Informasjon er en fundamental ressurs som kan forbedre operasjoner, effektivitet, kundeopplevelser og beslutningsprosesser.
Som en konsekvens av dette genererer, akkumulerer og lagrer bedrifter og organisasjoner kolossale mengder data fra utallige kilder. Imidlertid, i takt med at datavolumene vokser, kan det bli utfordrende å trekke ut den mest verdifulle informasjonen, spesielt når denne informasjonen er uorganisert og spredt på tvers av ulike steder.
En metode for å håndtere disse vanskelighetene er å lagre data i et egnet datalager. Dette gir en enhetlig datakilde som inneholder filtrert, søkbar og analyseklar informasjon.
Kilde: aws.amazon.com
I denne artikkelen skal vi utforske definisjonen av et datalager, lære om dets fordeler, forskjellige typer og beste praksis.
Hva er et datalager?
Et datalager er et arkiv eller bibliotek som inneholder data designet for å støtte analyse- og rapporteringsfunksjoner innen forskning eller forretningsdrift. I praksis er et datalager et overordnet begrep som henviser til det sentrale stedet hvor data oppbevares. Det kan representere en enkelt lagringsenhet eller et nettverk av databaser som strekker seg over flere enheter.
I en typisk arbeidsprosess kan organisasjoner samle inn data fra salgssystemer, CRM, ERP, regneark og andre kilder. Deretter overføres disse dataene til et datalager hvor de blir sortert, renset, validert, formatert, strukturert og lagret.
Ofte vil organisasjoner isolere og lagre spesifikke datatyper i lageret for analyse- eller rapporteringsformål. Siden dette er en langtidslagring, kan de bruke dataene om igjen for å gjennomføre ulike typer analyser.
Et typisk datalager består av tre hovedlag:
- Datakildelag
- Databearbeidingslag eller lager
- Målapplikasjonslaget, for eksempel bestående av brukere, analytikere og rapportering
Hvorfor er et datalager nødvendig?
Data er tilgjengelig fra ulike kontaktpunkter som kundekontaktpunkter, internett, forskning, markedsføring, applikasjoner og mange andre kilder. Disse dataene er som oftest i råformat, og organisasjoner trenger de rette verktøyene for å trekke ut nyttig informasjon som kan bidra til å nå målene deres. Det er fornuftig å opprette et datalager for å organisere dataene og gjøre dem tilgjengelige for analyser og andre anvendelser.
Datalageret gjør det mulig for autoriserte brukere å raskt og enkelt aksessere, hente ut og administrere data ved hjelp av søk, spørringer og andre verktøy. Dette gir brukere og bedrifter mulighet til å gjennomføre analyser, forskning, deling og rapportering. Dette gjør dem i stand til å effektivisere driften og ta bedre datadrevne beslutninger.
Tenk deg at du vil finne ut hvilken avdeling i organisasjonen din som har de største driftskostnadene. Du kan etablere et datalager for leieavtaler, sikkerhet, energikostnader, verktøy og andre utgifter. Det å samle dataene på ett sentralt sted gir deg muligheten til å analysere og identifisere avdelingen med de største utgiftene, slik at du kan ta mer informerte og fokuserte beslutninger når du skal redusere kostnader.
Selv om datalager ofte brukes av forsknings- og vitenskapelige institusjoner, er de også relevante for generelle organisasjoner og bedrifter.
Fordeler med datalager
I dag benytter de fleste organisasjoner datalager som et middel for å administrere og bruke dataene sine mer effektivt. Datalagerkonseptet har stadig vunnet popularitet på grunn av fordelene som enkel informasjonsadgang, administrasjon, analyse og rapportering.
Andre fordeler inkluderer:
- **Økt synlighet:** Ved å lagre data på et sentralt og pålitelig sted, er de tilgjengelige når som helst. Å holde data i separate applikasjoner eller lokale siloer derimot, begrenser tilgjengeligheten til en enkeltperson eller noen få personer. Dette reduserer synlighet og brukervennlighet. Som et resultat kan det ta lengre tid og kreve ekstra ressurser for team å få tilgang til dataene.
- **Lett tilgang til relevant data:** Data i digital form er enkle å søke etter og få tilgang til. Å legge til metadata i dataene i datalageret hjelper brukere med å forstå og bruke dataene på en bedre måte.
- **Enklere datasikkerhet og overholdelse:** Det er mye enklere å beskytte data på ett sentralt sted, i motsetning til når de er spredt over flere lokasjoner. Et datalager gjør det også lettere og mer kostnadseffektivt å overholde ulike regulatoriske standarder.
- **Gjenbrukbare data:** Datalageret inneholder et bredt spekter av data for analyse og rapportering. Analytikere og forskere kan bruke de samme dataene til å lage forskjellige typer rapporter.
- **Gir verdifull innsikt:** Ved å bruke egnede verktøy på datalagre kan du få en flerdimensjonal oversikt over dataene, i motsetning til å analysere informasjon på forskjellige steder.
Typer datalager
Datalager er et generelt begrep som refererer til informasjonsarkivet. Det finnes imidlertid ulike typer depoter basert på målbruken eller formålet. Nedenfor er de fire hovedtypene datalagre:
#1. Datavarehus
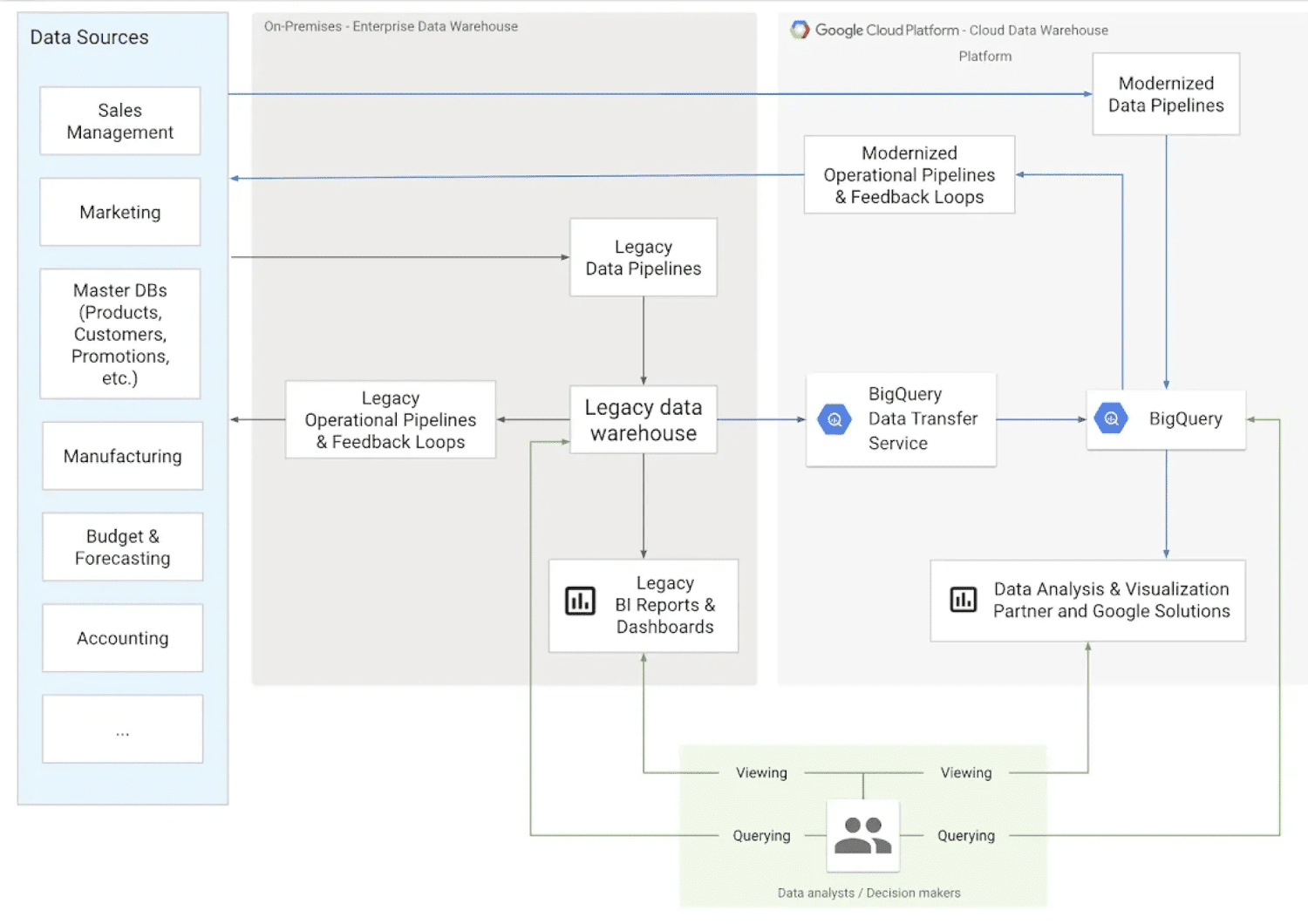
Kilde: cloud.google.com
Datavarehuset er en av de største typene datalager. I denne kategorien kan virksomheter samle inn data fra mange kilder og i ulike formater. Et typisk datavarehus lagrer store mengder data fra ulike kilder. Strukturen gjør det mulig for organisasjoner å enkelt strukturere dataene, analysere og generere rapporter. Dette gjør det mulig for team å ta bedre datadrevne beslutninger.
Informasjon i et datavarehus kan dekke mange emner, og den blir vanligvis renset, filtrert og definert for en spesifikk bruk.
#2. Databutikk
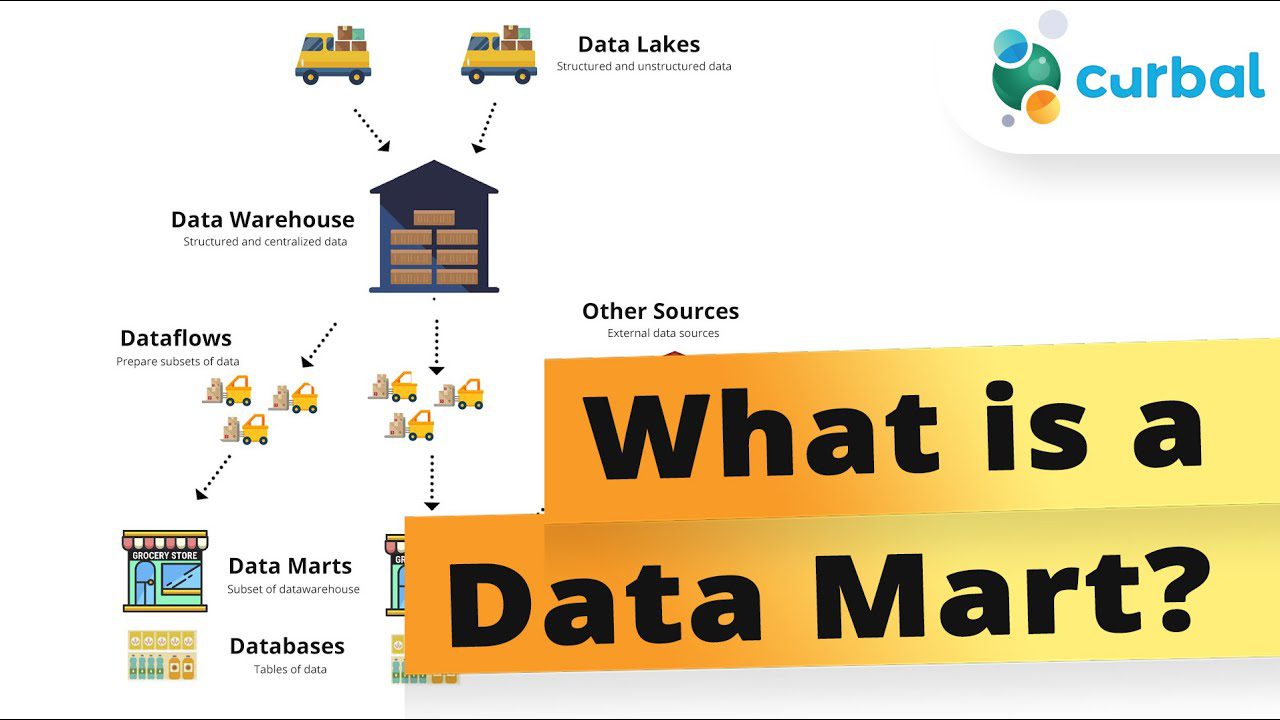
En datamart er en segmentert del av et datavarehus. Dette fagorienterte datalageret lagrer en undergruppe av data som fokuserer på en bestemt forretningsfunksjon eller avdeling, som for eksempel finans, kundestøtte, innkjøp eller markedsføring.
Vanligvis er en datamart mindre i størrelse. Dette bidrar til å fremskynde forretningsprosesser ved å gi tilgang til relevant data innen en kortere tidsperiode. De tilbyr en kostnadseffektiv metode for raskt å få praktisk innsikt.
#3. Data Lake
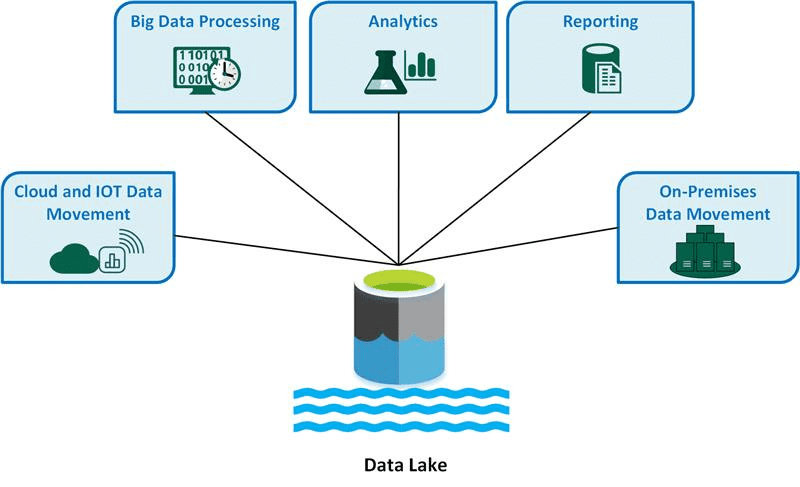
Kilde: microsoft.com
En datasjø er et enormt arkiv som inneholder data i alle former. Dette inkluderer ustrukturerte, semistrukturerte og strukturerte data. Den bruker metadata for å klassifisere og merke dataene, som stort sett er ustrukturerte. En datasjø gir full kontroll og bedre datastyring enn et datavarehus.
#4. Datakuber
Datakuber er flerdimensjonale datalagre som er mer fokusert på komplekse data som ikke støttes av de andre typene. Disse har tre eller flere dimensjoner, der hver representerer en spesifikk egenskap, som daglige, månedlige eller årlige kostnader eller salg. Datasjøer gjør det mulig for forskere å vurdere data fra ulike perspektiver.
Les også: Data Lake vs Data Warehouse: Hva er forskjellene?
Beste praksis for utforming og vedlikehold av datalager
Et typisk datalager har verktøy for å lagre, administrere og sikre informasjon. Det inkluderer funksjoner som tilgangskontroll, indeksering, komprimering, rapportering, kryptering og mer.
Når du designer og etablerer et datalager, må du ta hensyn til flere faktorer knyttet til maskinvare og programvare, i tillegg til å samarbeide med datapipelineingeniører, dataanalytikere og andre spesialister. Avhengig av domenet må du involvere bransjeeksperter. Hvis du for eksempel lager et klinisk datalager, er det viktig å samarbeide med leger og andre helsepersonell.
En effektiv databehandlingsstrategi omfatter følgende:
✅ Organisering av filer
✅ Sikker lagring og korrekte tilgangskontroller
✅ Versjons- og dokumentasjonskontroll
✅ Støtte for samarbeid
✅ Klare retningslinjer for gjenbruk og deling
✅ Arkivering og oppbevaring av data for fremtidig referanse eller bruk.
Selv om trinnene for å designe, etablere og administrere et datalager kan variere fra bransje eller organisasjon til en annen, er det noen beste fremgangsmåter beskrevet nedenfor.
Begrens omfanget i de første stadiene
I starten er det en god praksis å jobbe med et mindre omfang av datalageret. En strategi er å bruke et mindre antall fagområder og datasett, og deretter øke omfanget gradvis.
Velg de riktige verktøyene
Verktøy er essensielle for å skape, lagre, dele, analysere og administrere datalagre. Som et resultat vil datakvaliteten og analysen avhenge av verktøyene du bruker. Siden det finnes ulike typer verktøy med varierende funksjoner, er det viktig å sikre at valget ditt oppfyller dine spesifikke behov.
Automatiser så mange prosesser som mulig
Hvis mulig, automatiser innlasting og vedlikeholdsoppgaver for å forbedre effektiviteten, redusere tidsspill og risikoen for feil.
Design et fleksibelt og skalerbart arkiv
For å kunne håndtere økte datavolumer, utviklende datatyper og formater, er det best å designe og skape et skalerbart lager. Et slikt system vil ivareta dagens behov og kunne skaleres for å støtte utvidede datatyper og -volumer i fremtiden. Det bør også være fleksibelt slik at det kan fungere med ulike verktøy og ny teknologi.
Beskytt data til enhver tid
Sørg for dataintegritet og sikkerhet, siden eventuelle avvik, kompromisser eller tyveri kan føre til unøyaktige analyseresultater og dårlige beslutninger. Angi korrekte tilgangsregler og gi kun autoriserte brukere de nødvendige tillatelsene for å utføre sine oppgaver. Krypter også dataene i hvile og under overføring. Vurder ytterligere tiltak som multifaktorautentisering for å legge til et ekstra lag med beskyttelse.
Bruk standard datamodeller
Datamodellering bidrar til å omforme data til verdifull informasjon som forskere og bedriftsledere kan forstå bedre. Normalt kan informasjon i et datalager brukes om igjen.
Organisasjoner kan bruke de samme dataene til å hente ut relevant informasjon på ulike områder. Data har mange sammenhenger basert på hvordan de brukes i forskjellige prosesser og analytiske applikasjoner. Derfor kan en organisasjon bruke flere datamodeller for å imøtekomme ulike analytiske behov.
Indeksering av data
Det å opprette indekser i datalagertabellene forbedrer søkeytelsen og bør være standard praksis. Det øker hastigheten på spørringer ved å tilby en organisert oppslagstabell basert på spesifikke attributter og med oppføringer som peker til spesifikke dataplasseringer.
Indeksering på datalagre kan variere avhengig av bruken. Det kan være lett eller omfattende, avhengig av formålet. Ideelt sett bør indekseringsstrategien fokusere på å akselerere ETL-prosessene. En god praksis ved transformering av data er å sikre at indeksen gir den nødvendige informasjonen uten å gå glipp av nyttige data, og samtidig ikke være unødvendig stor.
Det er også viktig å balansere avveiningen mellom forbedret spørringsytelse i datalageret og de tilhørende drifts- og vedlikeholdskostnadene ved indekseringen.
Les også: Beste ETL-verktøy for små og mellomstore bedrifter å bruke.
Eksempler på datalager
Datalagre kan kategoriseres på følgende måte:
- Institusjonelle arkiver (IR) for forskningsinstitusjoner, som for eksempel Texas Data Repository fra Texas A&M University Libraries.
- Fag- eller domenespesifikke arkiver (DR): Disse er domenespesifikke og drives av et konsortium av forskere eller en profesjonell organisasjon, som f.eks. Register for forskningsdatalager (re3data) fra DataCite, og Directory of Open Access Repositories (OpenDOAR), som omfatter flere akademiske arkiver med åpen tilgang.
- Åpne eller generelle arkiver, som for eksempel Dryad, Figshare og Harvard Dataverse.
Bruksområder for datalager
Fintech, helsevesen, e-handel, forsyningskjeder og andre bransjer kan ha nytte av å bruke datalagre. Ved å fullt ut utnytte de store datamengdene de samler inn og genererer, kan de få bedre innsikt for å optimalisere tjenestene sine og tilby bedre og raskere tjenester.
Klinisk forskning
Klinisk forskning er et dataintensivt felt. Det å få mest mulig ut av dataene bidrar til å drive helsesektoren i riktig retning. Analysering av store datamengder gir forskere og annet helsepersonell muligheten til å dykke dypere ned i kliniske studier og få innsikt som bidrar til å forbedre helsevesenet og redde liv.
Finansielle tjenester

Finansnæringen kan dra fordel av å analysere de store datamengdene de har. Analysen gir dem innsikt som de kan bruke til å forbedre tjenester, effektivitet og inntekter. Noen av områdene finansinstitusjoner kan bruke datalager inkluderer:
- For å generere økonomiske rapporter ved å analysere data fra et sentralt sted.
- Muliggjøre AI-drevet automatisert beslutningstaking.
Siste ord
Data er en viktig ressurs i beslutningstaking. Organisasjoner som lagrer store mengder data trenger de riktige løsningene for å samle inn, lagre, administrere og analysere dataene.
Et datalager tilbyr en løsning for å konsolidere og administrere viktige data. Datalagrene gir organisasjoner muligheten til å analysere data, få innsikt og ta bedre datadrevne beslutninger.
Et datalager tilbyr sentralisert lagring av ulike typer informasjon, men på en logisk måte som gjør det enkelt å få tilgang til, søke etter, analysere og administrere dem. Det hjelper også organisasjoner med å sikre, dele, vedlikeholde og garantere dataintegritet og kvalitet, samt overholde regulatoriske standarder.
I neste trinn bør du sjekke ut de beste datahåndteringsverktøyene for mellomstore og store bedrifter.