Introduksjon til Scikit-LLM
Scikit-LLM er et Python-bibliotek designet for å forenkle integrasjonen av store språkmodeller (LLM) i scikit-learn-økosystemet. Dette verktøyet er særlig nyttig for utføring av komplekse tekstanalyseoppgaver. Er du allerede kjent med scikit-learn, vil du finne overgangen til Scikit-LLM smidig og intuitiv.
Det er viktig å forstå at Scikit-LLM ikke er en erstatning for scikit-learn. Mens scikit-learn er et allsidig maskinlæringsbibliotek, er Scikit-LLM spesifikt utviklet for å håndtere utfordringer knyttet til tekstanalyse.
Kom i gang med Scikit-LLM
For å begynne å bruke Scikit-LLM, må du først installere biblioteket og konfigurere din API-nøkkel. Det anbefales å starte med et nytt virtuelt miljø i din IDE for å unngå konflikter mellom bibliotekversjoner. Deretter kjører du følgende kommando i terminalen:
pip install scikit-llm
Denne kommandoen sørger for at Scikit-LLM og alle nødvendige avhengigheter blir installert.
For å konfigurere API-nøkkelen, må du skaffe den fra din valgte LLM-leverandør. Her er hvordan du skaffer en OpenAI API-nøkkel:
Naviger til OpenAI API-siden. Klikk deretter på profilikonet ditt, som du finner øverst til høyre. Velg «Vis API-nøkler» for å komme til API-nøkkeladministrasjon.
På denne siden klikker du på «Opprett ny hemmelig nøkkel».
Gi nøkkelen et navn, og klikk på «Opprett hemmelig nøkkel» for å generere den. Det er viktig å kopiere og lagre denne nøkkelen på et sikkert sted, da OpenAI ikke vil vise den igjen. Du må generere en ny nøkkel dersom du mister den.
Etter at du har API-nøkkelen din, går du tilbake til din IDE. Her importerer du `SKLLMConfig`-klassen fra Scikit-LLM. Denne klassen brukes til å sette opp konfigurasjonsinnstillinger for bruk av store språkmodeller.
from skllm.config import SKLLMConfig
Denne klassen krever at du spesifiserer din OpenAI API-nøkkel og organisasjons-ID:
SKLLMConfig.set_openai_key("Din API-nøkkel")
SKLLMConfig.set_openai_org("Din organisasjons-ID")
Husk at organisasjons-ID og navn ikke er det samme. ID-en er en unik identifikator for organisasjonen din, og du kan finne den på OpenAI sin side for organisasjonsinnstillinger. Med dette er forbindelsen mellom Scikit-LLM og den store språkmodellen etablert.
Scikit-LLM krever en betalt «pay-as-you-go»-plan, da den gratis prøveversjonen av OpenAI har en begrenset rate på tre forespørsler per minutt, noe som ikke er tilstrekkelig for Scikit-LLM.
Et forsøk på å bruke den gratis kontoen vil resultere i en feilmelding som den nedenfor:

Mer informasjon om takstbegrensninger finnes på OpenAI sine sider for takstbegrensninger.
Du er ikke begrenset til å kun bruke OpenAI. Det finnes flere andre LLM-leverandører som kan brukes med Scikit-LLM.
Importere nødvendige biblioteker og laste inn datasettet
Start med å importere pandas for håndtering av datasettet, samt relevante klasser fra Scikit-LLM og scikit-learn:
import pandas as pd from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier from skllm.preprocessing import GPTSummarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.preprocessing import MultiLabelBinarizer
Neste skritt er å laste inn datasettet du skal jobbe med. Koden nedenfor benytter IMDB-filmdatasettet, men du kan tilpasse det til å bruke ditt eget datasett:
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
Det er ikke nødvendig å begrense seg til de første 100 radene, du kan bruke hele datasettet dersom ønskelig.
Deretter trekker du ut funksjons- og etikettkolonnene, og deler datasettet inn i trenings- og testsett:
X = data['Description'] y = data['Genre'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Kolonnen med sjanger inneholder kategoriene vi ønsker å forutsi.
Zero-Shot tekstklassifisering med Scikit-LLM
Zero-shot tekstklassifisering er en funksjon som lar store språkmodeller kategorisere tekst i forhåndsdefinerte klasser uten behov for tidligere trening med merkede data. Dette er spesielt nyttig i situasjoner hvor du må klassifisere tekst i kategorier som ikke var planlagt under modellutviklingen.
For å utføre zero-shot tekstklassifisering med Scikit-LLM, bruker du `ZeroShotGPTClassifier`-klassen:
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Zero-Shot Text Classification Report:")
print(classification_report(y_test, zero_shot_predictions))
Resultatet vil være som følger:
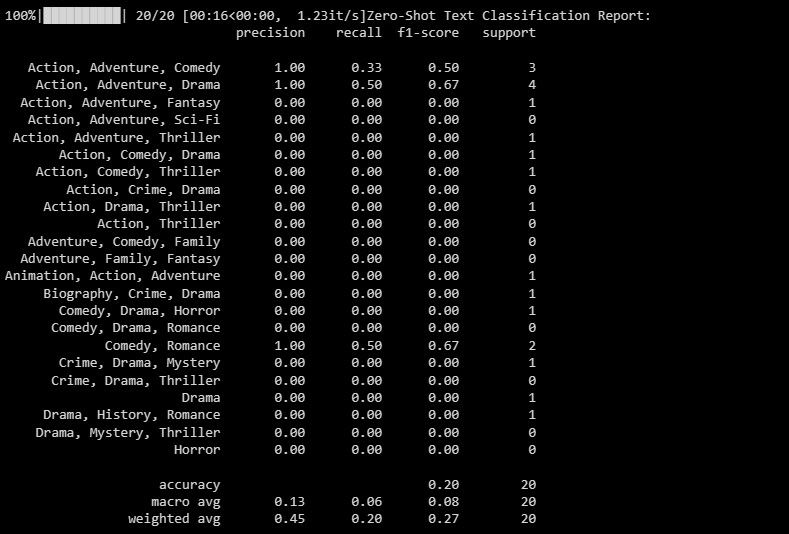
Rapporten gir detaljerte beregninger for hver etikett som modellen prøver å forutsi.
Multi-Label Zero-Shot tekstklassifisering med Scikit-LLM
Noen ganger kan en tekst falle inn under flere kategorier. Tradisjonelle klassifiseringsmodeller har problemer med dette, men Scikit-LLM muliggjør en slik flermerket klassifisering. Dette er viktig for å tilordne flere beskrivende etiketter til en enkelt tekst.
Bruk `MultiLabelZeroShotGPTClassifier` for å forutsi hvilke etiketter som passer til hver tekst:
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Multi-Label Zero-Shot Text Classification Report:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
Her definerer du de potensielle etikettene som teksten kan tilhøre.
Resultatet vil være som følger:
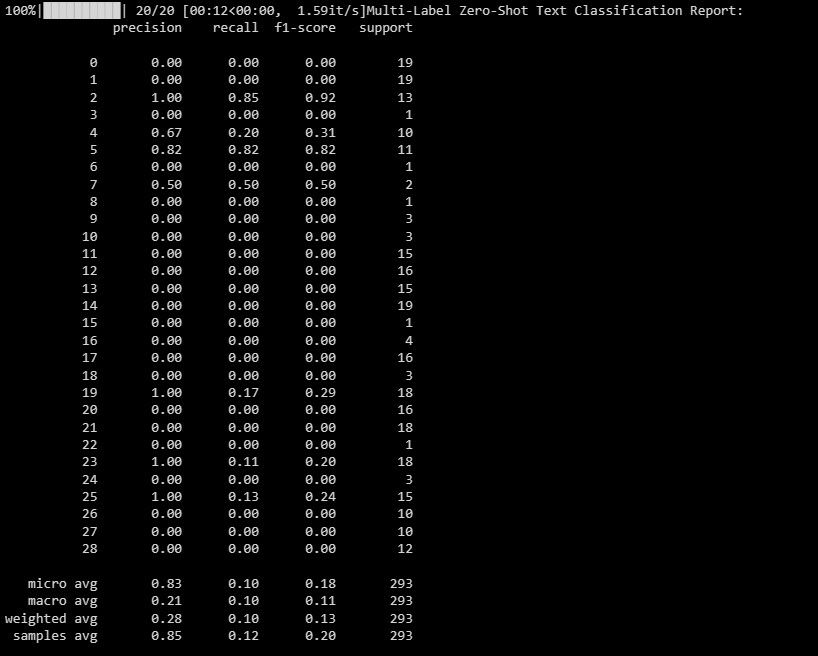
Denne rapporten gir deg innsikt i hvor godt modellen presterer for hver etikett i flermerket klassifisering.
Tekstvektorisering med Scikit-LLM
Ved tekstvektorisering konverteres tekstdata til et numerisk format som maskinlæringsmodeller kan forstå. Scikit-LLM tilbyr `GPTVectorizer` for dette. Det tillater deg å transformere tekst til vektorer med fast dimensjon ved hjelp av GPT-modeller.
Du kan også oppnå dette ved hjelp av Term Frequency-Inverse Document Frequency (TF-IDF):
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("TF-IDF Vectorized Features (First 5 samples):")
print(X_train_tfidf[:5])
Her er resultatet:
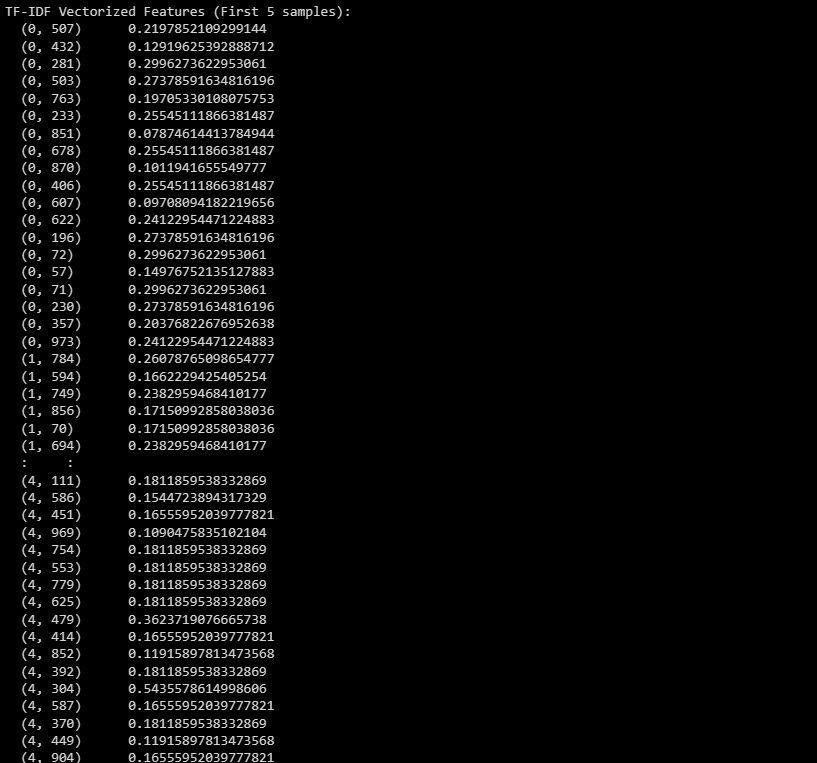
Output viser TF-IDF vektorfunksjoner for de fem første prøvene i datasettet.
Tekstoppsummering med Scikit-LLM
Tekstoppsummering handler om å redusere lengden på teksten samtidig som viktig informasjon bevares. Scikit-LLM tilbyr `GPTSummarizer` for dette, som bruker GPT-modellene til å generere korte sammendrag av tekster.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15) summaries = summarizer.fit_transform(X_test) print(summaries)
Resultatet er:
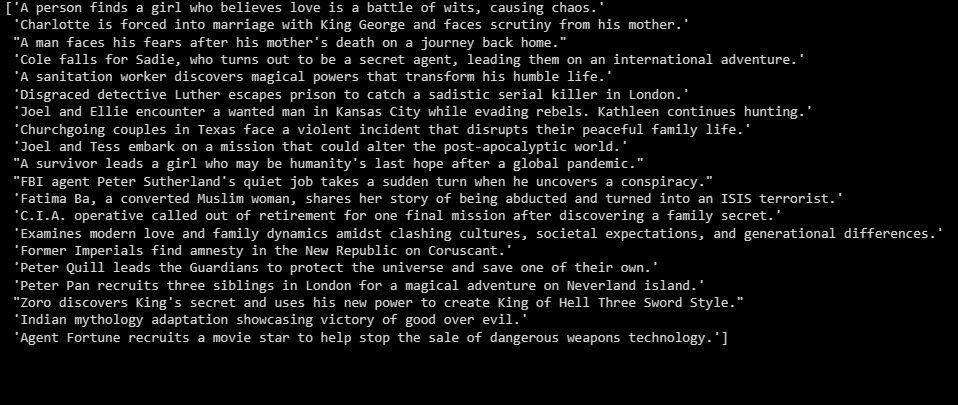
Ovenfor ser du et sammendrag av testdataene.
Bygg applikasjoner basert på LLM-er
Scikit-LLM åpner opp for en rekke muligheter innen tekstanalyse ved hjelp av store språkmodeller. Det er viktig å ha en god forståelse av teknologien som ligger bak disse modellene for å utnytte deres styrker og unngå fallgruvene. Dette vil hjelpe deg med å skape effektive applikasjoner basert på denne nyskapende teknologien.