din og importer SKLLMConfig-klassen fra Scikit-LLM-biblioteket. Denne klassen lar deg angi konfigurasjonsalternativer knyttet til bruken av store språkmodeller.
from skllm.config import SKLLMConfig
Denne klassen forventer at du angir OpenAI API-nøkkelen og organisasjonsdetaljer.
SKLLMConfig.set_openai_key("Your API key")
SKLLMConfig.set_openai_org("Your organization ID")
Organisasjons-ID og navn er ikke det samme. Organisasjons-ID er en unik identifikator for organisasjonen din. For å få din organisasjons-ID, fortsett til OpenAI organisasjon innstillingssiden og kopier den. Du har nå etablert en forbindelse mellom Scikit-LLM og den store språkmodellen.
Scikit-LLM krever at du har en pay-as-you-go-plan. Dette er fordi den gratis prøveversjonen av OpenAI-kontoen har en hastighetsgrense på tre forespørsler per minutt som ikke er tilstrekkelig for Scikit-LLM.
Å prøve å bruke den gratis prøvekontoen vil føre til en feil som ligner på den nedenfor mens du utfører tekstanalyse.

For å lære mer om takstgrenser. Fortsett til Siden for OpenAI rategrenser.
LLM-leverandøren er ikke begrenset til bare OpenAI. Du kan også bruke andre LLM-leverandører.
Importere de nødvendige bibliotekene og laste inn datasettet
Importer pandaer som du skal bruke til å laste datasettet. Importer også de nødvendige klassene fra Scikit-LLM og scikit-learn.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
Deretter laster du inn datasettet du vil utføre tekstanalyse på. Denne koden bruker IMDB-filmdatasettet. Du kan imidlertid justere det for å bruke ditt eget datasett.
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
Det er ikke obligatorisk å kun bruke de første 100 radene i datasettet. Du kan bruke hele datasettet.
Trekk deretter ut funksjonene og etikettkolonnene. Del deretter datasettet i tog- og testsett.
X = data['Description']y = data['Genre']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Sjangerkolonnen inneholder etikettene du vil forutsi.
Zero-Shot tekstklassifisering med Scikit-LLM
Zero-shot tekstklassifisering er en funksjon som tilbys av store språkmodeller. Den klassifiserer tekst i forhåndsdefinerte kategorier uten behov for eksplisitt opplæring på merkede data. Denne funksjonen er veldig nyttig når du arbeider med oppgaver der du trenger å klassifisere tekst i kategorier du ikke forutså under modelltrening.
For å utføre zero-shot tekstklassifisering ved hjelp av Scikit-LLM, bruk ZeroShotGPTClassifier-klassen.
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
Utgangen er som følger:
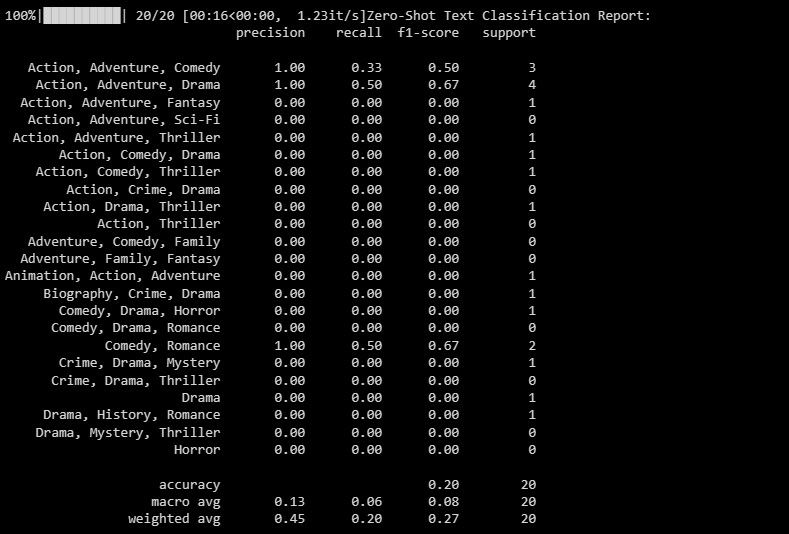
Klassifiseringsrapporten inneholder beregninger for hver etikett som modellen prøver å forutsi.
Multi-Label Zero-Shot tekstklassifisering med Scikit-LLM
I noen scenarier kan en enkelt tekst tilhøre flere kategorier samtidig. Tradisjonelle klassifiseringsmodeller sliter med dette. Scikit-LLM på den annen side gjør denne klassifiseringen mulig. Multi-label zero-shot tekstklassifisering er avgjørende for å tilordne flere beskrivende etiketter til en enkelt teksteksempel.
Bruk MultiLabelZeroShotGPTClassifier for å forutsi hvilke etiketter som passer for hvert teksteksempel.
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
I koden ovenfor definerer du kandidatetikettene som teksten din kan tilhøre.
Utgangen er som vist nedenfor:
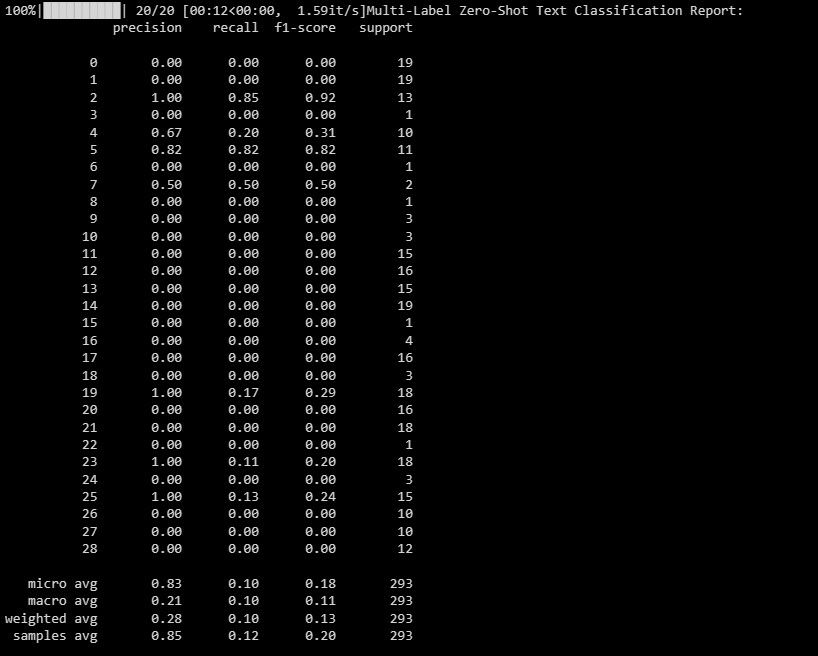
Denne rapporten hjelper deg å forstå hvor godt modellen din presterer for hver etikett i fleretikettsklassifisering.
Tekstvektorisering med Scikit-LLM
I tekstvektorisering konverteres tekstdata til et numerisk format som maskinlæringsmodeller kan forstå. Scikit-LLM tilbyr GPTVectorizer for dette. Den lar deg transformere tekst til fastdimensjonale vektorer ved hjelp av GPT-modeller.
Du kan oppnå dette ved å bruke Term Frequency-Inverse Document Frequency.
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5])
Her er utgangen:
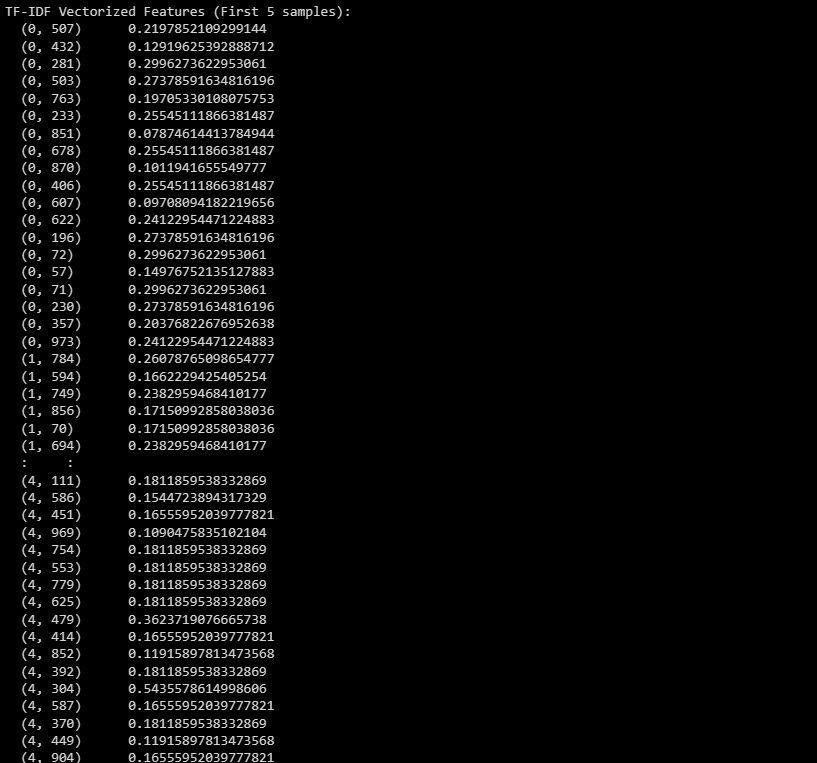
Utdataene representerer TF-IDF vektoriserte funksjoner for de første 5 prøvene i datasettet.
Tekstoppsummering med Scikit-LLM
Tekstoppsummering hjelper til med å kondensere et tekststykke samtidig som den bevarer den mest kritiske informasjonen. Scikit-LLM tilbyr GPTSummarizer, som bruker GPT-modellene til å generere konsise sammendrag av tekst.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
Utgangen er som følger:
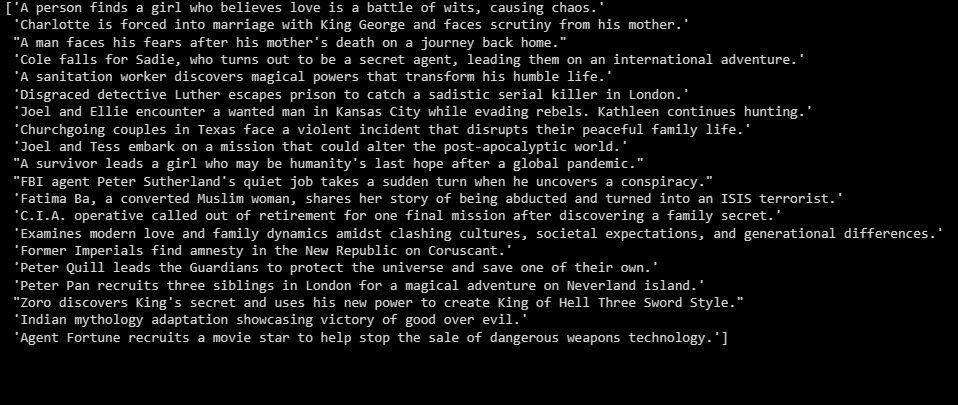
Ovenstående er et sammendrag av testdataene.
Bygg applikasjoner på toppen av LLM-er
Scikit-LLM åpner for en verden av muligheter for tekstanalyse med store språkmodeller. Å forstå teknologien bak store språkmodeller er avgjørende. Det vil hjelpe deg å forstå deres styrker og svakheter som kan hjelpe deg med å bygge effektive applikasjoner på toppen av denne banebrytende teknologien.